
一种用于多源人脸图像检索的损失函数改进策略
2021-11-12 00:47:22任国印吕晓琪李宇豪
液晶与显示 2021年11期
任国印,吕晓琪,3*,李宇豪
(1. 内蒙古科技大学 机械工程学院,内蒙古 包头 014010;2. 内蒙古科技大学 信息工程学院,内蒙古 包头 014010;3. 内蒙古工业大学,内蒙古 呼和浩特 010051)
1 引 言
目前,从监控摄像机上获取目标嫌疑人人脸图像是公安民警的重要技术手段之一。几乎所有街道都安装了高清摄像头,并且摄像机的覆盖范围很广。高清监控摄像机每天不停地采集视频数据,每天都会产生大量的离线视频。以高清摄像机为例,每秒50~60帧,24 h能够产生500万帧左右的视频录制图片,这样一台摄像机录一个月的视频数据非常庞大。如果将一个区域的所有摄像机数据加起来,就会更加庞大。对于刑侦部门来说,一帧一帧地对可疑视频进行人工过滤,显然是低效和痛苦的。
人脸识别一直是图像识别中的一个重要问题。首先,人脸识别的任务比图像分类要复杂得多。在人脸识别技术中,最重要的工作是人脸图片的特征提取[1-3]。直到2013年,人脸识别还处于手工特征提取阶段,主要依靠图像处理专家对人脸进行仔细分析,最终得到人脸的特征,也就是构建人脸局部描述符。目前,基于深度学习的人脸识别已逐渐取代传统的人工人脸特征识别方法,传统借助人眼来识别人脸的方法已经不能满足刑侦部门的需要。
研究和发展图像检索技术已经进行了近20年[4-6]。但是目前基于内容的人脸图像检索系统还很少,主要的瓶颈是检索精度低和存在语义鸿沟。人脸检索是人脸识别和基于内容的图像检索的结合,它通过匹配人脸特征来搜索现有的人脸照片数据库[7-10]。基于深度学习的图像识别和检索技术逐渐取代现有方法。为了找到一组与被侦查人面部最为相似的照片,进而缩小刑事侦查范围,协助刑事侦查人员确定犯罪嫌疑人的身份。目前基于深度学习的跨多摄像机检索技术的研究还很少,所以基于深度学习的跨多摄像机的人脸检索技术也越来越迫切[11-14]。
M. Zhang、Y. Zhao和M. Sardogan等人提出了基于CNN的图像分类方法,它和传统图像分类方法相比明显提高了分类精度[15-17]。特别地,W.Ge等人使用孪生网络输入同一人脸图像对(正样本对)或不同人脸对(负样本对),每对训练图像都有一个标签。以上两个样本对完成训练,通过最小化相似度损失函数,使同一类人脸之间的距离最小,不同类人脸之间的距离最大。尽管这些数据集预处理方法比以往常用的PaSC、LFW、PubFig、FERET、AR和YaleB等基准数据集有了显著的改进,但更多的研究者试图通过改进损失函数和孪生网络的网络结构来探索改进的可能性。例如Triplet loss是一种广泛使用的学习损失度量函数,它通过添加多个网络分支来提高孪生网络的性能[18-19]。三分支孪生网络Triplet训练使用Triplet loss,这需要3个图像作为输入。与对比度损失不同的是,Triplet loss输入三元组由一对正采样对和一对负采样对组成。这3幅图像分别被命名为锚样本(anchor)、正样本(positive)和负样本(negative)。人脸a和人脸p是一对正样本对,人脸a和人脸n是一对负样本对。三元组可以缩短正样本对之间的距离,扩大负样本对之间的距离。最后,在特征空间中对相同的人脸图像进行聚类。通过类比,Triplet loss只考虑正负样本对之间的相对距离,而不考虑正样本对之间的绝对距离。W. Chen等人使用四分支孪生网络Quadruplet Network和一个新的损失函数来训练局部图像描述符学习模型,该模型可应用于孪生网络Siamese和三分支孪生网络Triplet[20]。四分支孪生网络Quadruplet损失函数产生一个特征向量,该特征向量使属于同一类的正图像之间的距离方差最小化,使属于同一类的样本图像之间的平均距离最小化,并使不同类的图像之间的平均距离最大化。四分支孪生网络损失函数增加负样本的绝对距离,以确保四分支孪生网络不仅在特征空间中扩大正样本和负样本,而且使正样本或负样本彼此靠近。
