
基于多向特征金字塔的轻量级目标检测算法
2021-11-12 01:56:04王英杰DJUKANOVICMilena
液晶与显示 2021年11期
白 创,王英杰,闫 昱,DJUKANOVIC Milena
(1. 长沙理工大学 物理与电子科学学院,湖南 长沙 410114;2. 柔性电子材料基因工程湖南省重点实验室,湖南 长沙 410114;3. 黑山大学 电气工程学院,黑山共和国 波德戈里察 81000)
1 引 言
目标检测是机器视觉领域的研究热点之一,因其快速、准确、可识别性高等特点广泛应用于无人驾驶、行人检测和视频监控等领域。传统的目标检测方法[1]主要是根据先验知识建立数学模型并求解该模型得到检测结果,而此种人工设计特征加浅层分类器的方案只能提取细节信息较少的低层特征,检测精度和鲁棒性受到极大限制[2]。由于卷积神经网络能够自动学习到更深层次的特征表达,与传统方法相比,学习到特征的鲁棒性更强、精度与速度更高,因此广泛应用于目标检测领域。
目前基于卷积神经网络的检测方法主要包括两大类:基于区域的双阶段目标检测方法,如R-CNN系列[3-5];基于回归的单阶段目标检测方法,如RetinaNet[6]、SSD[7]、YOLO[8-10]等。双阶段检测器使用生成建议网络提取特征后送入分类器得到类别,而单阶段检测器不需要额外的区域分类步骤,直接对特征映射图上每个位置的目标进行分类预测。双阶段检测器较单阶段检测器检测精度更高但实时性明显降低,故YOLO作为检测精度与速度均衡发展的单阶段检测器得到更加广泛的研究与应用。YOLO是一种端到端的实时目标检测框架,将物体检测作为回归问题进行求解,不需要预先通过生成建议网络(RPN)得到感兴趣区域(ROI),而是直接将图片送入特征金字塔网络[11](FPN)提取特征经过分类回归器得到输出。轻量级目标检测模型Tiny YOLOv3较YOLOv3减少了大量的特征提取卷积层与残差块,同时仅使用FPN简单级联,忽略了更深层次的语义特征及梯度消失问题,损失了较多的有效信息从而检测精度明显下降;其次,网络模型尺寸虽然随着卷积层的减少而降低,但仍然存在着计算量(FLOPs)冗余影响检测速度的问题;最后,在计算损失函数时未考虑坐标点之间的相关性及关键指标IOU(Intersection over Union)的影响,导致边界框定位不够准确,回归精度明显下降。
本文针对Tiny YOLOv3存在的特征提取不充分、检测速度受限、边界框回归精度低的问题,通过改进金字塔特征提取网络、使用深度可分离卷积与引入CIOU loss函数,提出实时高精度MTYOLO检测模型。
