
基于DCN的无监督域自适应行人重识别方法
2021-11-12 00:47:22杨海伦王金聪任洪娥
液晶与显示 2021年11期
杨海伦,王金聪,任洪娥,3*,陶 锐,4
(1. 东北林业大学 信息与计算机工程学院,黑龙江 哈尔滨150040;2. 东北林业大学 机电工程学院,黑龙江 哈尔滨 150040;3. 黑龙江林业智能装备工程研究中心,黑龙江 哈尔滨 150040;4. 呼伦贝尔学院,内蒙古 呼伦贝尔 021008)
1 引 言
行人重识别方法[1]旨在依据行人的一张查询图像,在大规模图像数据中检索出同一行人最相似的前n张图片。基于深度学习理论[2-4]的行人重识别方法研究主要分为有监督学习的行人重识别[5]和无监督学习的行人重识别[6-13]两类。随着行人重识别领域研究的不断深入,数据集规模和数量也在不断扩大,但是其需要耗费大量人力和时间进行数据集的标注。因此,近些年的行人重识别研究逐渐开始转向无监督域自适应(Unsupervised domain adaption,UDA)行人重识别方法。
卷积神经网络[3](Convolution Neural Networks,CNN)作为深度学习的重要组成部分,它凭借特征提取的巨大优势受到广泛关注,但在卷积操作中也会导致图像中的许多重要信息丢失。可变形卷积网络[14-15](Deformable Convolutional Networks,DCN)通过加入可变形卷积核模块和可变形兴趣区域(ROI)池化模块,提高了CNN的特征提取能力。此类方法可以在特征提取过程中定位到感兴趣的采样点位置,并通过反向传播进行网络训练。
2018年,Deng等[6]提出的一种UDA风格转换模型(Similarity Preserving Generative Adversarial Network,SPGAN)和Wei等[7]提出的行人风格迁移模型(Person Transfer Generative Adversarial Network,PTGAN)实现了风格迁移应用于无监督域自适应问题。CamStyle[8]通过学习相机的不变性对相机风格进行迁移,在一定程度上解决了过拟合问题。然而,这些方法比较依赖生成图片的质量,没有关注生成对抗网络[16](Generative Adversarial Network,GAN)与CNN间的迭代优化、影响域适应能力。2019年,Fu等[9]提出一种基于聚类方法的UDA模型SSG,依据行人的全局和局部特征寻找目标域样本间相似性进行聚类,然而该模型没有从根本上解决域间差异性问题。Song等[10]提出的UDA模型,在一定程度上提高了域适应能力,但没有过多关注域间、相机间风格差异问题。