Trihard loss是Triplet loss的一个改进版本。传统的Triplet loss随机抽取训练数据中的3幅图像作为训练输入。该方法简单,但大多数样本是易于识别的简单样本对。如果大量的训练样本对都是简单的样本对,则不利于网络学习更好的表征。大量的研究发现,使用更难的样本对网络进行训练可以提高网络的泛化能力,对更难的样本对进行训练的方法有很多种。用一种基于训练批Batch的在线困难样本抽样方法,称为难样本损失法,即Trihard loss[20]。
Trihard loss通常比传统的Triplet loss更有效。边界样本挖掘损失(Boundary sample mining loss, MSML)是一种度量学习方法,它引入了难样本采样的思想[21]。Triplet loss只考虑正负样本对之间的相对距离。总之,Trihard loss为Batch中的每个图像选择一个正负样本,而MSML损失函数仅选择最困难的正样本对和最困难的负样本对来计算损失。因此,MSML比Trihard更难采样,可以看作是正样本对之间距离的上界和负样本对之间距离的下界。MSML是将正负样本对的边界分开,因此称为边界样本挖掘损失。一般来说,MSML是一种同时考虑相对距离和绝对距离的度量学习方法,MSML引入了困难样本抽样的思想。
2 本文所用方法
2.1 MSML
MSML是一种度量学习方法,它引入了困难样本抽样的思想。
Triplet loss只考虑正负样本对之间的相对距离。为了引入正负样本对之间的绝对距离,MSML加上了负样本对比较,形成三元数模型。MSML损失函数可定义为公式(1):
Lq=(da,p-da,n1+α)++
(da,p-dn1,n2+β)+,
(1)
如果忽略参数的影响,可以用更通用的形式公式(2)来表示MSML损失:
Lq=(da,p-dm,n+α)+,
(2)
其中m和n是一对负样本对,m和a是一对正负样本对。然后介绍了三孪生损失的难样本挖掘思想,公式(3)中引入了MSML损失函数:
(3)
其中:a、p、m、n是输入的所有图片,a、p是该Batch中最不相似的正样本对,m、n是该Batch中与a最相似的负样本对。总之,Trihard loss[22]为网络选择一个三元难样本输入,而MSML loss[23]仅选择一个难四元组,即最困难的正样本对和困难的负样本对来计算损失。所以MSML loss比Trihard loss更难取样。
2.2 改进型四孪生神经网络
在介绍网络模型设计之前,说明模型的输入是一项必要的工作。首先模型有4个样本作为输入,分别是anchor、positive、negative1、negative2,具体说明如下:
anchor:anchor是锚定样本也就是基准图像,一个随机样本是正样本还是负样本取决于随机样本的分类是否和该锚定样本同属一类,如果属于一类就是正样本,如果不同类就是负样本。
positive:该样本和锚定样本同属一类的样本,因此称之为正样本。
negative: negative1和negative2样本和锚定样本不属于一类样本,由于本模型需要输入两个负样本,因此称之为negative1和negative2。
而样本对泛指两个样本,正负样本是指样本对中一个为正样本和一个负样本,正样本对是指样本对由两个正样本构成,而负样本对是指样本对由两个负样本构成。
按照样本对的难度可以进一步细划分为难正样本对、难负样本对、难正负样本对。这里的难度是相对Siamese、Triplet和Trihard输入样本的复杂度而言的。Siamese是随机抽取两个样本,Triplet是随机抽取两个正样本和一个负样本,Trihard是将两个最不像的正样本和一个与正样本最像的负样本构成一个三元组。本模型需要输入4个样本,这4个样本可构成3组样本对,即难正样本对、难负样本对、难正负样本对,具体说明如下:
难正样本对是同属锚定样本类的人脸样本中差别较大的两张人脸图片,虽然来自一个人但看上去却像不同人的人脸。
难负样本对是不属锚定样本类的人脸样本中差别较大的两张人脸图片,虽然来自一个人但看上去却像不同人的人脸。
