
多段支持度数据频繁模式关联规则挖掘仿真
2021-11-17 08:36王培培
计算机仿真 2021年5期
王培培,孟 芸
(河南大学民生学院,河南 开封 475000)
1 引言
伴随数据信息的迅速传播,数据挖掘技术可以使人们在巨大网络空间当中选取自己所需要的信息和知识。数据挖掘是从含有大量数据集合中提取隐藏的重要信息或关键知识,将其转化为另一种简便、易懂的形式。关联规则挖掘是数据挖掘中必不可少的一部分,数据信息之间存在的相关联系得到人们高度重视,具有广泛的应用前景。
自关联规则挖掘问题被提出后,有部分人不断质疑其局限性,为了避免产生冗余虚假规则,引入新的阈值,从而加强对关联规则的评判。
朱益立[1]等人提出了一种有向无环图的挖掘算法,根据候选项集构建二进制表,计算出所构建二进制表支持度,作为有向无环图边权值,运用人工设置阈值判断计算出的边权值是否需要保留,整个构建过程只需扫描一次数据库,不会产生候选项集。具有较好的性能。
乔少杰[2]等人提出了一种正负双支持度的关联规则挖掘算法,在频繁项集发现阶段,引入最大支持度以解决过频繁问题,再运用建立负项频繁模式树进行递归挖掘,引入支持度计数矩阵提高了正负频繁项的发现效率。强关联规则发现阶段,通过设置合适的置信度阈值和采用互信息进行相关性分析判定药物项集的关联关系。最后验证了所提方法较在挖掘的时效性和准确性上有较大提高。
上述两种方法在关联规则挖掘时忽略了数据在集合内分布频率的不同特点,在挖掘时,存在时间较长、复杂度高、规则冗余等问题,本文所提方法通过多段支持度算法获得最小支持度和最小置信度,在挖掘时利用数据集缩减,实现多段支持度数据频繁模式关联规则挖掘,且具有较高适用性和可行性。
2 多段支持度分析
2.1 多段支持度算法
关联规则可以有效的反应出众多数据中各个对象之间的关联程度,并能够挖掘出数据集内所包含的重要信息,并在多各领域中广泛应用。
在相关规则[3]当中,把一个数据项集内各个对象的数量作为项集长度,且长度是k的数据项集作为k项集。数据集中频繁项集就是满足最小支持度的项集,频繁项集整体模式就是其包含的项集的数量,利用各个项集中多段支持度的计算,寻找最频繁的项集。假设有m个项目,在多个不相同的项集中数量增加到2m-1个,在众多数据集D内,依据网络中产生的频率确定其最少支持度阀值,并挖掘出多段支持度数据频繁模式中有效关联规则。
建立多段支持度模型,关联规则挖掘使用的是逐步搜索方法,在众多候选项集内选取频繁项集。依据数据项在数据集内出现的频率来选择最少支持度阈值,规则Min Supt等于所蕴含的全部数据项的最少MIS。那么规则R的表达式即:
I1∧I2∧…∧Ik⟹Ik+1∧…∧Ir
(1)
其中Ii∈I,那么所得公式表示即
MinSupt(R)==min(MIS(I1),MIS(I2),…,MIS(Ir))
(2)
式(2)作为满足规则的最小支持度[4]。假设数据项整体集的公式为
I={i1,i2,…,im}
(3)
对象之间相关数据[5]集合表达式为
D={T1,T2,…,Tn}
(4)
如对象T作为数据项子集,为T⊆I,每个项目中都具有一个识别编号TID。对象I中所得到的每个子集是X作为D所包含的项集,假设|X|=k,那么项集X作为对象k-的项集,若X⊆Ti,那么对象Ti中就蕴含项集X。