本文基于Song等的UDA模型提出基于DCN的域自适应模型,其UDA模型的训练过程主要分为3个步骤:首先,在已标注的源域上进行预训练;之后,基于聚类算法执行伪标签的预测,依据伪标签进行特征学习;最后,通过两个步骤的反复迭代进行训练。由于域间、相机间的风格差异性较大,使聚类生成的伪标签变得不准确,影响域自适应能力。因此,缓解域间、相机间风格差异所带来的负面影响是UDA成功的关键。
本文提出将可变形卷积加入到CNN模型中,代替传统的CNN模型,有效缓解了UDA中存在的遮挡问题。预训练阶段提出应用SPGAN直接减小域间差异,训练过程中应用CycleGAN[6]生成不同相机风格图像解决相机风格差异性问题。为了进一步提高识别准确率,提出多损失协同训练的方法实现CycleGAN和复用CNN模型的迭代优化。
2 研究技术与模型架构
2.1 可变形卷积网络结构
本文提出的可变形卷积网络结构主要是将可变形卷积嵌入到ResNet-50[17]网络框架中,替换其中固定卷积层和池化层,更换为可变形卷积层和可变形池化层,提高特征学习能力。二维卷积主要包含两个步骤,首先使用规格固定的卷积核R在特征图x上进行滑动采样,之后利用采样点乘权重w求和。其中R决定感受野大小和扩张,如:R= {(-1 , -1) , (-1 , 0), … , (0 , 1) , (1 , 1)},传统的卷积过程[3]如公式(1)所示:
(1)
Pn是R中所列位置的枚举值,P0是输出在特征图上的位置。DCN的卷积过程则在规则网格R中增加一个偏移量来提高特征提取的自适应能力,同样位置的P0则需要加一个偏移量ΔPn(第n个采样点的偏移),采样位置变为不规则可形变的区域。因此,可变形卷积过程[14]如公式(2)所示:
(2)
由于特征图上每个位置的取值需要整数,而公式(2)中ΔPn是非整数,故采取双线性插值的方式处理(寻找坐标距离最近的4个像素点,计算该坐标点的值)。
可变形卷积与传统卷积的对比如图1所示,传统卷积只需要训练网格点的相应位置点权重,可变形卷积通过增加额外参数来训练卷积网格窗口形变。因此,可变形卷积的采样点选取可以通过学习得到。图1(a)为传统卷积的规则采样点位置,1(b)为可变形卷积的采样点位置。
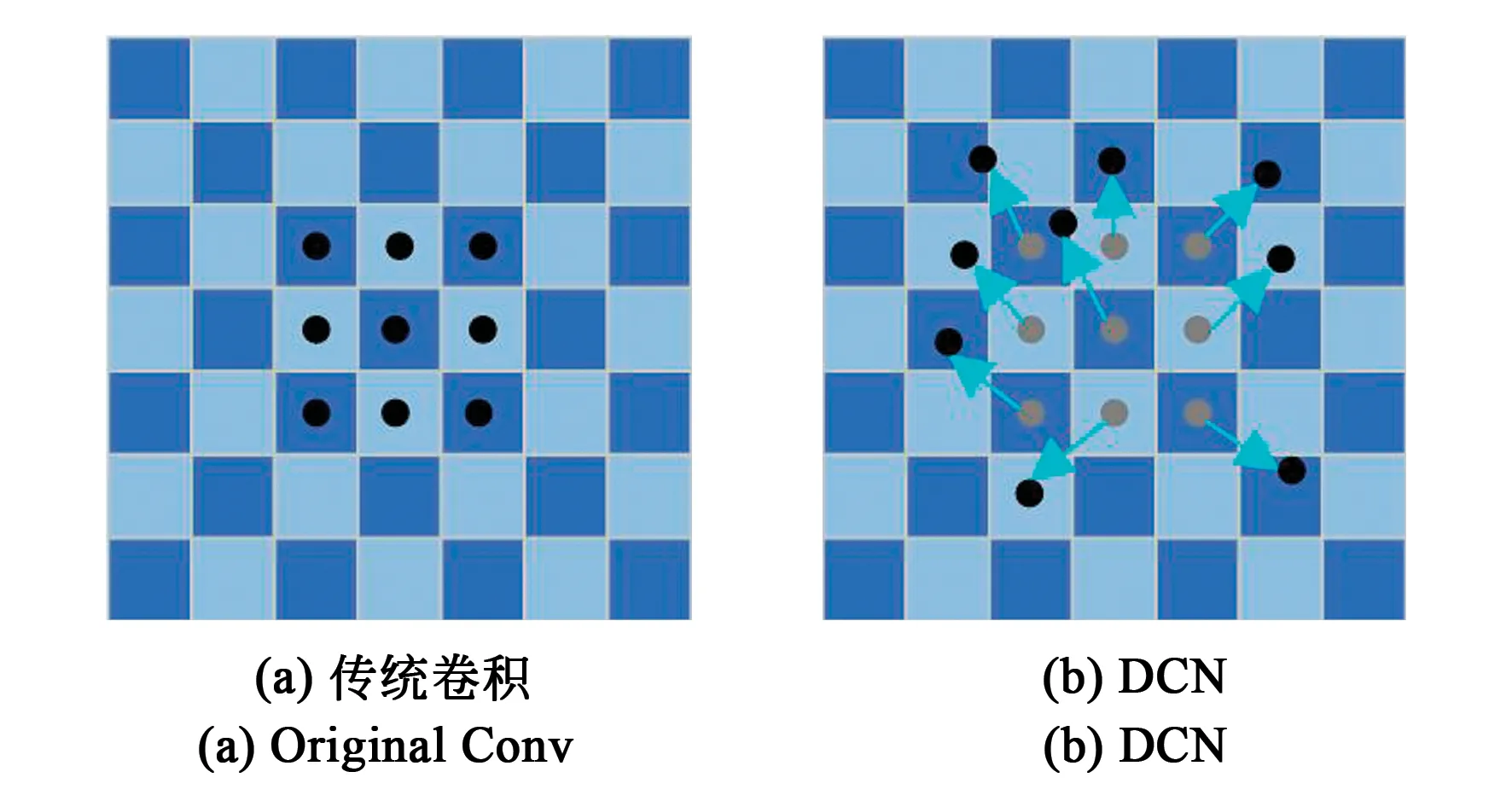
图1 传统卷积和可变形卷积对比图Fig.1 Comparison of traditional convolution and DCN
传统的卷积过程主要分为两个步骤:首先利用已定义感受野大小和扩张的网格窗口卷积核R在特征图上滑动,之后根据窗口权重相乘求和。
