
虚拟化网络中的异常大数据剔除算法仿真
2021-11-19 11:15:36李军华丁宪成
计算机仿真 2021年10期
李军华,丁宪成
(1.江苏理工学院,江苏 常州 213001;2.常州大学,江苏 常州 213016)
1 引言
将两个没有任何物理连接的计算机,通过网络的虚拟技术进行连接,从而形成一种至少包含两个部分的计算机网络,被称为虚拟化网络,其中最常见的虚拟化网络,它们分别为:以协议模式所生成的虚拟化网络,例如:虚拟专用局域网业务(VirtualPrivateLanService,VPLS)、虚拟专用网络(Virtual Private Network,VPN)与虚拟局域网(Virtual Local Area Network,VLAN);虚拟化设备,例如:在虚拟机监视器(Virtual Machine Monitor,VMM)内部连接虚拟机。
经过互联网的快速发展,虚拟化网络也随之产生变化,其不足点在于:一VLAN技术没有办法在云计算内使用;二融合数据需要重新定位工作的范围;三虚拟交换机,为新的虚拟工作负载;四虚拟化网络服务的蔓延。要想实现这些功能,必不可少地需要与大数据相结合,以大数据作为支撑,从而实现虚拟化网络的发展。但是大数据的数据量庞大,其中不乏存在一些异常数据,导致网络运行过程中出现错误,所以需要对这些数据进行检测、剔除。
文献[1]构建起始拟合数据,通过B样条曲线方法建立递推模型,采用基于样条平滑的方法计算判断门限对于双向检验的结果,观察数据是否存在异常,同时对满足修复条件的数据实现拟合修复,当双向检验结果不同时,利用构建的内推模型,实现进一步的检验。文献[2]采用长基线定位野值点法实现数据的修正,利用卡尔曼绝对值数据作为标准,以此完成对数据的检测,通过调整卡尔曼的滤波转变成野值点的修正值,考虑到滤波模型实际应用时不匹配的状态,会导致滤波前后数据信息的偏差比较大,因此,对不正常数据点进行处理,完成数据剔除。
上述方法虽然能够实现数据剔除,不过剔除效果不够理想,误剔除数据较多,为此本文提出一种虚拟化网络中的异常大数据剔除算法,通过事先对异常数据进行挖掘、检测,最后利用粒子群优化以及支持向量机完成剔除,以此可以减少误操作带来的影响。
2 虚拟化网络中异常大数据挖掘
2.1 数据类似度分析
要想实现虚拟化网络内的异常大数据挖掘,需要对网络中的异常大数据进行类似度分析,通过分类决策树C实现异常大数据的类似度分解[3]。再对异常大数据的混合属性以及分类属性进行识别,构建混合属性的分类模型,同时,利用数据属性的类似度进行分析,求出模糊属性集X的奇异值,具体公式为
X=UDVT
(1)

(2)
式中:psp(si,qj)代表冗余数据的概念集qj以及自身概念集si,即异常簇中的数据信息,其模型为[s,q]=[x(t),x(t+τ)],可以计算出模糊信息的闭频繁项,s表示取样信息流x(t)的序列样本,q代表延迟时间样本,延迟序列是x(t+τ),I(Q,S)通过τ代表模糊决策函数的自变量[4]。
(3)
式中:d代表数据集中的类别标签,λ代表数据之间的原始类似度,h2代表簇与簇之间的距离,a2代表簇中心群。
通过大数据不同属性处于不同聚类内的差异性,从而识别异常数据,具体获得的精确概率密度函数公式为
(4)
式中:λS代表数据采集的类似度系数,p2D代表簇内的信息分布密度。具体异常大数据的相异度公式为:
(5)
式中:Dis(A)代表聚类过程扩展的损失,Dis(B)代表属性的数据集。
2.2 网络异常大数据属性特征提取
以虚拟化网络异常大数据的类似度分析结果作为基础,提取分类特征以及数值特征[5]。如果X代表存在m个分类的异常大数据集,那么第i个数值的异常大数据y(k)以及分类训练的数据集φ(k),具体公式为
y(k)=s1(k)+n1(k),φ(k)=s2(k)+n2(k)
(6)
s1(k)=AAHej(Ωk+θH),s2(k)=AAHej(Ωk+θHB)
(7)
