
结合区块链的非结构化大数据云存储优化研究
2021-11-17 07:35徐智,王岳,王欣
计算机仿真 2021年7期
徐 智,王 岳,王 欣
(1. 三江学院机械与电气工程学院,江苏 南京 210012;2. 江苏科技大学船舶与海洋工程学院,江苏 镇江 212003)
1 引言
传统网络中,数据大部分以结构化形式传递与存储,随着云计算网络的发展,非结构化数据大量涌现。所谓非结构化,表示不具有固定格式,不具有约定规则[1],这类数据不容易统一处理,也不利于理解。但是在IDC的统计报告中提到,这类无规则数据的年增长速度超过60%,在2020年会达到40ZB。当前,Google日处理网页量在20PB以上;Facebook日存储数据量在15TB以上;一些实验室和教育机构的非结构化数据日生成量也在TB或者PB级别,其中,主要由本文、网页、音视频等组成。依托着云计算,非结构数据正在向着海量发展,其存储负担和存储成本也急剧上升,同时,对非结构大数据的持久化和操作也有着严格的可靠程度和时延要求。在其优化存储研究中,可靠程度的保证主要是采取冗余持久化机制;而在提高时效方面,由于现有的存储机制采取的是统一结构处理,将其直接向非结构化拓展存在很大难度,所以针对非结构化存储机制和存储方法的优化亟待解决[2]。采用Hadoop集群并行存储,是当下主流的持久化框架,但是还需要在此基础上部署数据清洗和存储调度策略等。有学者[3]设计了有关节点类型的存储方案,根据节点所属类型,以及相应的流行度对数据采取差异性存储。这种存储机制有利于降低云存储数据的传输距离与访问时延,但是没有针对非结构化数据的优化处理。也有学者[4]提出了UDSS存储,通过MongoDB[5]或者NoSQL数据库的拓展查询机制,与其它组件集成非关系数据库[6]。另外,非结构化数据由于不规则,在云存储过程中很容易受到损坏,因此通常进行数据审计。当前多采用三方审计,这种方法存在着单点失效、时间开销增加等问题。考虑到区块链网络具有良好的去中心化和拓展能力[7],可以替代三方审计,改善交互速度。为此,本文在优化非结构化大数据云存储方法的同时,引入区块链,并在区块链网络中对数据进行完整性验证,进一步提高非结构化大数据的云存储性能。
2 非结构化大数据云存储设计
根据云环境中的分布与偏好差异,将数据调度方程描述如下
mij=w1a+w2b+w3c+w4d
(1)
这里的w1~w4为加权系数,它们的和为1;a项为云存储数据包采样时间成本;b项为数据包符合要求的程度;c项为存储质量;d项为存储消耗。假定云环境面临的非结构化数据总量为n,对应的持久化集合为(1,2,…,n+a),a>0。集合中n+a代表网络中节点的数量,也代表了存储的数据量。由此可以得到任意存储数据,如下所示
yi=λi[x1,x2,…,xn]
(2)
其中,λi是域F2={0,1}中的行向量;xi为数据包。为保证数据包的唯一性,构成向量λi的元素应符合如下分布规则
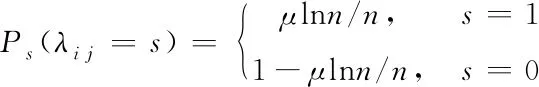
(3)
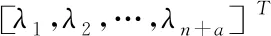

(4)

(5)
其中,v是节点总数。在存储节点选择概率为0.5时,非满秩概率关系化简成pfailure≤(0.5)a。考虑到存储过程中的损耗受节点数量影响,将其关系采取指数形式表示为