相对于传统卷积过程,可变形卷积过程[14]如图2所示。使用3×3的可变形卷积执行卷积操作,在训练过程中,同时学习用于生成输出特征的卷积核和偏移量。偏移量特征与输入特征的分辨率相同,通道数需要是采样点个数的2倍,即每个位置需要有x、y二维的偏移量。可变形卷积单元中增加的偏移量是网络结构的一部分,使用平行的传统卷积单元计算,因此可以通过反向传播实现端到端的训练,偏移量的增加使特征提取过程偏向于感兴趣的区域,即达到采样点位置的自适应变化。
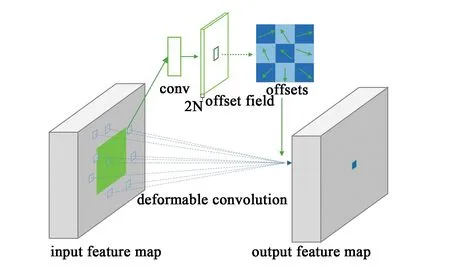
图2 3×3可变形卷积Fig.2 3×3 deformable convolution
可变形池化过程类比于可变形卷积过程,同样采取增加偏移的方法,实际处理过程[15]如图3所示。给定输入特征图x,首先通过一个兴趣区域池化将它划分为k×k个容器,经过兴趣区域池化后的特征图通过一个全连接层产生归一化偏移,全连接层的输出为容器个数的2倍。

图3 可变形池化Fig.3 Deformable ROI pooling
由于需要偏移和兴趣区域尺寸相匹配,故对偏移做微调,偏移量可转化为ΔPk,单个容器的输出特征可以表示为公式(3)[15]:
(3)
其中:Pkj表示第k个容器的j个采样点坐标,x(P0+ΔPk)通过双线性插值求得,nk代表第k个容器的采样点数量,ΔPk表示第k个容器的偏移量。
本文采取的特征提取网络架构是将可变形卷积结构和可变形池化结构嵌入ResNet-50中,将ResNet-50网络中conv3~conv5中所有的3×3传统卷积替换为可变形卷积,并于相应位置加入可变形池化层。
2.2 基于源域的有监督预训练
2.2.1 SPGAN实现域间风格迁移
SPGAN以CycleGAN作为基础框架,能够解决无监督行人重识别中存在的域间差异问题。首先,使用两个镜像对称的生成对抗网络搭建环形网络,实现图像的风格转换;其次,加入新的损失函数辅助生成器生成目标域风格的行人图像;此外,加入孪生网络及对应的一致性损失函数,保证转换之后关键身份信息不丢失。
2.2.2 预训练损失函数
使用分类损失函数Lcls与改进的三元组损失函数LBH协同训练,对预训练模型微调,总损失函数为:
Lsrc=Lcls+LBH,
(4)
分类损失函数[11]定义为:
(5)
其中:N表示批量所包含的图像数量,i代表图像索引。改进的三元组损失函数[18]被定义为:

(6)

2.2.3 预训练过程
应用SPGAN实现源域风格迁移,使用基于DCN的CNN模型在源域上进行预训练。为了提高收敛速度,梯度变化更加稳定,在可变形池化层后加入BN层;为了抑制过拟合,使用Adam优化器代替SGD优化器。
2.3 基于DCN的无监督域自适应模型
