
安卓平台上基于卷积神经网络的跌倒检测研究 *
2021-11-23 03:52刘攸实戴安琪刘毅飞
湖北科技学院学报 2021年5期
刘攸实,戴安琪,徐 慧,刘毅飞
(湖北科技学院 生物医学工程学院,湖北 咸宁 437100)
在65岁以上的老年人中,跌倒是老年人因伤致死的主要因素[1],因此如何准确检测老年人是否跌倒成为近些年的研究热点。现有的跌倒检测方式主要有两类:一是基于计算机视觉的跌倒检测,这种方法用多个摄像头对目标进行监测并判断是否跌倒,但存在侵犯个人隐私且检测对象容易被遮挡[2]。另外一种则是由运动传感器进行数据采集,再根据特定的算法判断是否跌倒,这种方法检测精度较高,在日常生活中使用方便[3]。因为智能手机一般都有运动传感器,且具有发送信息和定位功能,许多研究者也直接用智能手机进行跌倒检测,如Sposar等人[4]提出根据Android手机的内置三轴加速度计采集的数据用阈值法来检测跌倒。另外基于深度学习的卷积神经网络在模式分类和识别领域表现出优异的性能, He[5]、Liu[6]等人在服务器上运行卷积神经网络作为跌倒检测服务端,检测精度接近100%。
但目前很少有基于安卓手机平台的卷积神经网络跌倒检测系统的研究。本文将PC机上的跌倒检测卷积神经网络移植到安卓手机平台,可以直接使用手机的运动传感器和数据通信功能还可以提高跌倒检测的精度,另外现代手机通常包含图形处理器(GPU),在GPU上运行深度学习模型进行跌倒检测具有速度快,功耗低优点[7],本文同时研究在GPU上运行卷积神经网络进行跌倒检测的性能。
一、方法
1.数据集
根据Gia等人[8]对可穿戴式传感器位置的研究表明,人腰部及其以上部位运动范围较小,更适合采集人在运动过程中的加速度和角速度数据,基于Gia等人的研究,本文的研究是将手机横向放置在人的腰部,如图1所示并建立三维空间坐标系X、Y、Z轴,其中ax、ay、az分别对应轴的加速度,ωx、ωy、ωz分别为对应轴的角速度。
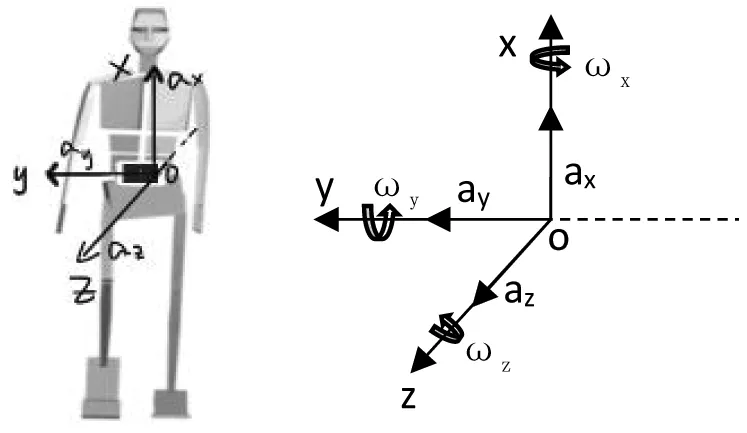
图1 运动时坐标图
