
结合胶囊网络的领域适应意图识别
2021-11-12 15:11赵鹏飞李艳玲
计算机工程与应用 2021年21期
赵鹏飞,李艳玲,林 民
内蒙古师范大学 计算机科学技术学院,呼和浩特010022
口语理解在人机对话系统任务中具有十分重要的作用。为了让机器理解用户的需求并进行反馈,口语理解通常利用三个模块对用户输入内容进行分析,分别是领域识别、意图识别和语义槽填充,其中,意图识别的准确性能够直接影响口语理解的性能。随着智能人机对话系统应用的广泛发展,例如Siri、Cortana以及智能教育系统和预订票务系统,人们逐渐体会到了人机对话系统的便利性和实用性,对于其他新领域对话系统的需求也在增加。因此,开发新领域对话系统成为当前的研究热点。在新领域开发过程中,通常很难获得可直接用于模型训练的数据和标签,这导致了训练新模型需要昂贵的代价。为了解决新领域数据不足的问题,目前通常的做法是利用迁移学习。
迁移学习能够将源任务中的知识和信息最大化地迁移到目标任务中,解决目标任务的相关问题。近年来,迁移学习在图像识别、目标检测以及跨语言翻译方面应用广泛,并在实际领域发挥作用,比如医学领域、物理领域等[1]。Wu等人[2]针对低分辨率图像分类问题,提出利用源域高分辨率图像和低分辨率图像进行模型的预训练,并将其嵌入目标任务的分类模型中,提升目标任务的分类性能。Chen等人[3]利用迁移学习的预训练模型对神经网络进行模块微调,解决跨领域的医学图像分类问题。对抗网络是实现迁移学习中领域适应的一种有效方法,胶囊网络对于小样本特征提取具有一定优势。本文针对新领域人机对话系统中意图识别训练数据较少的问题,利用胶囊网络改进领域对抗神经网络解决训练数据稀缺的意图识别问题。
1 相关工作
意图识别问题其本质也属于一种文本分类问题。杨志明等人[4-5]针对意图文本较短以及卷积神经网络(Convolutional Neural Network,CNN)不能充分学习到意图特征表示和语义信息的问题,提出一种双通道CNN算法,利用字级别词向量辅助词级别词向量捕捉更深层次的语义信息,该方法对于解决意图识别中的短文本问题具有一定效果。侯丽仙等人[6]针对意图识别以及语义槽填充任务,采用一种增加门控机制、注意力机制以及条件随机场约束条件的双向长短时记忆网络(Bidirectional Long Short Term Memory,BiLSTM)方法,该方法在航空信息领域数据集上取得了不错的效果。刘娇等人[7]针对意图文本较短以及CNN中池化操作可能丢失特征信息的问题,采用一种改进胶囊网络的意图识别算法,该方法验证了胶囊网络在意图文本特征提取方面的优势。尹春勇等人[8]针对CNN丢失部分特征信息以及胶囊网络准确度较低的问题,提出一种增加两层CNN的胶囊网络方法,通过对文本进行两层卷积操作再利用胶囊网络捕捉更深层次的特征信息。
迁移学习有基于实例的方法、基于网络的方法以及基于领域适应的方法[1]。领域适应是迁移学习的重要实现方向,其目标是在源数据集上建立一个性能良好的神经网络,并确保该神经网络在目标数据集上也具有良好的性能。领域适应的实现方法中主要包括基于分布的领域适应和基于对抗的领域适应。Pan等人[9]提出一种基于迁移成分分析(Transfer Component Analysis,TCP)的边缘分布领域适应方法,该方法利用最大平均差异(Maximum Mean Discrepancy,MMD)学习源域和目标域的数据映射。在此数据映射空间中,源域和目标域尽可能接近且相似,利用该特征空间完成源域到目标域的迁移。Zellinger等人[10]针对最大平均差异的高阶特性,提出一种基于最大平均差异的中心矩阵差异算法,该方法通过高阶矩阵差异进行匹配概率分布的中心矩阵,解决了最大平均差异存在的计算量大的问题,在迁移学习数据集上取得了一定的效果。Goodfellow等人[11]首次提出生成对抗网络(Generative Adversarial Networks,GAN),首先利用生成器生成样本,将生成样本输入到判别器与真实数据进行对抗训练,目标是使生成器数据尽可能接近真实数据,判别器尽可能无法区别数据的真伪。Ajakan等人[12]针对目标域数据稀缺的问题,提出一种领域对抗神经网络(Domain-Adversarial Neural Network,DANN)方法,该方法首次将对抗训练引入迁移学习,通过对抗训练,特征提取器能够学习到源域和目标域的公共特征,即域不变特征,利用域不变特征对目标域进行分类。Ganin等人[13]利用领域对抗神经网络解决了目标域数据稀缺的问题,领域对抗神经网络在MNIST-M数据集上获得了76.6%的准确率,验证了对抗网络的有效性。Daniel等人[14]针对目标语言数据稀缺的问题,利用领域对抗神经网络完成了在文本方面的研究,在亚马逊情感分类的跨领域适应任务中,该方法获得了88.8%的准确率,在低资源语言无标记数据领域获得了78.8%的准确率,上述实验验证了领域对抗网络在文本方面的可行性。赵鹏飞等人[1]针对对话系统中新领域对话语料相对稀缺的相关问题,综述了意图识别的相关方法模型,提出未来对于解决新领域对话数据稀缺的意图识别研究方向。
本文受文献[7-8,11-12,14]的启发,传统领域判别器无法深层次提取不同领域的独有意图特征,导致领域判别器对源域和目标域的判别能力弱以及特征提取器的混淆能力差。为了提升领域的判别能力,利用胶囊网络对领域判别器进行改进。使用胶囊网络对输入至领域判别器的源域和目标特征进行多次提取,深层次捕捉意图文本特征,提取足够多的领域特征信息,提升领域判别能力,保障领域适应的可靠性。通过该方法解决新领域人机对话系统中数据稀缺的意图识别问题。
2 方法
本方法的主要框架如图1所示,主要包含五个部分:输入层、特征提取器、意图识别器、梯度反转层和领域判别器。

