
机器人智能抓取未知目标位置深度识别仿真
2021-11-17 06:36周建慧
计算机仿真 2021年8期
高 云,彭 炜,周建慧
(山西大同大学计算机与网络工程学院,山西大同 037009)
1 引言
目前科技不断发展,促使人们对于智能生活的要求也随之提高,对于机器人的使用需求逐渐增加[1]。机器人在使用过程中,需完成抓取目标识别后,才可进行抓取。因此,抓取目标的位置识别是机器人使用过程中至关重要的步骤[2]。机器人智能抓取未知目标位置识别可看作其执行位置目标的视觉控制,该操作表示机器人可在不知道抓取目标的任何信息的情况下,仅根据当前图像信息即可完成机器人对未知目标的智能感知与位置识别[3]。在目标位置识别过程中,图像特征对整个机器人视觉识别和定位方法动态性能存在一定影响,其可决定识别和定位方法的稳定性以及在复杂环境中依旧可准确完成识别的条件。
为了保证机器人在正常情况下抓取未知目标位置识别性能,文献[4]提出基于深度卷积神经网络的目标识别方法,采用深层卷积网络提取自然环境下的目标视觉特征,获取目标特征图的深层池化结构后,基于非极大值抑制方法完成目标位置的识别,该方法仅可完成自然环境中的目标识别,复杂环境下定位误差较大。文献[5]提出轮廓匹配的复杂背景中目标检测方法,通过实行图像预处理后,利用形状描述子完成轮廓匹配,采用深度优先的搜索策略完成目标识别;该方法虽然可以完成复杂背景中的目标检测,但是当物体存在重叠情况下,其识别率较低。
针对上述问题,并考虑未知目标在遮挡、光照变化等复杂情况,提出具备目标位置深度识别能力的基于深度残差网络的未知目标位置识别方法,实现机器人可在多种识别环境中,完成对未知物体的自主视觉定位。
2 机器人智能抓取未知目标位置深度识别仿真
2.1 机器人智能抓取未知目标位置深度识别框架
基于位置的视觉识别和基于图像的视觉识别是机器人智能抓取未知目标位置识别的两种方式[6]。通常情况下,基于图像的视觉位置识别应用较为普遍。因此,采用基于图像的视觉识别完成机器人智能抓取未知目标位置的深度识别。该方法需在机器人末端的执行器上设置摄像机,使其在机器人手臂实行抓取行为时随之运动,可实时获取目标位置的图像信息,获取图像特征。将深度残差网络用于机器人智能抓取未知目标位置识别中,该算法识别流程如图1所示。
