
基于文档图结构的恶意PDF 文档检测方法
2021-11-23 03:14俞远哲王金双
网络安全与数据管理 2021年11期
俞远哲,王金双,邹 霞
(陆军工程大学 指挥控制工程学院,江苏 南京210007)
0 引言
PDF (Portable Document Format) 文档的使用非常广泛。随着版本的更新换代,PDF 文档包含的功能也变得多种多样,但其中一些鲜为人知的功能(如文件嵌入、JavaScript 代码执行、动态表单等) 越来越多地被不法分子利用,来实施恶意网络攻击行为[1]。APT(Advanced Persistent Threat) 攻击[2]常常构造巧妙伪装的恶意PDF 文档,通过钓鱼邮件攻击等手段诱骗受害者下载,从而侵入或破坏计算机系统。相比传统的恶意可执行程序,恶意文档具有更强的迷惑性。
基于机器学习的检测方法被研究人员广为使用,主要可以分为静态检测、动态检测和动静结合检测方法[3]。而现有的恶意文档特征选择方法大多依赖于专家的知识驱动,在恶意文档的手动分析期间进行观察来选择特征集(如调用类对象的数量、文档页数或版本号等),或是通过数学统计分析将特征细化(如某类对象在所有对象中的占比)。由于特征可选取的范围很大,如果仅仅根据经验选取了一部分作为特征集,就会丧失文档的部分信息,无法全面地表达文档特性。
由于PDF 文档格式的复杂性,其逻辑结构包含了大量的文档语义。文献[4]认为通过对结构属性的综合分析能够解释恶意和良性PDF 文档之间的显著结构差异。因此本文设计通过综合分析文档的逻辑结构,以文档的结构图为特征进行检测,而不是独立的结构路径。即使攻击者知道哪些对象是成功检测的关键,并可能针对性地修改某一特定路径,但这样就会破坏文档的整体结构,因此逃避检测的成本很高。
本文的主要工作和创新点如下:
(1) 以静态检测技术和图论为基础,根据文档的逻辑结构构造出文档结构图,得到包含图信息的邻接矩阵和度矩阵,并计算得到拉普拉斯矩阵作为特征。这种特征表达的优点在于不仅包含了相邻节点的邻接关系,还包含了节点本身的出入度,包含图的信息更多,对文档的表征能力更强。
(2) 在构造文档的图结构时,通过TF -IDF 算法对节点进行精简合并: 统计了PDF 文档中的对象对于分类的贡献度排名,前73 类对象的总贡献度达到了99%,将剩下的140 类对象合并为一类。通过图精简生成了74 类对象,实现了特征降维,在提升模型效率的同时,缓解了特征维度过高导致可能出现的过拟合问题。
(3) 基于特征加法攻击生成训练样本,对模型进行对抗训练。使用Metasploit 工具生成了2000个恶意对抗样本,与VirusTotal 的检测结果对比分析表明,本模型的检测性能高于VirusTotal 的检测引擎。
1 相关工作
1.1 恶意PDF 特征及特征值类型
前期研究所选定的特征主要依赖专家知识驱动[5],部分选定特征不是恶意文档所特有的,而且无论是单一特征还是混合特征,均是从庞大的特征集中选取的一小部分特征,以特征在样本中的频数作为特征值。这类选取的特征容易被攻击者篡改。攻击者只需要找到影响模型判定的关键特征,增大其他特征的频数,便能稀释文档中的关键特征,从而使分类器产生错误的判定。已有基于机器学习算法的恶意PDF 文档检测器之间的比较如表1 所示。

表1 恶意PDF 机器学习检测器对比分析
1.2 逃避攻击
逃避攻击是指攻击者试图修改恶意样本的特征,在不影响恶意行为的前提下来逃避模型检测。逃避攻击生成对抗样本的方式主要有梯度下降攻击和特征加法攻击[15]。梯度下降攻击通过修改恶意样本的特征,使得恶意样本无法被正确分类。它最早是在图像识别领域提出的,其原理是在图像上通过修改像素点生成微小的扰动,但并不会影响图像自身的格式。但是由于PDF 文档自身格式的规范性,随意地修改某一特征可能会使得文档格式无法正常解析以致损坏。因此基于梯度下降攻击生成可执行的对抗文档更难。
特征加法攻击通过将恶意负载附加到正常文档之中,或是向恶意文档中添加正常的内容来规避检测。由于PDF 文档自身格式和内容易于增添而难于删除[17],特征加法攻击更易于生成可执行的对抗文档。
1.3 模型鲁棒性
已有研究的检测模型绝大部分性能指标关注于检测率、准确率和误报率,而对于模型的鲁棒性考虑较少,模型对于对抗样本检测的效果也较差。高度健壮的模型[13]对于一个已知恶意文档,在不影响其恶意行为的前提下,无论对其增添或是删除其中一个或多个元素,都不会影响分类器的判定结论。
图1 展示了使用VirusTotal 病毒检测引擎检测一组恶意样本和对抗样本的结果。VirusTotal 系统中有39个杀毒引擎检测出了恶意样本,而只有8个杀毒引擎检测出了对抗样本。说明即使是目前先进的在线检测系统,也易遭受对抗样本的影响。