式中:AH,AHB以及θH、θHB分别代表函数H(z)与HB(z)相应的幅值以及属性特征量、p个元素的属性值。将其与目标方法的最小化进行结合,实现寻优条件,就可以获得分类以及数值的特征集合,具体可以得到公式
RβX=U{E∈U/R|c(E,X)≤β}
(8)
RβX=U{E∈U/R|c(E,X)≤1-β}
(9)
相对于第i个分类的属性两个数据块mi以及mj,利用分解数据的对象mi,j(1≤i≤n,1≤j≤k)即可实现混合特征,聚类特征系数能够表示为{λi:1≤i≤S},而判别准则能够表示为{λj:1≤j≤L}。通过异常大数据的分类差异性,可以获得训练函数f与dγ0之间的模糊概念集[6],具体公式为
(10)

采用关联规则的分析法,融合异常大数据模糊集,求出异常大数据的自相关特征分块函数,可以得到具体公式为
(11)
(12)
Si=Sb+Sω
(13)
式中:p(ωi)代表离散区间内的规则向量集,u=E(x)代表数据的离散区间数。
利用归一化方法,对异常大数据的关联规则模型X(t)进行处理,获得全新的聚类模态函数,具体公式为
(14)
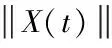
3 异常大数据剔除
3.1 数据冗余过滤
由于在异常数据挖掘过程中会将所有的异常数据挖掘出来,不管是无用的冗余数据,还是有用数据,都要对其进行冗余处理。在进行冗余过滤的过程中,通过测量数据间的接近度验证虚拟化网络数据,把网络内的节点数据作为一个集合,同时利用模糊集合间的接近度,设定冗余数据的判定门限值,从而确认网络内的冗余信息,并且进行滤除[8]。步骤如下:
如果ai′表示虚拟化网络中节点Wi′所测得的数据,aj′表示虚拟化网络中的节点Wj′所测得的数据,ai′j′表示虚拟化网络中的节点Wi′以及Wj′所测得的数据间接近程度。具体ai′j′的计算公式为
(15)
式中:μ代表一个阈值,该阈值为虚拟化网络中传感器的测量精度对大数据类似度的影响。
通过式(16)能够构建虚拟化网络中的大数据接近度矩阵A′,具体公式为
(16)
式中:N表示矩阵的元素个数。
基于式(16)内的A′第i′行元素,设置行间数据的类似度函数公式为
(17)
式中:Ki′数值越大,则说明第i′个虚拟化网络中节点测得的异常数据与多数测得的数据类似度越接近,相反,第i′个虚拟化网络中节点测得的异常数据与多数测得的数据类似度相差就越大[9]。
通过式(17)进行结果计算,能够获得虚拟化网络中所计算的冗余数据,如果v表示门限值,把Ki′>v类似度数据确认成被过滤掉的数据,标记成集合Q,若想将集合Q清除,那么具体公式为
(18)
式中:Ui′j′表示已将冗余数据清除之后的虚拟化网络数据集合,G(κ)表示冗余数据的过滤器[10]。
通过式(18)的计算,能够将虚拟化网络中的冗余大数据进行清除,以此为异常大数据的剔除提供了基础。
3.2 异常数据剔除
通过将冗余数据过滤之后,将其代入支持向量机以及粒子群优化算法内,即可剔除异常的大数据。在具体实现的过程内,对粒子群原始化参数进行设置,转变成二维的模式,以此表示支持向量机数值,然后训练粒子,得到适应度函数。即可得出粒子的最佳值以及全局数据,把二者相结合构建数据库,采用数据库就可以对所有粒子进行位置更新。以此对粒子的寻优条件进行判断,观察其能否满足结束条件。如果结果是采用最佳粒子所构建的虚拟化网络中异常大数据检测模型,那么即可检测出异常大数据,最后加入异常大数据的剔除窗口以及滑动窗口调整参数量,就能够实现异常大数据的剔除。
针对虚拟化网络中的异常大数据规模确认粒子群内的粒子个数,设置成m′,同时,设置粒子为二维模式,获得支持向量机的参数γ和σ。
通过支持向量机实现所有粒子的训练,从而获得粒子的适应度函数公式为
(19)
式中:F″表示粒子适应度的函数,k(x,xi″)表示核函数。
通过计算式(19)能够获得适应度的函数,从而得到粒子全局最佳值以及个体最佳值。具体公式为
P″bestxi″=(P″xi″1,P″xi″2,…,P″xi″e)
(20)
gbestxi″=(bg1,bg2,…,bge)
(21)
