
知识数据库中非结构化文本关键信息抽取模型
2021-11-17 12:37郭炜杰包晓安
计算机仿真 2021年9期
关键词:集合
郭炜杰,包晓安
(浙江理工大学,浙江 杭州 310018)
1 引言
随着互联网技术[1]的飞速发展,计算机中以电子文档形式存储与处理的事件信息数量与日俱增。作为信息的主要载体与交流平台,互联网已成为不同信息的汇集处。尽管互联网使信息获取更及时、全面、便捷,但与此同时也带来了一定的负面影响。如信息搜索时间长、搜索结果模糊等。因此,为用户提供更准确信息的信息抽取技术[2]应时而生。大数据时代的到来导致存储于网络上的大部分信息数据形式均为非结构化[3]形式,这对现有信息抽取技术提出了巨大的挑战。为此,该领域相关研究者进行了大量的研究,并取得了一定成果。
文献[4]提出基于深度学习的信息实体抽取方法。该方法以简历信息为目标,利用数据清洗、分词等预处理手段,将非结构化信息变成词序列,再将word2vec无监督训练得到的词向量表映射成低维实数向量,采用LSTM层融合语境信息,CRF层获取全部标签序列分值,根据标签约束计算最优序列,完成信息的抽取。该方法在可有效将非结构化信息进行转化,且抽取的信息精度较高,但该方法在信息转化和最有序列获取中耗时较长,存在一定局限性。文献[5]提出 基于大数据技术的文档关键词提取方法。该方基于Hadoop平台的HDFS与HBase,分布式存储多种地学文档资料,自动读取、处理非结构化数据,通过融合多种算法,得出一种组合关键词提取,实现了相关信息数据的提取,但该方法研究的信息数据较少,存在信息数据抽取精度较低的问题。
针对上述方法中存在的不足,提出设计一种新的非结构化文本关键信息抽取模型。通过改进隐马尔可夫模型,挖掘观察值出现对前后状态标注的相关性关联,提升信息分类准度;应用势分布概率假设密度平滑算法,有效解决不完整训练样本引发的零概率事件与稀疏矩阵问题;改进Viberbi算法,增加状态序列的最优程度;结合观察值序列的正序、逆序解码,使信息抽取结果更加精准。与传统方法相比所提方法抽取的非结构化文本关键信息精度更高,效果更好。
2 隐马尔可夫模型的发生概率获取
2.1 隐马尔可夫模型
在非结构化文本关键信息抽取模型设计中,采用隐马尔可夫模型实现文本关键信息的抽取。
在隐马尔可夫模型中,待识别观察序列为可视层,马尔可夫过程为隐含层,该模型也是一个有限状态机[6],各状态转移均存在转移概率。利用五元组界定一个隐马尔可夫模型,即
λ={S,V,A,B,Π}
(1)
五元组中各参数表达式分别为
S={S1,S2,…,SN}
(2)
V={V1,V2,…,VM}
(3)
A={aij=P(qt+1=Sj|qt=Si)},i≥1,j≤N
(4)
B={bj(Vk)=P(Vt=Vk|qt=Sj)},
1≤j≤N,1≤k≤M
(5)
Π={πi=p(q1=Si)},1≤i≤N
(6)
上述各式中,与隐马尔可夫模型隐含层相对应的状态集为S,状态数量为N种;与模型可视层相对应的观察值输出集为V,输出数量有M个;N*N状态转移概率矩阵为A,由Si到Sj的状态转移概率为aij;N*M释放概率矩阵为B,状态Sj下模型释放单词Vk的概率为bj(Vk);模型初始状态概率集合用Π表示,当状态为第i个时,初始状态概率用πi表示。
2.2 改进隐马尔可夫模型
通过改进隐马尔可夫模型,挖掘观察值出现对前后状态标注的相关性关联。改进t时刻的观察值Oi出现与当前状态Si、t+1时刻状态Si+1之间的依赖关系。改进隐马尔可夫模型的发生概率为
BB={bij(k)=P(Ot=Vk|qt=Si,qt+1=Sj)}
(7)
根据上式将改进的隐马尔可夫模型界定为一个六元组,即
λ={S,V,A,B,BB,Π}
(8)
因训练文本的各样本与状态转移、符号输出路径一一对应。所以,模型参数估计通过最大似然法[7]实现,令模型中A,B,Π是为固定值,则采用下列表达式求解发生概率BB,即

(9)
式中,训练样本状态为Emission(i,j,k)。
在参数估计过程中,不完整的训练样本会引发零概率事件与稀疏矩阵。此时,可利用CPHD平滑算法[8]对其展开平滑处理,即
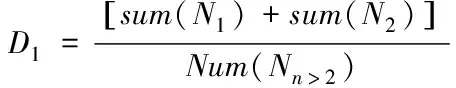
(10)