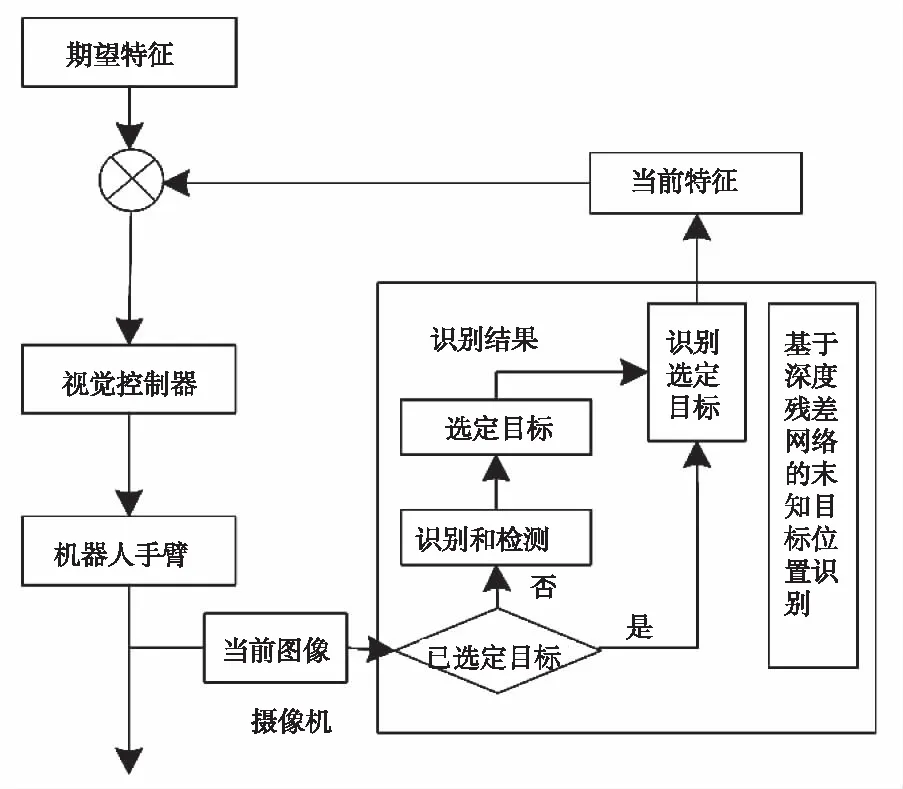
图1 机器人智能抓取未知目标位置识别流程
识别过程中,通过深度残差网络的识别和检测完成目标的识别和检测,得出未知目标的类别属性信息后,根据该信息计算当前图像特征,并预测目标的坐标信息,保证目标定位的精准度。该网络是基于端到端的实时目标检测系统,更适用于复杂环境中应用[7]。因此,将该网络应用于机器人视觉控制中,保证未知目标种类不清楚并且没有实行过训练的情况下,完成随机指定目标的快速、准确识别。
2.2 基于深度残差网络的未知目标位置的识别模型
2.2.1 深度残差网络
采用40层的深度残差网络识别未知目标位置,该网络结构如图2所示。
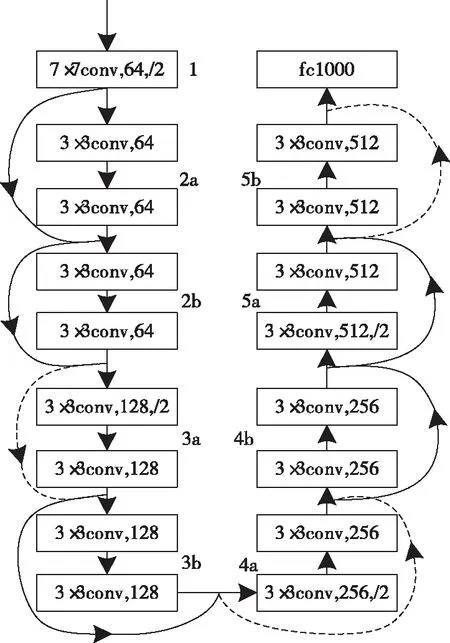
图2 深度残差网络结构
基于深度残差网络算法主要用于机器人视觉控制过程中所有未知物体的类别信息和位置信息的获取,可使用户根据该结果随机选择定位目标。并且可在定位初始帧任意选取的机器人待定位目标,并计算其图像特征,为机器人定位到该目标提供依据。为避免深度网络模型在提取深层次图像特征时产生退化,向深度残差网络融入恒等映射,组成残差模块结构[8]。多个卷积层级联的输出和输入元素之间的相加组成残差模块的输出,并通过线性整流函数将其激活后得出。
2.2.2 未知目标位置的识别模型
获取端至端的学习深度图像和最佳抓取位置的映射关联性,保证可以学习到更深的图像特征,是基于深度残差网络的机器人智能抓取未知目标位置识别的前提。基于深度残差网络模型设计机器人智能抓取未知目标位置模型,其识别流程如图3所示。
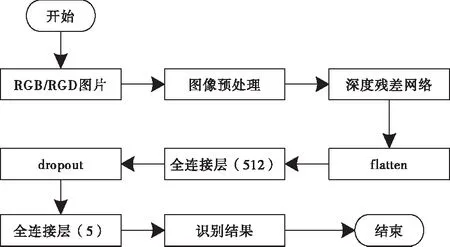
图3 基于深度残差网络的未知目标位置识别流程
