
视觉注意机制的注意残差稠密神经网络弱光照图像增强
2021-11-12 00:47王一斌刘立波
液晶与显示 2021年11期
邓 箴,王一斌,刘立波*
(1. 宁夏大学 信息工程学院,宁夏 银川 750021;2. 四川师范大学 工学院,四川 成都 610000)
1 引 言
高质量的清晰图像获取对于机器视觉任务,如视频监控、医疗诊断、自动驾驶、目标检测等领域尤为重要,它能为机器视觉操作提供准确的图像信息,确保机器视觉任务顺利完成。然而,在弱光照或曝光不足条件下拍摄的图像往往存在亮度低、色彩饱和度差、细节信息难以辨认等问题,不但降低了图像质量,还影响了后续机器视觉任务的准确度。因此,作为图像预处理操作的弱光照图像增强技术具有重要理论意义和应用价值。
传统的图像增强方法可分为两类:基于直方图均衡化的方法和基于成像模型的方法。直方图均衡化的方法可看作是利用直方图调节图像的灰度动态范围从而增强图像的过程。如PIZER等人提出的自适应直方图均衡化图像增强算法[1],KANDHWAY等人提出的结合全局直方图均衡化的图像增强算法等[2]。这类方法虽然简单高效,但暗区域易出现增强不足,而亮区域增强过度,从而出现色偏问题。
基于成像模型的方法又可分为:基于去雾模型的方法和基于Retinex理论模型的方法。基于去雾模型的方法发现反转后的弱光照图像与雾天图像有较高的相似性,若能利用去雾算法对反转的弱光照图像进行去雾处理,再将去雾结果反转回来,即可得到增强图像。如DONG等人提出的基于去雾模型的弱光照图像增强算法[3];LI,YANG和FENG等人提出的基于去雾的对比度增强算法[4-6]。这类方法在某种程度上虽能有效增强弱光照图像的视觉效果,但缺乏严谨的物理解释,易出现颜色失真问题。另一方面,具有严密理论支撑的Retinex理论模型增强方法被广泛使用。它将弱光照图像看作光照图像和反射率图像的乘积,利用估计出的光照图像,求得不受弱光照影响的反射率图像,即增强图像。如GUO等人提出的LIME(low-light image enhancement method)方法,通过求R、G和B颜色通道中像素的最大亮度值估计光照图[7],再利用光照图的结构先验修正和细化光照图,进而生成增强图像。赵晨等[8]采用局部零度算法调整图像的整体光照效果。FU等人利用高斯和拉普拉斯概率函数约束光照图像和反射率图像的分布,并构建加权变分模型来估计光照和反射率图像[9-10]。程亚亚等人[11]则采用一种基于自蛇模型滤波的全息图像增强方法,能对干扰信息进行抑制,去除“伪轮廓”,使刀具的边缘更加清晰。林剑萍等[12]将分数阶微分与Retinex相结合,提出一种自适应的弱光照图像增强方法。总体而言,上述算法利用先验知识或已有约束来估计Retinex理论模型中的光照图,从而计算反射率图像。然而,当先验知识或已有约束无法描述复杂变化的光照条件时,光照图像的估计会出现误差,从而影响后续反射率图像的准确度。
