
一种基于IC参数的知识图谱嵌入方法
2021-11-16 08:14赵晓函周子力李天宇陈丹华王凯莉
中文信息学报 2021年10期
赵晓函,周子力,李天宇,陈丹华,王凯莉
(曲阜师范大学 网络空间安全学院,山东 曲阜 273100)
0 引言
近年来,许多知识图谱,如WordNet[1]、Freebase[2]、NELL[3]以及YAGO[4]等,已经成为智能问答、新闻推荐等很多实际应用的重要资源。知识图谱是由节点和不同类型的边组成的语义网,其中节点表示真实世界中的实体,不同类型的边表示实体之间的语义关系[5]。知识图谱是结构化的知识库,通常将知识表示为(头实体,关系,尾实体)形式,即三元组(h,r,t)[6]。但是元组的底层符号特性使其不能有效表示实体之间的语义关联,并且难以实现知识图谱的智能化应用,智能化应用通常以深度学习等机器学习算法为支撑,而这些算法需要数值形式的输入[7]。
为了解决上述问题,知识图谱嵌入应运而生,并涌现了多种嵌入方法。其中,以深度学习为代表的嵌入学习技术在人工智能领域广受关注,其主要思想是通过机器学习的方法将知识图谱中的实体和关系表示成低维稠密向量,使得实体和关系分别嵌入表示[8]。目前,基于距离的翻译模型简单有效,如TransE[9]适用于一对一关系,将关系看作头实体和尾实体之间的一种平移。之后出现的拓展模型TransH[10],TransR[11],TransD[12],TransA[13]等,主要解决了TransE无法处理复杂关系的问题。TransC[14]在知识图谱嵌入时区分了概念和实例,将概念和实例分别建模为空间中的球体和点。然而,模型训练结束后的部分概念球体半径不符合其目标函数;同时学习三元组时并未考虑概念本身具有的信息量。
概念c的信息量[15](Information Content,IC)是指概念c在某给定语料库中出现的概率p(c)的负对数。一个概念在树形结构中所处的位置越高,所提供的有效信息就越少。IC值主要用于语义相似度计算,而对于一些涉及概念的知识图谱嵌入模型(如TransC),引入IC参数能够使模型对概念进行表示时捕获更多的语义特征,从而更有效地完成链接预测、三元组分类等任务。因此本文利用树形结构IC计算模型计算出每一个概念的IC值,进而求出对应的球体半径,使概念拥有丰富的语义信息,得以进一步增强知识图谱的嵌入效果。
1 相关工作
知识图谱嵌入方法可分为平移距离模型和语义匹配模型两大类[16]。前者又包括基于距离的翻译模型和其他距离模型,使用基于距离的损失函数;后者主要包括矩阵分解模型和神经网络模型,使用基于相似度的损失函数。其中,基于距离的翻译模型是当前知识图谱表示方法的研究热点,主要包括Trans系列模型。2013年Bordes等人提出TransE[9],其主要思想是将三元组(h,r,t)中的实体h,t和关系r表示在同一低维语义空间,使得h+r≈t。然而TransE在处理一对多,多对一及多对多复杂关系时仍然存在一些缺陷。
为解决TransE中的问题,一系列拓展模型随之产生。当涉及不同关系时,TransH[10]使得一个实体具有不同嵌入表示。首先将一个关系r建模在一个法向量为Wr的超平面,然后将三元组(h,r,t)中的实体嵌入h,t投影到关系超平面。虽然可以有效地处理复杂关系,但假设实体、关系在同一语义空间不利于TransH的充分表示。
TransR[11]致力于解决TransE和TransH的表示问题,为每个关系设置一个传递矩阵Mr,将三元组(h,r,t)中的h,t从实体空间嵌入到关系空间。虽然效果显著提升,但这一过程属于实体和关系的交互,TransR中的传递矩阵不应该仅考虑实体之间的关系。
TransD[12]同时考虑到不同类型的实体和关系,每一关系实体对(r,e)都会具有一个投影矩阵Mre,用于将实体信息嵌入投影到关系向量空间。如此改进了TransR的不足,使性能得到提高。
