
企业股权关系数据价值挖掘的研究报告
2021-11-20 02:18:28陈力交通银行股份有限公司
环球市场 2021年30期
陈力 交通银行股份有限公司
企业股权数据中蕴含着巨大的业务价值,而充分利用该部分数据价值不仅需要合理的数据分析步骤,还需要相应的技术手段。从数据清洗、图谱构造到最后的数据价值分析,一步步环环相扣,我们结合图数据库找到了一条挖掘企业股权数据价值的可行路径,并以实际案例进行有效的实践。
一、数据研究及方案制定
一般对于股权信息最基本的要求是有公司信息、股东信息以及股东持股比例,其中公司信息和股东信息包含的最小要素为企业名称和组织机构代码(或统一社会征信码)。
股权关系我们可以看作是公司主体作为实体的关系信息,即我们如果把股权关系进行抽象,可以获取的是代表公司主体的点,以及代表股权关系的边。而这些点和边最终组成了图,也就形成了我们最终数据需要存储的形式和展现的形式。
在此我们利用图数据库进行相关关系的分析与解析,并制定出数据实施方案,见图1:

图1
数据清洗旨在从原始的股权关系数据中提取中构造图谱的关键信息;图谱构造则是通过提取出的关键信息,抽象成点和边的形式,以图的方式存储这些关键信息;价值分析,则基于构建的图谱实现业务价值的提取分析。
二、数据清洗
(一)股东代码空值填充
有部分股东代码数值为空,因此我们需要补充这部分股东代码,鉴于股东代码在实际应用中仅起到区分不同股东的作用,因此我们采用简易的编码规则,即GD+5位序号的方式进行编码,实际生产应用时可根据相应使用场景进行调整。
(二)最新数据切片构造
实际应用股权关系数据时,我们最为关心的是当前各家企业的股权关系,因此其中需要有效过滤掉历史数据,而对于历史数据的判断,可通过以下两步实施:
第一步,历史数据的筛选,即同一公司代码+股东代码的组合,获取最新更新日期更大、出资时间更晚的数据,最后一个公司代码+股东代码只保留一条数据记录。
第二步,股权变更流程回溯,基于以下2个字段:最新更新日期、出资时间。将上述字段分别按照倒序排列,即优先排列最新更新日期最大的数据,然后优先排列出资时间更晚的数据,排除掉多余的数据直至该公司所有的股权持有比例之和不超过100%。
最后需要达到的数据目标为:1.一组公司代码+股东代码的组合对应一条数据记录;2.每一个公司所有的股东持股比例不超过100%。
(三)持股比例空值填充
填充持股比例为空值的数据,思路如下:对于某一家公司,将已知的股东信息相加,而后将剩余的持股比例由未知持股比例的股东平均瓜分。
例如某公司的持股比例空值应当为100%去除已知持股比例数37.98%,若其有2家持股比例未知的公司,则另两家持股比例为(100%-37.98%)/2=31.01%。
三、图谱构造
在完成数据清洗之后,我们获取了一份表格形式存储的企业股权关系数据。但是以表为形式存储对于股权关系分析的应用有以下局限:
1.数据可视化制作困难,无法完整地呈现某一家企业的上下游关联关系,对于股权层层穿透的情况分析效率较低;
2.对于图谱深度解析的需求,分析程序编写困难,执行效率不足,该情况主要出现在企业风险传播分析、高风险股权结构分析、高风险担保结构分析的应用场景中。