(6)
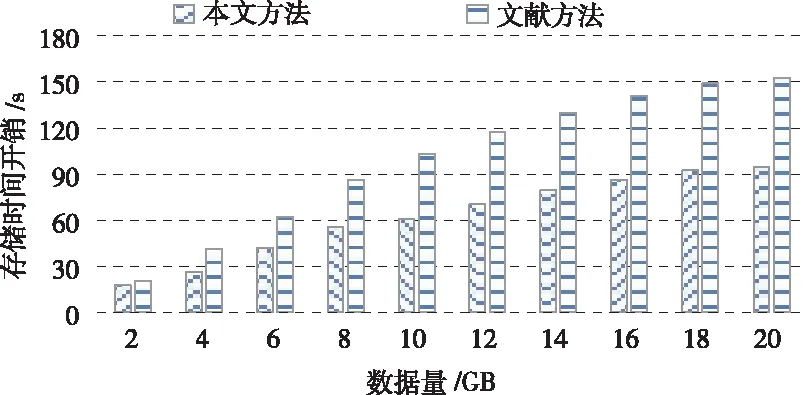
在进行存储操作时,本文采用了F2={0,1}域获得存储所需信息。调度控制根据域首判断出数据状况,并实时更新存储策略。将调度控制存储窗表示为{di|i=1,2,…,m},包采集窗表示为{dj|j=m-k+1,…,m}。其中,k为采集窗大小,且k (7) 对下一轮存储数据包进行预估,dm+1代表实际值;m+1代表估计值。于是,可以得到关于数据的动态振荡 (8) 当D(m,k)增加,即云环境中的非结构化大数据振荡活跃时,应该加速存储频次;当D(m,k)减小,即云环境中的非结构化大数据振荡活跃度下降,应该降低存储频次。 为了更好的提升非结构大数据云存储效率,引入审计方案进行优化存储。首先对云存储数据包采取审计需求分析。存储数据包是否进行审计,审计的必要程度有多大,受数据包的属性〈dv,hv〉影响,dv表示数据损坏的概率;hv表示数据热度。把单一属性的与审计需求关系扩展至数据包级别,得到云存储数据包的存储审计需求如下 (9) Qmax是最大审计需求;μ1、μ2依次是属性dv与hv的加权系数。 然后对数据存储时间采取审计。由于对时间进行审计能够确定数据存储的时间消耗,在完成数据存储的前提下尽可能降低节点存储时间。假定数据包存储集合是{D1,D2,…,Dn},任意数据包Di被存储次数是ci,于是可以得到存储审计时间如下 (10) 其中,ti,j代表第j次存储审计的耗时。再对云存储数据包的数量进行审计。根据审计周期将存储数据包采取正序排列{T1,T2,…,Tu},在第i个周期内数据包存储所需的平均耗时是τi,于是可以得到存储数据包的数量审计如下 (11) 对于周期Ti,如果取值偏小,会使审计结果急剧上升;如果取值偏大,则会使存储数据包的审计集合过于庞大。审计过程中,结合匹配指标尽可能保证数据包分散在各个周期中。这里将匹配指标定义如下 Maudit=(Sp-Smin)/Smin (12) 其中,Sp为审计强度;Smin为满足存储数据审计需求的Sp下限。Maudit指标用于衡量审计处理的偏差。当Maudit>0时,说明审计的强度超出需求范围;当Maudit<0时,说明强度在需求范围内;当Maudit=0时,说明强度正好满足需求。Sp指标能够体现存储数据的审计效果,如数据识别能力。假定将数据审计效果表示为关于审计周期的键值对形式〈Tv,Zv〉,其中Zv表示Tv周期内的数据识别率。则对应的Sp指标表示如下 (13) Smax代表最大审计强度;Tmax、Zmax依次为Tv与Zv的最大值;η1、η2依次为Tv与Zv的加权系数。 云计算采用数组与Merkle树对非结构化大数据进行存储。将保存非结构化数据的数组以一对一的形式映射至Merkle树,数组结构包含ID与Merkle根节点地址。这样一来,在有数据增加的情况下,就转变为数组相应Merkle树的操作。Merkle树由inner与leaf两种节点构成,其中,leaf采用(O,Hash,)形式数据结构,它的Hash选取的是同态Hash[8],O表示加密数据ID和数组ID,表示D的加密数据。inner采用(O,Hash)键值对形式的数据结构,它的Hash选取的是MD5,O表示leaf内的最大O值。假定任意非结构化数据D(ID,NAME,d1,d2,d3),在区块链中,根据ID和NAME分辨数据,所有节点会通过共享密钥实现除ID和NAME以外的加密处理[9]。当系统存在数据更新,只需要对加密后的数据进行修改,于是,数据更新过程描述为 UD=(1+Δd1,2+Δd2,3+Δd3) (14) 根据数据更新计算可知该过程符合同态Hash。在区块链结构设计中,其首部组件有父Hash、Merkle根Hash、时间戳,以及所在区块Hash。其中,父Hash用于构造链型结构,指向了前一区块Hash。所在区块Hash是由其余三个组件经过MD5计算得到,该Hash将会作为下一区块的父Hash。区块体组件有HashTable、Merkle树和认证路径。其中,HashTable用于存放区块链网络验证的请求,根据这些请求创建Merkle树。在Merkle树中,由leaf构成的数组即为认证路径。在区块链网络的创世区块中,父Hash和Merkle均是空值,创世区块Hash仅由时间戳计算得到。图1描述了本文的区块链模型。 图1 区块链模型 考虑到非结构化大数据云存储过程中,存储数据完整性审计依托于三方引发的存储效率下降问题,基于区块链网络实现数据完整性验证。验证阶段,区块链网络授权中心首先根据计算得到密钥键值,然后节点将非结构化数据采取加密、Hash操作,得到Lk(),并传送出去。云计算网络接收到数据后经过审计进行存储,同时得到区块链网络加密数据的Merkle树叶子节点。