近年来,卷积神经网络被广泛应用于图像处理的各个领域,其中也包括弱光照图像增强。LORE等人[13]提出了基于深度自编码器的弱光照图像增强及去噪算法,它利用堆叠的稀疏自编码器直接学习弱光照图像与其增强图像的映射关系,具有较好的增强效果。HUANG等人[14]在卷积神经网络的基础上提出一种改进的Unet模型来增强弱光照图像。KUANG等人[15]进一步利用生成对抗网络来抑制噪声,增强弱光照图像。CHENG等人[16]利用DFN (Deep Fusion Networks)融合弱光照图像的派生图像,如直方图均衡图像、对数变换图像、亮通道增强图像,从而有效实现图像增强。上述算法虽能利用神经网络估计增强图像,但并未在网络模型中注入视觉注意机制,使其有效注意到弱光照区域,并为其分配更多的计算资源,因此增强结果的精度及算法效率仍有进一步提升的空间。
考虑到视觉注意机制能使神经网络模型有效地关注到局部目标区域,进而大幅度提高目标检测的准确度。本文尝试将视觉注意机制引入到神经网络的图像增强算法中,提出了一个端到端的注意残差稠密神经网络。该网络包含注意循环网络和残差稠密网络两个部分。首先,注意循环网络需要生成一个光照注意图,这张光照注意图是整个网络最为关键的部分,它将引导注意循环网络聚焦于图像中的弱光照区域。然后,在光照注意图的引导下,利用网络的循环结构,联合输入图像,逐步学习到需要增强的弱光照区域。最后,由该注意网络逐步生成由粗到细,逐步优化的光照注意图。而光照注意图作为视觉注意机制的重要体现,与初始的弱光照图像进一步联合,作为第二部分稠密残差网络的输入。并以此引导稠密残差网络通过高维通道的卷积层和ReLU函数获取浅层特征,并将局部特征映射到一个相对“干净”的空间获取局部特征,进而将网络指向局部需增强光照的区域,使最终估计的增强图像具有黑暗区域得到有效增强,而明亮区域得到保留的自然视觉效果特征。
2 注意残差稠密网络的弱光照图像增强算法
2.1 算法思路
以人类视觉色彩感知角度出发的Retinex模型是图像增强算法选用的经典理论模型,它假设弱光照图像是反射率图像和光照图像的乘积:
IW=IR·IL,
(1)
式中:IW为初始弱光照图像;IL为光照图像,反应场景的光照情况;IR表示反射率图像即增强图像,反应图像的固有属性。为获取增强图像IR,我们提出了注意残差稠密网络。如图1所示,该方法是全自动的,包含两个子网络:注意循环网络和稠密残差网络。由于在图像增强过程中,我们无法预知哪些区域是需要增强光照的,因此,需要使用注意循环网络生成一个光照注意图来引导后续对图像的增强处理。而该光照注意图的生成则是注意循环网络的目的,同时也是注意循环网络中最为关键的部分。因为它将作为先验信息引导网络在下一次循环中关注到需要增强的弱光照区域,并与输入图像联合,作为网络下一次循环的输入。最终细化的光照注意图就是由最后一次循环得到的,并以此光照注意图联合输入图像作为稠密残差网络的输入,就能够使网络对弱光照图像进行增强处理时,为黑暗区域分配更多的资源使该区域得到增强,而明亮区域得到保留,产生更为自然、真实的结果。