图1 模型框架图Fig.1 Model structure diagram
本文针对新领域对话系统中意图识别数据稀缺的问题,采用领域对抗神经网络将源域特征迁移到目标域,解决目标域数据稀缺的问题。模型优化过程中,领域判别器需要尽可能正确区分特征的来源,而特征提取器则要尽可能让领域判别器无法区分特征来源,因此两个部分形成对抗训练。通过这种方式使得特征提取器能够学习到一个公共特征空间,即域不变特征。该特征具有两个特点:(1)特征提取器利用该特征无法区分其来自源域或目标域;(2)目标域使用该特征可以进行意图识别。由此可知,本文的主要思想是利用对抗网络学习域不变特征。
另外,本文针对传统对抗网络中领域判别模块无法更好地提取领域特征信息,降低了领域判别能力,从而限制了特征提取器领域混淆能力的问题,提出一种结合胶囊网络的领域适应方法。通过对源域和目标域特征进行二次提取,充分提取意图文本的深层次特征信息,捕捉不同领域的独有特征,提高领域的判别能力,提升领域适应的可靠性,并且提升意图识别器对目标域的意图识别能力。
模型的训练过程分为两个阶段:第一阶段,由源域和目标域中少量已标注数据共同训练意图识别器,使意图识别器具有良好的分类性能且对目标域有效;第二阶段,由源域和目标域共同训练领域判别器,使特征提取器能够更好地学习域不变特征,领域判别器能够很好地区分领域来源。通过两个阶段的共同训练,目标域意图文本利用特征提取器捕捉到具有域不变特征的信息表示,完成意图识别任务。
2.1 输入层
输入层的主要目的是对意图文本进行向量化表示。中文数据集的数据预处理包括分词以及去停用词等,英文数据集的数据预处理包括大小写转换等。模型的输入是长度为x的意图文本,在此模块中使用预训练Word2Vec词向量获得每个词的词嵌入,并将其映射到高维向量空间得到K维词向量表示,即(e1,e2,…,ex)。
2.2 特征提取器
特征提取器的主要作用是提取用户的意图文本特征,并且最大程度地将来自源域和目标域的特征信息进行混淆,使其所学习到的特征信息无法区分领域来源,即完成域不变特征的学习。特征提取器包括两个阶段的训练,第一阶段仅使用源域数据进行训练,并将训练后的特征表示输入意图识别器;第二阶段数据由源域和目标域组成,并将训练后的特征表示反馈给领域判别器。特征提取器利用卷积神经网络对文本的句子进行特征提取,每个句子经过预处理构建成一个标准化的表示:s=ℝx×K,这里x代表标准化后句子的长度,K代表预训练词向量的维度。通过不同维度(i=[3,4,5])的滤波器对原始句子进行特征提取,如式(1)所示:

其中,f代表非线性激活函数,W代表滤波器,b代表偏置项,i代表滤波器的窗口大小。
2.3 意图识别器
模型的第一阶段为意图识别器的训练,整个阶段由输入层、特征提取器和意图识别器构成。通过将源域意图文本所获取到的特征表示输入到意图识别器中进行模型训练。在训练过程中,将目标域中少量已标注数据加入源域中共同训练,提升模型对目标域的有效性和对意图的识别能力。模型训练结构如图2所示。

图2 意图识别器训练网络Fig.2 Intent detection training network
通过全连接层将特征提取器中所获取的特征表示进行展开,将特征表示转换成一个长度为||C||的向量,其中C表示意图类别的个数。通过softmax激活函数计算每个意图类别的概率,如式(2):

其中,h表示特征提取器所捕捉到的特征信息,y表示源域意图中每个意图类别的概率。意图识别器的损失函数为交叉熵损失函数,如式(3)所示:

其中,xi表示源域和少量目标域的输入;Gf表示特征提取器;Gy表示意图识别器;yi表示源域的意图标签,其中包含了少量目标域的意图类别。
2.4 梯度反转层
传统的反向传播过程会同时优化两个部分,无法实现特征提取器和领域判别器的对抗训练过程。因此,将梯度反转层引入特征提取器和领域判别器之间,目的是将判别器传入提取器的梯度进行反向,从而实现两个部分对抗训练的效果。
2014年,Ganin等人[13]首次将梯度反转层引入到神经网络中,利用梯度反转层实现对抗训练,解决领域适应问题。梯度反转层主要包括两部分内容:前向传播和反向传播。前向传播时,只对特征表示做线性转换而不改变特征表示的内容,如式(4)所示;反向传播是将传入本层的误差乘以一个负值,使得特征提取器和领域判别器的训练效果相反,实现对抗训练,如式(5)所示:

2.5 领域判别器
领域判别器的作用是尽可能正确区分特征来自于源域或者目标域。普通卷积神经网络无法深层次提取特定领域的意图特征且容易造成特征丢失问题,导致其对源域和目标域的判别能力下降。为了提升领域判别器的判别能力,本文利用胶囊网络对其进行改进,通过对源域和目标域的特征信息进行多次学习,深层次捕获源域和目标域的特征信息,学习更加丰富的特征表达。而且,利用胶囊网络能够提取用来区分源域和目标域的独有特征,提升模型的判别能力,为实现领域适应提供保障。模型的第二阶段为领域判别器的训练,整个阶段由输入层、特征提取器、梯度反转层和领域判别器构成。领域判别器的结构为胶囊网络,如图3所示。