在该背景下,我们引入图数据库,将传统关系型数据库中的数据,装载到图数据库中,来提高我们数据分析过程中提到的上述瓶颈。
(一)图数据库介绍
图数据库中的“图”,并不是指图片,而是以图这种数据结构存储和查询数据。
而市面上的图数据库有两种,一种是原生图数据库,即数据存储在自己本身的图数据库体系内;另一种是非原生图数据库,数据本身不存储在图数据库的框架体系内,而是存储在别的数据库中(一般为关系型数据库);而经过比较前者的效率更高[1]。
图数据库的性能评估包含两个重要的因素,一个是图存储,还有一个是图处理引擎。图的存储方式与传统的关系型数据库区别非常大,他是专门为存储和管理图而设计的,而图处理引擎更是关系型数据库所不具备的,这也是为什么图数据库在处理图谱数据时效率更高的原因[2]。
(二)装载方案
图数据库顾名思义就是将数据以“图”的形式存储在计算机中,而图具有的最基本的要素就是边和点,因此我们要将我们上一节清洗完的数据抽象成边和点。
我们使用到的数据中“公司”和“股东”都可以归类为标签为“公司”的节点,由于是股权关系表,关系可以归类为“股权”关系。“公司名称”是节点的属性,持股比例是“股权”关系的属性。
(三)方案实施
将表格数据装载入图数据库是一个比较关键的步骤,在装载是需要制定合理的方案,保证数据装载稳定且高效。因此我们使用批量加载的方法,同时用下列步骤进行数据导入:
第一步导入节点;
导入节点分批量导入和非批量导入,我们可以看一下两者的区别:
非批量导入过程为,将一条数据写入内存,然后将内存中的数据写入磁盘,周而复始;批量导入的过程为,将多条数据写入内存,而后批量将数据写入磁盘。我们发现批量导入大大降低了磁盘读写的次数,因此会有效地提升数据加载效率。
而实际的过程中我们会将所有数据分成若干个小批次进行操作,这样既可以减少磁盘读写的次数,同时也可以避免内存使用比例过高导致的性能下降。
第二步为关系关联属性(公司代码)加上索引;
加入索引的重要原因是提升数据库读取效率,经过性能测试,在关联属性上建立索引和不建立索引,前者的效率比后者有极大的提升。
第三步导入关系数据;导入关系数据,我们同样使用分小批次导入的方法来实现,来保证数据导入的效率。
四、数据价值分析
图数据库之于图谱分析,其优势除了在数据可视化上,还能充分挖掘企业间关系的业务价值。我们以以下两个场景进行举例:
(一)股权穿透分析
我们以某上市公司为例,下简称“A公司”,分析该主体如果发生负面事件,波及的范围。以该节点为出发点,向下穿透5层,可获得如图2:
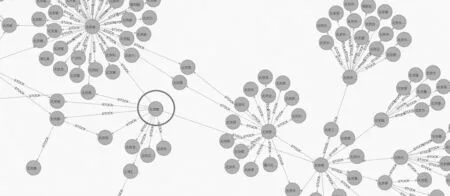
图2
大圈中的“A公司”对外的股权非常复杂,牵涉的企业面积非常广。所有涉及的企业都会或多或少因该企业的风险事件而受到负面影响。
传统的关系型数据库在搜索多层关系时,需要多次访问数据库表,为提升执行效率并且降低程序以外执行失败的概率,会以数据库事务的形式编写,代码编写复杂度较高。图数据库的可视化功能也要比关系型数据库更强,而在图处理的能力上也较关系型数据库更强。