图1 注意残差网络模型结构Fig.1 Architecture of attentive residual dense network
算法的基本思路:由光照注意图引导网络,将注意力集中在光照注意图所指示的需要增强光照的区域上,这个执行过程形成的网络就是注意循环网络。它在IL的引导下,通过多次循环逐步关注输入图像中的弱光照区域,并将弱光区域可视化,最终生成由粗到细,逐渐细化的光照注意图IA,产生的IA使得网络对图像中的弱光区域更加敏感。随后,IA进一步联合IW作为后续稠密残差网络的输入,以生成增强图像IR。这里IA由注意循环网络自动产生,每执行一次循环,IA对应的像素值改变一次,网络在上一次IA的引导下,联合初始图像,就能使网络更加聚焦于局部需要增强的弱光照区域,并为其分配更多计算资源,最终使稠密残差网络能更好地学习IW与IR的映射关系,生成没有过强或欠强区域的自然、真实的增强图像。
2.2 注意残差稠密网络
2.2.1注意循环网络
视觉注意模型已被成功用于目标检测与分类[17-18]。考虑到视觉注意模型中的注意机制能使神经网络注意到局部目标区域,本文创新性地将注意机制注入到图像增强的网络模型中。因为视觉注意可以让网络知道需要增强光照的重点应该放在哪里,这对生成视觉效果良好的增强图像来说非常重要,如图2所示。该网络使用循环结构来产生逐步聚焦的视觉注意映射,并将其可视化。每次循环,将当前的光照注意图与输入图像连接起来,作为下一次循环的输入,有助于我们进一步地从输入图像和逐步细化的光照注意图中提取特征,并引导网络将注意力集中在光照注意图所指示的区域上,得到逐步优化的光照注意图,有效实现图像增强。注意循环网络包含4个残差稠密模块(RDB, Residual Dense Block),1个LSTM循环单元及1个卷积层。每次循环时,残差稠密模块和LSTM循环单元从输入图像和上次循环产生的光照注意图中提取光照注意特征,随后利用卷积层产生此次循环的光照注意图。网络执行一次循环,就能使产生的光照注意图越来越多地集中关注到需要增强的弱光区域。
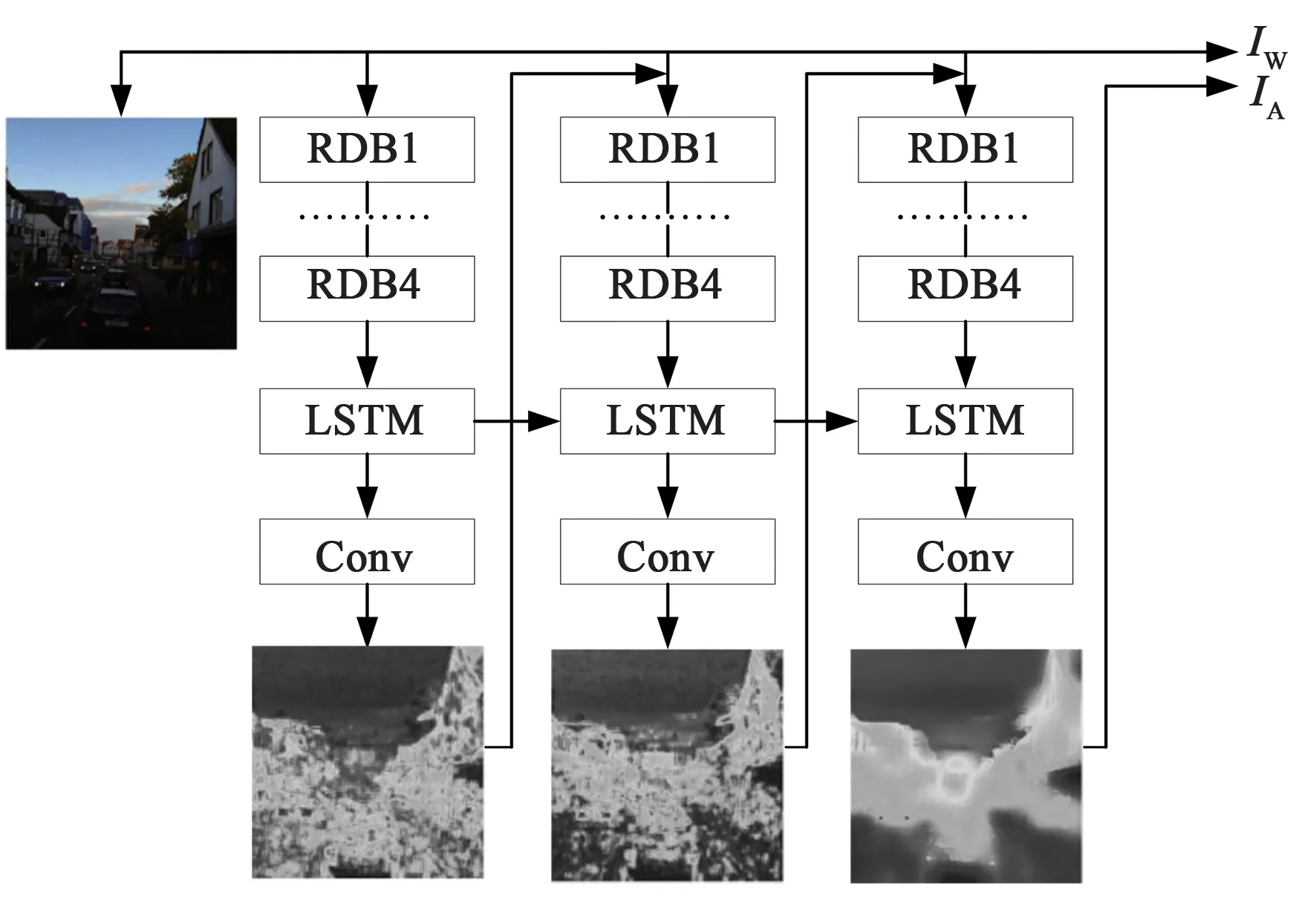
图2 注意循环网络结构Fig.2 Architecture of attentive recurrent network
注意循环网络中各步骤的函数定义如下:
(2)
式中:IAt-1为t-1次循环时注意循环网络产生的光照注意图。HRDB,1,HRDB,2,HRDB,3,HRDB,4分别为第1,2,3,4个残差稠密模块RDB的函数。Xt为t次循环时最后一个RDB模块输出的特征。
Ht,Ct=HLSTM(Xt,Ct-1),
(3)
式中:HLSTM为LSTM循环单元函数;Ht和Ht-1为t次循环和t-1次循环时LSTM的输出。
这里LSTM循环单元的结构如图3所示,它包含输入门N,遗忘门R,输出门O及记忆单元C,各门和记忆单元采用卷积操作来实现交互操作:
(4)
式中:Nt为Xt进入输入门后产生的特征,其中Wn和Bn分别为输入门卷积操作的权重和偏移;Rt为Xt进入遗忘门后产生的特征,Wr和Br分别为遗忘门卷积操作的权重和偏移;Ct为记忆单元中存储的信息,它由控制单元控制的信息Nt·(Wc*Xt+Bc)和遗忘门更新的信息Rt·Ct-1共同决定,这里Ct-1,Wc和Bc分别为t-1次循环时记忆单元中存储的信息,控制单元的卷积权重和偏移;Ot为Xt进入输出门产生的特征,其中Wo和Bo分别为输出门卷积操作的权重和偏移;Ht为LSTM循环单元的输出;tanh为激励函数;*1表示步长为1的卷积操作;·为点乘操作。

图3 LSTM循环单元结构Fig.3 Architecture of LSTM unit

(5)
式中:Wa是卷积操作权重;*1表示步长为1的卷积操作;Ba是偏差。
如图2所示,每次循环时,光照注意图将与输入图串联作为下次循环时网络的输入,并随着循环次数的增加,弱光照区域逐渐被关注,对应的像素值也逐渐增大,从而得到由粗到细,逐步优化的光照注意图。
2.2.2 残差稠密网络
当注意循环网络产生光照注意图IA后,IA串联弱光照图像IW共同作为残差稠密网络的输入,以生成增强图像。残差稠密网络模型如图4所示,主要包含:浅层特征提取,特征增强,全局特征融合,图像重建。

图4 残差稠密网络结构Fig.4 Residual dense network architecture
浅层特征提取:对于深度网络来说,浅层网络层能提取轮廓,边缘等低级特征,为深层网络层捕捉高级特征提供更多有效信息。为了更好地从IA和IW中提取值得注意的弱光照信息,有效地学习IW和IR之间的差异,这里采用一个高维通道数的卷积层Conv1和ReLU函数提取IW和IA中的浅层特征F0:
F0=σ(W0*2IW+B0),
(6)
式中:*2表示步长为2的卷积操作;W0是卷积操作的权重;B0是偏差;σ表示ReLU激活操作。通过该卷积操作,浅层特征图F0的尺寸变为输入图像的一半。
特征增强:由于弱光照图像易受到噪声的影响,局部光照特征提取较为困难,这里使用特征增强层捕捉局部光照特征,并进一步将其映射到一个相对“干净”的特征空间,以便提取全局特征。它利用浅层特征提取的F0作为输入,并由4个残差稠密模块RDB来实现特征映射。
F4=HRDB,4(F3)=
HRDB,4(HRDB,3(HRDB,2(HRDB,1(F0)))),
(7)
式中:HRDB,1,HRDB,2,HRDB,3,HRDB,4分别定义了第1,2,3,4个残差稠密模块RDB的函数;F3为函数HRDB,3的输出;F4为特征增强的输出。
全局特征融合:将特征增强层提取的信息非线性融合成全局特征,便于后续图像重建。为此,将各残差稠密模块RDB提取特征进行串联,作为全局特征融合层的输入,并用一个卷积层Conv2实现映射:
F5=σ(W2*1[F1,F2,F3,F4]+B2).