2 Tiny YOLOv3目标检测原理
Tiny YOLOv3以回归的方式训练由7层类Darknet-19构成的主干网络,同时通过 K-means 聚类算法对样本数据集进行聚类学习,分别在13×13和26×26两个尺度上得到两组 anchor box 作为先验框进行后续的回归操作。在针对多目标问题时,使用logistic分类器取代softmax分类器,解决了同一物体属于多个类别的表征问题。
在Tiny YOLOv3中,将输入图像送入卷积神经网络提取特征并划分为S×S的网格,每个网格包含3个预测框,每个预测框产生4个用于回归的参数(x,y,w,h) 与 1 +n个用于分类的参数(c,p1,p2,...,pn),送入预测层产生预测框返回值参数(ox,oy,ow,oh,oc,op1,op2,...,opn),可以表示为:
ox=σ(x) +cx,
(1)
oy=σ(y) +cy,
(2)
ow=pwew,
(3)
oh=pheh,
(4)
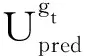
(5)
opi=σ(pi),
(6)
式中:ox、oy、ow、oh为预测框的中心点坐标和宽高,σ()代表sigmoid函数,σ(x)、σ(y)为预测框中心对应网格左上角的横坐标、纵坐标,cx与cy为当前网格相对于左上角网格偏移的网格数,pw与ph为边界框的宽度与高度,ew与eh为横纵方向上的缩放因子。c代表该边界框的置信度,当网格中存在目标时Pr为1,否则为为预测框和真实框的交并比;bpi为n个类别通过分类器的概率,当bpi大于0.5时,表示该边界框负责的目标属于此类。最后,将多个边界框的参数通过非极大值抑制(Non-maximum suppression,NMS)运算得到最终的位置信息和类别预测值。
3 改进的MTYOLO检测模型
改进的MTYOLO检测模型包括主干网络、特征融合网络、预测层与输出层。如图1所示,主干网络将输入图像经过一系列卷积操作得到不同感受野的特征图,特征融合网络将生成的各层特征图通过多向级联得到两种尺度的特征向量,送入预测层产生大量带有位置与类别信息的预测框,最后由NMS得到输出层的检测结果。

图1 MTYOLO检测模型Fig.1 MTYOLO test model
3.1 MdFPN特征提取网络
