
基于神经网络的复句判定及其关系识别研究
2021-11-18 02:18贾旭楠魏庭新曲维光顾彦慧周俊生
计算机工程 2021年11期
贾旭楠,魏庭新,曲维光,3,顾彦慧,周俊生
(1.南京师范大学 计算机科学与技术学院,南京 210023;2.南京师范大学 国际文化教育学院,南京 210097;3.南京师范大学 文学院,南京 210097)
0 概述
复句是由2 个或2 个以上的单句构成的句子,它下接小句,上承篇章,是语言的基本单位之一。由于复句有2 套或2 套以上主语谓语,而单句只有1 套主谓体系,因此判定一个句子是否为单复句对于句法分析、依存解析、AMR 自动解析及相应的下游任务非常重要。对于复句语义的构成,文献[1]指出复句除了本身的语义外,还与分句之间的逻辑语义有关,复句的语义等价于该句子的逻辑语义与各分句的语义之和。由于篇章的各种逻辑语义关系在复句中都有所体现,因此复句关系识别是篇章语义关系研究的起点和基础,对篇章语义解析以及机器阅读理解、关系抽取等下游任务都有着非常重要的作用。
对于复句的研究,语言学界主要集中在复句的逻辑语义关系的分类等,在自然语言处理领域,研究人员的关注则集中在显式复句的关系词识别和隐式复句关系识别2 个方面。然而,显式复句和隐式复句的识别主要靠人工标注,现有文献中并没有显式复句与隐式复句的自动识别研究。在汉语中,由于标点符号还具有语气停顿功能,含有多个形式分句的句子不一定是复句;同时由于大量紧缩句的存在,没有标点符号的句子也不一定是单句,这些都给单复句的自动识别造成一定困难。在隐式复句关系识别方面,虽然目前研究较多,但目前最好的性能也仅有56.20%[2],还有进一步的提升空间。
本文提出复句判定及复句关系识别联合模型,旨在同时解决复句判定和复句关系识别问题,实现复句的自动判定及复句关系的自动识别。在复句判定任务中通过Bi-LSTM 对句子进行编码,采用注意力机制挖掘更深层次的语义信息后,通过卷积神经网络(CNN)提取句子中的局部信息,最终对其进行分类。在复句关系识别任务中使用词向量Bert增强句子的语义表示,采用Tree-LSTM 对成分标记和句子中的单词进行联合建模后,并对建模结果进行分类。
1 相关工作
复句作为自然语言中重要的语法单位[3],在语言学上的理论成果较为丰富,且研究范围也较为广泛。对于复句的逻辑语义关系分类,代表性的研究主要有:文献[4]提出的两分法,依据分句之间的语义关系,将复句分为联合复句和偏正复句两大类;文献[5]将联合复句分为并列、递进、顺承、选择、解说5 个小类,将偏正复句分为转折、因果、假设、目的、条件5 个小类;另外一种是文献[6]提出的三分法,复句三分法的一级分类分为广义因果关系、广义并列关系和广义转折关系三大类,因果关系分为因果、推断、假设、条件、目的等,并列关系分为并列、连贯、递进、选择等,转折关系分为转折、让步等。