(8)
图像重建:最后采用上采样Upscale及卷积层Conv3将特征F5重建为与IW图像相同空间大小的增强图像IR:
IR=σ(W3*1F5↑+B3),
(9)
式中:F5↑为特征F5上采样的结果;*1表示步长为1的卷积操作;W3是卷积操作权重;B3是偏差。
2.2.3 残差稠密模块结构
残差稠密模块(Residual Dense block, RDB)作为网络的基本构建模块,将稠密网络和残差网络的优势相结合,能最大化网络的信息流,加速网络的收敛。RDB模块包括3个部分:稠密连接层,局部特征融合层以及局部残差学习。模块结构示意图如图5所示。
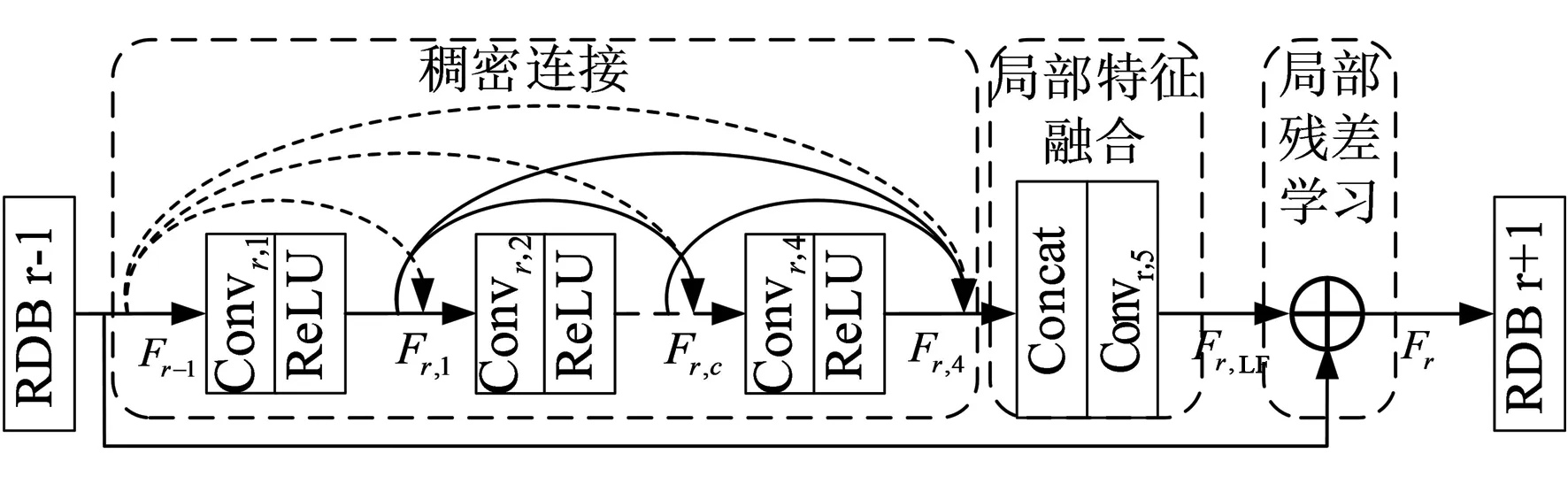
图5 残差稠密模块结构Fig.5 Residual dense module architecture
稠密连接:受稠密网络能加大信息流的启发,我们采用4组卷积层和ReLU激活函数共同组成稠密连接层。与传统稠密模块不同的是,此处的稠密连接将上一个RDB模块的输出传递到当前RDB模块的每一个稠密连接层中,如稠密连接层中的虚线所示,该设计能实现增强特征的连续传递。假设Fr-1和Fr分别为第r个残差稠密模块RDB的输入和输出,则稠密连接层中的第c个卷积和ReLU激活函数的输出定义为:
Fr,c=σ(Wr,c*1[Fr-1,Fr,1,…,Fr,c-1]+Br,c),
(10)
式中:[Fr-1,Fr,1,…,Fr,c-1]为第r-1个RDB的输出Fr-1,与当前r个RDB中前c-1个卷积层产生特征Fr-1,Fr,1,…,Fr,c-1的串联;Wr,c是稠密连接层中第c个卷积操作的权重;*1表示步长为1的卷积;Br,c是卷积对应的偏差。
局部特征融合:为了更好地融合前面各层提取的稠密信息,将稠密连接层各层的特征Fr,1,…,Fr,4与Fr-1共同作为卷积层的输入,得到局部特征融合后的信息Fr,LF:
Fr,LF=Wd,LF*1[Fr-1,Fr,1,…,Fr,4]+Bd,LF,
(11)
式中:[Fr-1,Fr,1,…,Fr,4]是串联特征;Wd,LF是当前r个RDB中局部特征融合层的卷积Convr,5的权重;*1是步长为1的卷积;Bd,LF是偏差。
局部残差学习:为了有效解决梯度退化问题,加速网络收敛,在模块的最后引入了局部残差学习操作:
Fr=Fr-1+Fr,LF.