该模型根据输入通道数据的差异,将通道分为两种,分别为RGB和RGD通道。向基于深度残差网络的未知目标位置识别模型中输入RGB或者RGD数据,实行裁剪、归一化等图像预处理后,将其输入深度残差网络中,并且采用两层全连接层替代模型最后一层分类器,同时引入防过拟合手段,识别结果为输出的五维参数集g={x,y,θ,h,w}。
2.2.3 模型训练
采用迁移学习方法对基于深度残差网络的未知目标位置识别模型展开训练,其步骤如下所述:
1)为保证模型的输入为五维参数集,将40层的深度残差网络传入端到端开源机器学习平台TensorFlow中,并采用两层全连接层替代模型最后一层分类器。
2)传入预训练模型参数,并且该参数为40层深度残差网络位于Imagenet数据集中[9],由端到端开源机器学习平台TensorFlow提供。
3)完成康奈尔数据集的划分后,并将其转化为TensorFlow数据格式TFRecord,其中,划分采用五折交叉验证的方式完成。
4)模型的训练通过康奈尔数据集完成,训练过程中,将40层深度残差网络中的卷积层参数固定,采用微调对模型进行处理。
由于模型输出的是五维变量参数集,在训练时结合抓取未知目标位置的坐标点和抓取宽度的影响存在差异,并且旋转角参数量纲也存在差异[10],因此,采用平方误差损失函数和均方差损失函数表示损失函数,其公式为
Q(G,GT)=(x-xT)2+(y-yT)2λ(θ-θT)2+
(1)
式中:x、y分别表示位置坐标点;w、h分别表示抓取宽度;康奈尔数据所标注的正例抓取框用GT表示;抓取位置识别算法输出的最优抓取框用G表示;θ表示旋转角。
He初始化方式是权重参数初始化方式,且权重参数属于模型最后两层全连接层,同时,采用零初始化对偏置参数实行处理[11]。模型训练完成后,直接输入测试RGB和RGD图像,以此检测出未知定位目标并计算出当前图像特征。
2.3 视觉控制器设计