图3 基于胶囊网络的领域判别器Fig.3 Domain discriminator based on capsule network
胶囊网络分为三层:卷积层、胶囊层以及领域胶囊层。卷积层对源域和目标域的特征表示进行特征提取,充分捕捉意图文本中的特征信息。胶囊层主要将卷积层的输出作为输入并生成一组胶囊单元,即将卷积层所获得的特征表示用胶囊单元进行封装。本质上,每个胶囊单元来自于卷积层的特征加权和。为了获得胶囊单元,采用d种W=ℝ1×m滤波器对卷积层的输出进行加权和,通过胶囊层获得(x-n+1)×d的胶囊单元,如式(6)所示:

其中,Ac:c+1表示卷积层的输出,W表示滤波器,b表示偏置项,f表示激活函数。
同时,采用z个滤波器进行特征提取,获得句子的特征图表示,Z=ℝ(x-n+1)×z×d。
领域胶囊层主要由领域胶囊组成。源域和目标域均由上层d个主要胶囊产生的矢量作为此层输入,输出源域和目标域的胶囊类别,其主要的胶囊变换由动态路由算法进行操作。
动态路由算法完成上层胶囊到下层胶囊的转换,其输入由胶囊层的输出提供,其输出为领域胶囊单元,图4表示动态路由算法的转换过程。

图4 基于动态路由的胶囊转换Fig.4 Capsule conversion based on dynamic routing
在动态路由算法中,对bij进行初始化并获得初始化的耦合系数cij,即胶囊间转换权重,如式(7)、(8)所示:

其中,i表示当前层胶囊单元,j表示下层胶囊单元。
上层胶囊ui通过权重Wi获得预测向量uj|i,如式(9);利用初始化的胶囊权重以获得胶囊输出sj,如式(10);通过激活函数Squashing对sj进行处理获得下层的胶囊输出vj,如式(11);通过预测向量uj|i和胶囊输出vj进一步更新胶囊权重cij。已有实验表明[7],迭代次数为3时,可以获得最好的权重值表示。

领域判别器损失函数为Margin损失函数,如式(12)所示,该损失函数类似于交叉熵损失函数,其对每个表示领域类别的胶囊分别给出单独边缘损失函数。

其中,xi表示源域和目标域的输入,Gf表示特征提取器,Gd表示领域判别器,di表示领域标签,c表示领域类别,Tc表示领域类别的指示函数,||vj||表示领域类别胶囊的输出概率,m+为上界,通常设置为0.9,m-为下界,通常设置为0.1。模型的总体优化损失由意图识别器分类损失以及领域判别器胶囊损失构成,如公式(13)所示:

其中,yi表示源域和少量目标域的意图标签,di表示领域标签。
3 实验
3.1 实验语料
本次实验采用的数据集包括:SNIP-NLU[15](英文)、ATIS航空领域人机对话系统语料[16](中文)、SMP中文人机对话评测语料以及团队扩充语料[17](中文)。数据集示例及介绍如表1所示。

表1 数据集示例及介绍Table 1 Dataset example and introduction
3.2 实验设置
本次实验中文数据集利用维基百科的预训练word2vec词向量,其中,中文词向量28维,英文词向量300维,利用word2vec词向量对用户的输入文本进行向量化表示。
3.3 评价标准
意图识别任务本质上属于文本分类任务。通常使用准确率、精确率以及F1值对模型的性能进行评价[1]。在本实验中也使用上述评价标准。
3.4 对比实验
从相关的领域适应文献中选取具有代表性的相关方法与本实验方法进行对比实验。对比方法如下:其一,Tzeng等人[18]提出一种深度领域混淆方法(DDC);其二,利用胶囊网络改进深度混淆方法中的强分类机制模型方法(DDC+Capsule);其三,Ganin等人[13]提出的一种领域对抗神经网络方法(DANN)。对比实验中所有的源域数据数量以及目标域已标注数据数量均一致,实验设置和词向量维度均一致。
对比实验在源域选择英文数据集B、R、W、M,目标域选择P,并将目标域中500个已标注样本加入源域中共同训练意图识别器。实验结果如表2所示。