(11)
式中,当样本在训练样本里的发生次数为1时用N1表示,发生次数为2时用N2表示;对应样本占比为sum(N1)、sum(N2);N1样本的发生次数总和为Num(N1)。在平滑处理阶段,超过两次发生次数的事件需与折扣系数D1做差,而零概率事件则要与折扣系数D2做和,确保∑P取值为1。
2.3 非结构化文本关键信息抽取模型
假设模型处理对象为中文引文,为抽取出引文含的文本关键信息段,诸如:标题、作者、期刊名称等,构建基于改进隐马尔可夫模型的抽取模型。
2.3.1 Viterbi优化解码算法
在模型参数估计完成后,采用Viterbi解码算法选取出最优状态序列,该序列在给定观察值序列的相应状态序列内具有最大概率。在改进隐马尔可夫模型时,将其从五元组转变为六元组,因此,对Viterbi算法[9-10]也需做出对应的优化改进。

若q1,q2,…,qt(qt-1=Si,qt=Sj)表示路径,O1,O2,…,Ot为该路径上t时刻的释放观察值序列,其最大概率为δt(i,j),即:
i≥1,j≤N,2≤t≤T
(12)
推导得出t+1时刻释放观察值序列最大概率表达式为
j≥1,k≤N,2≤t≤T-1
(13)
假定记录节点数组为ψt+1(j,k),利用以下Viberbi优化算法流程,获取最优状态序列。
步骤1 :采用下列各式实现释放观察值序列的初始化处理,即
δ2(i,j)=πiaijbi(O1)bij(O2)
(14)
ψ2(i,j)=0
(15)
其中,i≥1,j≤N。
步骤2 :当满足j≥1,k≤N,2≤t≤T-1时,可得出以下表达式
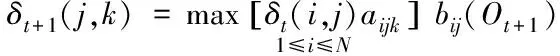
(16)

(17)
步骤3:终结操作主要通过下列两个表达式完成

(18)

(19)
步骤4 :利用下列表达式获得最优状态序列

(20)
2.3.2 逆序Viterbi解码算法
采用Viberbi优化算法解码观察值序列O=(O1,O2,…,OT)时满足下列等式
P(qi+1|q1,q2,…,qi)=P(qi+1|qi)
(21)
该式表明O1的标识状态对O2状态有决定性作用。
针对观察值序列O′=(OT,OT-1,…,O1),t时刻的状态qt决定t+1时刻状态qt+1。此时,O2的标识状态对O1状态有决定性作用。综上所述,解码观察值序列O′=(OT,OT-1,…,O1)的关键点为:基于观察值序列O=(O1,O2,…,OT),t+1时刻的状态qt+1决定t时刻状态qt,此时需满足下列等式
P(qi|q1,q2,…,qi,qi+1)=P(qi|qi+1)
(22)
2.3.3 歧义消除
经过解码观察值序列,对比得到的正序解码序列与逆序解码序列,滤除无解码歧义的状态,筛选出存在的解码歧义与前N(N≤3)个状态,对歧义进行消除。
已知状态序列S=(S1,S2,…,Si,…,SN)的发生概率表达式为
P(S)=[P(S1),P(S2|S1),…,P(SN|S1S2…SN-1)]
(23)
结合观察值序列的正序、逆序解码,得出以下两个状态序列为
S=(S1,S2,…,Si,…,SN)
(24)
S′=(S′1,S′2,…,S′k,…,S′N)
(25)
式中,状态Si的观察值等同于状态S′k的观察值,且满足i+k-1=N。若两状态的观察值存在差异性,则提取出状态序列TS与TS′,前者包含状态Si在内的前n(n=min(i,k))个状态,后者包含状态S′k在内的后n个状态。采用常用于词性标注的统计语言模型——N-Gram模型[11-12],对序列概率P(TS′)、P(TS)进行求解,最佳解码序列即为最大概率的状态序列,也就是所要抽取的文本关键信息。
3 仿真分析
3.1 仿真环境
为验证所提方法的有效性,进行仿真分析。实验在Matlab 平台上进行,操作系统为Windows XP 系统,运行内存为8 GB ,CPU 为3.6 GHz。
3.2 仿真参数
实验中在搜索引擎中检索附有答案的NLPCC 2017问答评测问题集,经过预处理后,从中抽选15000条数据作为实验用数据集,验证抽取模型的有效性。其中,由百度搜索引擎检索得到的文本片段分别为候选信息集与候选信息句集,如果候选信息答案正确,则标注1;反之,则标注0。由训练集与测试集组成所用数据集,各类语料具体分布情况如表1所示:

表1 数据集语料分布信息统计表(单位:条)
利用IG方法对文本各信息特征的重要性展开检验,特征重要性与信息增益得分之间成正相关,文本各信息特征的重要性如表2 所示:

表2 文本信息特征重要性统计表
3.3 仿真指标
基于相同数据集,利用准确率precision、召回率recall、综合指标F,对比抽取出的关键词集合,检验模型的抽取性能,各指标计算公式为

(26)
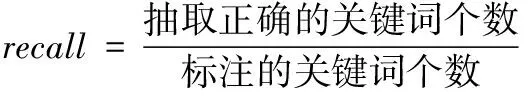
(27)

(28)
3.4 仿真结果分析
为验证所提方法的有效性,从数据集中选取人物、地点以及时间等关键词,对比了所提方法、深度学习的信息实体抽取方法以及大数据技术的关键词提取方法的关键词抽取效果如图1 所示。

图1 不同方法抽取效果对比
分析图1 可以看出,在相同实验环境下,采用三种方法进行文本关键信息的效果存在一定差异。其中,采用所提方法抽取文本关键信息的准确率、召回率以及综合指标值均在0.9 以上,而其它两种方法抽取文本关键信息的准确率、召回率以及综合指标值始终低于本文方法。这是由于本文模型改进了隐马尔可夫模型与Viberbi算法,解决了零概率事件与稀疏矩阵问题,取得了最优状态序列,通过对比得到的正序解码序列与逆序解码序列,滤除了无解码歧义的状态,消除了歧义,进而提升了关键信息抽取准度,验证了所提方法的科学有效性。
为进一步验证所提方法的可行性,实验对比了三种方法在抽取文本关键信息的耗时,实验结果如表3 所示:
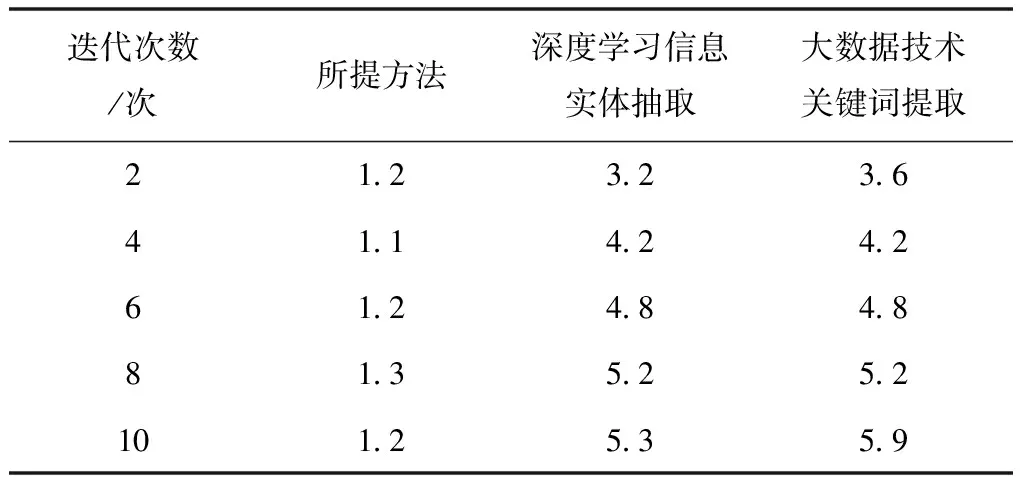
表3 不同方法文本关键信息抽取耗时(s)
分析表3 中数据可以看出,随着迭代次数的改变,三种方法抽取文本关键信息的耗时随之发生改变。其中,所提方法的抽取耗时始终低于1.3 s,深度学习信息实体抽取方法的耗时最短约为3.2 s,大数据技术关键词提取的最短耗时约为3.6 s,始终高于所提方法,验证了所提方法的可行性。
4 结论
文本信息抽取技术是自然语言处理领域的重要组成部分,随着信息技术的发展与应用,文本信息抽取技术成为研究热点,并引起了广泛关注,为解决其存在的弊端与问题,本文以知识数据库为背景,构建出一种非结构化文本关键信息抽取模型。通过改进隐马尔可夫模型与Viberbi算法,解决零概率事件与稀疏矩阵问题,获取正序解码序列与逆序解码序列,滤除无解码歧义的文本状态,实现了文本关键信息的抽取。实验结果表明:采用所提方法抽取文本关键信息的准确度始终高于0.9,且抽取的耗时较短。
猜你喜欢
数学教学通讯·高中版(2017年5期)2017-05-17
艺术科技(2016年12期)2017-05-04
中学生物学(2017年3期)2017-04-11
理科考试研究·高中(2017年2期)2017-04-08
数学学习与研究(2017年2期)2017-03-06
艺术评鉴(2016年18期)2017-02-22
青年时代(2016年30期)2017-01-20
考试周刊(2016年50期)2016-07-12
考试周刊(2016年26期)2016-05-26
教师·上(2016年4期)2016-05-06