难正负样本对是锚定样本类的人脸样本和非锚定样本类的人脸样本构成的样本对,这两个样本的差别较小,虽然样本不是一个人,但这两张图片看上去却像同一个人的人脸。
本文所述方法基于MSML。为了改进MSML损失函数输入的复杂度,从样本输入难度上本文模型输入的难度比以上提到的所有损失函数的输入都要大,因此本文模型可以更加充分拉近同类模型间距离而拉远不同类别间的距离。
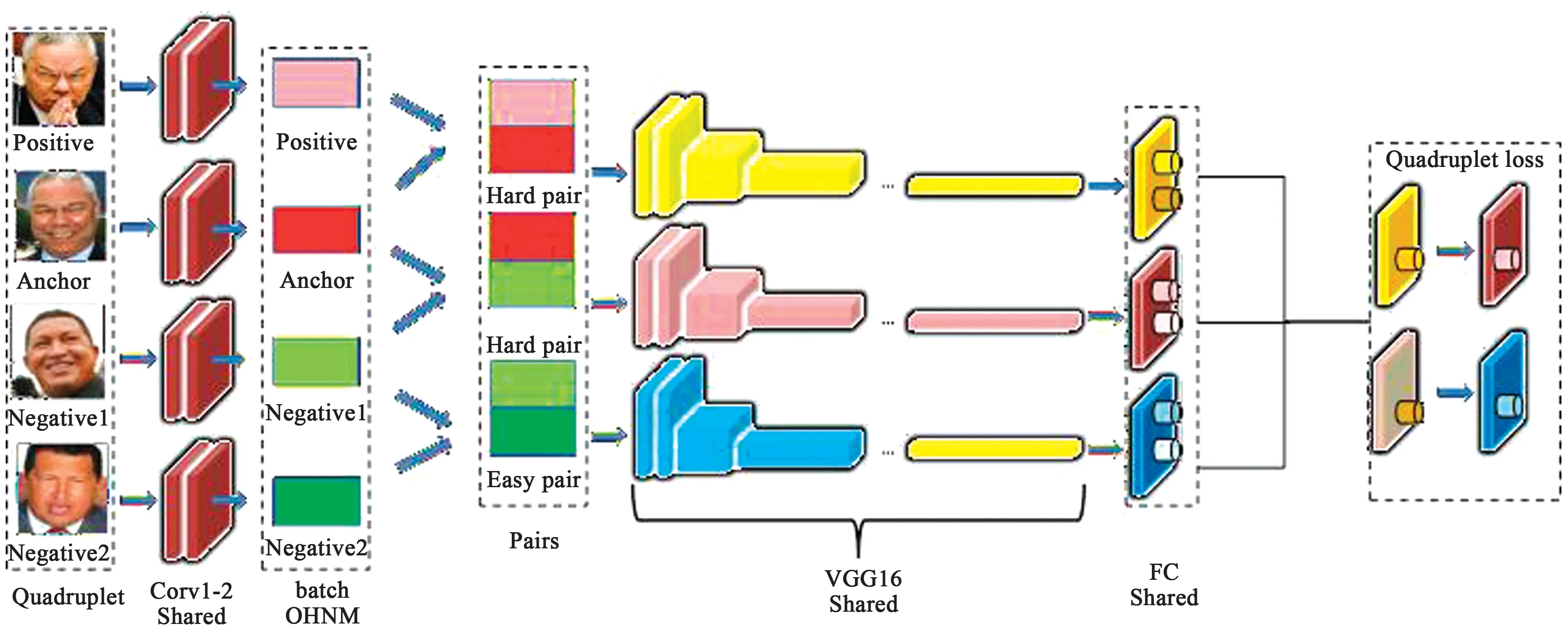
图1 改进的MSML模型结构图Fig.1 Improved MSML model structure diagram
(1) 网络结构:本文使用的网络如图1所示。图像输入仍然是anchor, positive, negative1, negative2四种样本,其中positive和anchor是正样本,negative1和negative2是负样本。通过两个卷积层提取图像特征,形成3对难样本。采用3层VGG16网络对困难样本进行训练,完成样本分类。因此,前3层(1~3层)构成两个正样本和一个负样本面对三分支孪生网络T1,后3层(2~4层)构成两个负样本和一个正样本面对三分支孪生网络T2,即两个平行互相传递参数的三分支孪生网络,如图2所示。
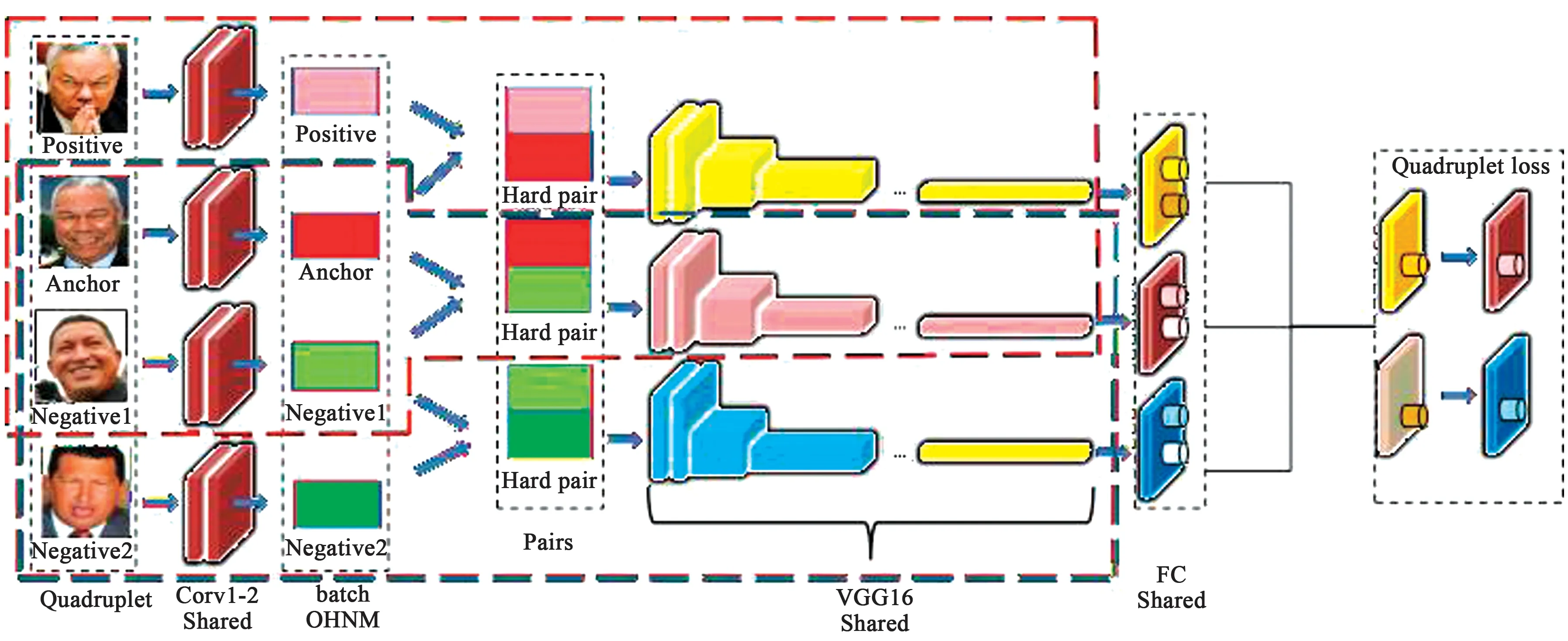
图2 将改进的MSML模型看作双三重网络(DTN)Fig.2 Improved MSML model regarded as the double triple networks (DTN)
(2) MSML改进:从图2可以看出,四分支孪生网络可以看作是两个并行的三分支孪生网络,红色虚线部分是三分支孪生网络,蓝色虚线部分也是三分支孪生网络。本文的创新之处之一是从这一角度对MSML的损失函数进行改进,同时增加输入四元组样本对难度,输入最不相似的正样本对和最相似的正负样本对,同时负样本对之间挑选同一类别中距离最大的负样本对作为样本输入。
MSML在第一层和第二层输入难正样本对(两个最不相似的正样本对),在第3层和第4层输入难负样本对(同一个人的两个最不相似的负样本对)。正负样本对使用了不同人群最相似的两张脸。该方法考虑了正样本距离的上界和负样本距离的下界,同时考虑了相对距离和绝对距离。
在双三重网络(DTN)中,每个三重实现不同的目标,而T1和T2通过Trihard loss计算正采样距离和负采样距离。这样可以防止同一张人脸被误认为其他人的脸。T1和T2的功能是计算具有最难Trihard loss距离,即最不相似的正样本之间的距离,并扩大具有最近Trihard loss距离,即最可能的负样本之间的距离。这将使负样本与正样本完全分离。这相当于同时使用Triphard两次。这样做使得正负样本的模糊边缘变得逐渐清晰,如图3所示。

图3 从边缘模糊样本向难样本和简单样本转换Fig.3 Conversion from margin blurred sample to hard sample and simple sample
双三分支孪生网络(DTN)实现了不同的目标,即红圈区域变大,绿色区域也变大,黄色区域逐渐缩小直到黄圈区域消失,如图3所示。
3 训练策略
3.1 基于子空间聚类的MSML
子空间聚类的计算过程定义为公式(4)和公式(5):

(4)

(5)
Y. Sun等人[23]认为只选择两对样本来形成四元组Batch是不合适的,并提出用OHNM通过聚类来优化Batch。因为这个正负Batch也是从整个样本中选择的,所以当有太多的人脸样本时,很难匹配两个相似的人脸。这也大幅降低了获取难样本的成功率。一个简单的做法是把同一个人的人脸聚在一起。最后,在每个聚类空间中发现难以区分或非常相似的样本。虽然特征提取和聚类比较耗时,但在聚类空间中的搜索速度得到了很大的提高,因此提升了整体系统的实时性。
聚类子空间的个数决定了困难样本提取的成功率。如果子空间的数目太少,那么子空间的划分将与批处理方法非常相似,大量不相似的人脸被聚类成一类;如果子空间数目太多,会将同一个人的人脸图片划分到多个子空间中,这样挖掘的难度就会加大。