特征提取网络是影响目标检测算法性能的关键因素之一。Tiny YOLOv3使用传统的FPN采用bottom-up跨层连接方式保留了高层特征的语义信息与低层特征的细节信息,提升了小物体的检测效果。然而传统的FPN只能学习相邻尺度的特征,固有地接收单向信息流,导致网络过多关注低层特征的优化,累计更多的梯度从而不能充分学习高层特征。
MTYOLO采用MdFPN(Multi-directional feature pyramid network)结构通过在传统的FPN提取网络上添加双向交叉连接及侧向级联后充分地进行多层间不同分辨率、不同语义特征的融合,缓解了原网络在特征提取过程中对边缘信息的忽略,极大地共享了网络权重参数,提高了网络敏感度。此外,由于偶数卷积核因其感受野不对称会在特征图中累计位置像素的偏移,致使空间信息受到严重侵蚀,故选择奇数卷积核作为核函数。与较大的卷积核相比,3×3的卷积核可在保证获得相同感受野和更多特征信息的同时消耗更少的计算资源。因此,MdFPN选择堆叠多个3×3卷积核代替较大的卷积核以便获得更好的非线性判决网络。算法的整体网络结构如图2所示。
(1)构建了7层的主干网络,使用6个卷积模块(包含卷积、标准化和Leaky ReLU激活3个过程)与最大池化提取复杂背景下的物体信息,将输入图像X1经过32倍降采样后得到Y6,保证在提取到(208,104,52,26,13,7 pixel)各尺度特征图的情况下控制网络层数。
(2)添加图像融合与跨层连接运算。将主干网络特征图Y2~Y6与跨层上采样后的Y9~Y11进行初次融合得到特征融合层C1~C5。
(3)利用3个深度可分离卷积与2个 3×3 卷积完成对初步融合图像特征的再次提取,获得更多有效的特征。此时,由于C4、C5特征通道数过大故使用普通卷积防止计算量骤增。
(4)移除Tiny YOLOv3中单一特征融合与预测的卷积层,通过对(1)、(2)、(3)中各层特征图进行最大池化、深层卷积与特征融合操作得到不同尺度的输出向量C6~C9,使其既包含池化聚焦的空间信息与前一层融合变换后的局部特征,又包含本层与后一层的全局特征。
(5)将特征融合后的Y12、Y13分别卷积后得到output1、output2,直接送入预测层用于多分类和回归操作,不断训练迭代模型,得到最终的检测结果。
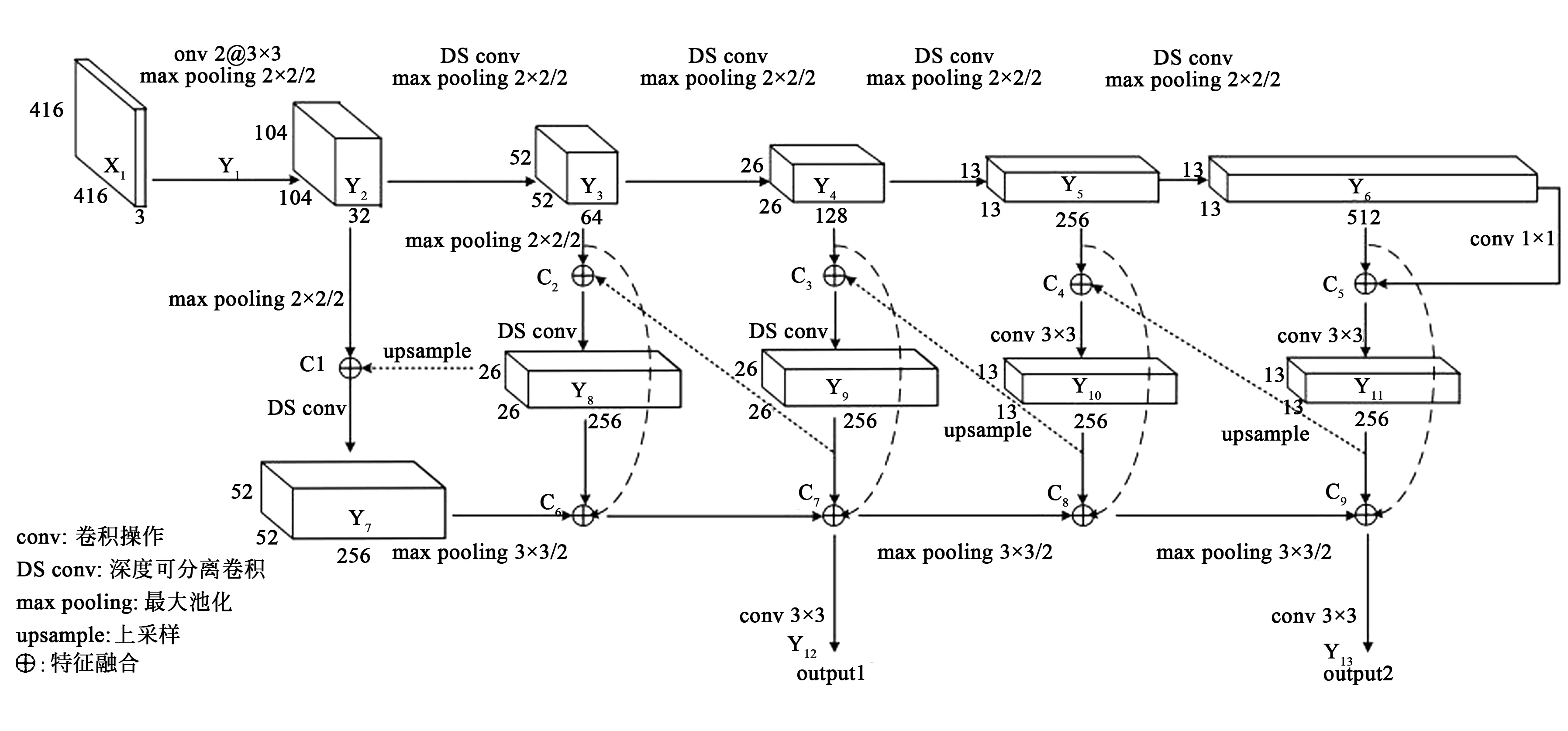
图2 MdFPN特征提取网络Fig.2 MdFPN feature extraction network

表1 Tiny YOLOv3与模型A在VOC2007/COCO数据集上的mAP
