
基于BERT的中文多关系抽取方法研究
2021-11-12 15:17黄梅根刘佳乐
计算机工程与应用 2021年21期
黄梅根,刘佳乐,刘 川
重庆邮电大学 计算机科学与技术学院,重庆400065
知识图谱[1]是近些年非常热门的一个研究方向,它在很多方面都取得了非常不错的应用效果,例如问答系统[2]、推荐系统[3]、Google的搜索等。随着近几年计算机网络的飞速发展,产生了海量的数据,知识图谱可以结构化地存储这些数据,查询的时候也可以更全面地了解相关知识,提升搜索的深度与广度。知识图谱通常是由许多相关知识、类似结构的三元组构成的关系图,三元组一般是由<实体-关系-实体>这种两个节点包含一个关系的结构。现在关于知识图谱构建较为普遍的方法是通过机器学习或深度学习的方法对文本进行处理,通过处理后得到实体与关系的三元组,在这个过程中会有许多问题,本文主要解决如下两个问题:
一是三元组抽取的多关系问题,且句子关系较多时往往会有其他抽取难题。如:“台湾省,是中华人民共和国省级行政区,省会台北,地处中国大陆东南海域,由中国第一大岛台湾岛和周围属岛以及澎湖列岛等岛屿组成,总面积约3.6万平方公里。”其中可以抽取出<中华人民共和国-省级行政区-台湾>,<台湾-省会-台北>,<台湾-位于-大陆东南海域>,<台湾-面积-3.6万平方公里>等多个三元组。这些三元组中都含有“台湾”的实体,会有实体重叠问题;<台湾-面积-3.6万平方公里>中两个实体相距较远,不易抽取;<中华人民共和国-省级行政区-台湾>实体间含有从属关系,不能抽取为<台湾-省级行政区-中华人民共和国>;若关系词集合中含有“位于”却没有“地处”那么可能不能抽取出<台湾-位于-大陆东南海域>,或者抽取为<台湾-地处-大陆东南海域>从而增加三元组的繁杂。面对这些问题使用传统方法抽取比较复杂,而使用BCMRE可以根据多标签分类快速找到句子中所有的关系这就解决了多关系问题;分类同时解决了未标注关系词或者同义关系词的问题,如上文的“位于”“地处”都会被归于一类;根据关系找出对应实体这就解决了实体重叠、实体相距较远问题;训练数据中的三元组含有从属关系,通过模型训练就能在实体选取中完成从属的识别。
二是知识图谱的研究是在国外兴起的,所以针对知识图谱问题大多使用英文数据源进行研究,但中文有不同于英文的特点,以中文构建知识图谱的过程中在进行关系抽取时中会遇到不同于英文的问题,模型可能需要针对中文环境进行优化适配。
基于以上阐述,模型使用中文数据源,对构建知识图谱中的多关系抽取进行研究,并且通过模型解决多关系抽取中遇到的其他问题。
1 相关研究
构建知识图谱通常采用自然语言处理的方法提取三元组,这个过程的关键是对句子进行命名实体识别(Named Entity Recognition,NER)[4]与关系抽取(Relation Extraction)[5-6]。实体关系抽取是构建三元组的重要步骤,主要分为有监督学习方法、半监督学习方法和无监督学习方法,近年来也将深度学习运用到关系抽取任务上取得了不错的成果[6]。有监督学习方法早期通过基于规则的方法与基于特征的向量等方法进行抽取[6]。Kambhatla等[7]就使用这种方法构造向量作为输入,建设模型。Oudah等[8]通过一定规则处理抽取任务。半监督实体关系抽取只需要少量的标注就可以对大量无标注样本进行迭代训练建立模型[6]。半监督方法在抽取任务中应用最广泛的就是Bootstrapping算法[9]。Glass等[10]使用这种方法进行实体关系抽取。