随着理论研究的不断深入,复句的相关研究逐渐从理论转向信息处理领域,关联词作为复句的重要信息。文献[7]对语料进行分析并总结出一个复句关联词库,采用基于规则的方法对关联词进行自动识别;文献[8]考虑到关联词与语境的关系,以复句关联词所处的语境以及关联词搭配为特征进行特征提取,使用贝叶斯模型实现关联词的识别;文献[9]充分利用句子的词法信息、句法信息、位置信息,采用决策树对复句进行复句关系分类,在显式复句中取得了较好的效果;文献[10]用极大似然估计计算关联词对于各类关系的指示能力,构造关联词-关系类型矩阵,预测句子的复句关系类别;文献[11]提出了一种基于句内注意力机制的多路卷积神经网络结构对汉语复句关系进行识别,其研究对象既包括显式复句也包括隐式复句,F1 值达到85.61%,但其仅在并列、因果、转折三类复句关系中进行识别,并没有涵盖自然语言中的大部分复句类别;文献[12]采用在卷积神经网络中融合关系词特征的FCNN 模型,对复句关系进行分类,准确率达到97%,但其研究对象仅为二句式非充盈态复句;文献[13]利用关联词的词性分布规则标注潜在关联词,对比关联词库中的模式表,标注出其语义关系。
由于隐式复句中没有关联词连接分句,因此隐式复句关系的识别较显式而言更为困难,目前专门针对复句判定、复句关系识别的研究比较少,大部分研究都是针对篇章进行的,然而由于汉语复句与篇章之间存在天然的联系,有关篇章的研究仍有许多值得借鉴的地方。文献[10]实现了基于有指导方法的隐式关系识别模型,融入依存句法特征和句首词汇特征,采用对数据不平衡容忍度较高的SVM 实现对篇章关系的识别;文献[14]以词汇、上下文信息及依存树结构信息作为特征训练最大熵分类器,以实现复句关系的自动识别;文献[2]在中文篇章树库(CDTB)上提出了模拟人类重复阅读和双向阅读过程的注意力机制网络模型,得到论元信息的交互表示。
2 基于注意力机制的复句判定模型
复句判定是指对于给定句子,复句判定系统能够准确地识别出是否为复句。如表1 中的例句1 即为包含关联词的显式复句,例句2 为紧缩型复句,例句3 为无关联词的隐式复句,上述3 类统称为复句,例句4 为单句。

表1 单复句示例Table 1 Examples of simple and complex sentences
本文以循环神经网络为基础实现复句的自动判定,模型主要分为输入模块、编码模块、输出模块3 个部分,其模型结构如图1 所示。
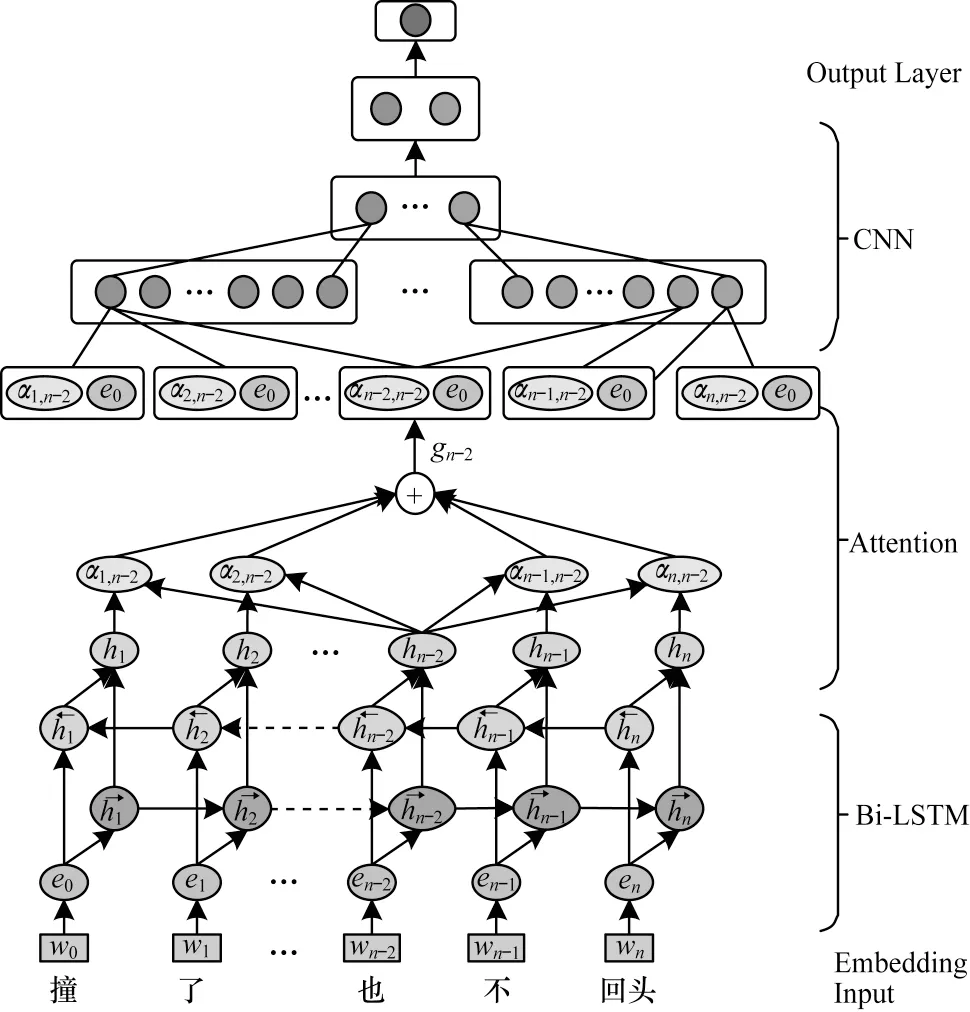
图1 基于循环神经网络的复句判定模型Fig.1 Model of complex sentence identification based on recurrent neural network