根据滑膜控制器的设计逻辑,设计机器人视觉定位控制器,其由滑模切面函数和滑模动态控制两部分设计完成。保证确定的滑动模态稳定以及动态质量较高是滑模切面函数的作用;使图像特征误差可快速到达滑模面后顺着该面逐渐稳定,直至达到期望图像的特征,也可将其理解为保证设置的某个阈值,大于当前图像和期望图像两者特征的重合,是滑模动态控制的作用[12]。
滑模切面函数用s表示,则其公式为
s=ld-l
(2)
式中:ld和l分别表示期望图像特征和当前图像特征。
机器人视觉控制中,其抓取时在运动空间的运动速度和未知目标图像特征空间中的运动的关联性可采用图像雅可比矩阵Jim表示,其公式为
(3)
结合上述内容设计机器人视觉滑模定位控制律,其公式为
(4)
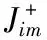
(5)
(6)
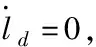
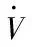
=-sTZp|a|sat(Φ-1s)
(7)
获取机器人任意第i个运动方向的控制率ui的对应李亚普诺夫函数的导数
(8)
当|si/φi|≤1,即表示|si|≤φi,此时
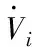
=-sZpi|ai|(s/φi)
=-Zpi|ai|(s2/φi)<0
(9)
当|si/φi|>1,即表示|si|>φi,此时
=-sZpi|ai|sgn(s/φi)
=-Zpi|ai|s×sgn(s/φi)
=-Zpi|ai|(|s|/φi)<0
(10)
3 实验分析
为了验证机器人智能抓取未知目标位置深度识别方法的有效性,采用MATLAB仿真软件完成机器人仿真,测试所提方法的识别效果。仿真两类目标物体进行未知目标位置识别,分别为刚体和非刚体。其中,刚体包含5号锂电池、空调遥控器、水杯;非刚体包含面包和小玩偶。该物体在位置识别前没有采取预训练等相关处理。
深层残差网络的训练次数对未知目标位置识别结果存在一定影响。因此统计训练次数对目标识别准确率的影响,结果如图4所示。