当区块链网络发现数据存在更新,则将Merkle对应的叶子节点进行修改。网络中负责验证的节点会随机选择数据ID,与云存储网络、区块链网络中该ID数据相关的节点做验证。云存储网络搜索到数据标签后回送响应至区块链网络节点,一起回送的还有Merkle树根Hash,区块链节点搜索到对应标签Lk()后对比Merkle树根Hash,当确认Hash值一致时,则表明验证成功,数据完整性验证结束。 基于4台PC建立实验平台,配置为:Ubuntu12.04.3系统,16GB内存,150GB ATAHitachiHTS54501硬盘。其中,2台PC建立云存储网络集群,部署非结构化数据存储方法与存储审计策略。另外2台PC建立区块链,部署验证策略。仿真时间设定24h,审计策略参数设置为μ1=μ2=0.5,η1=0.3,η2=0.7,dmax=0.3,hmax=2,Tmax=5,Zmax=1。 首先,仿真确定格式差异对非结构化数据云存储时间的影响,实验用的非结构化数据含有文本、图像、网页三种格式,总量达到100万条。在文本、图像、网页三种格式下,依次改变请求进程的数量,得到存储时间的变化情况,结果如图2所示。根据存储时间的变化曲线可知,在请求进程数量相同时,三种格式数据的存储时间比较接近,说明非结构化数据的格式差异并不会导致存储时间的明显差异,方法对于格式差异的非结构化数据具有良好的普适性。在请求进程增加的过程中,存储时间的增速在逐渐放缓,并接近与平稳,表明本文提出的非结构化数据云存储方法能够应对大量请求访问,具有良好的大数据处理能力。 图2 三种格式非结构化数据存储时间 再针对存储数据完整性审计功能进行验证,在给定数据包为1024kB的前提下,通过递增数据包数量,仿真得到数据完整性审计的时间开销,结果如图3所示。本文引入TPA[10]审计作为对比,根据结果对比可知,本文的完整性审计时间开销明显缩短,且受数据包数量影响较小。在给定数据包数量为100的情况下,依次增加数据包的大小,每次增幅为1024kB,通过仿真得到此时数据完整性审计的时间开销,结果如图4所示。根据数据完整性审计结果可以发现,两种方法的审计时间受数据包数量变化影响较小,受数据包大小的影响较大,但是经过与TPA审计对比可知,对于同样大小的数据包,本文方法所需的审计时间明显更短,且随数据包大小变化的增幅更为缓慢。数据完整性审计时间开销的缩短,是由于云存储网络每接收固定个数据包就会构造出相应的区块数据,由区块链网络完成数据完整性审计,并且结合匹配指标尽可能保证数据包分散在各个审计周期内,避免云存储节点出现空闲和审计急剧上升的情况。 图3 存储数据量对完整性审计时间的影响 图4 数据包大小对完整性审计时间的影响 最后,为了验证本文方法在非结构化大数据云存储时间开销上的性能优势,仿真过程中通过依次递增非结构化数据的大小,得到云存储的时间开销,并与文献[3]方法的性能做对比,结果如图5所示。根据结果对比可知,本文方法的非结构化大数据云存储时间开销明显小于对比方法,存储效率显著提升。 图5 非结构化大数据云存储时间开销 本文提出了基于区块链技术的非结构化大数据云存储方法。针对云存储网络端的非结构化数据,通过域分析获得存储信息,根据估算的数据振荡情况动态调整存储频次。同时在云存储网络端设计了数据存储审计方案,旨在提高数据存储效率。为了保证非结构化大数据云存储的完整性验证效率,引入区块链技术,设计了相应的区块链网络结构,并在其中实现了数据完整性高效验证。通过仿真,证明了本文所提方法对于格式差异的非结构化数据具有良好的普适性,且显著提高了非结构化数据的云存储效率,能够有效应对大量请求访问数据,具有良好的大数据处理能力。

3 云存储数据审计
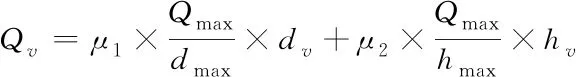
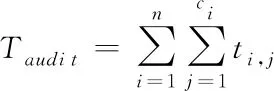

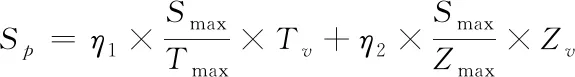
4 区块链网络设计

5 实验与结果分析
5.1 实验参数设置
5.2 实验结果分析



6 结束语
猜你喜欢
课堂内外·好老师(2022年3期)2022-04-25
学习与科普(2022年17期)2022-04-23
计算机与数字工程(2022年3期)2022-04-07
云南教育·小学教师(2021年12期)2021-03-23
福建基础教育研究(2020年3期)2020-05-28
红楼梦学刊(2020年3期)2020-02-06
物联网技术(2018年8期)2018-12-06
金桥(2018年7期)2018-09-25
当代贵州(2018年21期)2018-08-29
南都周刊(2018年6期)2018-06-23