(二)企业股权关联分析
在进行业务分析时,我们经常会发现,两家看似毫无关联的企业,却有着千丝万缕的联系。例如图3左大圈中的“A公司”与右大圈中的“B公司”,这两家公司,从名字上分析除了可以得出两家公司都涉及相同的行业,似乎毫无关联信息。但我们查询一下这两家企业的关联关系,我们会发现,两家企业有着一定的关联,其股权关联如图3:
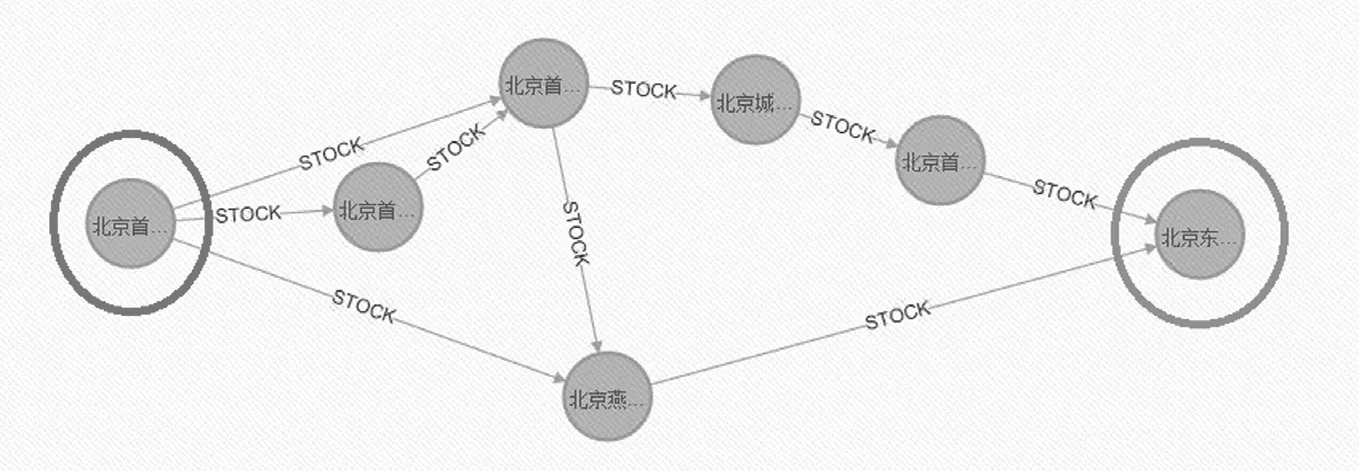
图3
同时,可以根据股权关系中的持有份额比例,通过各条路径的乘积之和来计算“A公司”对“B公司”的实际控制份额。
实现上述功能,通过关系型数据库,我们不仅要多次访问数据库,同时还要使用递归,代码实现难度比较大,而图数据库只需要执行指令,匹配起始节点与重点,即可自动搜索出所有的路径,大大降低了程序编写的难度,并且提升了执行效率。
图3展示了图据库以表格结合数组的形式展示开始节点到结束节点的所有路径,将这路径中的权重值相乘最后再相加,我们即可获得最后开始节点对结束节点的实际控制份额。
图3我们能找到5条从A公司出发,B公司结束的路径。
路径1:
[{"percentage":50.0},{"percentage":40.0}]
路径2:
[{"percentage":47.12},{"percentage":100.0},{"percentage":96.875},{"percentage":11.0}]
路径3:
[{"percentage":47.12},{"percentage":50.0},{"percentage":40.0}]
路径4:
[{"percentage":100.0},{"percentage":5.53},{"percentage":100.0},{"percentage":96.875},{"percentage":11.0}]
路径5:
[{"percentage":100.0},{"percentage":5.53},{"percentage":50.0},{"percentage":40.0}]
最后我们根据计算各条路径中持股比例的乘积,最后加总得知A公司对B公司的实际控制份额为36.14%。
五、总结
企业股权数据中蕴含着巨大的业务价值,而充分利用该部分数据价值不仅需要合理的数据分析步骤,还需要相应的技术手段。而图数据库在图谱分析的过程中提升了效率,简化了代码,通过业务实施步骤的合理规划,以及技术流水线的合理部署,提升数据分析能力,真正做到为业务赋能。
猜你喜欢
少先队活动(2020年12期)2021-01-14 01:47:40
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
现代营销(创富信息版)(2018年10期)2018-10-12 03:01:36
中成药(2017年3期)2017-05-17 06:09:01
甘肃农业(2017年3期)2017-04-22 08:24:18
领导科学论坛(2016年9期)2016-06-05 14:59:58
创业家(2015年7期)2015-02-27 07:54:18