基于DCN的无监督域自适应模型如图4所示。首先,使用预训练好且基于DCN的CNN模型进行特征提取,通过距离度量获得源域和目标域之间的距离矩阵M,使用DBSCAN[10]算法进

图4 基于DCN的域适应模型框架图Fig.4 Framework diagram of domain adaptation model based on DCN
行行聚类以赋予无标签数据集标签数据。之后,基于目标域样本应用CycleGAN,生成不同相机风格的图像数据扩充目标域样本。将生成样本和目标域样本一同输入到复用的CNN模型(即共享权重),依据生成的伪标签,通过多损失协同训练方式实现CycleGAN和复用CNN模型的迭代优化。
2.3.1 DBSCAN聚类方法生成伪标签
DBSCAN聚类方法是一种基于密度的聚类算法,此方法由特征样本分布紧密程度决定。将紧密相连的样本划分为同一簇,将不同簇划分为不同类别,从而得到不同的聚类结果。
在本框架中,首先利用在源域预训练好的CNN模型提取无标签目标数据集的特征矩阵,通过距离度量获得源域数据集和目标数据集之间的距离矩阵M,然后依据DBSCAN聚类方法对其聚类,依据聚类结果赋予无标签的目标域生成伪标签。
D=DBSCAN(M,τ,n),
(7)
其中:τ为半径,与距离矩阵M共同描述样本分布紧密程度;n为密度阈值。
2.3.2 样本风格增强
受源域与目标域的域间差异问题影响,基于DBSCAN聚类算法生成的伪标签存在部分噪声。除此以外,目标域训练样本的数量限制也导致每个聚类中样本多样性较低,这就导致模型域自适应能力低、学习能力差。针对这个问题,本文提出了数据样本风格增强(Sample Style Augmentation,SSA)的方法,应用GAN扩充目标域解决样本不足的问题。使用GAN生成的新样本需要满足条件:保留原始身份ID的同时,从现有的行人生成新的行人数据,克服相机风格差异。
循环生成对抗网络[6](Cycle-consistent Adversarial Networks,CycleGAN)的网络结构包括两个生成器G(X->Y),F(Y->X),两个判别器DX、DY,旨在实现域X到Y的普适映射,而不是单一的x到y的映射,能够满足不同相机风格转换的要求。因此,本文使用CycleGAN产生不同相机风格的新行人数据扩充目标域样本数据。例如,数据集中含有N个相机,首先进行CycleGAN模型训练,该模型能够实现不同相机图像之间的转换,基于伪标签生成N-1张不同相机风格的行人数据图像。通过数据增强,目标域每个聚类样本数量变为原来的N-1倍。
2.3.3 多损失协同训练
如图5所示,CycleGAN样本风格增强模型包括两个生成器G(X->Y),F(Y->X),两个判别器DX、DY。
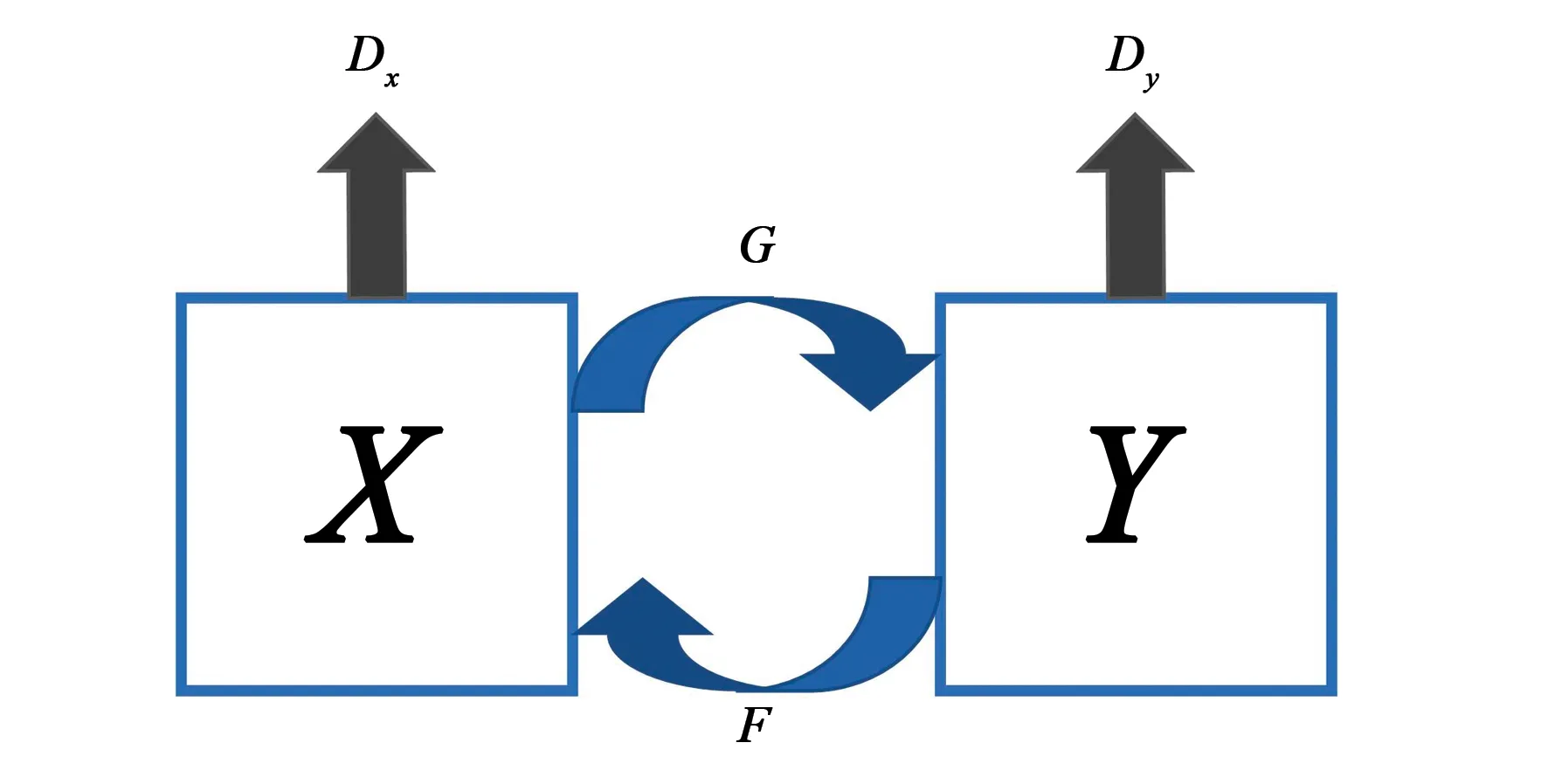
