
基于卷积神经网络的汉字结构多分类任务研究
2021-11-15 01:55:50李镇宇战国栋
大连民族大学学报 2021年5期
李镇宇,战国栋
(1.大连民族大学 计算机科学与工程学院,辽宁 大连 116650;2.大连市计算机字库设计技术创新中心,辽宁 大连 116605)
汉字是中华民族的重要文化特征,也是文化传播和交流的重要载体,将汉字以图片的形式保存后,在面对成千上万的汉字图片想要对其按照结构分类时,很多问题就出现了。如果使用人工对汉字图片分类,首先要识别几万汉字,然后按照结构对其分类,即分类的结构分别是半包围结构、单一结构、品字结构、嵌套结构、全包围结构、上下结构、上中下结构、左右结构、左中右结构9种结构[1],人工分类必然存在主观分类误差.有很多汉字看似是上下结构,当使用字典查询时实则是嵌套结构、还可能存在的问题是分类效率低和分类时间长等问题。而传统的数字图形图像学知识处理面对汉字复杂的结构,很难处理此类问题。近几年随着生产力的发展,计算机性能也在不断提升,人工神经网络[2]在很多已经领域得到了广泛的应用。目前处理图像分类主要采用深度学习的方法,人工智能技术在图像分类方面具有无法超越的效率和准确率的优势。深度学习主要通过卷积神经网络利用滤波器矩阵对图像进行特征提取,需要大量已标注数据集来理解数据中的潜在联系。但是汉字的数量是有限的,常用的3 000个汉字[3]则已经可以覆盖99%的书面资料。因此面对数据量少的这个问题,迁移学习是图片汉字结构分类的一个重要的分类方法,同时本文也搭建了两层卷积层的卷积神经网络卷积神经网络模型,与迁移学习的模型进行对比。
1 实验方法
1.1 数据来源及分析
本研究的数据集是font forge提取瑞意宋字库图片,共计19 798张汉字图片作为训练集,见表1。汉字结构和各个的汉字结构的数量,包含9种汉字结构(半包围结构、单一结构、品字结构、嵌套结构、全包围结构、上下结构、上中下结构、左右结构、左中右结构)。由表1可知,左右结构和上下结构的汉字占了绝大多数,而其他结构的汉字却十分稀少,最少的品字结构的汉字只有15个,数据量的缺少是本研究的一个难点。
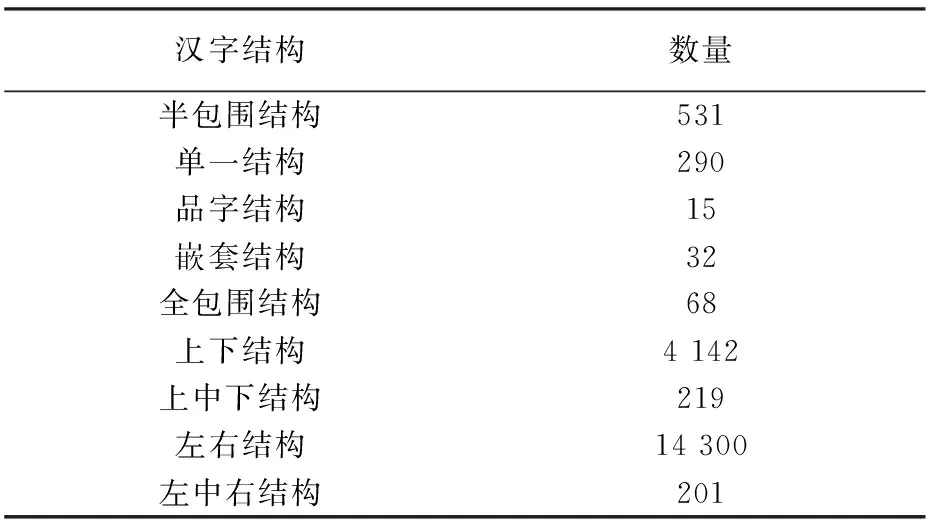
表1 汉字结构和数量
1.2 数据增强
数据增强是指对已有训练数据一定变换以增强增加训练样本数量,从而提高模型性能的方法。对于图像数据,常用的数据增强方法有翻转、旋转、缩放、裁剪、移位、高斯噪声等[4]。图像的翻转不会产生信息的损失,而旋转、缩放、裁剪、移位等变换都有可能造成原始图像信息丢失,对于这个数据集的图像小角度旋转也是不会造成图像边缘信息的丢失 。但是,非常遗憾的是数据增强的方法并没有在发挥出它的优势,相反数据增强反而让测试集的准确率低的离谱,这就说明数据增强在本次图像分类的研究中是不可行的。
1.3 迁移学习
深度学习中的迁移学习[5]是为解决训练数据集中训练数量不足这个基本问题,通过利用公开数据集训练网络模型,然后将参数和模型迁移到新的领域,完成新任务的机器学习方法[6]。根据域(domain)和任务(task)的不同,迁移学习划分为特征迁移、样本迁移和参数迁移等。本文处理目标与原本的模型架构都是图像,任务都是对图像进行训练提取特征,实现对不同属性图片的分类,所以采用参数迁移方式[6]。
1.4 模型搭建
1.4.1 迁移学习模型搭建
迁移学习模型搭建主要使用的是python3.7库和版本,分别是pytorch1.4和torchvision0.5作为本次学习基本框架,在框架中可直接加载ResNet18、ResNet50、ResNet152网络模型[7]。然后更改全连接层, 最后一层使用到了LogSoftmax[8]。
(1)
式中,x表示输入数据。全连接层损失函数只使用到了NLLLoss。
f(x,class)=-x[class]。
(2)
式中:x表示输入数据;class表示类别,优化器为Adam[9]。
mt=β1mt-1+(1-β1),
(3)