无监督的学习方法不依赖标注数据,基于聚类的思想进行抽取[6]。Hasegawa等[11]首先提出了这种思想,其他人又有一些不同程度的优化提高。随着深度学习在许多NLP领域的成功,文本的信息提取也开始使用深度学习,主要分为流水线方法和联合抽取方法。Attardi[12]使用流水线方法,这种模型通常用词嵌入表示句子,然后标记出的实体,再进行关系分类,实现了任务流程封装。Wang等[13]使用联合抽取实体与关系思想,这种方法直接从句子中抽取实体与关系,联合抽取模型虽然将抽取实体与关系作为一个任务具有不错的效果,但是建模较为复杂,没有流水线方法灵活。深度学习框架模型主要是基于卷积神经网络(CNN)、递归神经网络(RNN)、长短时记忆网络(LSTM)等。Zeng等[14]基于CNN提出了一种分段卷积神经网络(Piecewise Convolutional Neural Network,PCNN)。为了更好地处理上下文问题,提出了双向RNN考虑当前状态与之前与之后状态的关系,RNN虽然能够处理文本之间的依赖,但当句子很长时或者两个实体之间相隔比较远,RNN会产生梯度消失或者爆炸的问题。Hochreiter等[15]使用LSTM解决这个问题,以及衍生的双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)都是根据门的概念去解决这个问题。Vaswani等[16]使用注意力机制attention能更好地捕捉上下文关系。Johnson等[17]将字符嵌入、词语嵌入、词性嵌入以充分获取句子的信息并采用注意力机制捕获当前位置与任意位置之间的内在关系。Devlin等[18]结合之前的算法经验提出了BERT(Bidirectional Encoder Representations from Transformers)预训练模型,得益于BERT较高的灵活性,使其在以中文为数据源的场景以及多个NLP领域取得了较好的效果。Jiang等[19]将BERT与LSTM-CRF结合取得了优于其他模型的效果。Lan等[20]通过优化BERT提出了ALBERT,证明BERT具有较好的拓展性。传统的方法大多是在一条语句中抽取一个三元组普通类型,提取多个三元组时效果较差,因为研究对象是多关系抽取,本文利用BERT模型的灵活性进行优化,使用流水线方法抽取三元组,提出一种基于BERT的多关系抽取模型BCMRE处理中文多关系抽取任务。
2 改进BERT多关系抽取模型BCMRE
本文提出了一种针对多关系抽取的模型BCMRE,它由两个任务模型串联构成:关系分类任务与元素抽取任务。针对不同任务两个任务模型设计加入不同的前置模型优化BERT模型处理任务,关系分类任务负责计算可能包含的关系,对每一种关系进行标记并复制出一个实例,元素抽取任务再针对每一个实例生成三元组,最后组合得到所有的三元组。BCMRE模型的构成如图1。

图1 BCMRE模型Fig.1 BCMRE model
BCMRE模型首先将数据源中的json数据通过代码抽取出文本text、关系组合relation和用BIO编码的分词标注序列labels,其中relation与labels如果用于训练就从数据源读入,如果用于测试和验证就使用默认字符初始化;然后这些关系序列经过词向量处理模型生成各种向量,同时在这一步把训练数据中的分词标注序列labels输入模型,可以更充分获取句子信息,有利于元素抽取任务的分词训练;向量生成以后为了针对不同任务进行优化、提取出更多特征,在BERT计算之前加入前置模型,并针对关系分类任务与元素抽取任务的区别设计了不同的前置模型;如图2、图3前置模型处理生成可以由BERT计算的token,再由BERT进行编码解码计算,BERT计算中针对两个任务设计有不同的词向量输入、不同的损失函数进行优化;最后通过BERT计算之后分别得到分类集合k与三元组集合Q。