图5 CycleGAN网络结构Fig.5 CycleGAN network structure
该部分选取的损失函数[6]LSSA为:
LSSA=LGAN(G,DY,X,Y)+
LGAN(F,DX,Y,X)+Lcyc(G,F),
(8)
利用对抗损失LGAN使生成图像在分布上更加接近于目标图像,其中LGAN被定义为:
LGAN(G,DY,X,Y)=Ey~pdata(y)[log(DY(Y))]+
Ex~pdata(x)[log(1-DY(G(x)))],
(9)
使用循环一致性损失Lcyc防止学习到的映射G和F产生矛盾,Lcyc可以表示为:
Lcyc(G,F)=Ex~pdata(x)[‖F(G(x))-x‖1]+
Ey~pdata(y)[‖G(F(y))-y‖1].
(10)
为了进一步提高模型准确率,实现CycleGAN模型和复用CNN的迭代优化,本文提出改进的三元组损失函数LBH、分类损失函数Lcls和CycleGAN损失函数LSSA协同训练的多损失协同训练(Multi-loss Training,ML)方法,总体模型损失函数为:
Lloss=Lcls+LBH+LSSA,
(11)
Lcls、LBH如公式(5)、(6)所示。
3 实验与结果分析
本文在源域DukeMTMC-reID/Market-1501和目标域Market-1501/DukeMTMC-reID下对本文所提出的模型进行消融实验、对比实验,来验证本文算法的有效性。

Algorithm 1 模型训练过程Input:源域数据集S,目标域数据集TOutput:CNN模型F 1:CNN模型F在源域进行预训练 2:for 每次进行聚类迭代 do: 3: 特征提取:F(T),F(S);求距离矩阵M 4: 聚类:D=DBSCAN(M,τ,N) 5: for 从T中取出一个batch的样本 do: 6: 样本风格增强,数据扩充 7: 多损失协同训练,优化 8: end for 9:end for 10:return CNN模型F
3.1 数据集设置和评估方法
本文采用两个无监督行人重识别领域常用的公开数据集Market-1501和DukeMTMC-reID,使用累积匹配特性(Cumulative match characteristic curve,CMC)中的Rank-1、Rank-5、Rank-10和平均精度(mean average precision,mAP)作为评价标准。

(12)
对于n位命中率Rank-n的描述如下:qi对应的Gqi在前n位包含同一行人,则qi满足n位命中条件,待检索图像集中所有满足n位命中的图片数量记为N′,则Rank-n可表示为
Rank-n=N′/N.