将仅使用MdFPN代替Tiny YOLOv3网络的简单级联,不改变其他结构的检测模型记为模型A。由表1可以看出,相对于传统的Tiny YOLOv3网络,模型A在VOC2007和COCO数据集上的mAP分别提升了13.3%和14.1%,表明MdFPN可有效融合多层信息,提高检测精度。
3.2 深度可分离卷积
传统的卷积计算每一步都需要关注所有通道的计算区域从而累积较多的参数。针对深层网络导致模型计算复杂度过高与检测速度受限的问题,可采用模型裁剪[12]与使用深度可分离卷积构建网络来减少参数占用内存设计轻量级模型,但由于模型裁剪可能会带来不可逆转的细节丢失,故选择深度可分离卷积对MTYOLO模型进行简化。
深度可分离卷积将标准卷积分解成两层。一层用于滤波,在输入的每个通道上独立执行空间卷积;一层用于组合,将深度卷积的通道混合后使用点卷积输出。如图3所示,输入图像为DF×DF×M,输出图像为DW×DH×N,当采用标准卷积核DK×DK×M×N时,此卷积层的计算量为DK×DK×M×N×DF×DF;而使用深度可分离卷积时卷积层的计算量为DK×DK深度卷积和1×1点卷积的计算量之和。故采用深度可分离卷积与使用标准卷积的网络计算量之比为:

(7)
以MdFPN的第二层结构为例,网络中输入特征图为104×104×32,输出特征图为104×104×64。由(7)式可知,DK=3时,网络参数可被压缩为原来的1/9。因此,MdFPN使用多个深度可分离卷积可构建紧凑的模型,从而提升检测速度。从理论上来说,模型的时间复杂度可以用来衡量检测速度,即一张图像送入模型进行一次完整的前向传播所需的浮点运算个数(FLOPs)。由于普通卷积相比于深度可分离卷积而言,在进行卷积运算时的数据调用的逻辑更加繁琐,且在对每个特征图的卷积操作完成后还会对这些特征图进行累加操作,大量的中间数据需要更多的寄存器来存储,故在前向传播时将花费更多的时间。

图3 标准卷积和深度可分离卷积Fig.3 Standard convolution and depthwise separable convolution

表2 Tiny YOLOv3与模型B的参数总量、FLOPs及FPSTab.2 Total parameters,FLOPs and FPS of Tiny YOLOv3 and Model B
将仅使用深度可分离卷积代替部分标准卷积,其他网络结构均不改变的检测模型记为模型B。由表2可知,相比传统的Tiny YOLOv3网络,模型B的参数总量下降了12.3%,模型尺寸减小了68.5%,FPS在GPU和CPU上分别提升了40.6%和49.2%。结果表明,使用深度可分离卷积代替标准卷积极大地节省了计算资源,提高了检测速度。