表2 在不同领域判别器下模型的准确率Table 2 Accuracy of model on different discriminator
结果表明,利用胶囊网络改进领域对抗神经网络中的领域判别器的实验方法,在同样的测试样本取得了88.3%的准确率,改进后的模型相比于原始模型分别提升了0.072、0.054、0.031。实验表明,通过胶囊网络对源域和目标域的意图特征进行再次提取,保存了句子中的多种特征。通过胶囊间的动态路由转换,对句子中所包含特征进行进一步的聚类表示,充分学习了源域和目标域的意图文本的大多数信息,包括语义、语序以及方向等,更深层次的捕捉领域间的独有特征表示,进一步提升了领域判别器对源域和目标域的判别能力,提高了模型的领域适应能力,对目标域的意图识别准确率具有一定效果。
3.5 实验分析
为了尽可能模拟目标域包含不同数量已标注样本对意图识别准确率的影响,将目标域中不同数量的已标注样本加入源域共同训练意图识别器进行实验分析。实际应用中标注大量数据的代价是十分昂贵的,因此,本实验仅使用少量已标注数据,在实际应用过程中,标记少量数据相对容易。在SNIP-NLU英文数据集中选取上述四个领域作为源域,目标域选择另外一个领域。从目标域中选取M={100,200,300,400,500}作为目标域的已标注数据量,目标域测试数据选取1 000个数据样本进行评测,在此模型上做了5个任务。实验结果如表3所示。
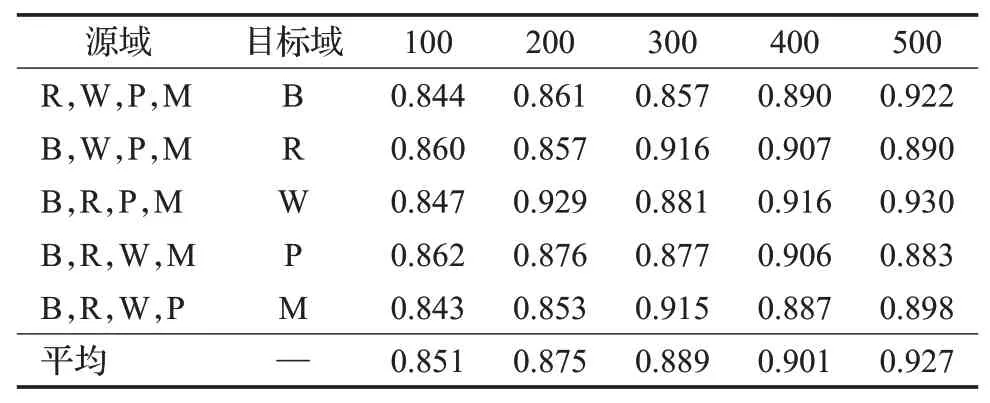
表3 不同已标注目标域下模型在1 000个样本的准确率Table 3 Accuracy of model in 1 000 samples under different target domains and labeled data
实验表明,排除部分噪声数据外,总体模型准确率随着已标注数据量的增加而增加。目标域已标注数据量仅为100的情况下,通过源域和目标域的意图样本对抗训练,在目标域数据下可以取得平均85.1%的准确率,目标域已标注数据量为500时,可以获得平均92.7%的准确率。可以看到,随着目标域已标注数据量的增加,每增加100个已标注数据样本,模型可以取得平均0.015的提升,总体平均准确率达到88.9%,验证了该方法的有效性。
另外,噪声数据的存在影响了模型的总体提升走向。如图5所示,随着目标域数据量的增加,每个任务均有不符合总体趋势的情况。从表2中可以看到,当源域选择为B、W、P、M,目标域选择为B时,在已标注数据为300的情况下,测试结果出现了下降的情况。通过对相关数据集和网络结构的分析,原因主要是:其一,在数据集P中包含了一些“想要播放音乐”的相关表述,与数据集B中“想要预订餐厅”存在一定的相似性,造成意图混淆,导致准确率下降。其二,数据量较少的问题,导致多轮迭代后造成过拟合现象对实验结果造成影响。通过分析,模型性能变化的最主要原因是在英文数据集中不同领域存在文本信息的交叉情况,即领域间文本表述相似度高。