2.1 判定模型输入模块
2.2 判定模型编码模块
对复句的判定需要着眼于整个句子的内容,句子中某一个词的语义信息由上下文信息共同决定,因此采用Bi-LSTM 对句子中的词语表示进行建模,以便较准确地获得句子的语义信息,通过前向LSTM 和后向LSTM 计算得到句子向量表示,将两者拼接得到当前状态的向量表示。由于复句由2 个或2 个以上分句组成,与单句相比,句法结构更加复杂,长度更长,因此一层遍历所得到的语义信息往往是不足的,采用多层Bi-LSTM 能够避免梯度爆炸、梯度消失等问题。本文采用了多层Bi-LSTM 来学习文本数据中的层次化信息、增加语义建模的准确性。
由于复句语义关系是由分句语义的交互作用而形成的,因此本文采用了能够衡量内部相关性的Self Attention[16]。计算方式如式(1)~式(3)所示:
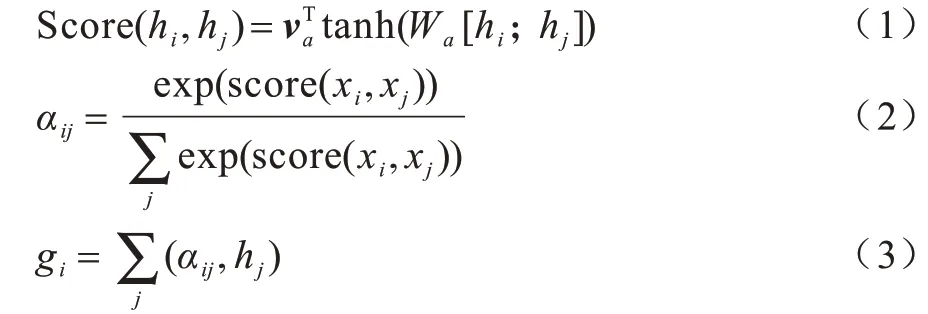
为挖掘文本中更深层次的语义信息,引入了卷积神经网络(CNN),通过卷积核提取出相邻单词的特征,对卷积层输出的结果进行池化操作,从而将最重要的特征提取出来。本文采用max-over-timepooling 操作,即将最大值作为最重要的特征。
2.3 判定模型输出模块
该模型在全连接层后通过softmax 函数对给定句子进行复句的判定预测。

其中:W和b分别为权重和偏置;C为经过模型编码后的输出。此外,本文所使用的损失函数为负对数似然函数。
3 基于Tree-LSTM 的复句关系识别模型
识别复句关系对于把握句子整体语义有至关重要的作用,也是本文另一项重要任务。表2 为4 种出现频率较高的复句关系类别示例。

表2 复句关系类型示例Table 2 Examples of complex sentence relation types
本文基于Tree-LSTM 的复句关系识别模型的输入为给定句子的2 个论元,输出为复句关系预测结果。该模型由输入模块、成分句法树模块、编码模块和输出模块构成,模型结构如图2 所示,下面依次对上述4 个模块进行展开。
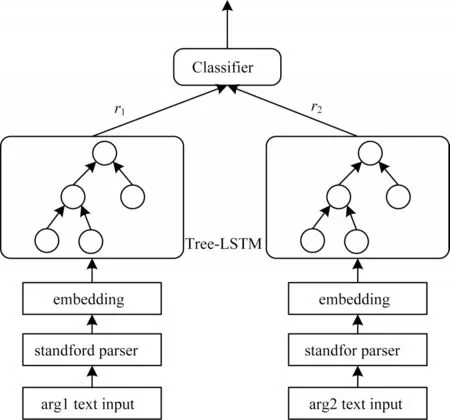
图2 基于Tree-LSTM 的复句关系识别模型Fig.2 Model of complex sentence relation recognition based on Tree-LSTM
3.1 成分句法树
成分句法树能够清晰地将句子中所包含的句法及句法单位之间存在的关系展示出来。在自然语言中,不同类型短语所对应的语义的重要性也各不相同,在一般情况下相较于动词短语,介词短语对复句关系影响较小。