(4)
(5)
式中:m是梯度的一阶动量 ;β1和β2是两个超参数,一般默认 0.9 和 0.999;g是梯度;θ是参数;α是学习率;是个很小的数,作用是为了防止分母为零的情况出现;v是梯度的二阶动量。
最后的参数微调可解决预训练神经网络模型在目标域中特征参数与任务的不匹配问题,参数微调是迁移学习的最重要步骤。迁移学习主要分为3个步骤[6]:(1)利用大量有标识的数据集(源域)对神经网络进行训练,通过模型前端的卷积层和池化层,对源域的图像特征、参数,进行提取;(2)预训练模型,将训练好的模型导入到目标任务中,通过对全连接层自定义,重构分类层;(3)微调,冻结前面多层的网络参数,用目标域图像进行训练,通过前向传播,记录前向传播各参数,将训练好的模型应用到目标任务中,完成迁移学习。因为实验数据集较小,且汉字图像与源域的自然图像差异性较大,所以本文主要采用冻结方式对模型进行微调。迁移学习模型搭建过程如图1。
1.4.2 卷积神经网络模型CNN_2的搭建
卷积神经网络模型CNN_2搭建使用的是python3.7版本和库,框架使用的分别是pytorch1.4作为本次学习基本框架,在模型中构建了两个卷积层、两个激活层,两个池化层,最后使用一个全连接层输出分类结果,激活函数为ReLU[10],
ReLU(x)=max{0,x},
(6)
式中,x表示输入数据。ReLU激活函数可以快速的收敛,去除特征图中不太重要的样本,减少参数数量,实现数据的压缩,防止过拟合。这里采用最大池化,就是取出卷积层中元素的最大值。损失函数为CrossEntropyLoss[11]。
(7)
其实loss(x,class)就是(1)式与(2)式的结合,优化器为Adam,卷积神经网络模型如图2。