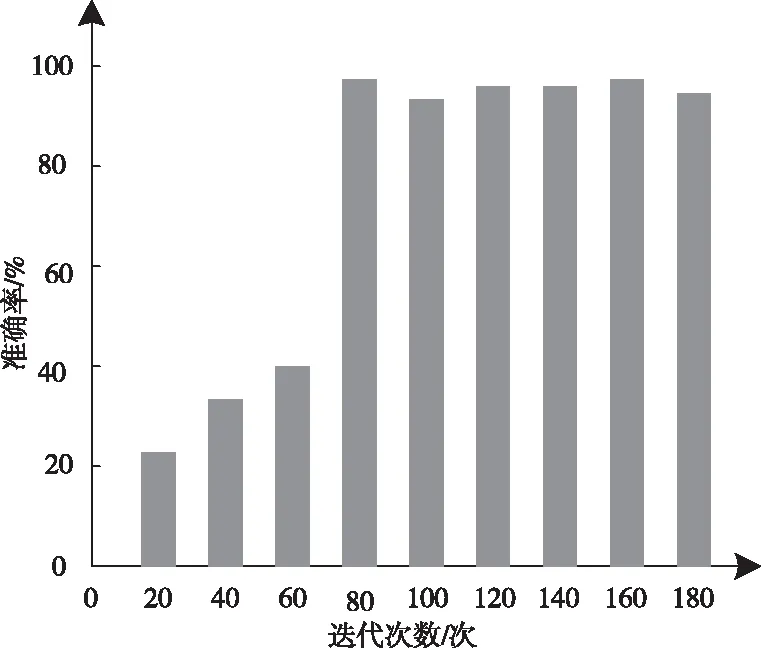
图4 训练次数对目标识别准确率的影响
根据图4测试结果可知,机器人智能抓取未知目标位置识别的准确率随着迭代次数的增加而提升,当迭代次数达到80次以上,识别准确率达到95%以上并保持平稳。该结果表示,要保证识别的准确率,深度残差网络识别模型的训练迭代次数需要在80次以上。因此为保证后续实验结果的准确性,模型的迭代次数为80次以上。
损失函数值的大小与迭代次数存在较大关联性,为确定最佳损失函数值,统计在不同迭代次数下的损失函数值,结果如图5所示。
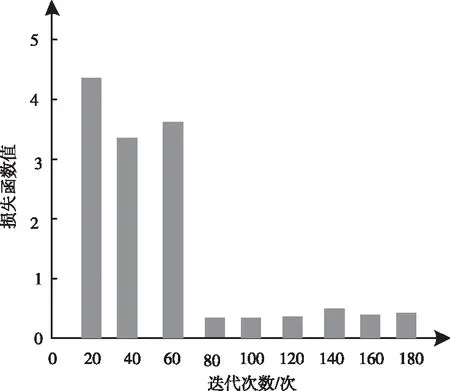
图5 损失函数与迭代次数的关联性
根据图5的测试结果可知,迭代次数的增加会降低损失函数值,当迭代次数为80次以上时,损失函数值均为0.5以下,且处于平稳状态,说明迭代次数为80次以上时,损失函数值为最佳值,因此将后续实验中的迭代次数为80次,损失函数为0.44。
为测试所提方法的识别结果,模拟机器人对水杯进行目标视觉定位,获取目标视觉定位过程中图像平面u和v方向的定位轨迹以及对应的误差结果,根据输出的像素值和定位误差像素值,分析所提方法的定位效果,结果如表1所示。
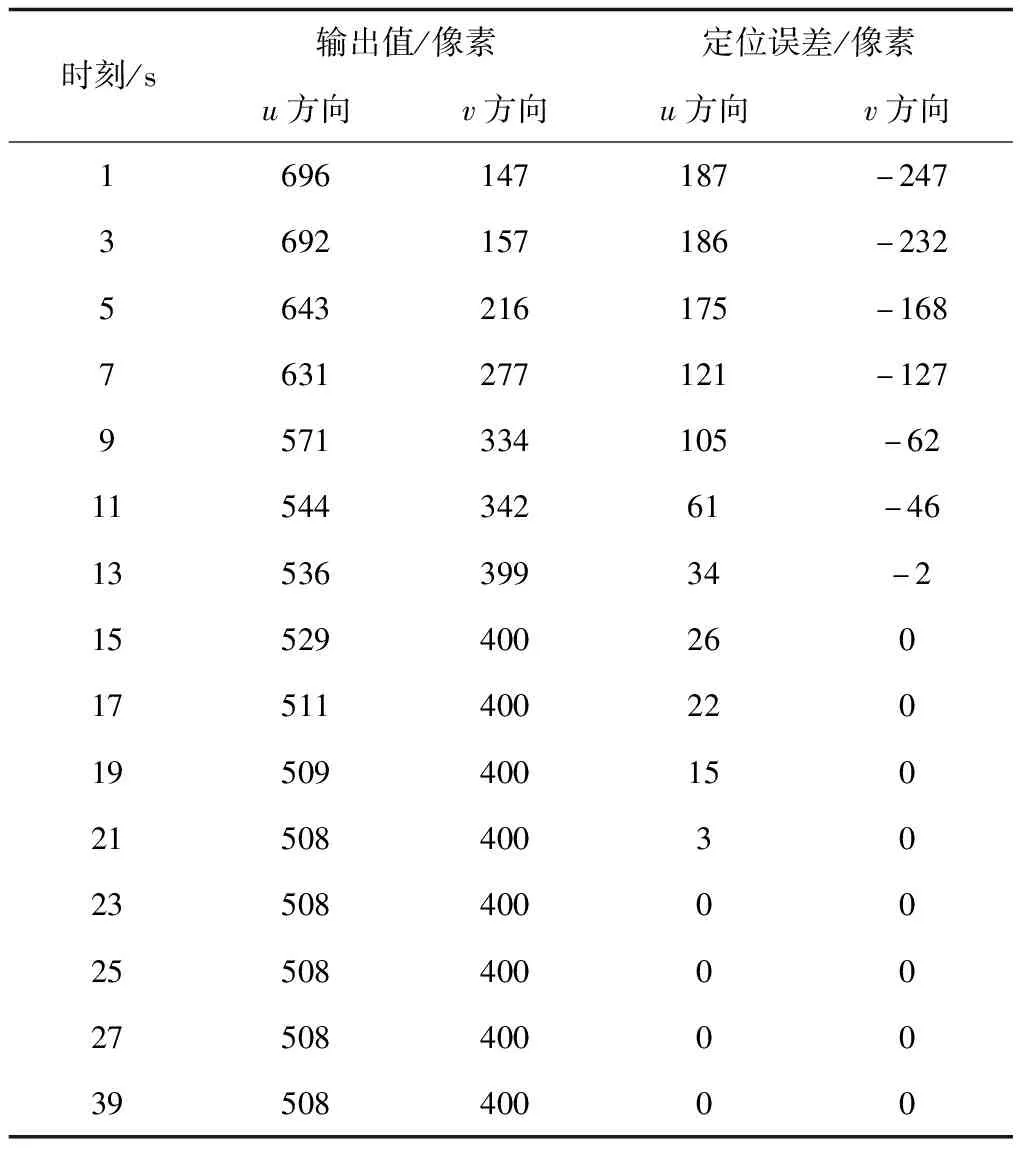
表1 图像平面u和v方向的定位轨迹及其误差结果
根据表1的测试结果可知,随着时间的增加,图像平面u和v方向的输出像素值程逐渐降低趋势,u方向达到19s时,输出像素值趋于稳定;v方向达到15s时,输出像素值趋于稳定。同时随着时间的增加,图像平面u和v方向的输出像素值对应的误差也呈现降低趋势,u和v方向分别为23s和15s时误差值为0。实验结果表明,所提方法可识别到未知目标位置。
为进一步分析所提方法的识别效果,设置迭代次数为80次,分别采用文献[4]方法、文献[5]方法和所提方法对于刚体和非刚体五种物体进行10次处于机器人工作平面不同位置的视觉定位,获取其不同方法的定位误差结果如图6所示。