采用子空间聚类方法对所有人脸样本进行聚类,将相似的人脸分为一组。在这些聚类空间中形成一个四元数输入比较容易,挖掘效率较高,如图4所示。

图4 聚类子空间中负样本和正样本的选择Fig.4 Selection of negative and positive samples from cluster subspace
3.2 聚焦损失

图5 通过焦损平衡难阴性正样品和难负样品Fig.5 Balance of hard negative samples and hard positive samples by focal loss
聚焦损失(Focal loss)用来解决正样本和负样本比例之间的严重不平衡问题。Focal loss降低了训练中大量简单负样本的权重,这也可以理解为挖掘难样本,如图5所示。
Focal loss[24]是交叉熵损失函数的改进,从二分类交叉损失来看,其表达如公式(6)所示:
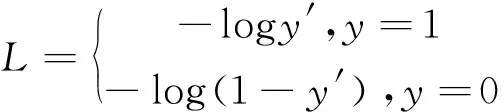
(6)
y′是激活函数的输出,所以它介于0和1之间。对于正样本,输出概率越大,损失越小;对于负样本,输出概率越小,损失越小。当y′减小时,交叉熵损失函数越小,正样本的收敛速度越慢,不适合选择难样本,损失函数没有参数控制正负样本的比例。
(7)
Focal loss通过增加困难样本控制参数和正负样本平衡控制参数,改进了交叉熵损失函数,并用公式(7)计算了Lfl。
如果α是常数,其中γ>0,则对于正样本,如果γ接近1,则所选样本是简单样本,因此-α(1-y′)γ的值将很小,然后损失函数的值将较小。如果γ接近0,则采样困难,损失较大,收敛速度较快。对于负样本来说,它将选择最难的样本,即如果y′接近0。
如果γ为常数,其中α>0,对于正负样本,平衡控制参数α是用来平衡正负样本比例,让正负样本本身更加均匀,正样本比例α越大,负样本越少。相反,α越小,正样本比越小,负样本越多。
4 系统设计
4.1 多摄像机监控的特征共享
在现实中,人脸目标可能会出现在几个监视区域。如果要从这些区域的监控视频中检索出所有的相似人脸帧,就需要建立一个具有数据交换功能的监控网络。
因此,有必要实现多摄像机信息互联和数据共享。多摄像机协作不仅可以扩大监控范围,而且可以从不同角度捕捉人脸信息。如果在摄像机与服务器之间连接多个数据通道来同步人脸特征信息,智能视频监控(IVS)就有可能完成特征交换。在摄像机之间进行人脸特征交换,利用DTN神经网络对摄像机之间的人脸特征相似度进行匹配,就可以完成局域网中的多摄像机人脸识别和相似人脸检索。
为了更清楚地描述上述多摄像头特征同步方法的原理,这里设置了一个2.5D虚拟智慧城市场景,如图6所示。虚拟场景中有10个主要建筑物,假设4个建筑物监控范围内有行人经过,所以一个特征中心和4个建筑物组成一个特征交换监控网络。在理想的情况下,我们假设特征中心没有安装摄像头,其他4栋普通建筑都有监控摄像头。从图6可以看出,每台监控摄像机都给出了自己的编号和定位标志,分别是A、B、C、D。可以看到,在每栋楼的摄像机视野范围内,只有一名行人经过,被拍摄的4名行人也给出了自己的编号和定位标志。其中,A摄像机拍摄行人1,B摄像机拍摄行人2,C摄像机拍摄行人3,D摄像机拍摄行人4。当摄像头A捕捉到行人1的面部特征时,首先通过PUSH将其同步到特征中心。同样,在第一时间,B、C和D摄像机分别将行人2、3和4的面部特征通过PUSH推送到特征中心。特征中心从不同的摄像头接收到这些面部特征后,首先要做的是打包这些面部特征,并在第一时间将它们发送到每个摄像头,以完成SHARE共享同步。在从特征中心接收到SHARE完成的命令后,每个相机将开始PULL同步,即将其他摄像机的人脸特征拉到本地,并将其存储在自己的本地特征库中。完成PUSH、SHARE和PULL的同步操作后,每个摄像头的特征库将保持一致。局部特征库中的特征用于匹配捕获的人脸特征。因此,当行人1通过B、C和D摄像机的视野时,每个区域的监控摄像机都可以识别和检索行人1。类似地,每个摄像机也可以识别和检索行人2、3和4。