另外,矩阵分解模型通过矩阵分解进行知识图谱表示学习。以RESCAL[17]为例,将每个实体关联向量从而捕获其潜在语义,每个关系都表示为一个矩阵,该矩阵对潜在因子间的成对交互关系进行建模。许多RESCAL的扩展如DistMult[18],将矩阵约束为对角矩阵以简化RESCAL;HolE[19]结合了RESCAL的表达能力及DistMult的简单性。还有DistMult的扩展如ComplEx[20],通过引入复值嵌入来更好地建模不对称关系。
2 TransIC知识嵌入方法
针对TransC中部分球体半径不满足模型训练目标和概念语义信息表示不足这两个问题,TransIC结合IC参数提出了新的计算概念球体半径的方法来加以解决。
2.1 TransC问题分析
TransC[14]提出之前,Trans系列模型都将实体和关系以相同的方式编码为低维语义空间中的向量。TransC尝试在同一语义空间中按照不同方式表示概念、实例和关系。具体而言,TransC将每个概念编码为一个球体s(p,m),其中,球心p∈Rk表示概念向量;Rk表示维度为k的向量空间,m为球体半径,用于判断实例与概念和子概念与概念的相对位置关系。对于每个实例i∈I和实例关系r∈Rl,分别学习一个低维向量i∈Rk和r∈Rk,其中实例用点表示。然后使用球体与点的相对位置关系表示概念与实例间的关系(instanceOf),球体与球体的相对位置关系表示子概念与概念间的关系(subClassOf),点与点的相对位置关系表示实例与实例间的关系(relational)。对于subClassOf关系,两个概念之间可能的相对位置如图1所示,其中,符号“∧”表示“并且”。
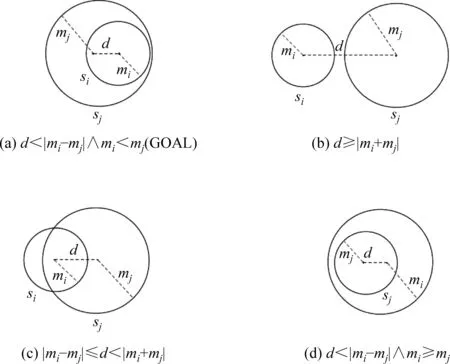
图1 球体si和sj之间的四个相对位置
对于给定正确三元组(ci,rc,cj),其中,ci和cj分别表示子概念和概念,rc表示subClassOf关系,如图1(a)所示,TransC的训练目标为概念球体sj包含子概念球体si,故表示子概念大小的球体半径mi应小于表示概念大小的球体半径mj。然而,表1中列举出了3对经TransC训练得到的子概念球体半径大于概念球体半径的情况,如子概念“Artists_from_California”的球体半径(0.597 961)大于概念“artist”的球体半径(0.406 852),表明TransC在训练中迭代更新得到的部分球体半径仍存在不合理之处,导致学习得到的概念嵌入向量不够准确。

表1 TransC部分子概念与概念球体半径结果分析
2.2 TransIC
2.2.1 概念球体半径求解方法
概念IC值是概念本身所包含的信息量,具体含义为:概念c出现的概率越大,其包含的自信息量就越小[21]。IC计 算主要分为基于统计和 基 于树形结构两种方法[22],前者通过求解概念c在给定语料库中出现的概率得到IC值;后者最早由Nuno[22]提出,Nuno认为,树形结构中叶子节点比非叶子节点包含更大的概念信息量。该方法的IC计算模型如式(1)所示。
(1)
其中,hype(c)是概念c在树形结构中所有子节点的总数,Nodemax是概念节点的总个数。
根据信息论,同一个概念出现的次数与其包含的信息量(IC)成反比。对于子概念-概念结构,子概念出现的次数小于概念出现次数,则子概念IC值大于概念IC值。然而TransC的训练目标为概念球体包含子概念球体,即概念球体半径大于子概念半径,因此根据Nuno提出的IC计算模型给出概念球体半径求解方法,半径计算方法如式(2)所示。
(2)
概念球体半径具体求解步骤如下:
(1)统计出训练数据中所有概念的总数N;
(2)分别统计出每个概念出现的次数,记为Nci。如图2所示,左子树自底向上递归过程为:

图2 概念次数统计示意图
a.实例层节点Y7~Y10各出现1次;
b.子概念层Y3=Y7+Y8+1,Y4=Y9+Y10+1;
c.概念层Y1=Y3+Y4+1,右子树同理。
(3)计算得到概念球体半径如式(3)所示。
根据式(3)求出的概念球体半径满足TransC模型训练目标,即子概念球体半径小于概念球体半径。具体对比结果如表2所示。

表2 TransC与TransIC的部分概念与子概念球体半径对比结果
2.2.2 模型构建
TransC采用随机值的方式初始化实例向量i、概念向量p和概念半径m。其中,m在(0,1)内随机取值初始化,并在随机梯度下降SGD(stochastic gradient descent)中不断迭代更新,导致TransC中的部分球体半径在训练结束后仍存在与优化目标相反的情况,并且忽略了概念中应包含的语义信息内容,使得概念的嵌入向量存在偏差。
TransIC模型中,概念球体的半径通过新的半径计算方法生成,不再由随机值初始化,且随机梯度下降中不再迭代更新,所有的球体半径一直保持初始值,如式(4)所示。
其中,mi表示第i个球体的半径大小,ICi(c)表示第i个概念的IC值。
TransIC可建模的关系分为三类:实例与概念间的关系(instanceOf)、子概念与概念间的关系(subClassOf)以及实例与实例间的关系(relational)。对此,模型分别定义不同的损失函数来测量嵌入空间中的实例与概念、子概念与概念及实例与实例之间的相对位置,并且同时学习概念、实例和关系的表示。
(1)instanceOf:给定一个实例i,概念c,若它是正确三元组(i,re,c),则i应该在球体s内部,re为instanceOf关系。损失函数如式(5)所示。
(2)subClassOf:对于一个正确的子概念与概念三元组(ci,rc,cj),子概念ci,概念cj分别被编码为球体si(pi,mi)与sj(pj,mj),且sj应包含si,rc为subClassOf关系。两个球心之间的距离定义为d=‖pi-pj‖2。损失函数如式(6)~式(8)所示。
fc(ci,cj)=‖pi-pj‖2+mi-mj
(d≥|mi+mj|)
(6)
fc(ci,cj)=‖pi-pj‖2+mi-mj
(|mi+mj|≤d<|mi+mj|)
(7)
fc(ci,cj)=mi-mj
(d<|mi+mj|∧mi≥mj)
(8)
其中,式(5)中m=1-IC(c),式(6)~式(8)中mi=1-ICi(c),mj=1-ICj(c)。
(3)relational:给定一个实例关系三元组(h,r,t),采用与TransE[5]相同的学习方式。损失函数如式(9)所示。
2.2.3 训练目标及算法
对于instanceOf三元组,Se和S′e分别表示正例三元组集合和负例三元组集合。将下面基于边际的损失函数定义为训练目标,如式(10)所示。
其中,[x]+≜max (0.x)表示模型的输出值为0或x,γ是边际参数。同样地,对于subClassOf三元组,Sc和S′c分别表示正概念三元组集合和负概念三元组集合,训练目标定义如式(11)所示。
对于relational三元组,Sl和S′l分别表示正关系三元组集合和负关系三元组集合,训练目标定义如式(12)所示。
最后,整体训练目标定义为上述三个函数的线性组合如式(13)所示。
TransIC采用TransH[10]中的抽样策略替换头实体或尾实体,并使用随机梯度下降的方法对目标函数进行优化,具体训练过程如表3所示。

表3 TransIC训练过程
3 实验验证
本文采用YAGO数据集的一个子集YAGO39K验证与评估TransIC模型的性能。完成知识图谱嵌入中的两个典型任务——链接预测和三元组分类,并与其他模型进行对比分析。YAGO39K的统计信息如表4所示。