图3 为复句“孟山都在欧洲遭遇滑铁卢,肯定会开拓市场弥补损失”中2个分句的成分句法树表示,在arg1中存在介词短语“在欧洲”和动词短语“遭遇滑铁卢”,在arg2 中有动词短语“开拓市场”“弥补损失”,通过比较2 个论元的动词短语,容易分析出2 个论元呈现因果关系,如果把arg1 中的介词短语和arg2 中的动词短语进行比较则难以得出上述结论。由此可见,句子中的成分信息对于复句关系识别具有一定的辅助作用,故本文采用Stanford Parser 得到句子中每个论元的成分句法树,将成分句法树的标记嵌入到词语的embedding中。
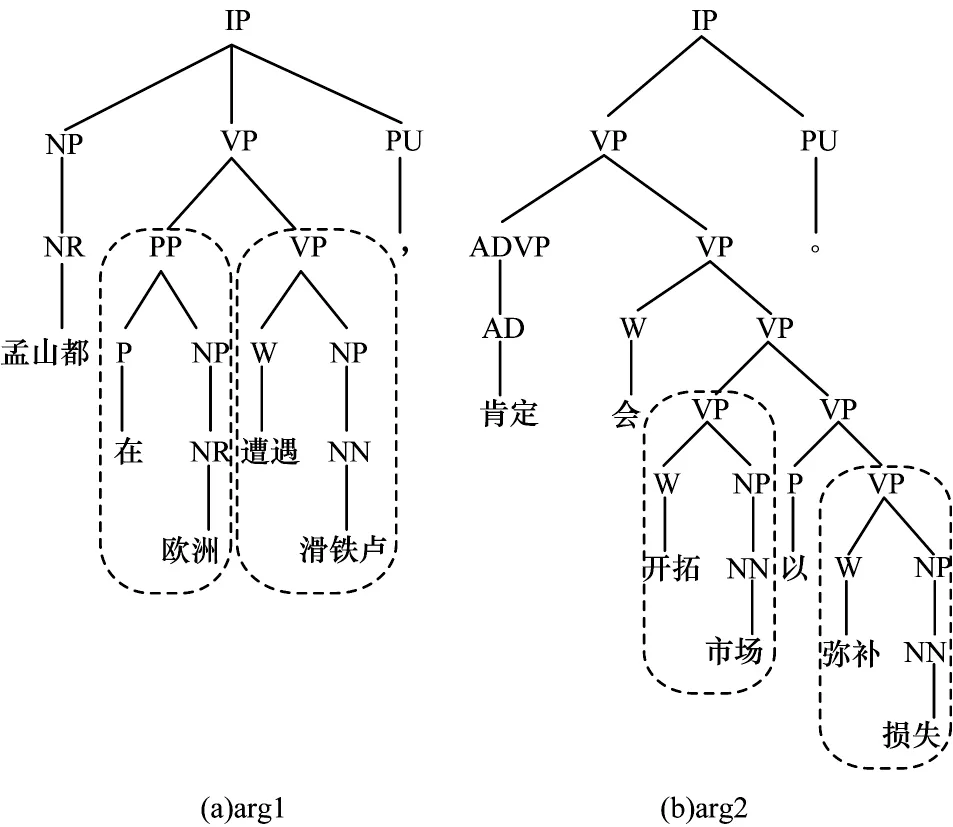
图3 成分句法树实例Fig.3 Example of constituent syntactic tree
3.2 识别模型输入模块
本文通过文献[17]提出的预训练语言模型Bert构造词语的向量表示,采用随机初始化的方式构造成分句法树标记向量,对于输入的句子c={c1,c2,…,cn},其中ci={wordi,tagi},1≤i≤n,ci包含在i这个位置上所对应的词以及该词在成分句法树中所对应的标记,对于每一个词ci,将其词向量和标记向量进行拼接,得到对应的向量表示ei=[wi;ti]。
3.3 识别模型编码模块
虽然链式的LSTM 已经取得了较好的效果,但是句子的语义不仅仅是由单个词的语义进行简单的拼接而成的,句子的结构信息也起着至关重要的作用,本文在编码时采用了能够捕获句子语义信息的同时也考虑句子的结构信息的Tree-LSTM[18]。
与LSTM 类似,Tree-LSTM 由1个输入门、1个输出门和多个遗忘门构成,遗忘门的个数与树节点数一致,即本文采用的方法有2 个遗忘门。但Tree-LSTM 的当前状态并不取决于上一时刻的隐藏层状态,而是取决于孩子节点的隐藏层状态,其计算方式也在LSTM 的基础上做出了调整,如式(5)~式(7)所示:
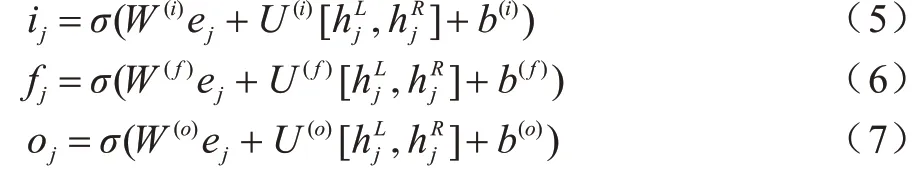
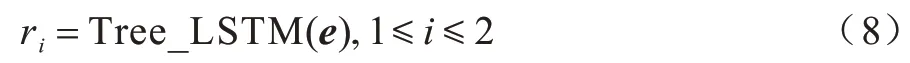
在通过Tree-LSTM 编码后,在复句关系识别任务中采用前馈神经网络,对Tree-LSTM 编码后的结果进行编码,在关联词的分类任务中采用了卷积神经网络对输出结果进行编码。
3.4 识别模型输出模块
在输出模块中,最终将复句中2 个论元的表示送入softmax 函数得到复句关系分类的概率,计算公式如下:

其中:D为训练时所用的数据集;R为复句关系的类型;yi(x)为训练样本x的标签(x)为通过本文模型得到的样本x被预测为属于类型i的概率值。
4 复句判定及复句关系识别联合模型