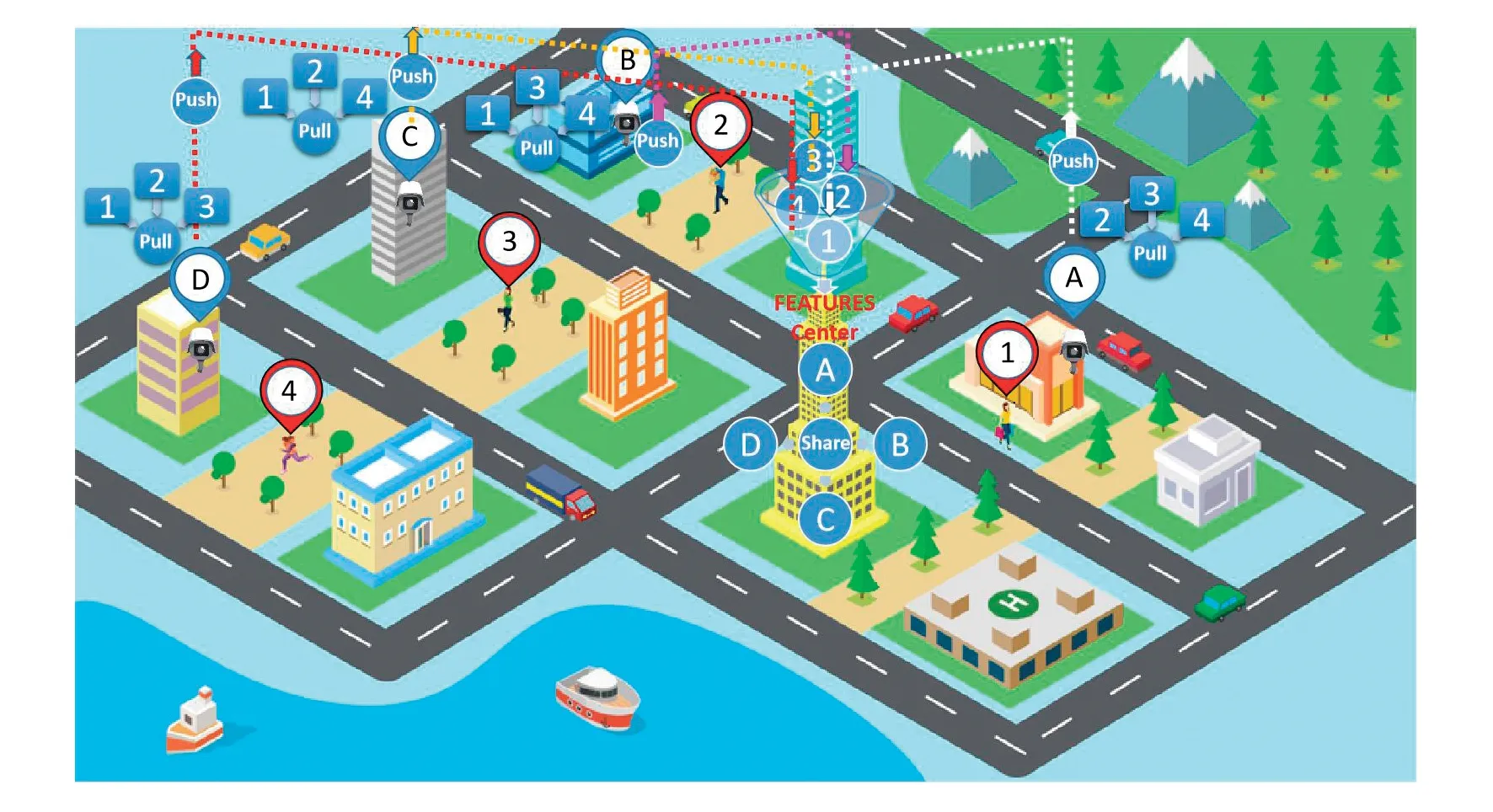
图6 智慧城市数据通道特征共享立体图Fig.6 Stereogram of data channel feature sharing in smart city
4.2 联合人脸检索
4.2.1 训练DTN
(1)人脸训练数据集LFW
户外标记人脸(Wild LFW)是人脸识别中常用的一种测试集,它提供了生活中自然场景下的人脸图像,因此识别起来会比较困难,特别是由于多姿态、光线、表情、年龄、遮挡等因素的影响,甚至同一个人的照片也有很大的不同。而且有些照片可能有多张人脸,对于这些多人脸图像只能选择图片中心坐标的人脸作为目标,其他区域作为背景干扰。目前,LFW数据库的性能评价已成为人脸识别算法的一个重要指标。
(2)图片预处理
采用子空间聚类方法对LFW数据集的所有样本进行聚类,将相似的人脸都聚类到一个子空间中。在局部聚类空间中选择训练的Batch样本对将更容易、更有效。
在每个相似的人脸子空间中包含了简单样本和难样本。所有包含简单样本的子空间都应该被剔除。本文采用Focal loss难样本筛选的方法,剔除简单样本,留下难样本子空间,从中选取本文网络输入的四元组输入。这个四元数输入包含3个难样本对,一个是难正样本,另一个是难负样本,还有一个难正负样本对。系数参见公式(4)所示。
样本方程可以在同一子空间中选取正样本对anchor和positive,负样本对negative1和negative2,Focal loss可以平衡正样本和负样本,解决了正样本和负样本的不平衡问题。
4.2.2 使用改进的MSML训练DTN
子空间聚类和Focal loss可以解决以下问题。子空间聚类方法能更有效地将相似人脸的样本聚类到一个子空间中。对于一个子空间中的所有Batch,预测错误的Batch交叉熵损失不会减少。对于得分好的样本,交叉熵损失将大为减小,而Focal loss使得分好的难样本的损失增大。同时,该模型将更加注重优化样本数较少的损失,训练权重将更加准确。测试分类结果DTN加载训练好的权值,通过样本预处理将每个视频的视频帧输入DTN,对所有人脸进行分类。
4.2.3 联合人脸图像检索
每个视频监控区域将要检索的图像转换为图像的深层特征,用于图像特征匹配,将特征交换和存储层的人脸特征共享给其他视频监控区域后,完成联合人脸检索。
5 实验和结果分析
5.1 改进损失函数有效性的比较分析
LFW数据集主要测试人脸识别的准确性。数据库随机抽取6 000对人脸组成人脸识别对,其中3 000对属于同一个人,3 000对属于不同的人。LFW给出一对照片,询问测试中的2张照片是否是同一个人,然后DTN神经网络给出是或否的答案。将6 000对人脸测试结果的系统答案与真实答案进行比较,可以得到人脸识别的准确率。
DTN在人脸识别方面有很大的优势。在LFW人脸数据库中,人脸识别的准确率为99.51%。虽然在精确度上没有超越功能强大的Facenet网络,但DTN也有很好的表现。DTN除了网络结构的设计外,最重要的是损失函数的选择。
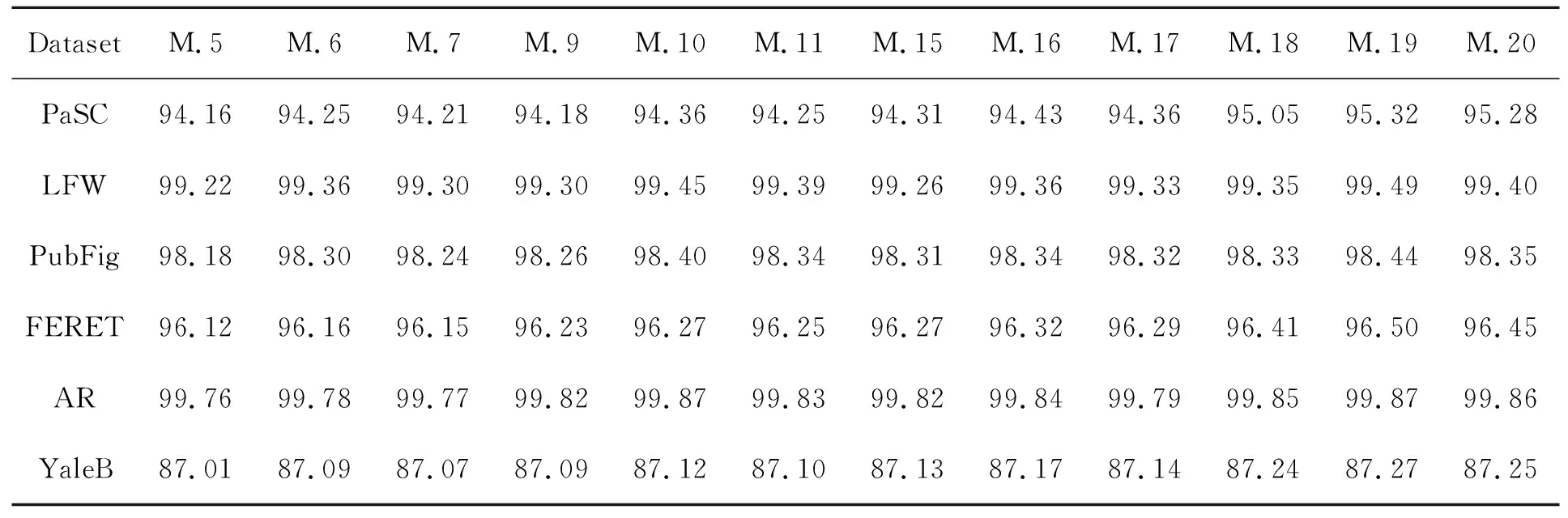
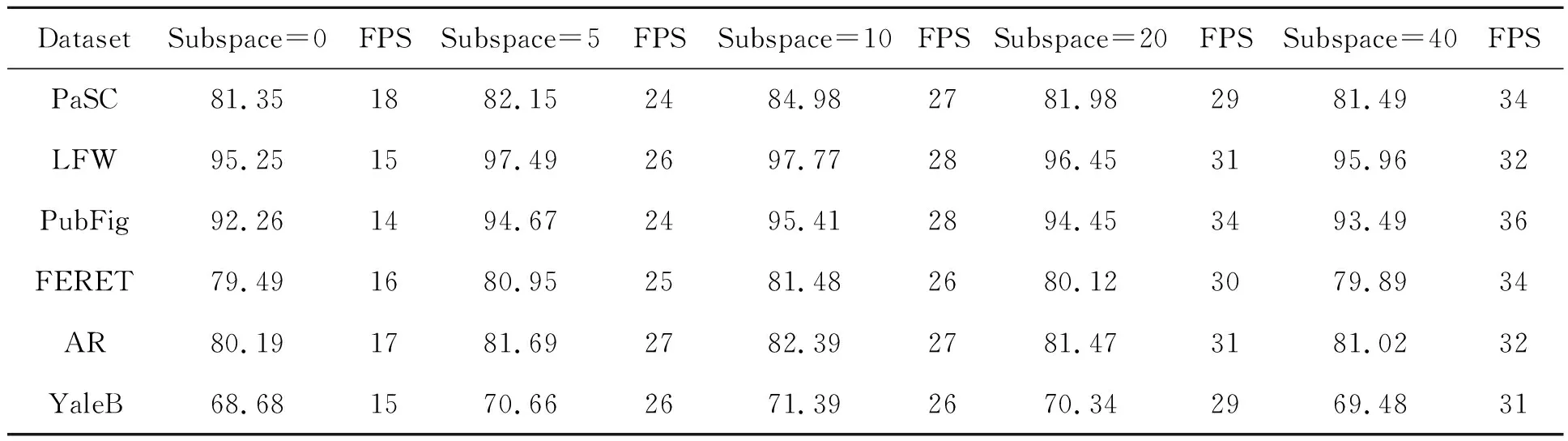
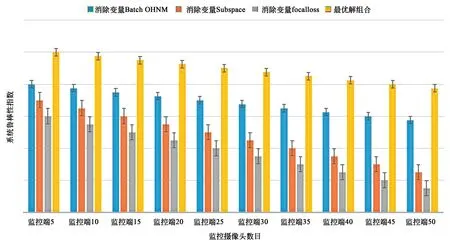