关系分类任务如图2,元素抽取任务如图3。

图2 关系分类任务Fig.2 Relationship classification task

图3 元素抽取任务Fig.3 Element extraction task
2.1 词向量构建
BCMRE模型首先要将数据源抽象为各种向量,然后才能交给后面的模块处理。在BERT模型中对于中文文本是按字进行分割的,而原数据集中文本已经进行了分词,BERT的分词方式会浪费掉原有的分词信息,不利于提取实体关系,所以BCMRE模型将数据集中的分词及词性信息以BIO编码的方式输入到embedding生成labels向量。labels在元素抽取任务用于分词及分词标注序列的训练,而关系分类过程中不需要此向量,如图2,图3。因为关系分类任务与元素抽取任务是串联起来的任务,所以当关系分类任务得到分类结果后需要更新词向量,如图3中融合词向量。
2.1.1 词向量生成
因为数据集中句子长度等问题,在词向量中生成向量长度不一致,不利于后续算法计算,模型规定了标准长度128位。如图2通过词向量模型形成句子向量input(I)、填充标识向量mask(M)、句子标识向量segment(S)、标签向量relation(R)、分词标注序列向量labels(L);然后将I、S、M、R输入到关系分类任务对四个向量进行计算,得出句子可能包含的关系分类{k1,k2,…,km};如图3,将得到的分类加上偏置值得到分类编码{t1,t2,…,tm};词向量处理模型通过复制并针对每个分类编码进行融入构成一个新向量组I′、S′、
模型中的四个主要向量:I′、S′、M′、L′生成的伪代码如下:
input:最大长度max,句子text,句子标签F,关系初始化r,字典vocab,偏置b
output:句子向量I,句子标识向量S,填充标识向量M,分词标注序列向量L

经过上面的算法后得到句子向量I=(cls,w1,w2,…,wn,sep,t1,t2,…,tn,sep,0,0,…,0)128,从cls到sep是通过vocab字典形成的汉字编码,接下来的ti是分类ki加偏置值b,这样使每一个句子的每一种分类都能产生不同的向量,为了加强关系的权重会复制n个ti,后面0是填充位;M=(1,1,…,1,0,0,…,0 )128前面2⋅n个1代表原句子加n个ti,表示整合后的有效句子长度,最后填充0;S=( 0,0,…,0,1,1,…,1,0,0,…,0 )128前面n个0表示第一个句子后面n个1表示n个ti,最后填充0;L=(c,l1,l2,…,ln,s,r,r,…,r,0,0,…,0 )128其中的c与s是cls与sep的编码,li是词性信息,r是关系初始化占位,最后填充0。
2.1.2 词向量嵌入层
词向量生成之后算法再经过嵌入层把几个向量融合到一起进行降维操作加快后面的计算。因为实体关系三元组抽取的过程需要考虑前后关系,如王华是李红的丈夫,<王华-丈夫-李红>,BERT模型中的自注意力机制(self-attention)也需要考虑整个序列的关系,所以需要位置向量。图4左侧因为句子标识向量segment只有0与1两种情况所以先进行onehot操作,然后再与词向量input统一成相同维度相加得到output,右侧通过随机初始化产生位置嵌入向量(position),通过将左侧output加上右侧position形成融合位置向量的词向量,最后将这个向量进行归一化处理与dropout操作防止过拟合。词向量经过嵌入层之后就生成完毕了,接下来交给BCMRE模型的下一个模块前置模型用于特征提取。