表4 YAGO39K数据集统计信息 (单位:个)
其中,subClassOf关系中包含概念-子概念(2层树结构)、概念(1层树结构)及子概念(1层树结构)三种层级;instanceOf关系分为子概念-实例(2层树结构)和概念-实例(2层树结构)两种层级;relational关系无层级。
3.1 链接预测任务定义及实验分析
链接预测的目的是预测关系三元组(h,r,t)中缺少的头实体h、尾实体t或关系r。具体实验如下:
(1)评估标准。对于测试集中的每个关系三元组(h,r,t),将头实例h或尾实例t随机替换为给定知识图谱中任一实例得到负例关系三元组(h′,r,t)或(h,r,t′);然后利用损失函数fr计算关系三元组和负例关系三元组的距离并对其升序排列。此任务使用两个评估指标:所有正确实例排名倒数的平均值MRR和排名不大于N的正确实体的比例Hits@N。MRR和Hits@N越高说明实验结果越好。然而,若负例关系三元组仍然存在于知识图谱中,则会对关系三元组的排序结果产生干扰。所以排名前需要从训练、验证、测试集中过滤掉干扰三元组,此过程称为Filter,用“Filt”表示。未过滤的评价设置表示为“Raw”。
(2)实验设置。TransIC进行训练时,随机梯度下降学习率λ从{0.1,0.01,0.001}中选择,边际参数γl,γe和γc从{0.1,0.3,0.4,1,2}中选择,实例向量和关系向量维度n从{20,50,100}中选择。多次实验得出最优参数配置为:γl=1,γe=0.4,γc=0.3,n=100,以L1范式作为相似性度量。构造负例关系三元组的方法为:使用“unif”表示分别以50%的概率替换头实体或尾实体的传统方法,使用 “bern”表示伯努利抽样策略,即对于一对多关系三元组,以更高概率(大于50%)替换头实体;对于多对一关系三元组,以更高概率替换尾实体。模型训练时迭代1 000次。TransIC与其他模型链接预测对比结果如表5所示。

表5 关系三元组链接预测对比结果
从表5中得出:(1)TransIC在Filt设置下的平均排名倒数MRR及排名前1、3、10的比例Hits@1、Hits@3、Hits@10指标均高于TransC及之前的其他模型。尤其是unif采样下的Hits@3,与模型中最好的TransC相比提高了3个百分点,bern采样下的Hits@3提高了1.5%;其次是unif采样下的Hits@1和Hits@10,均比TransC提高了0.9个百分点,而bern采样下分别提高了0.2%和0.7%,这进一步表明,TransC和IC参数结合求出概念球体半径的方法是合理有效的,TransIC模型包含丰富的概念语义信息,使得链接预测指标结果得到提高。(2)与其他模型相比,TransIC在Raw设置下的MRR指标稍低。其中unif采样下的MRR(Raw)比模型中最好的TransE降低了0.027,不过bern采样下的MRR(Raw)仅降低了0.001,差别相对不明显。分析其原因,在选取最优实验参数配置时,TransIC根据整体指标效果设置参数,没有单独针对MRR选取实验参数的最优配置。(3)另外,TransIC实验中unif采样方法整体优于bern采样方法,Filt实验结果优于Raw实验结果。
3.2 三元组分类任务定义及实验分析
三元组分类用来判断给定关系三元组是否正确,也就是对关系三元组进行二分类。在YAGO39K数据集上,采用与链接预测相同的方式得到负例关系三元组。根据损失函数fr计算给定关系三元组(h,r,t)的相异性得分,若得分低于一个阈值δ,则预测为给定关系三元组,否则为负例关系三元组。