本文采用20种损失函数对Siamese、Triplet和Quadruplet、DTN网络进行训练,比较了哪种网络模型的损失函数性能最好。本文的方法1~12从文献[25]训练精度数据中参考,在此基础上加入各种DTN损失函数,然后从多个角度分析训练的最优结果。从表1中的20种方法的准确度可以看出,acc(Siamese) (1)通过方法1和方法2的横向对比可以发现,随着网络分支的增加,人脸识别的准确率有了很大的提高。 (2)从方法3到7,可以看到使用难样本作为输入提高了Triplet训练精度。然而,当用子空间聚类代替Batch OHNM时,其精度不如softmax。这主要是因为softmax降低了训练难度,使得多分类问题更加收敛。Softmax鼓励增多在实际目标类别中的特征种类。Softmax鼓励在类别之间分离特征,但不鼓励太多的特征分离。然而,通过难Trihard在OHNM上预先使用子空间聚类,可以大幅提高收敛速度和精度。如果从方法8~11中添加softmax,子空间可以更有效地分离。 (3)在使用OHNM和子空间聚类的训练方法5、6、7的过程中,过大子空间会增加负样本干扰,过小子空间会分离出相似的人脸图像,搜索效率会下降。因此,选择合适的子空间数目更为重要。 (4)方法15~17与方法5~7比较,方法8与方法13比较,发现DTN比Triphard更准确。 (5)方法9~11和方法8~20表明,在排序方面,Focal loss优于softmax。通过分析,得出DTN、Batch OHNM、子空间聚类和Focal loss相结合的分类方法是最佳的分类方法,人脸识别效果最为准确。 本文从不同角度对表1中的20种损失函数进行了比较。将20种方法中最具代表性的3组作为判断依据,每组中有6种方法。各组分别建立真阳性率(TPR)和假阳性率(FPR)的ROC曲线。每个模型都有相似阈值的调整。曲线越靠近左上方,分类器就越好。如图7~9所示,每组ROC曲线由6条ROC曲线组成。在FPR都取0.1的情况下,每个ROC曲线中的red分类器产生更高的TPR。这表明ROC越高,分类器越好。 表1 LFW数据集上多种损失函数训练精度对比Tab.1 Comparison of training accuracy of various loss functions on LFW data sets 图7 不同子空间数DTN的ROC曲线图Fig.7 ROC for DTN of different subspace numbers 图7中使用了两种方法:DTN+MSML+Batch OHNM + Subspace和DTN+MSML+ Batch OHNM+Subspace+Focal loss。为3个子空间绘制ROC曲线,子空间数分别为5,10,20。如图所示,为训练添加焦点损失函数可以提高分类精度。同时,子空间个数的选择是关键,子空间不能太多或太少。太多的子空间会使相似的人脸分开;子空间数目太少,许多不相似的人脸被划分到相似的人脸子空间中,降低了遍历效率。 图8 3种不同子空间数的ROC曲线图Fig.8 ROC for Triple of different subspace numbers 图8使用两种类型的方法:Triple+Batch OHNM+ Subspace和Triple+Batch OHNM+Subspace+Softmax。为3种子空间编号中的每一种绘制ROC曲线,分别设置子空间数为5,10,20。从图中可以看出,利用Softmax函数进行训练可以提高Triple的分类精度。此外,子空间数目的选择也很关键,子空间不能太多或太少。太多的子空间会使相似的人脸分开;子空间数目太少,许多不相似的人脸被划分到相似的人脸子空间中,降低了遍历效率。 图9 不同网络与FaceNet的ROC曲线比较Fig.9 ROC comparison between different networks and FaceNet 图9将不同网络与Facenet在性能上进行了比较,结果表明,虽然DTN的精度比Facenet低,但与其他模型相比,DTN的训练效果有了明显提高。 本文选取表1中5、6、7、9、10、11、15、16、17、18、19、20的方法在PaSC、LFW、PubFig、FERET、AR and YaleB数据集上完成训练和测试。 在数据集PASC、LFW、PubFig、FERET、AR和YaleB中,本文利用这些方法计算了平均搜索精度ARP的性能评价。 采用平均检索查准率对人脸检索结果进行评价。每个数据库中的每幅图像都作为一个查询图像来检索所有剩余的图像,以记录相应网络的检索性能。对数据库中所有数据的检索精度和检索率进行平均,得到平均检索精度(ARP)。 