
基于实例分割的目标三维位置估计方法
2021-11-12 00:47刘长吉郝志成杨锦程聂海涛
液晶与显示 2021年11期
刘长吉,郝志成*,杨锦程,朱 明,聂海涛
(1. 中国科学院 长春光学精密机械与物理研究所, 吉林 长春 130033;2. 中国科学院大学, 北京 100049;3. 重庆嘉陵华光光电科技有限公司, 重庆 400000)
1 引 言
基于点云数据的三维物体检测的难点在于深度感知设备价格高、高质量的稠密点云获取困难且运算规模大、点云数据集制作困难。经典点云分割算法例如LCCP[1]、区域生长[2]、RANSAC[3]等,效果较差,且速度慢。近些年已经有学者提出使用深度学习进行三维物体检测,如PointNet[4-5]、F-PointNet[6]等。其中F-PointNet提出使用基于二维检测器的三维物体检测,减少对点云的搜索空间。PointNet直接使用全部点云信息进行分割,达到了非常不错的效果。但是基于深度学习的三维物体检测都需要使用三维点云数据作为训练样本。而在实际的工程应用当中,很难获得大量的、高质量的点云数据作为训练样本。
在图像中存在丰富的目标信息,且二维图像训练集获取容易。如今成熟的二维检测算法,例如Yolo[7]、Faster R-CNN[8]等算法已经得到了广泛的应用,准确率高且速度快。经典的实例分割算法Mask R-CNN[9]其分割效果已经满足大部分的应用场景。因此本文提出了一种基于实例分割的三维目标位置估计方法,首先得到目标分割掩码,提取深度信息,由此获得目标粗略点云。再采用统计学异常点检测,对混入的极少量异常点进行剔除,最终得到精细的目标点云。
经过试验,该方法可以得到准确的目标物体点云,实现简单、成本低,无需任何点云数据作为训练样本。适合在目标点云提取、三维物体检测、障碍物检测等工程任务当中使用。
2 基于实例分割的目标粗略点云提取
2.1 基于Mask R-CNN的目标实例分割
目标检测(Object detection)需要获取图像中目标的位置(Bounding box),还需要获取物体的类别。实例分割(Instance segmentation)在目标检测的基础上,需要对每一个像素的分类,同时获得分割掩码,如图1所示。

图1 基于Mask R-CNN的实例分割结果Fig.1 Instance segmentation result based on Mask R-CNN
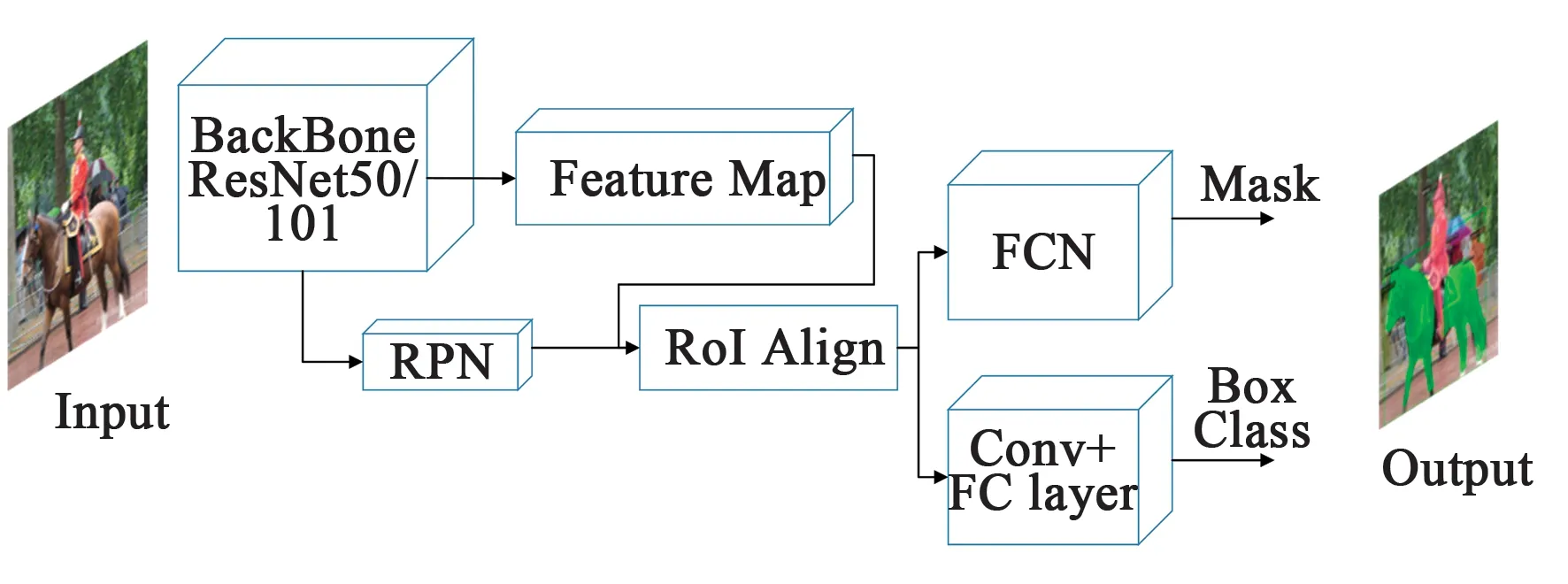
图2 Mask R-CNN网络结构Fig.2 Structure of Mask R-CNN
Mask R-CNN是一种通用图像实例分割算法,其沿用了Faster R-CNN[10]的思想,并且在Faster R-CNN的结构上增加了全卷积网络进行掩码预测[11],并将感兴趣区域池化(ROI pooling)替换成感兴趣区域对齐(RoI Align),使特征图与原图更加准确地对准,在区域推荐的过程中,减少了量化而损失的像素偏移,使得掩码更加准确。最后通过增加全卷积网络对推荐区域进行语义分割。不管是实例分割或者语义分割,由于其最后一层的分割掩码特征图一般为16倍下采样,直接上采样到目标尺寸大小会造成分割边缘的不准确。在2.2中我们会描述分割边缘不准确对点云分割造成的影响。Mask R-CNN网络结构如图2所示。
2.2 RGB图像与深度图融合
使用成熟的二维检测器在RGB图像中对目标进行实例分割,得到目标掩码和类别。不论是使用双目相机TOF相机或者是相机与雷达融合,都可以获得RGB图像与深度信息。如图3所示。