本实验跌倒检测的数据集来自MobiFall[9]和SisFall[10],按照图1的坐标系进行提取和变换,以确保与实际应用时坐标一致,因为人的运动坐标系X、Y、Z轴可以被视为RGB图像的三个通道,对应轴的加速度和角速度的值可以分别映射到RGB图像中的RGB三个通道, 并按照各自的取值范围变换到0~255之间。因为三轴传感器数据集的采样频率为100 Hz,每个跌倒过程通常在两秒种内完成,这样检测时间窗对应的数据可以通过以上方法变换为20×20像素的RGB空间图像,最后总共提取8 000组样本图像数据作为本文的数据集,其中跌倒的样本为981例, 其他日常活动状态样本为7 019例, 具体的过程可以参考文献[5]。
2.跌倒检测卷积神经网络结构
我们用于跌倒检测的卷积神经网络由两个卷积层、两个下采样层、一个flatten层和两个全连接层组成,具体的网络结构如图2所示。样本数据为20*20的RGB图像,首先对每个像素值进行归一化处理作为网络的输入,最后输出层有10个神经元进行全连接,采用Softmax激活函数计算10种分类结果的概率,这10类分别对应于人类日常活动的各种状态:跌倒、步行、坐下、起立等,最后选取概率最大的分类作为预测结果,在本文研究中区分了各种非跌倒状态,在实际应用中最后一个全连接层输出维度可以改为2,也就是对应于跌倒和非跌倒两种状态。
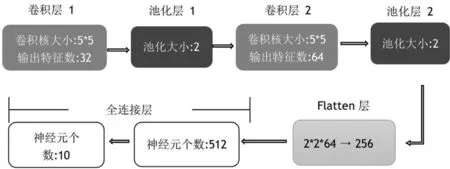
图2 跌倒检测卷积神经网络结构
3.跌倒检测卷积神经网络训练
数据集按照6:2:2的比例随机抽取并进行归一化后作为跌倒检测神经网络深度学习时的训练、验证、测试数据集。深度学习采用Keras和Tensorflow框架,选择随机梯度下降(SGD)作为优化器和categorical_crossentropy作为损失函数,训练时的学习率设置为0.01,批处理大小为64,整个训练过程中的跌倒检测精度和损失变化如图3、图4所示:当迭代次数超过10次时跌倒检测精度超过90%,随着迭代次数的增加,训练精度趋于稳定,最终训练的迭代次数选择100次。
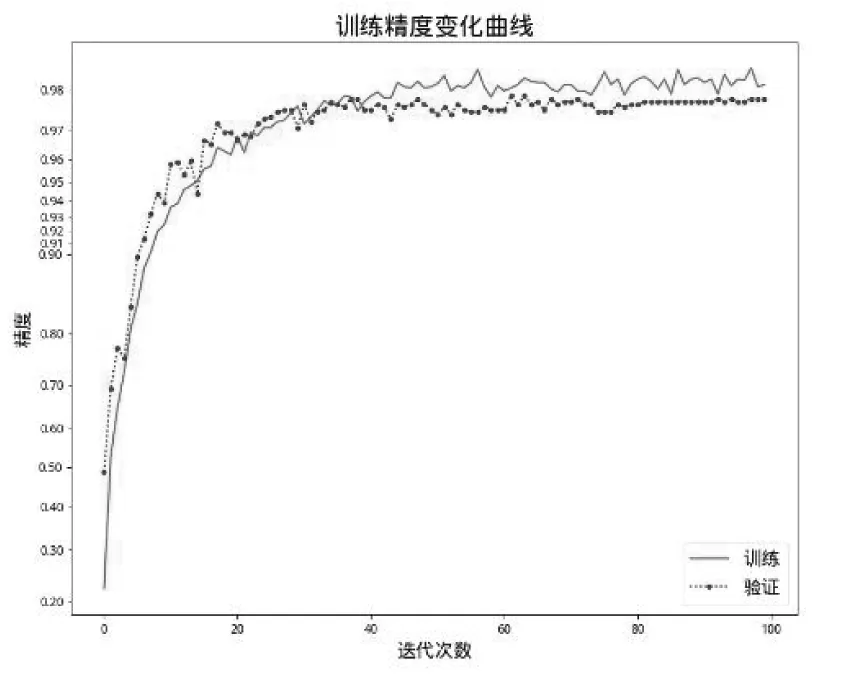
图3 训练时跌倒检测精度变化曲线
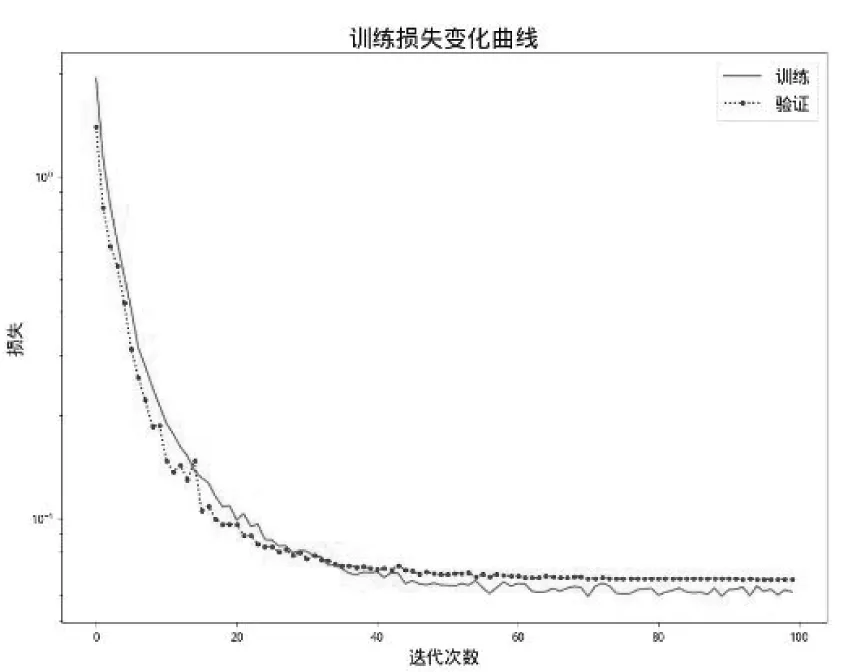
图4 训练时跌倒检测损失变化曲线