在统计模型的基础上,可将模型分为管道式模型和联合模型两大类。管道式模型的方式容易传递误差,导致模型的性能衰减,且各环节独立进行预测,忽略了2 个任务之间的相互影响,无法处理全局的依赖关系。联合模型则是将各个模型通过整体的优化目标整合起来,从整体的结构中学习全局特征,从而使用全局性信息来优化局部预测的性能。因此,本文采取联合模型同时进行复句判定和复句关系识别。模型结构如图4 所示,主要分为输入模块、编码模块、输出模块3 个部分。
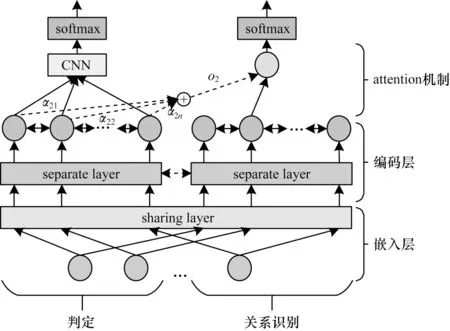
图4 复句判定及复句关系识别联合模型结构Fig.4 Joint model structure of complex sentence identification and compelx sentence relation recognition
4.1 联合模型输入模块
在自然语言处理的相关任务中,一个单词的特征或者含义不应该因为任务的不同而不同,统一的向量表示使联合学习模型不过分地倾向于某一任务,增加了模型的泛化能力,故本文在嵌入层中复句判定和复句关系识别任务的嵌入层中共享向量表示。
参数共享是联合模型中较为常见的一种方式,可以分为硬共享和软共享2 种。硬共享指多个模型之间的共享部分直接使用同一套参数,使模型学习到可以表示多个任务的解;软共享通常是通过计算多个模型之间的共享部分的参数之间的差异,使其差异尽可能得小,并保留任务的独立性。为了使模型在底层的句子表示中使复句的判定和复句关系识别任务可以相互借鉴,故本文在参数共享中选择了参数软共享方式,使多个模型中需要共享部分的参数差异尽可能得小,这种参数共享方式能够使模型在学习多个任务共有的表示下保留任务的独特性,对不同的任务学习不同的句子表示。

4.2 联合模型编码模块
对于复句判定任务,编码层采用Bi-LSTM 进行编码,获得句子的上下文表示信息,将Bi-LSTM 的结果作为CNN 的输入,得到句子的局部特征表示。
在复句关系识别任务中,为了得到句子的结构化信息,采用Tree-LSTM 进行编码。此外,由于复句判定任务中学到的句子表示有助于丰富复句关系识别任务中的信息,因此本文引入了注意力机制对这部分信息进行学习。在复句判定编码层输出的上下文词表示为,复句关系识别编码器获得的输出记为,通过下式计算:

4.3 联合模型输出模块
在得到新的向量表示后,将编码后的结果通过softmax 函数进行进行复句判定和复句关系识别。若在联合模型中输入的句子被判定为单句时,该句子在进行复句关系识别后会进行后处理,将其复句关系识别的结果更正为无关系。
在联合模型中损失函数的定义是一个十分棘手的问题,若2 个任务之间出现梯度不平衡的问题会导致参数的更新倾向于某个单独的任务,降低所有模型的表现效果。故本文计算2 个任务之间的损失采用静态加权求和的方式,将不同任务之间的损失进行组合,计算公式如下:
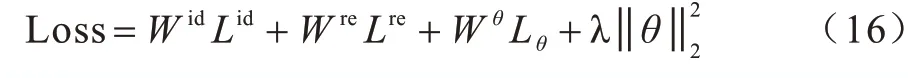
其中:Wid和Lid分别为复句判定模型的权重和总损失;Wre和Lre分别为复句关系识别任务中的模型的权重和总损失;θ为模型的参数;Lθ为参数软共享所构成的参数距离损失。
5 实验结果与分析
5.1 数据集
本文中 所使用 的语料是由CAMR[19](Chinese Abstract Meaning Representation)和篇章结构树库[20]中抽取的复句语料。图5 为CAMR 中复句的结构示例。

图5 CAMR 复句结构示例Fig.5 Example of CAMR complex sentence structure
在CAMR 中共标记了并列、因果、条件、转折、时序、递进、选择、让步、反向选择9 类复句关系,但由于后5 类仅占语料的4.23%,因此对这5 类进行了归并,得到了如表3 所示的数据集,其中无关系类别为单句,共5 359 种。
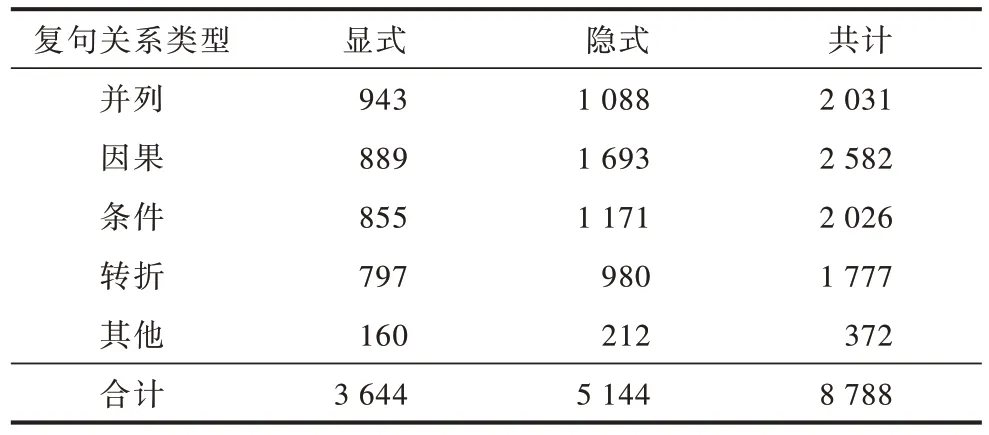
表3 语料库中复句关系统计Table 3 Statistics of complex sentence relations in corpus
5.2 复句判定
在复句判定实验中训练集、测试集的比例为4∶1,由于深度学习算法容易出现过拟合的问题,因此在每一层的输出中进行Dropout[21]操作,采用Adam[22]算法对模型进行优化,实验中所涉及的参数设置如表4 所示。
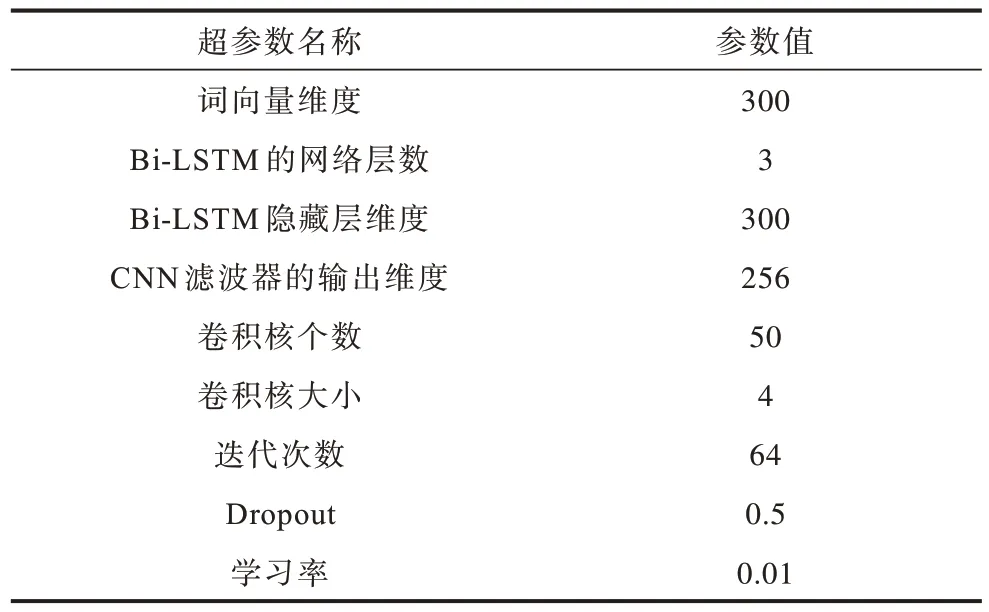
表4 复句判定模型的超参数设置Table 4 Hyperparameter settings of complex sentence identification models
表5 为复句判定任务的实验结果,可以看到仅使用Bi-LSTM 时准确率(P)达到94.81%,但召回率(R)较低,这是因为Bi-LSTM 着眼于复句的整体语义,若复句句法结构不够典型则效果较差,无法识别。Attention 机制能够捕获分句间对揭示语义有提示作用的词语或搭配信息,因此F1 值提升了6.07 个百分点。CNN 的加入则是突出了分句内部对语义有提示作用的局部信息,因此性能进一步提高。这说明对于复句而言,除了整体语义外,局部语义及分句间的语义交互作用对揭示复句语义有着同样重要的作用。
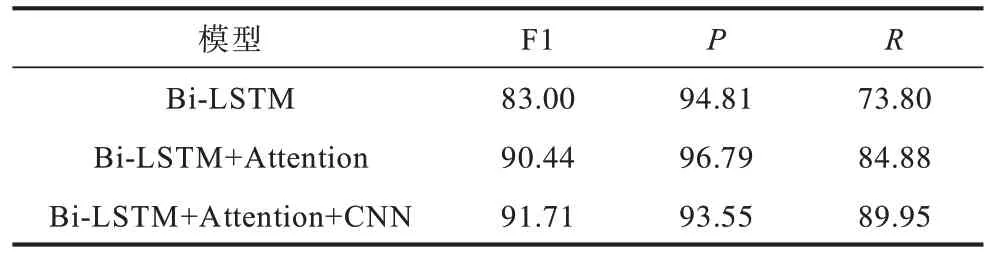
表5 复句判定实验结果Table 5 Experimental results of complex sentence identification %