采用Triplet+Batch OHNM+Subspace、Triplet + Batch OHNM + Subspace + Softmax和DTN MSML + OHNM + Batch + Subspace + Focal loss三种训练模式对PaSC、LFW、PubFig、FERET、AR和YaleB数据集的ARP进行测试。 表2使用上述3种训练模式计算了上述6个数据库中平均检索精度最高的最佳匹配人脸。从表2中可以看出,这3类子空间的ARP在LFW上最高,在YaleB上最低。这是因为扩展的YaleB增加了很多干扰因素,如光照、姿态等,在这3种方法中,DTN-MSML+Batch-OHNM+Subspace+Focal方法的性能最好。同样地,选择子空间数为10可以提高训练精度。 表2 最顶层匹配的平均检索精度(ARP)Tab.2 Average retrieval precision (ARP) for topmost match (%) 通过以上对比实验,发现模型损失函数的最佳组合为:DTN(MSML)+Batch OHNM+subspace-10+Focal loss。在本节中,我们将建立该模型的消融实验[26]。消融实验的目的是从一个单独角度探讨每个变量的作用。这里以DTN(MSML)为基本模型,控制变量主要包括Batch OHNM、Subspace和Focal loss。我们一次只减少一个变量来观察检索精度、实时性、鲁棒性的变化。 5.4.1 控制变量Batch OHNM 从DTN+Batch OHNM+Subspace-10+Focal loss的组合中去除Batch OHNM,选择随机样本配对。从表3可以看出,正样本对和负样本对没有难样本配对机制,使得DTN模型失去了拉开正样本和负样本之间相对距离的意义,导致检索率大幅降低。通过Batch OHNM机制,可以在DTN模型中加入两个不同模式的样本,使得模型具有异构性,大幅提高了检索精度。然而,由于样本选择的困难,预处理时间比随机样本时间长,因此严重影响了实时性。 表3 在PaSC、LFW、PubFig、FERET、AR和YaleB上使用DTN+ Subspace-10 + Focal Loss的10个检索图像的ARP。Batch OHNM对检索精度和样品预处理时间的影响 5.4.2 控制变量Subspace 从DTN+Batch OHNM+Subspace-10+Focal loss组合中去除子空间(Subspace),不生成聚类子空间。从表4可以看出,没有子空间聚类的DTN模型检索精度大幅降低,焦点丢失无法找到模糊样本集,进而无法平衡困难样本对的比例。同时,由于没有子空间聚类,使得困难样本的配对效率低下,导致预处理速度慢。加入子空间聚类机制后,可以快速发现相似样本,包括相似正样本和相似负样本。但是从表4来看,太少的聚类子空间划分会减慢搜索速度,如子空间为5,而太多的聚类子空间划分会丢失出许多相似的样本对,如子空间为20,子空间为40,这也破坏了样本的内部关系。因此,选择合适的聚类子空间数目是非常重要的。从实验中可以看出,子空间为10是最好的子空间划分,而且每个数据集的检索精度最高,而随着子空间数目的增加从更小的范围内搜寻目标样本的时间明显降低,因此实时性会有所提高。 表4 10个使用DTN+批次OHNM+在PaSC、LFW、PUBPIG、FERET、AR和YaleB上使用DTN+批次OHNM+焦耗检索的图像的ARP。聚类子空间的数目对检索精度和实时性的影响 5.4.3 控制变量Focal loss 从DTN+Batch OHNM+Subspace-10+Focal loss组合中消除Focal loss,这样做的后果是正、负样本既不均衡,也不利于难样本筛选。从表5可以看出,DTN模型输入端缺乏难样本筛选,在很大程度上是从简单样本聚类子空间中选择样本对,不能充分发挥模型的相对优势。同时,正样本与负样本之间不平衡,导致正负样本混淆,进而导致模型训练中的过拟合问题,大幅降低了检索精度。