(12)
2.2.4 损失函数

(13)

LD为注意残差稠密网络的损失函数,同样由网络输出的增强图像f(IW)与真实图像IR间的MSE定义:
LD=‖f(IW)-IR‖2,
(14)
式中:f表示注意残差稠密网络的映射函数。
3 实验结果分析
3.1 实验环境与参数设置
注意残差稠密神经网络模型在PyTorch平台上搭建,并在4*NIVIDIA RTX 2080 Ti GPU的计算机上训练。优化函数为ADAM(Adaptive Moment Estimation),初始学习率0.05,每100 000次迭代学习率下降50%,迭代800 000次。
注意循环网络中LSTM及卷积层的卷积操作核大小均为3×3,步长为1,边缘填补像素量为0。残差稠密网络及RDB参数如表1设置,除全局特征融合层和局部特征融合层的卷积操作核大小为1×1,边缘填补像素量为0外,其余卷积操作的核大小均为3×3,边缘填补像素量为0。其中,浅层特征提取层中卷积操作的步长为2,因此输入图像经过浅层特征提取层后,特征空间大小为输入图像大小的一半,而在图像重建层中采用双线性插值的上采样操作,进一步将特征大小复原为输入图像大小。

表1 残差稠密卷积神经网络及参数设置Tab.1 Parameters setting of attentive residual dense convolution neural network
3.2 数据集
本文首先从图像质量评估数据集[19-20]中选取600张正常光照图像,这些图像均采集于包含不同景物的真实场景,将其视为真实结果;然后,根据Retinex模型(公式(1))合成训练数据,让其光照分量IL的元素服从[0,1]的均匀分布,得到对应的弱光照图像数据集。
根据图像内容与照明条件相独立的假设,对每张正常光照图像,我们利用上述方法随机合成7张不同校正参数的弱光照图像。共合成4 200对图像,其中4 000对图像作为训练集,200对图像作为测试集。
3.3 注意残差稠密网络消融实验
为了验证网络中各模块的有效性,我们通过逐步添加模块的方法对结果进行了比较。测试集选用含200对弱光照图像及正常光照图像的图像对。其中室内、室外场景下整体光照偏弱图像及真实图像100对,光照不均匀图像及真实图像100对。保持每个模型训练过程中的超参数,所有网络训练40 000次,以达到收敛状态。
首先,将除去注意稠密网的网络模型作为主干网络。然后在主干网络中添加注意循环网络的1~4次循环,选择PSNR和SSIM作为指标衡量添加不同次数的循环网络对算法性能的影响。结果如表2所示,注意循环网络的加入可以显著提高图像的PSNR和SSIM,本文方法的性能优于其他结构。一方面说明注意网络的加入对提高图像质量、视觉特性和增强网络性能十分必要;另一方面也说明了并不是循环的次数越多越好。
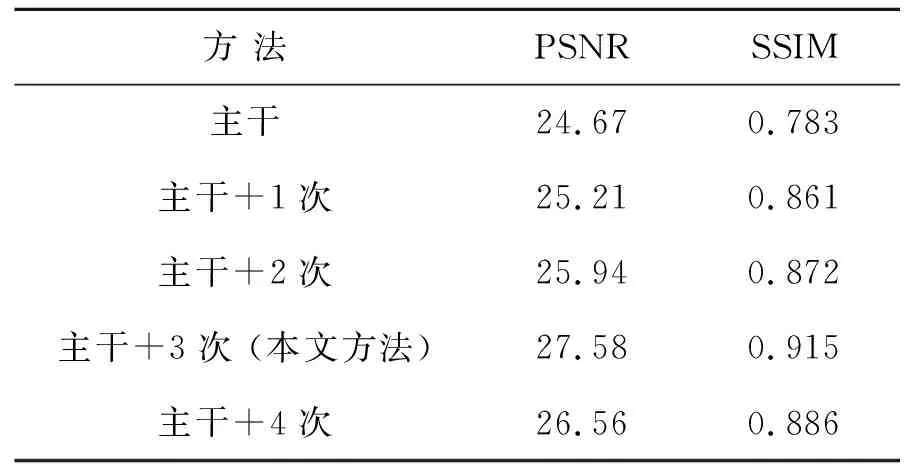
表2 不同模块的网络性能Tab.2 Performance of network with different block
3.4 注意残差稠密网络有效性和鲁棒性验证
为了验证本文增强算法的有效性和鲁棒性,选用经典的LIME算法[7],基于卷积神经网络的LORE算法[14]和DFN算法[18]及本文算法在200对弱光照图像及正常光照图像的测试集上进行测试。