图3 深度图像Fig.3 RGB image and depth image
本文使用深度图来表示深度信息,深度图与RGB图像尺寸一致,每一个像素上储存的是与其对应RGB图像每一个像素的距离,使用单通道无符号16位整形(Uint16)来保存深度信息,单位取mm,如图4所示。

图4 使用分割掩码得到的RGB信息与深度信息Fig.4 Mask,RGB and depth from instance segmentation.
根据相机成像模型,物体投影在像平面上生成图像,此时从世界坐标系转换到像素坐标系,当拥有深度信息时,可从像素坐标系转化到相机坐标系。相机成像模型可简化为图5。
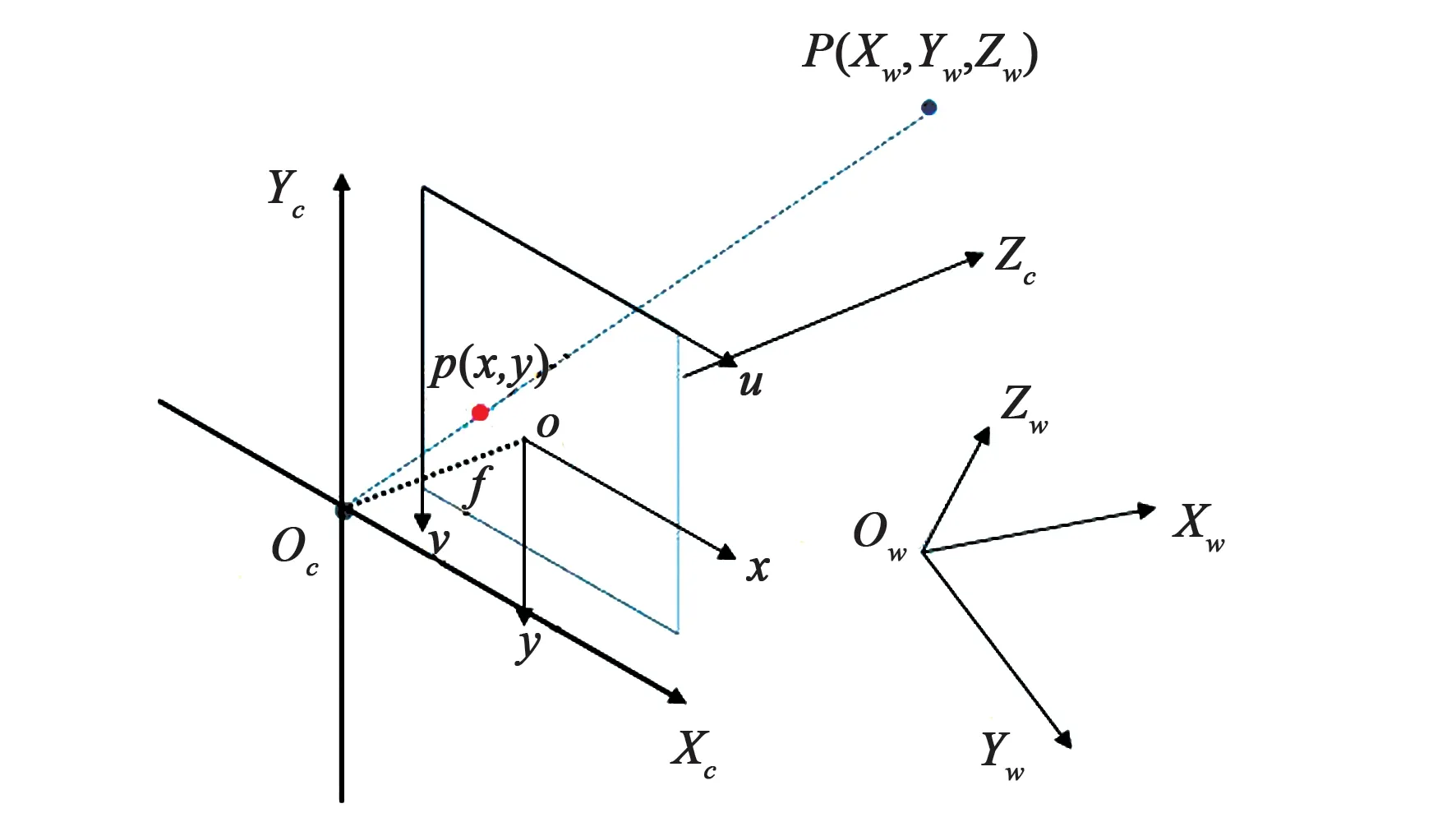
图5 简单相机成像模型Fig.5 Simple camera model
空间中一点可以分别在世界坐标系OwXwYwZw,相机坐标系OcXcYcZc,图像坐标系o-x-y,与像素坐标系u-v中描述。世界坐标系中一点P转化到像素坐标系的过程如下:
从世界坐标系到相机坐标系:
(1)
其中:R为旋转矩阵,T为平移矩阵。
从相机坐标系到理想图像坐标系:
(2)
其中:fx、fy为焦距。
假设像素坐标系原点在图像坐标系下的坐标为(u0,v0),每个像素点在图像坐标系x轴、y轴方向的尺寸为dx、dy,且像点在实际图像坐标系下的坐标为(x,y),于是可得到像点在像素坐标系下的坐标为:
从实际图像坐标系到像素坐标系:
(3)
式(4)被称为内参矩阵:
(4)
根据式(1)、(2)、(3)、(4)可以得到图像坐标系到相机坐标系的转换公式:
(5)
其中depth为深度图中储存的深度信息,根据式(5)可以将RGB图像与深度图像融合得到点云数据,其点云效果如图6所示。
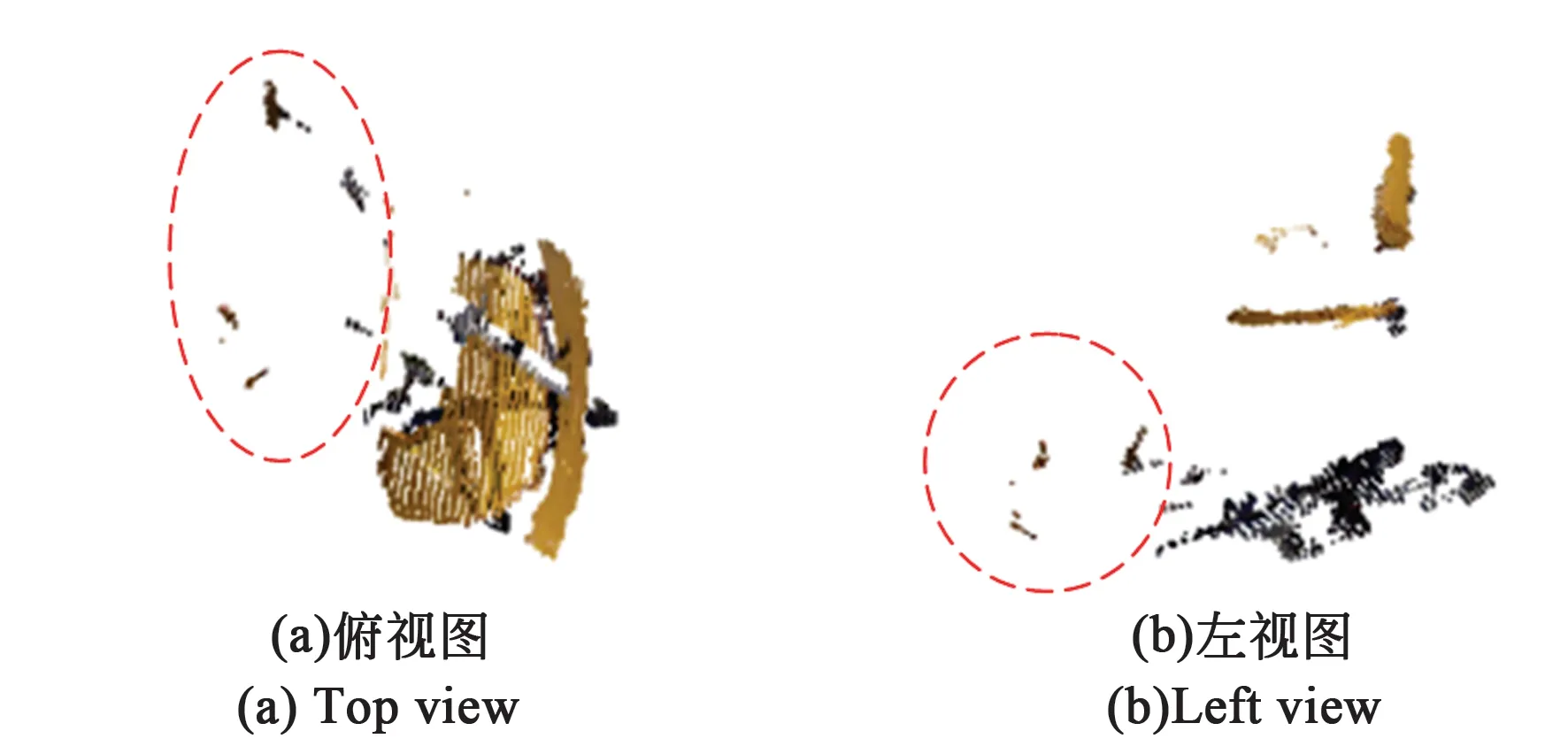
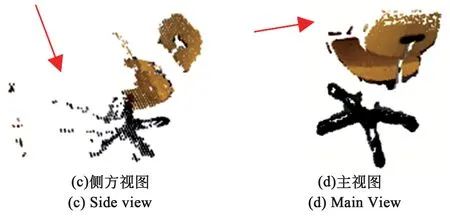
图6 不同视角下椅子点云中混入的非目标点云[12]Fig.6 Outliner point cloud in different view