3.3 损失函数的优化
Tiny YOLOv3仅使用MSE函数作为网络的回归函数,独立地计算边界框4个坐标点的损失,未考虑坐标点之间的相关性与距离损失的尺度不变性,故存在收敛速度慢和回归不准确的问题。针对MSE函数存在的问题,充分考虑边界框回归的三要素:重叠区域、中心点距离和长宽比,MTYOLO采用CIOU损失代替MSE,通过引入IOU(图4)、添加惩罚项αv来最小化两个边界框,进一步明确了梯度优化的方向。MSE函数与CIOU损失可描述为式(8)、(9):
(8)

(9)
式中,gt代表真实框,o与ogt分别为预测框与真实框的中心点,d表示欧氏距离;c表示预测框和真实框最小外接矩形的对角线距离,与IOU共同实现对预测框相交面积的约束;ɑ是一个正的权衡参数,控制梯度下降方向;而v约束两框的相交比例,使模型能够向区域重叠更密集的方向优化,进一步提高检测结果。将ɑ与v表示如下:
(10)
(11)
对于分类损失与置信度损失,使用二值交叉熵损失函数,则总损失可以表示为式(12):
(12)
Lconf=-tclogoc-(1-tc)log(1-oc) ,
(13)
Lcls=-tpilogopi-(1-tpi)log(1-opi) ,
(14)
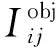

表3 Tiny YOLOv3与模型C在VOC2007/COCO数据集上的mAP
将仅使用 CIOU损失代替MSE,其他网络结构均不改变的检测模型记为模型C。由表3可以看出,相对于传统的Tiny YOLOv3网络,模型C在VOC和COCO数据集上的mAP分别提升了10.3%和8.2%,表明使用CIOU loss可提高回归框的检测精度进而提升mAP。
3.4 模型传播过程分析
模型训练过程分为前向计算及反向传播过程。在两个过程交叠往复中持续对权值参数保持更新,使损失函数结果达到最小。在 MTYOLO 前向传播的过程中第i个卷积层可以表示为式(15):
Yi=F(Xi)=F(Xi-1*wi+bi),
(15)
式中,Xi、Yi分别代表输入与输出张量,wi、bi表示第i层的权重信息与偏移量,F()是激活函数。将输入图像通过特征提取等操作得到网络最后一层的输出参数Yi。进行后向传播时,第i层的损失函数的梯度信息可以表示为式(16)。其中,⊙为逐元素乘积(Hadamard乘积)。