图6为各算法的视觉增强结果,其中图6(a)从上到下分别为室外整体光照偏弱图像,室外光照不均匀图像和室内光照不均匀图像。图6(d)~图6(e)分别为LIME算法、LORE算法、DFN算法与本文算法的图像增强结果。图6(f)为真实结果。算法虽能提升图像亮度,但提升效果并不明显,图像整体亮度偏暗,细节信息清晰度低,如图6(b)中第一行的天空区域虽有增强,但豹子的斑纹信息仍不清晰。同样,图6(b)的第三行中书架区域亮度虽有增强,但书架上摆放的书籍杂物仍无法辨认。LORE算法的增强效果最为明显,颜色对比度高,但同时图像的平均亮度也最大,易出现过度增强及颜色失真的问题,如图6(c)第一行图像中天空区域颜色过亮,第二行图像的地面颜色失真。DFN算法增强图像的亮度介于LIME算法和LORE算法之间,但对弱光照的区域,其增强结果仍然偏暗,如图6(d)第二行图像的地面区域及第三行图像的书柜区域。本文算法因注入了视觉注意机制,增强效果较好,如图6(e)所示,增强结果不但亮度适中,颜色自然,还具有细节清晰的优点,与真实结果图6(f)最为接近。

图6 不同算法在合成弱光照图像上的视觉结果对比Fig.6 Visual comparisons of different algorithms on synthetic weakly illuminated images
我们进一步在测试集上测试各算法的性能,并采用均方误差MSE、信噪比PSNR和相似度SSIM三种量化指标衡量算法的增强效果,对应结果如3所示。

表3 不同算法在测试集上的量化结果对比Tab.3 Quantitative comparisons of different algorithms on testing dataset
由表3可见,在整体光照偏弱图像下,本文算法的均方误差MSE最低,较LIME、LORE和DFN算法分别降低了82.91%、50.91%和7.31%,PSNR和SSIM较LIME、LORE、DFN算法分别提高了46.37%、18.72%、16.34%和24.18%、6.59%、3.30%。在光照不均匀图像下,本文算法仍然具有最低的均方误差MSE,较LIME、LORE和DFN算法分别降低了82.38%、49.33%和4.67%,PSNR和SSIM较LIME、LORE、DFN算法分别提高了46.48%、19.34%、9.07%和26.09%、8.70%、3.26%。在处理时间上,各算法的处理时间均在1 s内,本文算法的平均处理时间仅为0.45 s,较LIME和LORE算法分别高0.54 s和0.32 s,仅比DFN算法慢0.11 s。综合来看,本文算法效率较高。
3.5 真实弱光照图像增强结果对比
为了进一步验证算法的稳健性,我们选取了多数增强算法常用的3幅真实弱光照图像进行测试。如图7所示,图7(a)为真实的弱光照图像,图7(b)~图7(e)为各算法的增强结果。整体而言,各算法在真实图像上的增强效果与合成图像上测试的效果趋于一致。LIME算法的增强结果整体偏暗,细节部分信息丢失,如图7(b)第一行中汽车的车及行人区域无法清楚辨识。图7(b)第二行和第三行的图像虽有亮度增强,但是颜色依旧偏暗,增强效果不明显。LORE算法的增强结果,图7(c)存在过度增强问题,颜色明显失真,如图7(c)第一行的公路区域颜色偏紫,天空中白云过亮,图7(c)第三行草地颜色偏黄,明显与真实场景颜色不符合,图7(c)第二行的草丛区域边界存在明显暗影,过增强现象明显。DFN算法的增强结果在局部区域颜色偏暗,如图7(d)第一行的公路区域及第三行的草地区域整体偏暗。相比而言,本文算法增强结果图7(e)的视觉效果最佳,对弱光照部分进行增强的同时,确保了正常光照部分亮度适中,颜色柔和,且细节部分也最为清晰。