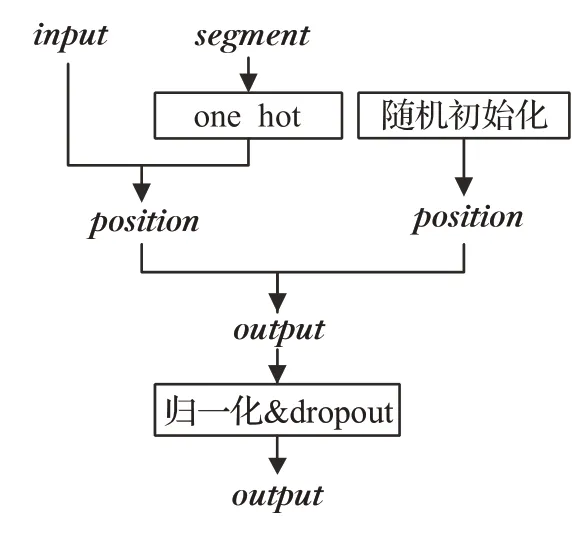
图4 嵌入层Fig.4 Embedded layer
2.2 前置模型
前置模型是在BERT计算之前,通过其他模型先对词向量处理,提取出一些针对任务的特征、BERT不易提取的特征,再交给BERT用于优化结果或者加快速度。BCMRE模型由关系分类任务与元素抽取任务串联而成,这两项任务都是基于BERT的分类任务,但关系分类任务的侧重点在于对于句子进行多种关系分类,属于一个多标签分类任务,更依赖模型的分类效果;元素抽取任务需要先对于句子分词及词性预测,然后根据每一种关系抽取实体词组合成一个完整的三元组,属于一个多类分类的单标签任务,会需要模型有优秀的分词效果。根据这两项任务的不同,模型中不仅设计了不同的损失函数,而且添加了不同的前置模型处理词向量,处理后再交给BERT处理计算,以优化模型的效果。模型中添加了两种前置模型:为了更好的分类,模型基于AGCNN[21]实现了句子分类器;为了分词标注序列预测,模型调用了BERT中的BiLSTM与CRF进行处理,前置模型具体处理方法如下。
2.2.1 前置模型AGCNN
为了更好的分类,BCMRE在关系分类任务生成词向量之后使用AGCNN进行前置处理后再使用BERT计算。AGCNN模型是基于CNN提出的,所以对网络位置信息不敏感,为了解决这个问题本层将词向量input与位置向量position通过embedding融合后的带位置向量的词向量输入网络进行处理。通过拼接融合位置向量AGCNN的处理之后能够将句子中的关系词相关特征、权重更好的表达出来。AGCNN的构成方式为Attention(注意力机制)、Gated Linear Units(门控线性单元)、Convolutional Neural Network(卷积神经网络)。模型中用的注意力机制与卷积神经网络使用的较多,而且在BCMRE中的BERT处理也用到了这些机制,所以接下来着重介绍门控线性单元,它具有控制词权重特征的作用。Gated Linear Units简称GLU,它可以调节上下文窗口,GLU通过控制目标词或句段特征的影响查找真正对结果重要的特征,计算公式如下:
Y=Conv1D1(X)⋅sigmoid(Conv1D2(X))
上述公式中Y表示对于每个元素进行两个权值不同的卷积,Conv1D1与Conv1D2是两个形式一样,但权值不同的卷积核。其中一个卷积结果通过sigmoid函数进行激活作为另一个卷积的gate,类似于LSTM的gata机制,用于控制哪些信息可以通过,哪些信息不可以通过,然后将这两个计算结果进行点乘运算后得到结果。
GLU在这一步加入残差网络用来保证信息的多通道传输,于是可将公式更新如下:
Y=X+Conv1D1(X)⋅sigmoid(Conv1D2(X))
经过如下进一步推导可以更清楚地看到信息传递过程:
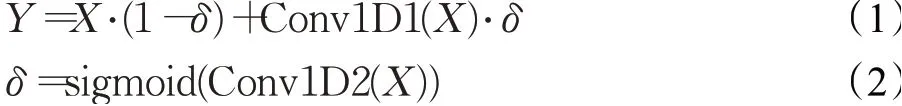