为了更好地分析模型的性能,本文对测试集中的显式复句和隐式复句的实验结果进行分析,其实验结果如表6 所示。
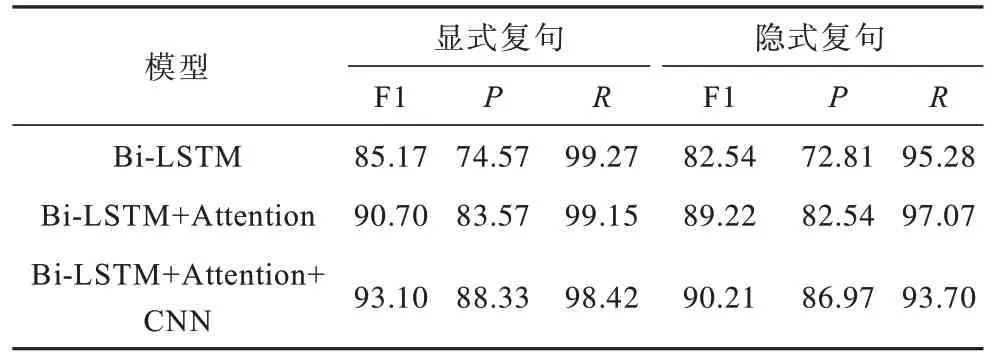
表6 显式及隐式复句判定实验结果Table 6 Experimental results of explicit and implicit complex sentence identification %
从表6 可以看出,与表5 相似,无论是在显式复句还是在隐式复句中,加入Attention 和CNN 以后的F1 值均高于其他2 种方法,这再次证明了局部信息的引入有助于提升模型对复句判定的性能。另外,通过比较显式复句和隐式复句的判定结果可以发现,显式复句的F1 值比隐式复句的F1 值高2.89 个百分点,这是因为隐式复句中并没有关联词这一明显的浅层特征,在编码时其内部的语义信息较难挖掘,导致隐式复句判定结果较低。
5.3 复句关系识别
在复句关系识别任务中所涉及的超参数如表7所示,复句关系识别任务的结果展示如表8 所示。
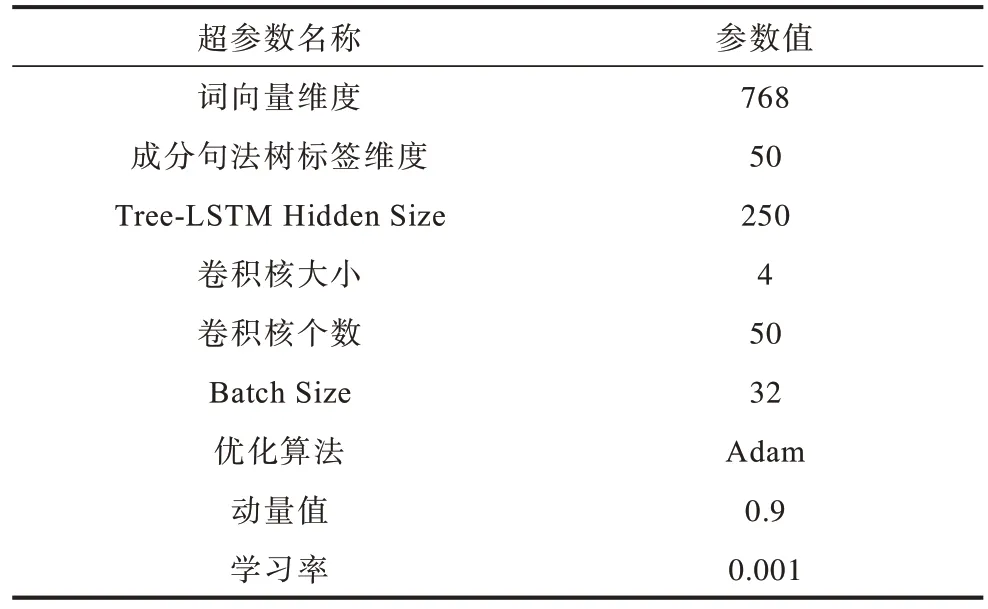
表7 复句关系识别模型的超参设置Table 7 Hyperparameter settings of complex sentence relation recognition model

表8 复句关系识别实验结果Table 8 Experimental results of relation recognition of complex sentences %
表8 中LSTM 模型表示只考虑句子的上下文语义信息,对句子的语义进行建模,但句子的语义信息并不只是每个词语义的叠加,与句子的结构信息有一定的关系,Tag+Tree-LSTM 模型考虑句子的句法结构信息,并在编码过程中融入成分句法树的标签信息,这种方式相较于只考虑上下文语义信息的LSTM 而言,效果提升了0.27 个百分点;在Tag+Tree-LSTM 中采用了随机初始化的词向量方式,但预训练的词向量能够更好地反映出词语词之间的关系以及句子的语义信息,故在Tag+Tree-LSTM 的基础上加入了句子级的词向量Bert,模型的性能提高了3.37 个百分点。
表9 所示为本模型与其他模型的实验结果对比,相比于文献[14]针对汉语篇章结构语料库提出的基于多层注意力的TLAN 方法,本文提出的方法采用Tree-LSTM 能够充分利用句子的结构信息,预训练词向量Bert 的引入对汉语中一词多义现象有所解决,因此本文所提出的Tag+Tree-LSTM+Bert 模型F1 值达到58.17%,相较于TLAN 模型,提升了1.97 个百分点。