当测试精度符合要求后,将训练好的Keras模型转换为TensorFlow Lite模型,另外因为安卓平台GPU上的卷积神经网络CNNdroid模型需要PC机的Caffe模型,我们按照前文中提到的神经网络结构和神经网络训练参数采用Caffe深度学习框架重写并重新训练获取。
4.安卓手机平台上的卷积神经网络跌倒检测
近年来,因为移动处理器运算能力的提高使得在安卓平台上运行深度神经网络成为可能。 另外安卓平台通常配备高性能的GPU用于高性能的图像和视频处理, GPU包含流处理器支持并行计算的特点使得在安卓手机平台上可以更低功耗运行卷积神经网络。但是由于桌面和移动端体系结构不同,在桌面和服务器上支持卷积神经网络在GPU进行并行计算的深度学习框架Caffe、Theano、Tensorflow等并不能直接移植到Android移动端。除了TensorFlow Lite支持Tensorflow模型运行于移动端的GPU, Oskouei等[11]基于OpenGL ES研究并开发了一个开源库CNNdroid,它支持将训练过的卷积神经网络运行于移动安卓平台GPU上,和移动CPU上运行卷积神经网络相比达到加速和降低功耗的目的,目前CNNdroid支持Caffe、Torch和Theano等模型。
本文将前文中训练好的跌倒检测卷积神经网络通过TensorFlow Lite和CNNdroid移植到安卓手机平台上,其中TensorFlow Lite支持卷积神经网络在CPU和GPU上运行,CNNdroid支持在GPU上运行。
二、 结果及分析
为了评估卷积神经网络在安卓手机平台上跌倒检测的精度,采用随机的训练集在Tensorflow和Caffe上分别训练十次,训练好的跌倒检测卷积神经网络模型按文中的方法配置到安卓手机上进行测试,分别取Tensorflow和Caffe模型十次测试的平均值再平均作为测试结果,结果表明运行于安卓手机平台的卷积神经网络所有日常活动状态检测的精度为97.70%,其中跌倒检测的敏感性(跌倒状态正确检测为跌倒的比例,真阳性)为99.18%,特异性(非跌倒状态正确检测为非跌倒的比例,真阴性)为98.77%。