公式(2)通过sigmoid函数进行激活输出的值域为(0,1),δ即是该信息的通过的概率,通过公式(1)看出信息以1-δ的概率直接通过,以δ的概率经过变换后通过。通过这样的计算方式能更好地提取出文本中分类词汇与周围词的关系,从而更好地表述向量特征,然后再进入BERT计算实现更好的分类。
2.2.2前置模型BiLSTM与CRF
为了进行分词及对词性信息分类,BCMR在元素抽取任务中调用BERT的函数加入前置模型BiLSTM与CRF,在词向量生成之后通过BiLSTM与CRF基于神经网络与规则进行分词特征提取,然后再用BERT进行词性分类。这一步元素抽取任务通过输入的input向量与mask向量计算出实际长度,过滤掉填充位,再输入到BiLSTM与CRF层。其中BiLSTM是通过神经网络构建双向LSTM捕捉到较长句子中字或词的依赖关系,而CRF主要负责进行一定的规则上的处理,增加一些约束条件,过滤掉可能性小的分类。根据训练集中的词性类别,算法初始化生成对应的转移矩阵,然后使用似然函数得到最可能的分词标注序列。通过BiLSTM与CRF前置模型可以更好地提取分词特征,从而优化BERT的分词性能,实现更好的关系元素提取效果。
2.3 BERT计算与处理
2.3.1 编码解码层
BCMRE模型在前置模型处理词向量提取相应特征后就可以交由BERT计算处理。在BERT中利用多头(Multi-Head)与自注意力机制(self-attention)充分提取句子中得特征信息。多头与自注意力机制的运算时通过三个向量Query(Q)、Key(K)、Value(V),这三个向量通过随机初始化的矩阵W与嵌入层的向量进行矩阵相乘得到,然后随着训练过程的进行不断进行更新优化。在计算词向量的时候使用的Q、K、V三个向量与随机初始化的矩阵有关,而多头机制可以初始化产生h个WQ、WK、WV。初始化矩阵的不同可以让每个头的运算得到的特征向量的表达也不同,结果进行整合处理得到最终的特征向量Z,这样多次产生初始化矩阵W可以使模型更充分地学习到句子内部结构。
BCMRE模型通过多头与自注意力机制提取特征信息,然后由前馈神经网络(Feed-Forward Neural Networks)进行并行加速计算得到特征向量Z。由于在计算的过程中可能会导致某些特征丢失,所以模型在multi-head与self-attention计算完后会加一个残差连接并进行归一化(Layer normalization)操作,这样就形成了编码层(encoder),这个过程需要迭代N次优化效果,所以会有多个编码层。解码层(decoder)与编码层结构是基本一致的,并且也需要N层解码层对应。解码层在多头计算Q、K、V的时候解码层需要能过滤掉模型中向量的填充位,公式如下:
s=softmax((w-1)⋅inf) (3)
公式(3)用于过滤填充位,如果之前填充0,通过减一乘无穷得到负无穷,softmax负无穷的结果趋于0,就不会影响整体结果。
2.3.2 损失函数
BCMRE中关系分类任务与元素抽取任务目的不同,关系分类任务需要对一个句子预测出多种或一种关系类别,只需要一个损失函数针对关系类别进行预测优化;元素抽取任务针对每一种关系进行三元组抽取,既需要对整个句子进行分词及词性预测又需要针对当前关系预测对应实体,损失函数是同时对分词及词性预测与三元组预测两项任务控制,所以有损失函数包含两项。
关系分类任务中的关系预测是一个多标签分类的任务,模型使用sigmoid作为损失函数,损失函数L1的定义如下:
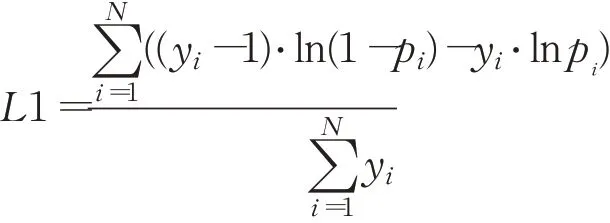
其中,y=inputs,pi=sigmoid(logitsi)=(1+exp(-logitsi))-1,是交叉熵。