首先,项集X的支持度表达式为
sup(X)=σx/|D|*100%
(5)
式中,|D|作为数据集D的事务数,σx作为数据集D内所蕴含项集X的事务数。
如sup(X)大于或等于指定的最小支持度,那么X就称为频繁集[6],与之相反,若小于指定的最小支持度,那么X就称为非频繁集。关联规则是类似X=>Y的逻辑式,式中X⊆T,Y⊆T,且X∩Y=Φ。
其次,若X=>Y事务集内的支持度,数据集D中蕴含的X,Y的事务数量和蕴含X的事务数量之比值,公式为
X=>Y=sup(X∪Y)/sup(X)*100%
(6)
式(6)中,sup(X∪Y)是指规则X=>Y的多段支持度。
2.2 最小支持度计算
多段支持度的构造过程需要2次扫描数据库,第一次扫描累积事务数据库内的各个项以及支持度的计数和叶子数,计算其最小支持度。通过第二次扫描来扩展事务数据库。挖掘过程中也不需生成大量的候选项目集和频繁地进行模式匹配。
达到预期最小支持度和最小置信度的关联规则显得格外关键。挖掘数据频繁模式关联规则[7]主要步骤分为:
步骤1:挖倔数据集内所有频繁集。
步骤2:依据频繁集,挖掘相对的关联规则。
因为步骤2较为简便,只要获得频繁集,就能轻易推导出关联规则,所以步骤1的处理显得尤为重要,其决定着关联规则的挖掘性能,同时也是衡量挖掘方法的首要标准。在各个结点中巧妙的通过互联网传对重要信息进行有效的转换,最终在整个事务数据库中挖掘出关联规则。
在多段支持度模型中,给数据项集内各个单独项设定满足所需条件的最小支持度。寻找频繁集时,利用相关项集内每个项最小支持度的最大值或最小值进行挖掘。
以最小值作为最小支持度的算法,在频繁子集内不能保证全部子集都是频繁的。设定数据集为
D,I={A,B,C,D}
(7)
那么可知公式为
MIS(A)=4
MIS(B)=3
MIS(C)=1
MIS(D)=2
(8)
依据多支持度最小值算法,在挖掘2-项集的过程中,可得出式(9)即
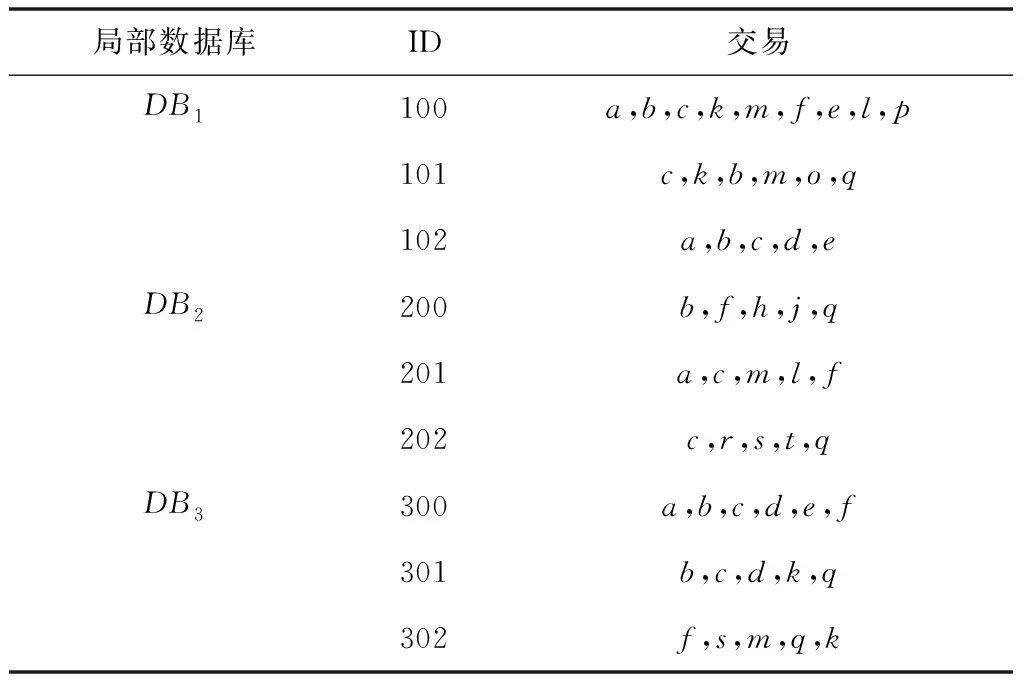
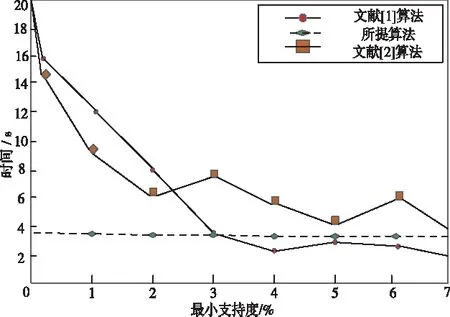
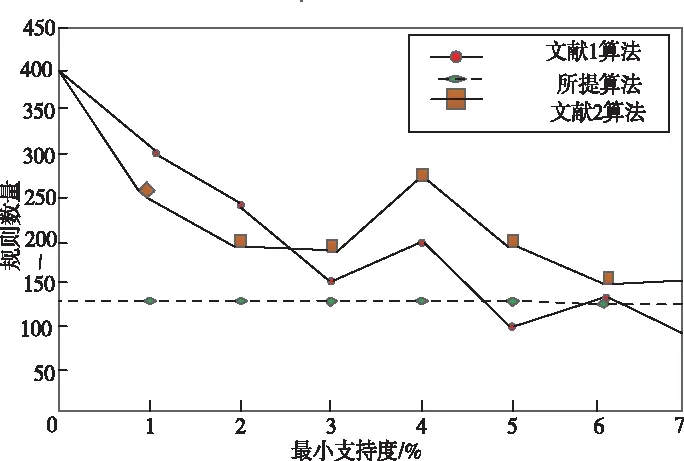
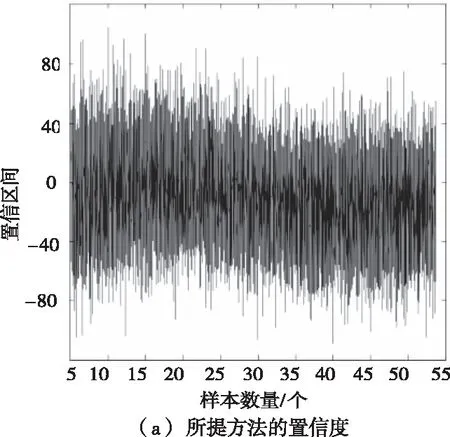
sup(AB)=2 (9) 故子集(AB)是非频繁集。在挖掘3-项集的过程中,可得出式(10)即: sup(ABC)==2>min(MIS(A),MIS(B),MIS(C)) (10) 故子集(ABC)是频繁集。 为了达到最小值作为最小支持度算法的地推性,把数据项集I内的每个单独项以MIS值实施有序排列,事务T内的每个单独项也按照MIS值实施有序排列。在形成频繁集L2的过程中,运用待选集C1并非频繁集L1,因频繁集L1内不包括原本支持度比本身MIS小的项,且比之前各个项MIS的项。用频繁集Lk-1所形成的待选集Ck,由于使用了排序,每个数据项按照MIS的项进行升序排列,把较高MIS值的数据项扩大,确保了达到最小值作为最小支持度算法的地推性。 在关联规则挖掘的过程中,能有效地结合实际情况,挖掘出让用户感兴趣的规则[8],在最小支持度的基础上进行频繁项集挖掘,能够排除许多冗余特征和虚假规则,减少工作量、节省时间。 