(13)
Market-1501数据集共有6个相机、1 501名行人,共包含了32 688张图像数据。其中训练集涵盖751人,共包含12 936张图像数据;测试集涵盖750人,共包含19 732张图像数据。DukeMTMC-reID共有8个相机、1 404个行人,共包含了36 411张图像数据。其中训练集涵盖702人,共包含16 522张图像数据;测试集涵盖702人,共包含19 889张图像数据。
3.2 实验环境及参数配置
本实验采用两个GeForce GTX 2080 Ti GPU,操作系统为Ubuntu16.04,基于python3.6和pytorch1.7.1完成程序编写。基于DCN的域自适应模型的迭代次数是30次,每次迭代70个epoch,批量大小设置为128。选用Adam优化器,设置学习率为6×10-5,动量设定为0.9。
3.3 消融实验
为了验证本文提出模型的有效性,在两个无监督公开的行人数据集上进行不同域自适应实验。分别以Market-1501为源域,在DukeMTMC-reID上进行无监督实验;以DukeMTMC-reID作为源域,在Market-1501上进行无监督实验。本文以Song等[10]提出的自训练框架方法作为Baseline,消融实验对比结果如表1所示。
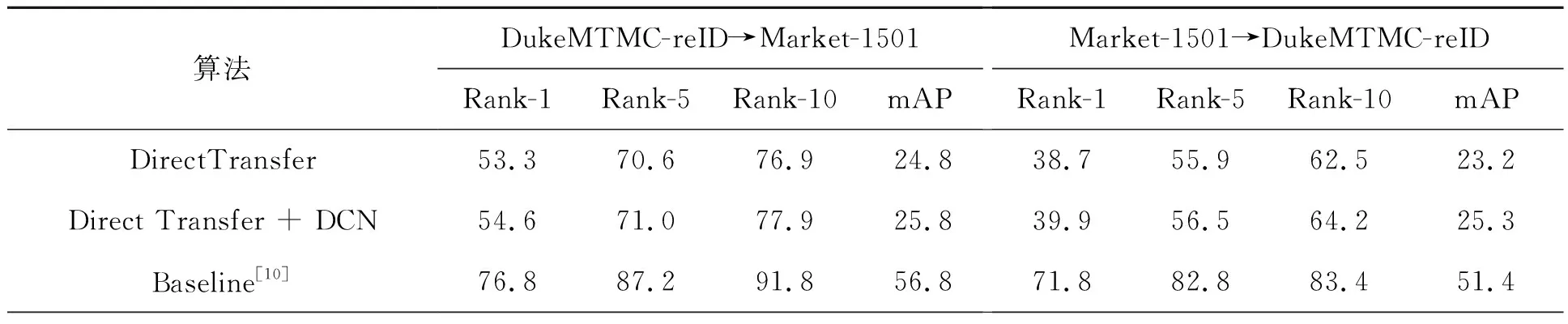
表1 消融实验对比结果Tab.1 Comparison results of ablation experiments (%)

续 表 (%)
首先,针对基于可变形卷积的CNN模型有效性进行实验,验证可变形卷积对特征提取能力的提高。从表1中可以看到,在DukeMTMC-reID/Market-1501>Market-1501/DukeMTMC-reID实验中:使用基于DCN的CNN模型代替Baseline中的传统CNN模型,mAP提高了4.4%、3.8%,Rank-1提高了3.9%、2.4%。验证了基于DCN的CNN模型较传统CNN模型在特征提取方面的优越性。为了进一步验证可变形卷积对CNN模型特征提取能力的提高,对比DCN-ResNet50和ResNet50特征提取能力,使用CAM实现特征提取过程中第5阶段(即layer4)的可视化热力图,其部分可视化结果如图6、7和8所示。结合可视化结果和表1中的实验结果可知,可变形卷积的增加使得特征提取部位更加偏向于我们感兴趣的区域,即达到采样点位置的

图6 第5阶段输出特征可视化热力图1Fig.6 Fifth stage output feature visualization heat map 1