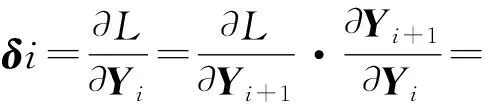
(16)
此外,Lconf(Lcls)对Yj的梯度信息可以表示为式(17),则参数oj向着tj方向梯度更新时可以得到理想的置信度与分类误差。
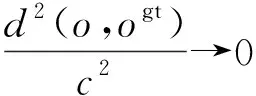
(17)
(18)
因此,对约束参数v进行求导得到式(19)、(20),其中,对于每一轮训练的wgt与hgt均为已知常数。由式(19)、(20)可知,若预测框的长和宽⊂[0,1]时,w2+h2的值会很小,可能导致梯度爆炸,因此应将其替换成1。
(19)
(20)
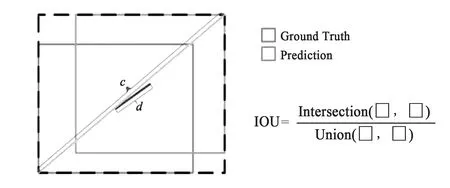
图4 IOU、c及d的示意图。Fig.4 Schematic diagram of IOU, c and d.
4 实验结果及分析
研究基于上述理论与消融实验的分析,在网络结构上将Tiny YOLOv3原有的类Darknet-19替换为MdFPN特征提取网络,使用深度可分离卷积代替部分标准卷积,并在预测层利用CIOU loss取代MSE函数,构造新的MTYOLO检测模型。实验环境为:Ubuntu 18.04;TensorFlow Version:1.13;CUDA Version: 10.1;内存: 32 G;GPU:Tesla P4。实验采用的数据集为PASVAL VOC 2007/2012和COCO 2014。VOC数据集由20种不同类型的物体标注的自然图像组成,包含训练验证集train_val共16 551张,测试集test 4 952张;COCO数据集包含了80个种类的目标,包含训练验证集train_val共123 287张,测试集test 40 775张。
4.1 训练过程
MTYOLO输入图片大小为416×416,批处理大小为64,最大迭代次数为 20 000,初始学习率为 0.001,动量为0.9,权重衰减率为 0.000 5。训练过程中使用交叉熵损失(Cross entropy loss)和CIOU loss对网络权重参数进行反向随机梯度下降更新权重,实现网络的有效学习。当迭代次数到达5 000次,学习率降为0.000 1;当迭代次数达到10 000次,学习率进一步降为0.000 01。