关联规则是指在特定数据集中频繁出现项集的规则[9],关联规则挖掘的重要方向就是从数据库中获取满足支持度和信任度阈值的规则。 在关联规则挖掘的过程中,频繁模式的发掘显得尤为重要。根据挖掘过程中所获结果的不确定性,关联规则的挖掘可以分为4种,分别是完全频繁项集挖掘、频繁闭项集挖掘、频繁表示集挖掘以及最大频繁项集挖掘。按照频繁项集向上闭包原则[10],最大频繁项集内具有全部频繁项集,并且在大多数挖掘过程中,最大频繁项集能够满足现实需求,故最大频繁项集挖掘具有较强适用性。 在待挖掘的用户群中,扫描其对应的数据集D,建立起访问页面矩阵,并以及访问整体数量进行统计,然后依次排序,进行矩阵扫描,按照排序顺序经访问页面建立起节点构建FP-tree树,最后按照排序,依次对树中每个结点进行一次访问,不小于支持度的作为频繁模式。 在访问页面按照顺序建立树节点,可准确、有效的挖掘频繁模式。(A,C,E),(A,D,E),(A,B,E)的支持度大于规定值,若依照常规树结构挖掘方法[11]输入后遍历,那么就不是频繁模式,继续调整顺序再次输入,因页面A,E的数量较大,而(A,E)的支持度不小于规定值,故是频繁模式。 为了更好地对关联规则进行有效挖掘。故描述算法如下: 输入:DB原有数据集,Lk是DB内的项集,db是新增数据集,s是指出度阈值[12]。 1)1项集挖掘 2)k项集挖掘 (11) 扫描db,累积在W内的项在db中的支持度,计算C在db中的支持度。 运用数据集缩减技术,把集合P作为非频繁项,若事务中包含P,可知该事务在频繁模式关联规则挖掘中,将不重要,可将其从数据集内去除。频繁扫描数据集DB和db,达到缩减数据集的效果。 使用多支持度中的最小值对频繁项集进行剪枝,降低了算法的时间复杂度,不会造成规则遗漏的现象,用时短,挖掘快速。 若数据库内有个结点分别是P1,P2以及P3,那么局部数据库就分为DB1,DB2和DB3。在任意结点的数据库如表1所示,最小支持度的阈值为minsup=0.4。 表1 局部数据库 从表1与minsup=0.4中得出全局的频繁项目。依据支持度的排列顺序,如表2所示。全局频繁项目的集合为: 表2 全局频繁模式及多段支持度 E={c,b,f,q,a,m,k} (12) 在结点P1,P2以及P3中,按照E建立FP-tree1,FP-tree2和FP-tree3。每个局部FP-treei仅包括全局频繁项目。 结点P1利用FP-tree1,采用频繁模式增长算法计算出DB1的局部频繁项集即 (13) 结点P2利用FP-tree2,采用频繁模式增长算法计算出DB2的局部频繁项集即 F2≠∅ (14) 结点P3利用FP-tree3,采用频繁模式增长算法计算出DB3的局部频繁项集即 F3={{c,b},{q,k}} (15) 中心结点P0汇总得到全部结点局部频繁项集的并集,其公式为 (16) 运用顶端和低端策略对F′实施修剪,获得挖掘的全局频繁项集为: F={{c,b},{c,a}} (17) 通过以上算法,可以很明确的在数据集中寻找到最终产生频繁模式进行关联规则有效挖掘,使挖掘更加便捷,算法性能优势更加明显,具有较强优越性。 