图5 准确率随标注数据量的变化曲线Fig.5 Change curve of accuracy rate with amount of labeled data
中文领域人机对话系统的意图识别任务中,中文意图识别数据集更为稀缺。因此,利用结合胶囊网络的对抗意图识别方法解决中文领域意图识别任务尤为重要。
为了解决上述问题,本实验中文数据采用ATIS航空领域人机对话系统语料、SMP2020中文人机对话评测语料以及扩充语料,其中ATIS数据集作为源域,SMP2020中的单个领域作为目标域进行中文数据下的迁移训练,模型结果如表4所示。表4结果表明,意图识别器在源域上的准确率可以达到90.6%,使用性能优良的意图识别器在中文目标域数据集上也可以获得平均83.3%的准确率。可以得到结论,利用胶囊网络改进的领域对抗神经网络方法能够在一定程度解决中文领域意图识别任务训练数据稀缺的问题。
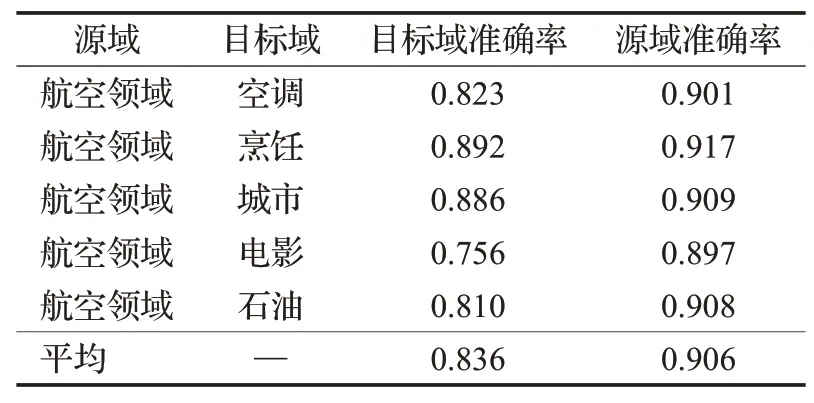
表4 模型在中文数据集下的准确率Table 4 Accuracy of model on Chinese dataset
4 总结与展望
本文主要针对新领域对话系统中训练语料稀缺的问题进行意图识别方法研究。利用胶囊网络改进领域对抗神经网络,通过梯度反转层的对抗训练完成领域自适应,从而完成知识迁移。胶囊网络在数据量较少领域的训练结果较好,且其独有的胶囊长度代表了其类别概率,可以很好地获取意图文本特征,提升领域判别能力。实验结果表明,结合胶囊网络的领域对抗神经网络可以很好地学习源域和目标域的域不变特征,目标域数据可以利用源域所训练的分类器获得不错的效果,验证了领域适应在意图识别的可应用性。为将来利用迁移学习研究新领域人机对话系统奠定了一定的基础。
本文虽然在一定程度上对迁移学习的意图识别问题取得了进展,但就意图识别任务本身还有许多值得研究的问题:(1)针对多意图识别,有时用户的输入文本不可能总包含单一意图,可能包含多种意图类别,而本文主要基于单意图识别任务进行研究,后续将针对多意图识别问题进行研究。(2)针对网络模型,对特征提取器以及胶囊网络架构进行改进优化,减少模型参数,提升训练速度和模型效果。(3)针对未知意图类别。新领域对话系统具有数据稀缺的特点,而意图类别通常由人工预先定义,这样可能造成新领域中部分文本的意图在已知意图类别中不存在,即存在意图类别不完善的情况。后续将对未知意图进行研究。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
计算机技术与发展(2020年11期)2020-12-04
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
电子与信息学报(2015年12期)2015-08-17
噪声与振动控制(2015年4期)2015-01-01
延河(下半月)(2014年3期)2014-02-28
轴承(2010年2期)2010-07-28