元素抽取任务是多类分类的任务,模型使用softmax作为损失函数,元素抽取任务得到预测关系的损失函数L2与预测序列的损失函数L3相加后得到最终损失函数L4进行训练,损失函数L4定义如下:

其中,y=pre_labels,δ=0.5,pi=softmax(pre_logitsi),z=token_labels,qi=log(soft max(token_logitsi))。
3 实验与分析
3.1 数据集
数据集选自2019语言与智能技术竞赛,其中包含20万条来自百度百科的中文文本。数据集中一条数据包含自然语言句子,所有的三元组,分词标注序列。这些三元组包含有
3.2 实验环境及参数设置
算法的实验环境操作系统是Ubuntu20,使用的语言是Python3.7,BERT中文预训练语言模型使用chinese_L-12_H-768_A-12,深度学习框架tensorflow1.15。句子最大长度设定为128,训练时的batch_size为8,分类概率阈值为0.5,学习率(Learning rate)2E−5,多头注意力有12层,多头数量有12个,为了防止过拟合,算法中多处加入dropout,其中dropout rate为0.1,关系分类任务与元素抽取任务上面参数都相同,但是关系分类任务epochs设定是6,元素抽取任务因为更复杂需要训练更
久,所以epochs设定是9。
3.3 实验结果评估与分析
本文使用准确率(Precision),召回率(Recall)和F1值评估模型的效果,准确率等于正确预测的数量/预测为正确的数量,召回率等于正确预测的数量/原本正确的数量,F1是一种较为均衡的评估方法,计算方式是2×Recall×Precision/(Recall+Precision)。模型经过多次训练后F1值逐步提升,关系分类任务训练2万次后提升不明显,元素抽取任务训练3万次后提升不明显,训练次数对模型整体效果的影响实验结果如图5。

图5 训练次数对整体效果的影响Fig.5 Impact of training times on overall results
BCMRE是由关系分类与元素抽取两项任务串联组成,所以任何一个任务效果不好都会影响到最终结果。本文针对不同的任务进行分析加入了不同的前置模型,根据图5的结果,不同前置模型的训练次数也基本在2到3万次。通过实验对两项任务交叉添加前置模型,然后经过实验记录F1的值如表1。
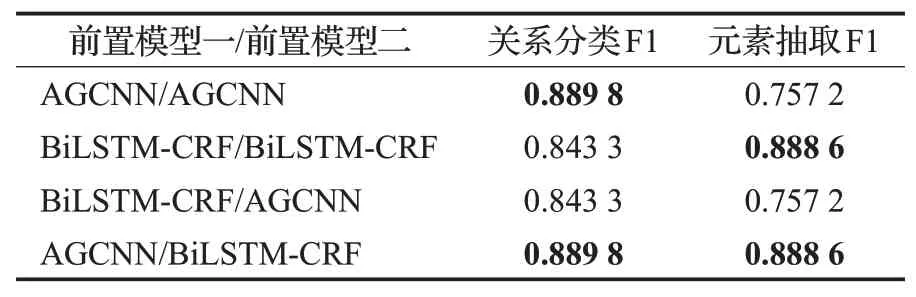
表1 不同任务不同前置模型效果Table 1 Different pre-model effects for different tasks
表1 的目的是为了针对任务选择合适的前置模型,不含有前置模型的BERT-base在表2的对比中有描述。这里是通过提取出实验的中间数据作为参数,然后对于两个任务添加不同的前置模型进行效果对比。从表1中可以看出最好的前置模型与任务的组合是AGCNN/BiLSTM-CRF即在分类任务中添加AGCNN前置模型,元素抽取任务添加BiLSTM-CRF前置模型。这与本文之前的分析是对应的,因为模型在开始的时候添加的前置模型都是BiLSTM-CRF,通过后来的研究,针对关系分类任务设计添加了单独的分类模型AGCNN。从表1中也能看出BiLSTM-CRF在关系分类中也有不错的表现,这可能是因为BiLSTM-CRF在分词与实体抽取这类任务做的比较好,能通过词之间的联系实现较好的分类,但仍没有分类模型AGCNN效果好,这也证明BCMRE添加的前置模型正确性。