式中:P″bestxi″表示粒子个体的最佳值。gbestxi″表示粒子全局的最佳值。把粒子个体的最佳值以及全局的最佳值进行结合,从而建立数据库。
采用以上数据更新所有粒子位置,具体公式为
x(t′+1)=(P″bestxi″·gbestxi″)±β·m′best
(22)
式中:x(t′+1)表示粒子的位置,β表示调节粒子的寻优收敛速度,m′best表示粒子群的最佳中值。
在计算方法迭代至第t′次时,β的具体计算公式为
(23)
式中:t′max表示最大的迭代次数。
随着迭代的次数增加,对寻优的结束条件进行判断,在满足时,能够将最佳粒子作为支持向量机的最佳参数,建立最佳异常大数据的检测模型,可以得到具体公式为
(24)
式中:y(x)表示异常大数据的检测模型,采用此模型能够把虚拟化网络中的异常大数据检测出来,γ′和σ′代表支持向量机最佳参数,bestx表示最佳粒子。
通过计算式(24)的结果,能够检测出网络中的异常大数据,而具体的剔除方法公式为
(25)
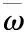
4 仿真证明
为了验证本文方法的异常大数据剔除效果,将本文方法与文献[1]、文献[2]方法在同一实验环境下进行对比,具体的实验环境为:主频CPU是Inter Core2 Dou E7400 2.80GHz、8GB的内存、带宽4M、硬盘500GB以及Xeone5型的服务器。
选择虚拟化网络内已知的大数据集作为实验数据条件,通过人为的方法添加10条异常数据,构成100000条。将所有的数据存储于节点内,然后经过多次实验,以节点形式划分为多个小组,观察效果,具体结果如图1所示:

图1 异常大数据剔除结果对比
通过观察图1(a)能够看出:异常大数据隐藏在虚拟化网络内,非均匀地分布于各个区域中,用黑色标记,以便于更好地观察剔除效果。图1(b)采用的是文献[1]方法,该方法仅能够对少量异常数据进行剔除。文献[2]方法剔除效果优于文献[1]方法,但是在实际应用过程中,仍然很难满足使用者的需求。而本文方法通过引入支持向量机以及粒子群优化算法,能够有效地剔除异常大数据,网络经剔除处理后无黑色节点,证明效果良好。
为了进一步验证本文方法的有效性,以误剔除率为实验指标,对比不同方法的剔除效果,结果如图2所示。
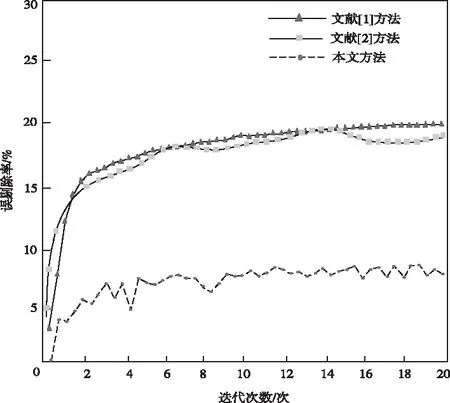
图2 误剔除率对比
分析图2可知,本文方法在虚拟化网络异常大数据剔除中,误剔除率明显低于传统方法。这是由于该方法通过决策树模型分解异常大数据的数值属性特征以及分类属性特征,可以更有针对性地对数据进行剔除,因此,降低了剔除过程中的误差。
5 结束语
本文提出的虚拟化网络中的异常大数据剔除算法,不仅能够有效剔除异常大数据,而且与其它方法对比误剔除率较低,具有可应用于虚拟化网络中的现实价值。不过随着网络发展速度的日新月异,用户量每天都在增加,同时数据量也在时刻地增加,所以,本文方法未来需要进一步的更新、优化,从而提升剔除的精度,加快剔除的时间,从而使其降低计算量,减少工作的时间。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
上海人大月刊(2022年4期)2022-04-14 08:20:49
作文通讯·初中版(2022年2期)2022-02-05 00:20:00
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
人大建设(2020年5期)2020-09-25 08:56:38
人大建设(2020年5期)2020-09-25 08:56:24
电子制作(2019年10期)2019-06-17 11:45:10
电子制作(2018年14期)2018-08-21 01:38:20
电子测试(2017年11期)2017-12-15 08:57:56
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