图1 汉字图像迁移学习流程

图2 CNN_2模型
2 实验结果与分析
2.1 迁移学习实验结果
使用ResNet18、ResNet50、ResNet152这三种模型进行迁移学习的方法分别训练,评价方法为测试集准确率,前20次直接使用迁移过来的网络模型,后30次是微调模型的结果。三个模型的训练结果如图3。观察这三种卷积神经网络模型发现虽然这三种模型的准确率都不高,但是可以发现,随着卷积神经网络层数的增加,效果反而不好,如图3所示,ResNet18的最高准确率为72.03% ,ResNet50的最高准确率为68.53%而ResNet152的最高准确率为64.34%。这里大胆的猜测一下,可能是随着卷积神经网络层数的增加,汉字的特征没有很好的保留,所以下一步搭建了一个类似于LeNet-5[10]一样简单的网络,观察准确率的情况。
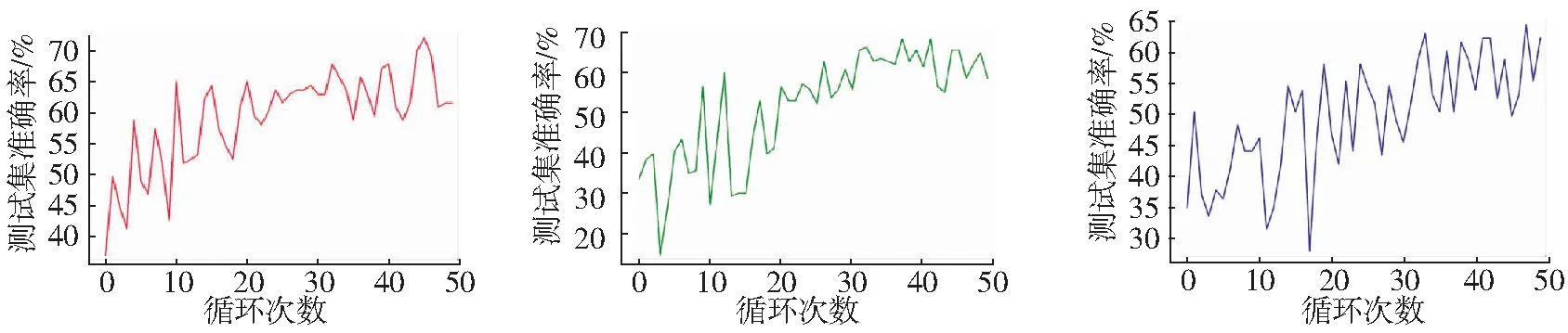
a)ResNet18测试集准确率 b)ResNet50测试集准确率 c)ResNet152测试集准确率图3 三种网络实验结果
2.2 卷积神经网络CNN_2实验结果
针对上边迁移学习准确率比较低,和随着网络层数的减少准确率却在上升的原因,就有了本文构建的更加简单的网络模型CNN_2,如图4。可以看到随着迭代次数的增加,CNN_2的准确率远远的超过了ResNet18的准确率。
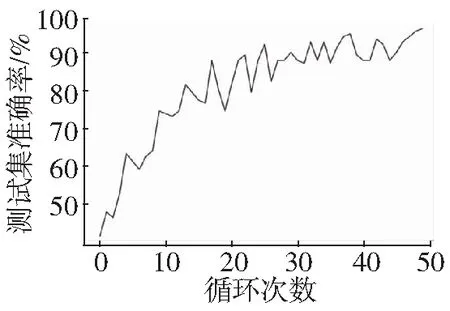
a) CNN_2测试集准确率

b) CNN_2和ResNet18的测试集准确率图4 CNN_2和ResNet18比较
3 结 语
针对汉字的结构进行分类的问题,提出了用基于迁移学习的分类方法和CNN_2分类的方法,经过对比发现随着卷积神经网络层数的减少准确率却在上升。这里猜测可能是卷积神经网络层数会影响提取的汉字图片特征。实验结果证明了卷积神经网络对于汉字图片结构的分类的准确率较另外三种网络模型更高,见表2。

表2 汉字结构和数量
准确率可以达到96.50%。使用CNN_2的方法成功解决了减少人工分类耗时耗力的问题。但是不清楚使用在与本文字体有很大差距时,会不会依然有相同高的分类准确率。然而这是一个很有潜力的模型,在今后的学习中将会对于汉字结构分类问题研究的更加透彻。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
七彩语文·写字与书法(2019年10期)2019-11-11 08:50:04
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
学周刊(2017年8期)2017-03-29 18:25:58
学周刊·中旬刊(2017年3期)2017-03-18 18:33:09