图7 第5阶段输出特征可视化热力图2Fig.7 Fifth stage output feature visualization heat map 2

图8 第5阶段输出特征可视化热力图3Fig.8 Fifth stage output feature visualization heat map 3
自适应变化,有效缓解遮挡、分辨率低等噪声问题。
由表1可知,加入样本风格增强后,使得图像数据得到扩充,提高了基于DCN的CNN模型学习能力。实验结果表明,使用样本风格增强后,mAP提高了4.5%、4.6%,Rank-1提高了4.7%、2.6%。证明了使用CycleGAN生成不同相机风格下的行人图像,实现了样本数据增强,并且在一定程度上抑制了DBSCAN聚类伪标签噪声问题,缓解了不同相机间的风格差异问题。
为了验证多损失协同训练方法,使用CycleGAN进行样本风格增强,并重用基于DCN的CNN模型,利用多损失协同训练方法实现CycleGAN模型和复用CNN模型的迭代优化。实验结果表明,使用多损失协同训练后,mAP提高了3.0%、4.3%,Rank-1提高了2.8%、1.3%。结果表明,多损失协同训练方法对于模型间的迭代优化训练过程有一定程度的提高,可获得更好的行人重识别效果;验证了CycleGAN损失函数(LSSA)在模型训练中的作用,能够提高CycleGAN生成图像数据的质量。
3.4 本文方法与现有主流方法对比实验
将本文方法与主流无监督行人重识别方法进行比较,表2给出以Market-1501/DukeMTMC-reID为源域,以DukeMTMC-reID/Market-1501为目标域的比较结果,“-”表示对应方法未在数据集上实现,其中包括:依据图像属性的MMFA[19]无监督行人重识别方法;基于域适应的7种无监督行人重识别方法SPGAN+LMP[6]、CamStyle[8]、AD-Cluster[11]、ACT[12]、CR-GAN[20]、PCB-PAST[21]、ECN++[22];基于全局与局部特征多重聚类的SSG[9]方法;针对无监督行人重识别的多标签分类来预测多类别标签,学习ID特征的MPLP[13]方法;基于风格正则化的SNR[23]方法;基于注意力机制的域对齐方法DAAM[24]。
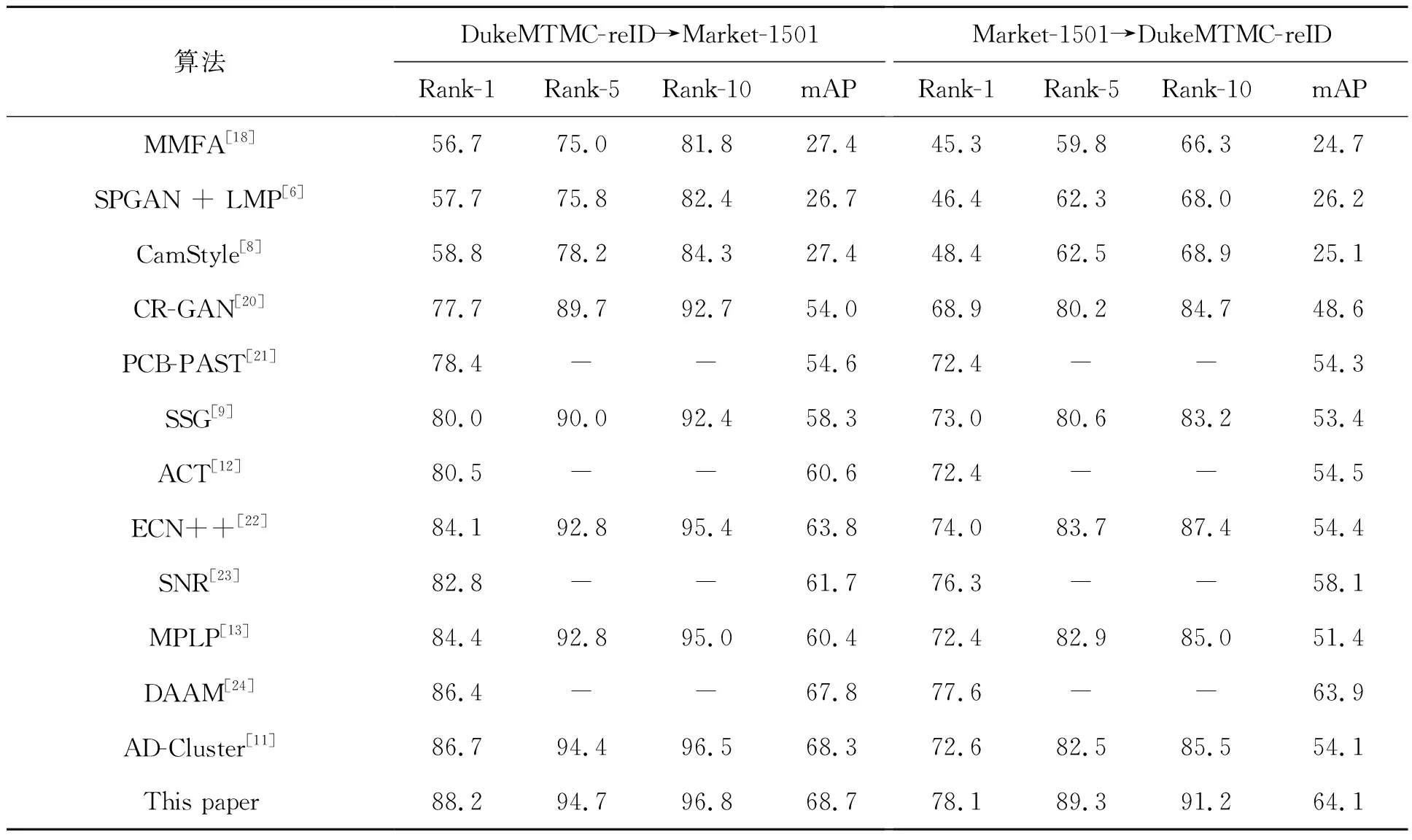
表2 算法结果对比Tab.2 Comparison of algorithm results (%)