为了验证挖掘方法的有效性,在实验中采用运行环境主机CPU主频是1.7GHz,2GB的内存容量,使用Windows XP操作应用系统,C++语言编程代码,数据结构定义以C++的STL标准模板库。 运用软件Clementine中交易数据集进行测试,其中有57354条记录,30个属性,分别表示商场内的饮品、面包、薯片等商品,在数据集中0代表无出售,1代表有出售。需要对原数据集预处理,获取出售2种商品以上的事务共42359条数据,以事务数据库规格保存在文件内。 根据多段支持度算法设置各项MIS,凭借项目在数据集内的实际频率乘以系数即f(i)×β,来分配MIS。在实验中β=0.1,图1作为多段支持度最小值算法、文献[1]算法以及文献[2]算法产生的运行时间比较。 图1 运行时间 从图1中可以看出,采用3种算法进行比较分析,多段支持度算法具有快速收敛的性质,其最终产生的运行时间始终保持平衡。图2作为关联规则的数量。 图2 关联规则数量 图2是置信度为10%的情况下,各个算法中赋有的关联规则的数量。从图中可以看出,多段支持度算法能够根据不同情况自动灵活调整各数据集内最小支持度,对待选集和频繁集进行收敛。上述实验采取了有效的剪枝,确保频繁模式的可行性,挖掘出最具有价值的关联规则。 图3用于检测不同方法的置信度,置信度也成为可靠度,置信区间范围越大证明方法的可靠度越高。从图3中可以看出,本文方法的置信范围始终在40之内,而文献[1]方法的置信范围较小,且多数在0处波动。可以证明本文方法置信度更高,准确性更好。 图3 不同方法的置信度 在多段支持度和数据集变化的情况下,进行关联规则挖掘,能够清晰、明确地发现其中所蕴含的频繁模式,再挖掘出频繁模式重要信息,提高挖掘性能。仿真结果表明:本文所提挖掘方法在基于多段支持度数据频繁模式关联规则挖掘中,相比其它方法在规则数量以及运行时间上都有显著的优越性。3 数据频繁模式关联规则挖掘
3.1 数据集缩减
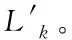
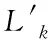
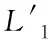
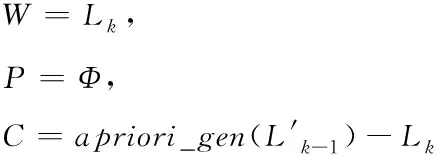
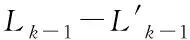
3.2 FP-tree算法

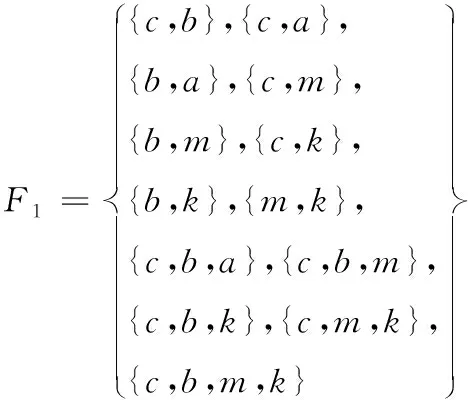
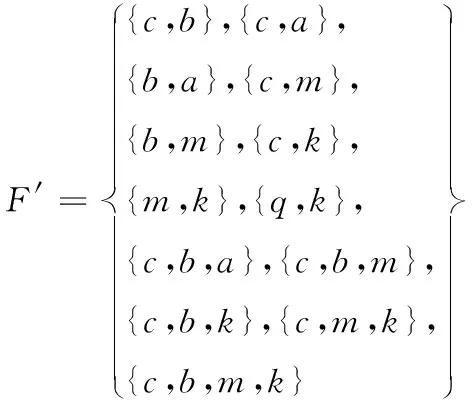
4 实验分析
5 总结
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
计算机应用与软件(2022年7期)2022-08-10
小型微型计算机系统(2022年4期)2022-05-09
电子制作(2022年1期)2022-01-28
哈尔滨理工大学学报(2021年4期)2021-10-07
计算机应用(2021年8期)2021-09-09
电子制作(2021年14期)2021-08-21
中国科技纵横(2016年20期)2016-12-28