图1 恶意样本和对抗样本VirusTotal 检测结果
提升模型鲁棒性的方法主要有: 一是利用特征工程[2,16],通过数学变换对特征进行组合,以增加各特征之间的相关性,使得即使攻击者对样本中的某一特征进行了修改,模型仍然可以通过相关特征检测到恶意文档;二是利用对抗训练[18-19],生成对抗样本对模型进行预训练,降低模型对未知对抗样本的误报率;三是利用集成学习[15],通过多个分类器进行决策,来减少对抗样本对单个模型产生的影响。
2 基于文档图结构和卷积神经网络的恶意PDF文档检测CNN-FGS
2.1 PDF 的文档格式
构成PDF 格式的语法主要包括四个元素[20]:
(1) 对 象: 构成PDF 的 基本元 素,如/ Catalog,/Page 等。
(2) 文件结构(也称物理结构): 指定了对象在PDF 文档中的布局和修改方式。
(3) 文档结构(也称逻辑结构): 决定了对象在逻辑上是如何组织起来,以呈现文档的内容。
(4) 内容流: 提供了一种高效存储文件内容各部分的方法。
PDF 文档的部分原始内容如图2 所示。

图2 PDF 文档的原始内容
PDF 文档结构常以/Catalog标签为根节点,根据引用对象号指向子对象节点,以此层层递进直到没有引用对象号,即到达叶子节点,最后形成的树或森林结构如图3 所示。PDF各对象之间通过引用关系相互联系,因此其逻辑结构较文档的原始内容更为复杂,但同时也表达了大量的文档语义,如是否存在某些对象,以及对象间的引用关系等。这些语义信息对于综合判断文档的行为具有重要的作用。

图3 PDF 结构树
文档的图结构特征包含了大量的文档语义,通过结构路径能反映出该部分的功能。相比起孤立的词袋模型特征,作为特征输入的图的拉普拉斯矩阵,每个元素之间都是相互联系的,不容易被篡改。基于上述思想,本文提出一种基于文档图结构的恶意PDF 文档检测方法,解决了特征间孤立的问题,提高了攻击者的成本,提升了检测模型的鲁棒性。
2.2 检测框架
CNN-FGS 检测方法的整体框架如图4 所示。

图4 CNN-FGS 检测方法的整体框架
结构路径生成模块使用PeePDF[21]对PDF 文件进行结构解析得到各对象的调用关系。PDF 文档的数据集可以表示为F={(f1,l1),(f2,l2),…,(fN,lN)};fi表示单个文件的拉普拉斯矩阵;li∈{0,1} 表示样本标签,0 表示良性文件,1 表示恶意文件。根据各对象的调用关系,通过深度优先搜索(Depth First Search,DFS) 算法得到文档的所有结构路径,并得到图的多条边。
图精简模块使用TF-IDF 算法对所有节点进行分类重要性排序,保留总重要性影响超过99% 的节点,对剩下1% 的节点进行合并,以实现图精简。
特征提取模块使用Python 的networkx 库构造文档的图结构,计算图的邻接矩阵和度矩阵,并求得拉普拉斯矩阵作为训练特征。
学习检测模块基于CNN 模型对特征学习检测,并进行模型评价。
对抗训练模块采用基于特征加法的攻击方式生成对抗样本,对模型效果进行检验,并对模型进行再训练,提升模型的鲁棒性。
2.2.1 结构路径生成模块
本方法通过PeePDF 工具分析提取文档对象的引用关系,如图5 所示。它的每一行按照引用的先后顺序排列,不同的缩进表示不同的父子关系。