本文方法高于所比较的主流竞争方法,在Market-1501上测试,Rank-1准确率为88.2%,mAP为68.7%。相较于目前性能优异的AD-Cluster、DAAM、MPLP、ACT、ECN、SNR等均有不同幅度的提升。在DukeMTMC-reID上进行测试,本文方法获得的Rank-1准确率为78.1%,mAP为64.1%。均高于目前主流方法,且较AD-Cluster的mAP精度提高了10%,Rank-1精度提高了5.5%,验证了本文方法的有效性。
总体来说,本文在CNN模型中嵌入可变形卷积,提高了CNN模型对行人的特征提取效果,缓解了数据集中普遍存在的遮挡、分辨率低等问题;使用样本风格增强和多损失协同训练方法,缓解了不相交相机视图下的类内变化大和类间模糊的问题。本文提出方法实现了无监督行人重识别跨域的域自适应,抑制了跨域所导致的性能大幅下降问题,具备在无标注目标数据集上的泛化能力。
4 结 论
本文针对传统CNN模型特征提取过程的遮挡、分辨率低等噪声问题,提出基于可变形卷积的CNN模型,使特征提取部位更偏向于感兴趣的区域,即达到采样点位置的自适应变化。针对域间、不同相机风格间差异性较大的问题,在预训练阶段提出应用SPGAN直接减小域间风格差异性,训练过程中提出应用CycleGAN生成不同相机风格图像数据解决相机风格差异性问题。为了进一步提升无监督域自适应行人重识别准确率,提出多损失函数协同训练的方法实现GAN和复用CNN模型的迭代优化过程。在当前无监督行人重识别领域的公开数据集设定前提下,对本文提出的方法进行验证。实验表明,在源域DukeMTMC-reID/ Market-1501和目标域Market-1501/DukeMTMC-reID下实验,mAP和Rank-1分别达到了68.7%、64.1%和88.2%、78.1%。实验结果表明,本文提出的基于DCN的域自适应模型,能够有效解决数据集中存在的遮挡、分辨率低等噪声问题;能够降低域间、不同相机风格间的差异性;有效提升无监督域自适应行人重识别的准确率。但仍有进步空间,未来工作可以在现有方法基础上进一步改进以提升特征聚类的准确度。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
意林(2021年5期)2021-04-18 12:21:17
电子制作(2019年11期)2019-07-04 00:34:38
扬子江(2019年1期)2019-03-08 02:52:34
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
电视技术(2014年19期)2014-03-11 15:38:20