表9 模型实验结果对比Table 9 Comparison of the model experimental results %
表10 所示为复句判定和复句关系识别任务构成的管道式模型实验结果,与前文中提出的Tag+Tree-LSTM+Bert 模型相比,pipeline 模型的实验结果比直接进行复句关系识别任务的模型低,这是因为pipeline 需要先进行复句判定任务,然后再进行复句关系识别。
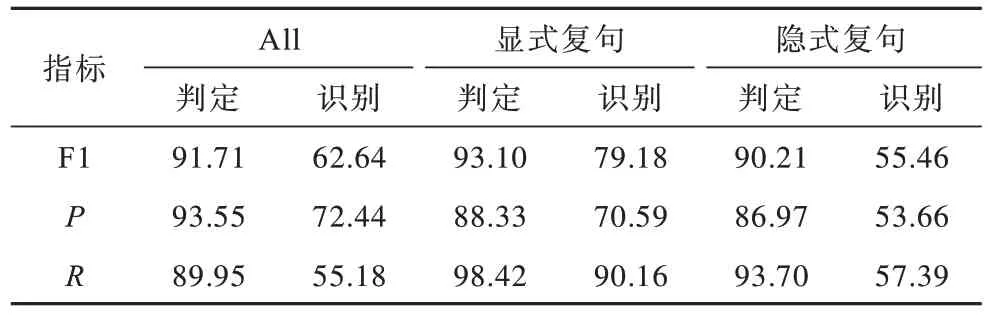
表10 复句判定及复句关系识别pipeline 模型结果Table 10 Pipeline model results of complex sentence identification and complex relation recognition %
5.4 复句判定及复句关系识别联合模型
在联合模型中,通过联合学习利用任务之间可以相互作用的特征,表11 为复句判定及复句关系识别联合模型的实验结果。
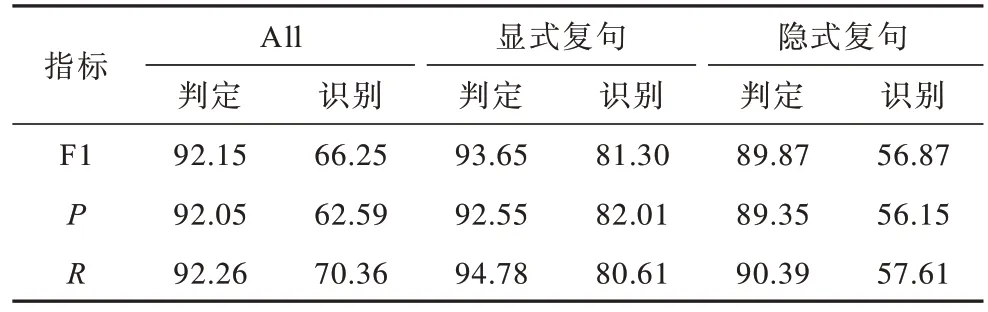
表11 联合模型实验结果Table 11 Experimental results of joint model %
通过比较表10 和表11 可以发现,无论是在复句判定任务还是在复句关系识别任务中,联合模型的F1 值相比管道式模型都有所提高,表11 联合模型中复句判定任务的F1 值较表10 中管道式模型提高了0.44 个百分点,联合模型复句关系识别的F1 值为66.25%,与管道式模型的实验结果62.64%相比提高了3.61 个百分点,这是因为联合模型能够有效地减少模型之间的误差传递。
6 结束语
本文基于神经网络方法对复句判定及复句关系识别任务进行研究,构造复句判定和复句关系识别联合模型,通过减少管道式误差传递以实现复句的自动判定和复句关系的自动识别。实验结果验证了本文方法的有效性。由于神经网络方法对语料规模较为依赖,因此下一步将继续扩充语料规模,提高网络模型性能。
猜你喜欢
疯狂英语·新阅版(2022年7期)2022-07-07
疯狂英语·新悦读(2022年7期)2022-07-06
成都理工大学学报·社会科学版(2022年1期)2022-05-26
华北电力大学学报(社会科学版)(2021年2期)2021-07-21
开放教育研究(2020年2期)2020-03-31
作文周刊·小学四年级版(2017年35期)2017-10-18
作文周刊·小学三年级版(2017年34期)2017-10-17
现代语文(2016年21期)2016-05-25
语文学刊(2015年24期)2015-08-15
大连民族大学学报(2015年2期)2015-02-27