图7 不同算法在真实弱光照图像上的视觉结果对比Fig.7 Visual comparison of different algorithms on real weakly illuminated images
此外,我们还从DICM[21]和NASA[22]等真实弱光照图像库中选取了30幅图像进行测试和客观评价。由于这类图像增强后没有真实结果作参考,因此我们选用客观评价指标,即信息熵、色度改变度、自然图像质量评估指标来量化增强结果。其中,信息熵用来量化图像中所含信息量的大小,其值越大图像所含的信息量越丰富,细节信息越完整。色度改变度反应了增强图像的色彩变化情况,值越小则颜色失真越少。自然图像质量评估指标是依据图像的自然统计特征来评价图像质量的指标,值越小则图像质量越高。表4列出了各算法在30幅真实弱光照图像上的平均量化值。从中可见,本文算法具有最大信息熵值,最低的色度改变度和自然图像质量评估值,其信息熵值分别较LIME、LORE、DFN算法提高了3.3%~5.1%,色度改变度和自然图像质量评估指标值分别降低了26.5%~76.3%和7%~17.4%。这表明该算法的增强结果不但含有最多的信息量,还具有最少的颜色失真,最佳的图像质量。
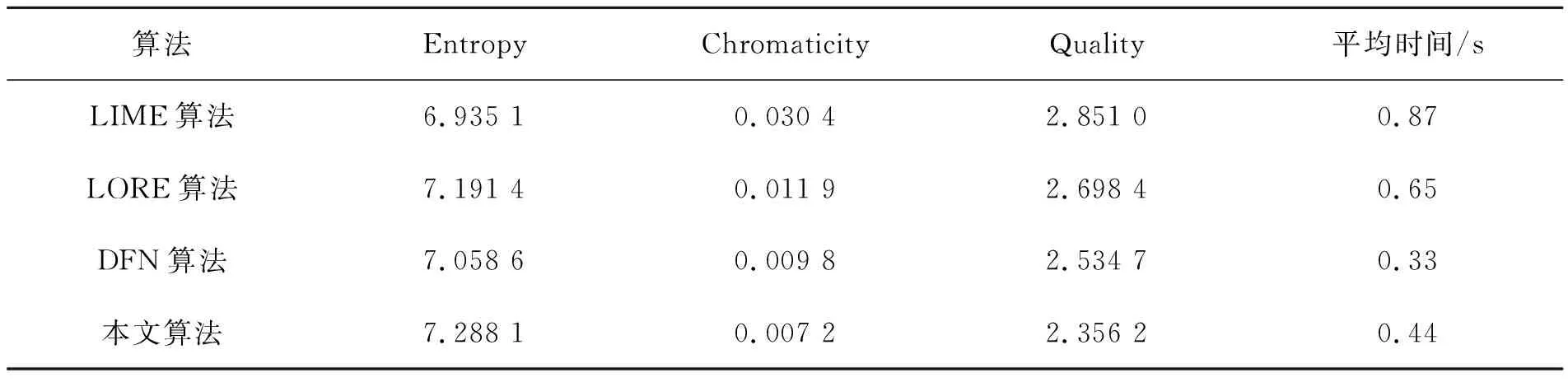
表4 不同算法在真实弱光照图像上的量化结果对比Tab.4 Quantitative comparisons of different algorithms on real weakly illuminated images
各算法的平均处理时间均在1 s内,本文算法较LIME和LORE算法在平均处理时间上分别提高了49.42%和32.31%,仅比DFN算法低25%,0.11 s。
4 结 论
本文将视觉注意机制注入到图像增强的神经网络中,提出了一个端到端的注意残差稠密网络。该网络包括注意循环网络和残差稠密网络。注意循环网络在真实光照图这个先验信息的引导下,利用循环网络结构产生由粗到细,逐渐优化的光照注意图。而这张优化的光照注意图则进一步联合输入的弱光照图作为后续残差稠密网络的输入,使得该网络能更好地关注到局部目标和弱光照区域,从而产生需增强光照区域得到增强,需保留光照区域得到保留的自然、视觉效果良好的增强图像。实验结果的量化指标均显示,本文算法在合成图像和真实图像上均较常用算法有更好的增强效果,没有过强或欠强区域,具有较好的视觉效果,并且处理效率较高。这也进一步说明将光照注意机制引入图像增强方法中是一种新颖且有效的弱光照图像增强方法。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
中国机械工程(2022年8期)2022-05-09
燃气涡轮试验与研究(2021年6期)2021-08-01
中国机械工程(2021年8期)2021-05-07
海洋信息技术与应用(2020年4期)2021-01-18
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
中国生物医学工程学报(2019年5期)2019-07-16
音乐教育与创作(2019年8期)2019-05-16
北京航空航天大学学报(2017年3期)2017-11-23