Focal loss的增加使得难样本进行过滤成为可能,也可以分离模糊样本带来的过拟合问题。通过调整Focal loss函数参数,发现当α=0.5时,即正负样本均衡,训练精度随样本难度的增加而提高。然而,当样本数相等时,训练精度提高,即样本难度最大时,训练精度提高γ=0.9。样本不平衡引起的过拟合问题使得检索精度降低(例如,当α=0.1和α=0.9时),从实时性角度未做样本均衡的输入会增加正负样本的搜索时间,影响实时性表现,而样本均衡设置的不好的情况(例如,当α=0.1和α=0.9时)也会使帧频降低,实时性表现不好,只有正负样本均衡的情况实时性才表现最佳。 以上消融实验结果表明,各变量的作用是不可或缺的。同时,每个变量都有参数调整状态,以达到最优解。从表3、表4和表5中可以得到最佳参数,最佳参数如下:①选择批量OHNM预处理;②子空间为10是子空间聚类的最佳聚类数;③α=0.5,γ=0.9是焦损的最佳参数。因此在最佳参数设置下,本文选择DTN(MSML)+Batch OHNM+Subspace-10+Focal loss的最佳组合,共同配合提高了检索精度,且实时性可达28 PFS左右。 表5 10个使用DTN+批次OHNM+在PaSC、LFW、PUBPIG、FERET、AR和YaleB上使用DTN+批次OHNM+焦耗检索的图像的ARP。Focal loss对检索精度和实时性的影响 为了验证系统的鲁棒性,应用Silktest测试工具建立测试,将系统监控数目和鲁棒性之间建立内部关联项,在最优化组合、消除变量Batch OHNM、消除变量Subspace、消除变量Focal loss属性上评估系统鲁棒性。从图10测试结果中可以看出,随着监控压力逐渐加大,最优解组合的鲁棒性表现最优,而其他每个变量都将对鲁棒性造成严重影响,其中Focal loss是对系统鲁棒性影响最大的变量。 图10 系统鲁棒性分析图Fig.10 Robust analysis of the system 本文提出了一种新型网络结构DTN。通过对Siamese,Triplet和Quadruplet的比较,我们发现网络结构与网络分支的通道数有关。在分支数相同的情况下,最重要的是如何设计有效损失函数。本文对DTN网络进行了改进。网络结构是一种双三分支孪生结构,以两个样本对为输入,可以拓宽正负样本之间的距离,使正负样本完全分离。本文设计的损失函数是几种损失函数的结合。为了提高搜索速度,选择了子空间聚类方法。在DTN网络的样本预处理阶段,为了解决增加训练难度和均衡样本的问题,在训练阶段采用了Focal loss函数。基于MSML,比较了20种方法的网络损失。实验结果表明,DTN + OHNM + Batch+Subspace+Focal loss具有较高的ARP、ARR和F-score值。因此,该方法的平均检索精度(ARP)为98.74%,模型训练精度为99.54%,帧率为28 FPS,能够满足人脸检索的实际应用,并且系统考虑了远程视频检索在刑侦部门远程通缉嫌疑人目标人脸应用中的实际困难。设计了一个多摄像机人脸联合检索系统,解决了多摄像机特征共享和特征联合的问题,实现了多局域网多摄像机人脸联合检索。5.2 损失函数受试对象工作特征曲线(ROC)综合比较




5.3 联合人脸检索的有效性分析
5.4 消融实验


5.5 系统鲁棒性测试
6 结 论
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
动漫星空(2018年9期)2018-10-26 01:17:14
中国公共安全(2017年8期)2017-10-13 08:12:17
中国公共安全(2017年11期)2017-02-06 05:27:47
办公自动化(2016年18期)2016-12-17 19:32:18
专利代理(2016年1期)2016-05-17 06:14:36
新闻前哨(2015年2期)2015-03-11 19:29:25
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