跌倒检测除了检测精度要达到要求,还需要符合其实时性的需求,也就是需要评估跌倒神经网络的检测时间以保证系统能对跌倒作出及时检测。我们用CNNdroid、Tensorflow Lite CPU和Tensorflow Lite GPU三种方式检测同一跌倒检测的神经网络运行在不同安卓手机平台的CPU和GPU上所用的时间, 实验采用的手机型号及其CPU和GPU配置如表1所示,实验环境是在手机有电状态下,将亮度调到最低并开启飞行模式,测试结果取10次运行的平均值,在不同型号手机的CPU和GPU上不同方法跌倒检测所用的时间如表2所示,实验结果表明采用单个跌倒数据集样本输入时,Tensorflow Lite 模型在CPU上跌倒检测所用时间最短,原因一是因为跌倒神经网络结构无需很复杂也就不能充分体现出GPU并行运算能力,另外一个原因是工作时CPU频率远高于GPU频率,但如果从功耗的角度考虑,可以采用Tensorflow Lite GPU方法检测跌倒功耗更低。
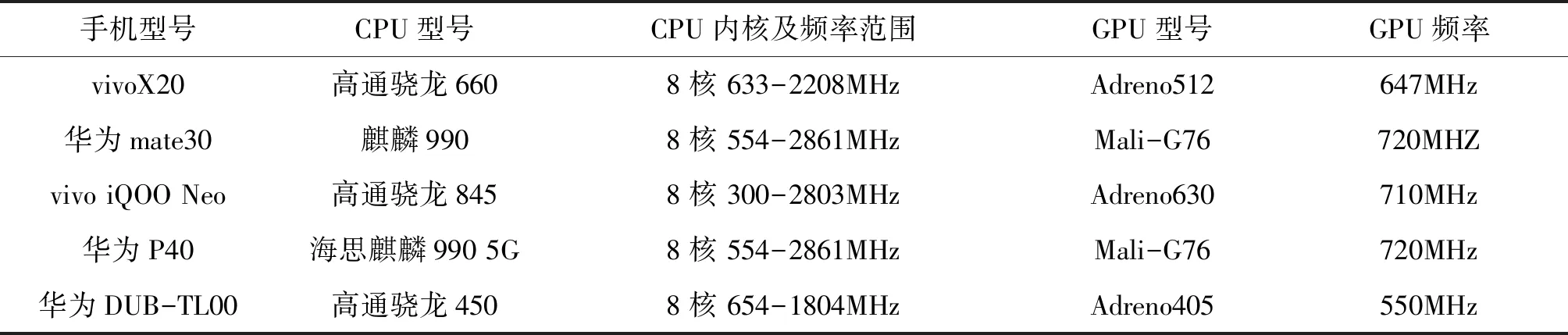
表1 不同型号手机的CPU和GPU配置对比
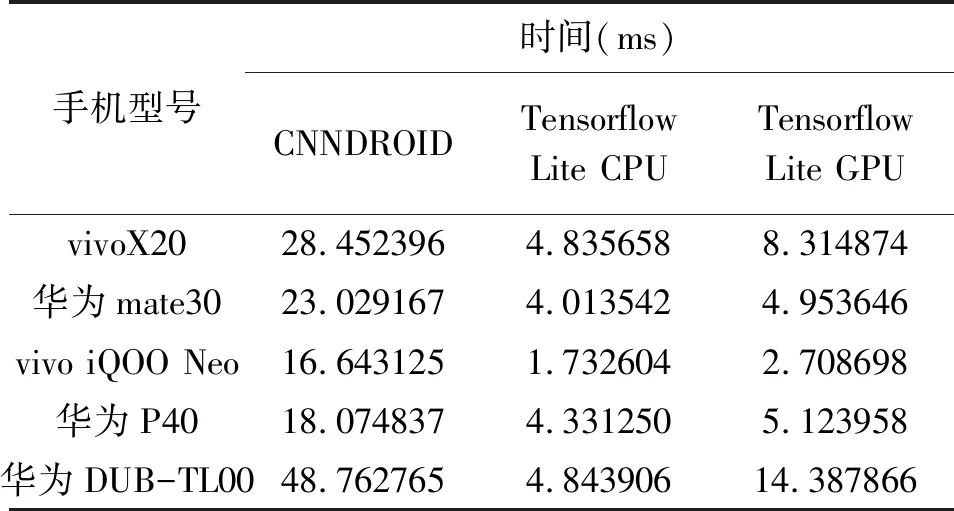
表2 单个数据输入时卷积神经网络跌倒检测时间对比
当批量输入数据集样本时, 批量输入的样本数可以表示活动状态下运动传感器数据采集终端的数量, 这样就可以评价将安卓手机平台作为移动跌倒检测服务平台的计算性能。我们在vivoX20手机测量了不同批量输入样本时卷积神经网络跌倒检测时间,实验结果如表3所示, 结果表明当批量输入样本数较少时可以采用CNNDROID方法进行跌倒检测, 当批量输入样本数较大时,可以采用Tensorflow Lite方法用于跌倒检测。

表3 批量输入时卷积神经网络跌倒检测时间比较
在表2和表3的实验仅仅是一次数据输入卷积神经网络跌倒检测时间,但是从运动传感器中输出的是数据流,当采样频率为100Hz时,如果采用连续时间窗,每一个数据间隔为10ms,这样从实验结果看安卓平台上的卷积神经网络用于跌倒检测只能采用表2的Tensorflow Lite方案,但在实际应用时为了降低功耗和对处理器处理能力的需求,通常采取如图5所示的覆盖,跳跃时间窗方法,如果采取50%的窗口覆盖率, 和本文实验2s的时间窗, 每一个数据采样间隔可以为1s, 这样卷积神经网络进行批量跌倒检测的时间符合作为多人跌倒监控服务端的要求。