BCMRE是针对中文文本的多关系抽取任务,比较难找到统一对比的数据集与经典的算法。为了进一步验证模型性能,在基于本文的数据集基础上,模型将两项任务分别与fine-tuning之后的BERT-base、神经网络模型Lattice-BiLSTM-CRF等进行对比,效果如表2。
从表2中可以看出Lattice-BiLSTM-CRF在两项任务中都没有取得较好的效果,说明单纯的神经网络模型即使加入了BiLSTM-CRF让模型学习语义结构仍不能胜任这种复杂的任务;BERT-base仅仅在做了fine-tuning的操作整体效果上不错,在准确率方面关系分类中比Lattice-BiLSTM-CRF有7%的提升,而元素抽取只比Lattice-BiLSTM-CRF提升3%,可能是因为没有BERT默认按字为单位处理,导致在语义表达上不能取得较好的效果,从而生成三元组的能力较差;基于BERT的模型中加入前置模型BiLSTM-CRF以处理语义表达关系,在元素抽取模型中有较为明显的提升,证明了BiLSTMCRF能提升分词效果,也证明了添加前置模型能解决BERT的不足;同时可以看到ALBERT相比传统BERT在F1上低2%左右,可能因为较为精简的ALBERT不适合处理这种复杂的情况;最后BCMRE关系分类任务中添加前置模型AGCNN使得关系分类的效果进一步提升,同时对应可以看到添加AGCNN后召回率提升4%~9%而准确率提升3%左右,说明了模型提取所有三元组的能力显著提高,这是因为在关系分类中前置模型AGCNN能做得更好,同时在元素抽取任务中使用BiLSTM-CRF用来分析语义词性,可以看到添加对应的前置模型后BCMRE在各方面性能都有了较大的提升。
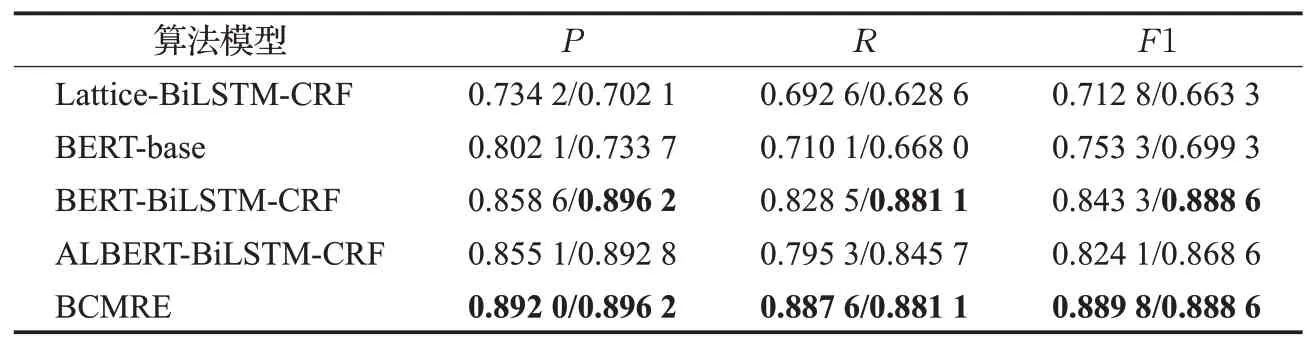
表2 不同模型关系分类/元素抽取的效果Table 2 Effect of different model relationship classification/element extraction
4 结束语
为了研究中文知识图谱的构建,本文提出了一种基于BERT的多关系抽取模型BCMRE,将多关系抽取分为关系分类与元素抽取两项任务串联处理。本文的创新点在于针对两项任务不同的特点分别加入前置模型ADGCNN与BiLSTM-CRF用于提取针对任务的特征、BERT不易提取的特征,加入labels向量,优化BERT处理过程,最后通过实验证明了前置模型的正确性与有效性。
BCMRE由两项任务模型串联构成,体量较大,训练起来比较耗时,将来会考虑优化模型复杂度,减少训练时间;而且本次的模型没有去考虑在某些领域的专用词语,关系类别较少,如果可以后面会考虑获取一些特定领域的数据进行处理,优化模型以产生实用价值。
猜你喜欢
山西大学学报(自然科学版)(2021年1期)2021-04-21
校园英语·月末(2021年13期)2021-03-15
中国生殖健康(2020年5期)2021-01-18
教书育人(2020年11期)2020-11-26
当代陕西(2020年13期)2020-08-24
五邑大学学报(自然科学版)(2019年3期)2019-09-06
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
计算机技术与发展(2018年12期)2018-12-20
中国生殖健康(2018年5期)2018-11-06