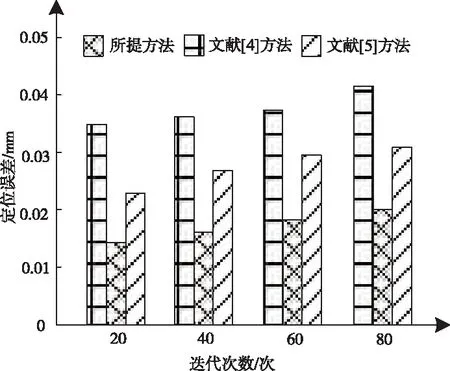
图6 不同方法的定位误差对比结果
根据图6的测试结果可知,随着迭代次数的增加,不同方法的定位误差随之增大,当迭代次数为80次时,文献[4]方法的定位误差为0.043mm,文献[5]方法的定位误差为0.031mm,而所提方法的定位误差为0.02mm,由此可知,所提方法的定位误差较小,定位准确性较好。
测试在不同环境下,机器人对未知刚体和非刚体目标位置识别的有效性,对五种目标物体进行识别。采用文献[4]方法和文献[5]方法作为所提方法的对比方法,统计三种方法的位置识别结果如表2所示。
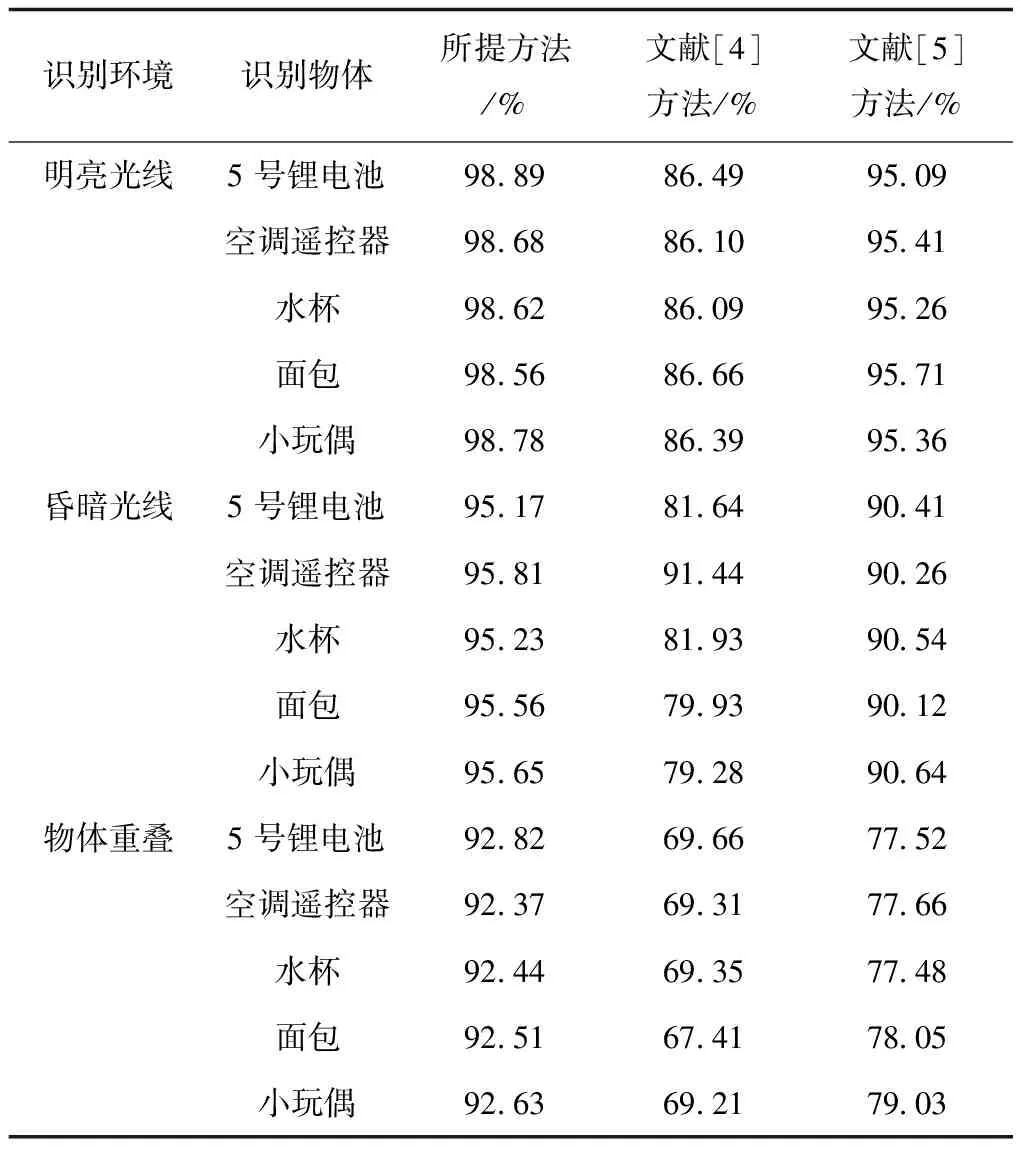
表2 不同方法的识别率对比结果
分析表2的测试结果可知,在不同识别环境下,三种方法的识别率出现不同的变化。在物体重叠的环境中,不同方法的识别率最低,而在明亮光线环境下,不同方法的识别率最高。但是,所提方法在三种环境下的识别率均明显高于文献[4]方法和文献[5]方法,识别率均为92%以上。由此可知,所提方法对未知刚体和非刚体目标视觉识别率较高。
4 结论
提出的基于深度残差网络的未知目标位置识别仿真,用于机器人对未知物体位置的识别。该方法的位置识别可在无需提前获取目标及其所在场景的任何信息条件下完成识别,并且在位置识别过程中,当空间里存在多个物体时,可以控制机器人运动,使其定位到指定的不同类别、不同规则形状的刚体或非刚体目标,完成目标位置定位。并且该方法具备良好的识别效果和定位结果,是一种有效的、准确的机器人智能抓取未知目标位置深度识别方法。
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
计算机系统应用(2020年1期)2020-01-15
福建基础教育研究(2019年6期)2019-05-28
海峡姐妹(2018年2期)2018-04-12
人大建设(2018年12期)2018-03-21
杂文选刊(2018年1期)2018-01-09