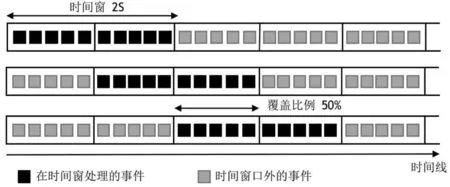
图5 数据流覆盖,跳跃时间窗图
三、 结论及展望
本文在安卓平台上分别采用CNNdroid和Tensorflow Lite CPU以及Tensorflow Lite GPU三种方法利用卷积神经网络完成了跌倒检测,并采用跌倒数据集对跌倒检测神经网络的性能进行了评估。实验结果表明采用卷积神经网络进行跌倒检测精度高,在安卓平台上不管是采用GPU还是CPU方案都能及时检测出跌倒, 如果采用覆盖,跳跃时间窗数据采样方法, 本文的研究还可以作为移动服务终端为多人提供跌倒检测服务。本研究和基于计算机视觉的跌倒检测相比具有检测精度高,数据采集方便,受环境影响小的优点,和非采用神经网络的运动传感器跌倒检测算法相比,利用安卓平台强大的运算功能运行卷积神经网络提高了跌倒检测的准确率,并且可以同时使用安卓系统的发送信息和定位功能对跌倒进行报警,具有较大的应用价值。
后续可以在两方面继续开展研究:(1)本文运动传感器的坐标轴是固定的方向,但在实际应用中由于坐标的偏差会使已经训练好的神经网络检测精度降低,如何提高神经网络的鲁棒性以适应实际应用环境需要进一步研究。(2)作为移动平台,功耗问题始终是一个关注的焦点问题。除了将数据采集任务分离给低功耗的前端,并且采取简单的阈值法在前端进行预判断,只有当有可能是跌倒时才将数据传给安卓上的卷积神经网络进行精确检测之外,在安卓平台则可以采取进一步优化神经网络结构并在GPU上运行神经网络降低系统功耗。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
消费电子(2022年6期)2022-08-25
一重技术(2021年5期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
少年文艺·开心阅读作文(2019年8期)2019-09-12
电子制作(2019年11期)2019-07-04
汽车观察(2019年2期)2019-03-15
华人时刊(2016年16期)2016-04-05