图5 PDF 文档对象的引用关系
为了更好地分析对象间引用关系来得到文档的逻辑结构,本文作如下规定: 以缩进数判断父子关系,相邻两行节点的缩进差为上一行缩进数减去下一行的缩进数;将第一行缩进数小的对象视作父节点,将缩进数大的节点视作子节点。即缩进数最小的对象为根节点,缩进数最大的对象为叶节点;若相邻两行缩进差为-1,则两节点存在父子关系,上一行的节点是下一行节点的父亲。若相邻两行缩进差为0,则两节点共享父节点;若相邻两行缩进差为1,则上一行节点的父亲节点是下一行的兄弟节点,即上一行节点的父节点的父节点是下一行节点的父节点。根据以上规则,使用DFS 算法遍历得到文档的结构路径的集合,如图6 所示。

图6 PDF 文档的结构路径
2.2.2 图精简模块
在结构路径生成模块已得到各文档的结构路径集合,首先对所有文档中出现的对象进行统计,使用十六进制编号表示,并对冗余对象合并以精简图。例如/Bullet 元对象在文档中出现了9 种不同的近似对象(如/Bullet_1,/Bullet_2,/Bullet_Last,/Bullet v2等),这些近似对象都起到了与元对象相同的功能,对这些对象进行冗余合并,不会对分析文档结构具有太大的影响。经遍历统计数据集中所有文档中的结构路径共提取得到672个对象,冗余合并后得到213个元对象。
使用TF-IDF 算法计算213个元对象对分类的贡献度。计算公式如下:


其中ni,j表示对象oi在PDF 文档fj中出现的次数,表示所有对象出现的总次数,|D |表示样本集的数量,|j:oi∈fj| 表示包含对象oi的文档数量。
计算各对象的贡献度并作图7 如下,可以看出有超过一半的对象对分类的贡献度不足0.01 。经统计如图8 所示,贡献度排名前73 类对象的总贡献占比达到了99%,说明前73 类对象对分类判定的重要性更大。虽然剩下的140 类对象只占了1%,但是对分类还是有一定的影响,因此不能直接将其抛弃,考虑将剩下140 类对象合并为一类。图精简模块最后生成了74 类对象,实现了特征降维,有助于提升模型效率,并缓解特征维度过高导致可能出现的过拟合问题。

图7 各对象的TF-IDF 贡献度

图8 对象贡献度占比变化曲线图
2.2.3 特征提取模块
以精简后的74 类对象为字典,将先前得到的结构路径集合一一对应得到文档图结构的边集。然后,利用networkx 模块生成文档的图结构,如图9所示。

图9 文档图结构
将图转化为邻接矩阵的形式,邻接矩阵反映了图中各节点之间的相邻关系,记作A 。

将图转化为度矩阵的形式,度矩阵对角线上的元素是各个顶点的度,表示和该顶点相关联的边的数量。度矩阵记作D :

拉普拉斯矩阵L 定义为:

拉普拉斯矩阵中的第i 行反映了第i个节点对其他节点的累积影响,相比图的邻接矩阵包含了更多的信息,也更能表征文档的特征。
2.2.4 学习检测模块
本文提取的图的拉普拉斯矩阵特征与传统的PDF 检测模型提取的词袋特征有很大的不同。词袋模型的每个特征都是经过人工挑选且相对独立,而作为描述图的信息的拉普拉斯矩阵,其每一个元素都是相关联的,每一部分都影响了图的信息表达,特征的表征能力更强。将图像分类的深度学习方法迁移到PDF 文档分类中,通过CNN 模型能够更好地捕捉PDF 文档的图结构中相邻特征之间的局部关系。
本文使用的CNN 模型结构: 输入层是样本中提取得到的74×74 的拉普拉斯矩阵,然后使用1个二维卷积层对特征向量矩阵进行卷积操作。卷积层由8 ×4 的卷积核组成来挖掘特征空间里不同范围的特征向量所包含的隐藏信息,并选择最大值池化的方法将特征值整合,最后通过三层神经元分别为256 、64 、2 的全连接层输出得到结果。选取效果更好的ReLU 作为激活函数,减轻了参数之间的相互依赖关系。同时在池化层与全连接层之间加入了Dropout 层,起到减少特征冗余避免过拟合的发生。
2.2.5 对抗训练模块
本文通过比较嵌入正常文档后的恶意文档特征值发生的改变,发现所选取的第74 类特征在数值上发生了显著的变化。分析其中的原因,主要是因为图精简时,第74 类特征合并了其余大量TFIDF值较低的特征,这些特征在正常文档中大量存在。
针对模型的此类特点,定义本文中的特征加法攻击的攻击强度S 为: 在原有恶意文档的特征基础上,对抗样本的第74 类特征值与之前样本的倍数。本模块按照不同的特征强度S 参数,生成多组对抗样本特征以对模型进行对抗训练。
3 实验结果与分析
3.1 数据、平台和评价指标
本文实验环境为CPU Intel ® i7 - 9750H,32 GB内 存,GPU 为GTX2060,硬 盘 为120 GB SSD,使用Ubuntu16.04 操作系统。实验数据集中恶意PDF 文档来自于VirusTotal 病毒数据库以及Contagio 数据集[22],良性样本来源于Contagio 数据集。使用的良性样本数为9093个,恶意样本数为14570个,特征加法攻击样本2000个,统计样本数为25663个。
本文的分类模型使用了准确率Precision 、召回率Recall 和F - score 三个指标进行综合衡量,其计算方法如下:

式中TP 为真正例,FP 为假正例,TN 为真反例,FN为假反例。
3.2 检测性能测试
本文以9:1 的比例随机地将样本集划分为训练样本和测试样本。其中,良性样本的标签记为0,恶意样本的标签记为1 。
为测试CNN 分类模型的性能,选择了适用于图分类的机器学习分类方法KNN 、SVM 与CNN 进行比较,并作表2 如下,可以观察到CNN 分类模型在各指标上都较其他两类方法更好。

表2 三类分类器性能指标比较
为进一步评估本模型的性能,将结果与近年来所提出的其他模型进行对比,结果如表3 所示。因为PDFRate 和PJScan 作为在线训练模型已停止服务,所以只引用其结果作为参考。对比分析表明,本文提出的分类模型较其他方法在准确率和召回率等指标上都有所提升。

表3 各研究性能指标比较
3.3 抗攻击测试
为了研究本文分类模型的鲁棒性,实验选取基于特征加法攻击的对抗样本进行对抗训练及性能评估。
首先,本文按照特征强度参数S=2,3,4,5,10,15,20,30 分别生成了250个对抗样本特征,将其送入模型对抗训练,训练前后的检测结果如表4 所示。
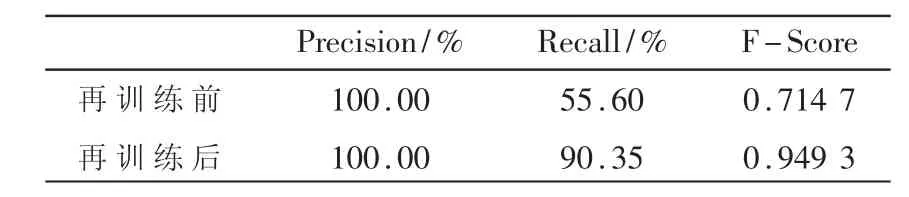
表4 对抗训练前后性能指标比较
训练前的模型对对抗样本的召回率较低,说明模型对恶意文档的识别能力不够,误将其分类为良性样本。对抗训练后,模型的召回率有了显著的提高。说明模型经过再训练,具备了一定的识别恶意对抗样本的能力,模型的F-score 指标也有所提高。
为了进一步研究对抗样本对模型性能的影响,本文通过Metasploit 制作了2000个嵌入正常文档的恶意对抗样本作为测试集来评估模型对抗训练后的性能(其攻击强度参数S 均大于20,文档的md5已上传github,可直接从VirusTotal 上检索到)。同时,将这批恶意对抗样本上传至VirusTotal 进行检测,统计所有杀毒引擎的检测结果及本文模型的检测率,如图10 所示。实验结果表明,对抗样本对VirusTotal 中的杀毒引擎影响较大,大部分杀毒引擎无法成功检测。而本文提出的模型对这批恶意对抗样本达到了98.86% 的检测率。

图10 本文模型与各杀毒引擎检测率比较
4 结论
针对基于机器学习的PDF 恶意文档检测方法存在依赖专家经验遴选特征、表征能力差等问题,本文提出了一种基于文档图结构和CNN 的恶意PDF文档检测方法,通过分析文档的逻辑结构,生成文档的图结构,以图结构的拉普拉斯矩阵作为特征送入分类器进行训练。图结构特征较前人研究特征表征能力更强,经过对抗训练后,模型的鲁棒性更强。生成基于特征加法攻击的对抗样本,通过比较本模型和VirusTotal 对该样本集的检测性能,结果表明本模型性能超过了VirusTotal 上的67 款杀毒引擎。
猜你喜欢
客联(2022年3期)2022-05-31
湖南税务高等专科学校学报(2021年4期)2021-08-30
中国新闻周刊(2021年26期)2021-07-27
意林(2018年3期)2018-03-02
信息安全研究(2016年4期)2016-12-01
厦门理工学院学报(2016年1期)2016-12-01
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
南都周刊(2015年4期)2015-09-10