此任务使用四个评估指标:准确率(Accuracy),查准率(Precision),查全率(Recall),查准率与查全率的调和平均(F1-Score)。四个指标越高说明模型的效果越好。实验中采用与链接预测相同的参数配置以及L1度量,采样策略为unif方法和bern方法,所有训练元组迭代1 000次。TransIC与其他模型的三元组分类实验对比结果如表6所示。

表6 三元组分类实验对比结果 (单位:%)
从表6可以得出:(1)在Precision指标上,bern采样下的TransIC与模型中最好的TransC取得了相同的实验结果,并对比于其他模型效果提升。(2)在Accuracy、Recall及F1-Score指标上,TransIC均相较于其他模型欠佳。其中,在unif采样下比各自最好的模型分别降低了1.4%、1.8%和1.4%,而在bern采样下比各自最好的模型分别降低了0.9%、2.3%和1%。这说明TransIC在三元组分类中表现的不是很好,仅在Precision指标上与最好结果持平。分析主要原因有两个:一是实验数据集中具有subClassOf关系的三元组数量较少,根据表4 可知仅有29 181个,使得基于IC计算概念球体半径未能在该实验中表现出优势。更重要的是,subClassOf三元组的训练往往存在较高的出错率,也就是说,若该类三元组数量增多,其训练的出错率相应增高,TransIC模型测试效果会更加明显,三元组分类实验相应指标也会得到一定提升;二是本实验直接采用了链接预测的实验参数配置,该组参数并非三元组分类实验的最佳配置。(3)本实验中,TransIC在bern采样下的测试结果整体优于unif采样下的结果。
3.3 球体半径定性分析
经过统计,TransC与TransIC训练结束后均得到29 181个subClassOf三元组,即(子概念,概念)结构中子概念球体半径-概念球体半径为29 181对。然而,TransC中存在6 789对球体半径与其训练目标完全相反。TransIC弥补了其不足,训练得到的球体半径均满足其目标函数。图3对比了TransC及TransIC的subClassOf三元组训练出错率。
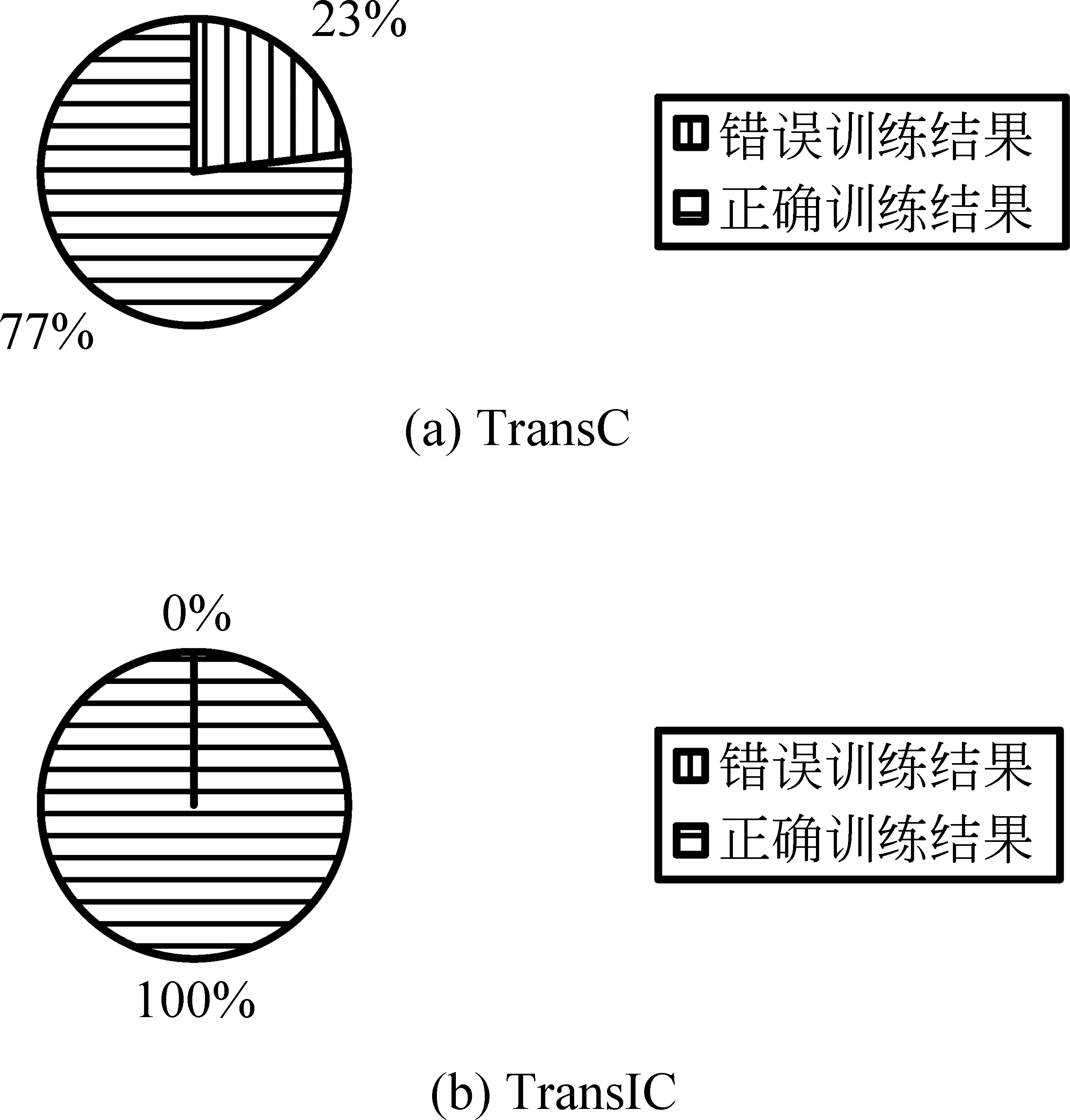
图3 TransC与TransIC的subClassOf三元组训练出错率对比
根据表4中YAGO39K数据集统计信息可知,具有subClassOf关系的三元组仅占总三元组的3.5%,又由图3得出,对于数量较少的此类三元组,TransC的训练出错率达到23%,而TransIC的训练出错率为0%,进一步说明TransIC中求解概念球体半径的方法是有效的。
4 结论
为了解决TransC中部分球体半径与优化目标相反以及概念语义信息表示不足这两个问题,本文提出了TransIC知识图谱嵌入模型。TransIC利用IC参数计算出每个概念的IC值,再通过概念IC值计算出对应概念球体的半径,以保证子概念与概念之间的半径关系满足模型目标。其中,IC参数提供了概念本身的语义信息内容,使其在嵌入学习中获取更丰富的语义信息。
在下一步工作中,计划扩充数据集,从YAGO中提取更多的subClassOf关系三元组加入到训练数据集中,使模型得到更充分地训练;同时继续优化TransIC,寻找更准确的IC计算方法以得到更精确的概念IC值,从而进一步提升模型性能。此外,尝试将IC参数用于其他知识图谱嵌入模型中。
猜你喜欢
数学大王·低年级(2021年4期)2021-04-27
山西大学学报(自然科学版)(2021年1期)2021-04-21
消费电子(2020年5期)2020-12-28
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
池州学院学报(2017年5期)2018-01-23
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
现代防御技术(2014年6期)2014-02-28