图5为使用 VOC 2007+2012数据集进行训练验证的回归误差(val_loss)与每2 500轮计算一次得到的分类准确率(Accuracy)得到的曲线。由图可知,经过 20 000 次迭代后,val_loss逐步趋于稳定,最终下降到 5.5左右,分类正确率上升至84.2%,与Tiny YOLOv3相比较,回归误差下降约50.9%,分类正确率上升约9.3%,表明训练得到的模型较为理想。同时,当MTYOLO的mAP达到56.9%时,仅耗时1 036 800 s,较Tiny YOLOv3减少了近25.9%,训练速度得到了较大的提升。
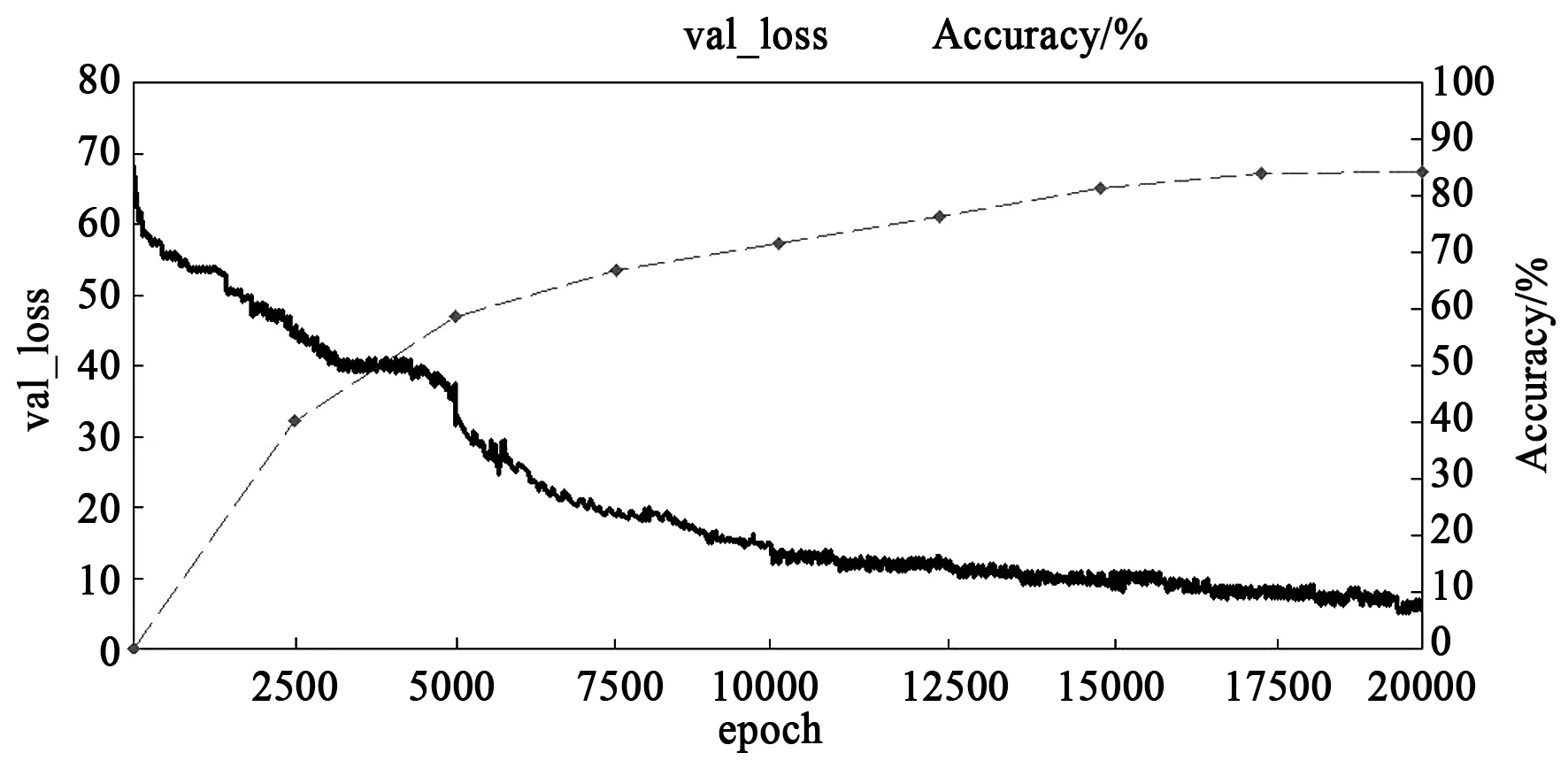
图5 回归误差与分类正确率Fig.5 Regression error and classification accuracy
4.2 测试结果
为了评估改进算法的准确率,对MTYOLO及马立[13-16]等人改进的Tiny YOLOv3模型分别在VOC 2007与COCO数据集上进行测试,结果如表4所示。
由表4可以看出,MTYOLO较Tiny YOLOv3在VOC和COCO数据集上mAP分别提升了25.3%和27.5%,模型尺寸下降了15.2%,FLOPs下降了5.6%,FPS在GPU与CPU分别提升了25.6%和36.2%。并且,与马立等人改进的模型及YOLO系列最新版本v4、v5相比,在损失较小精度的情况下,检测速度更理想,更适用于嵌入式平台。 因此,通过使用MdFPN网络、深度可分离卷积和CIOU损失构建目标检测模型,能在提升检测精度的基础上,有效地减少网络参数和计算量,保证检测速度提升到一个更高的水平。
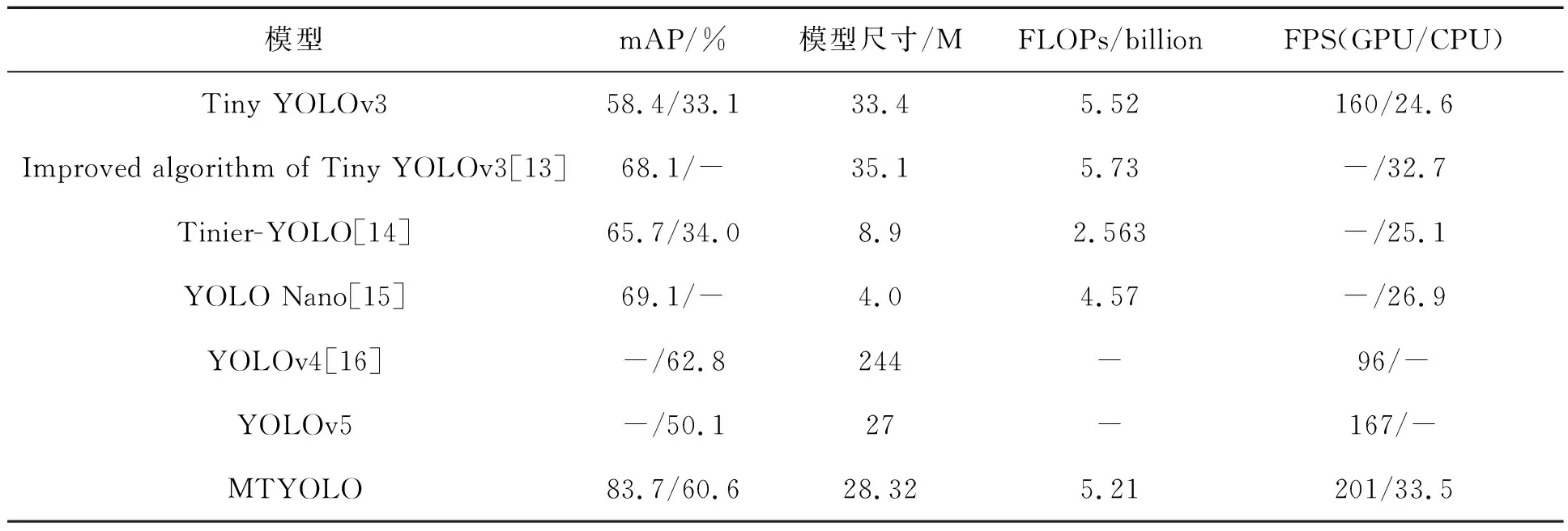
表4 七种模型在VOC/COCO上的mAP和模型尺寸、FLOPs、FPSTab.4 mAP on VOC / COCO and Model size, FLOPs, FPS for seven models
5 结 论
基于Tiny YOLOv3改进的检测模型MTYO-LO,通过构造多向特征金字塔与深度可分离卷积的特征提取网络代替标准卷积堆叠级联的网络结构,并使用CIOU损失代替MSE作为该模型的回归损失函数,在保证检测速度较理想的情况下提高了mAP。在PASCAL VOC和COCO数据集上与其他轻量级的目标检测算法进行对比实验,结果表明,MTYOLO具有更高的mAP,并且取得了较快的检测速度。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
噪声与振动控制(2015年4期)2015-01-01 07:08:21