图7 分割边缘不准确性Fig.7 Segmentation edge inaccuracy
由于分割边缘不准确性[13],如图7所示,导致得到的分割掩码中混入背景,从而造成点云中混入一定量的异常点。异常点云一般都与实际目标有一定距离,这些非目标点云会严重影响物体位置的判断,有必要将非目标点云进行去除。
3 点云主成分提取
3.1 自适应统计学异常点检测
由于每个目标形状差异不同,仅使用图像分割获取到的点云区别也很大,有些异常点云占比很大,有些异常点云占比很少,甚至有些规则形状的目标不存在异常点云的混入。异常点云有以下特点:(a)异常存在性未知,即是否存在异常点云;(b)异常占比未知性,即不同情况不同目标,基于图像分割得到的点云中,异常点云占比是不确定的;(c)异常分布未知性,即异常点云所处的位置是不确定、异常点云簇数量也不确定,可能存在多个点云数量较少的点云簇[14],分布在不同的位置。
由于以上3点特性,使得异常点的判断变得十分困难,并且由于异常占比未知性,使得异常点云的去除需要手动设置异常率的占比,这在同一场景多目标的情况下是不可用的。图8所示为在复杂室外场景下,不同目标混入的异常点云分布。

(a) 室外分割掩码与深度图(a) Outdoor segmentation mask and depth map

(b) 汽车分割掩码与粗略点云(异常占比少)(b) Car segmentation mask and coarse point cloud (few abnormal points)

(c)自行车分割掩码与粗略点云(异常占比多)(c) Bicycle segmentation mask and coarse point cloud(more anomalous point clouds)图8 不同目标混入的异常点云分布Fig.8 Distribution of abnormal point clouds blended in different objects
所以我们需要一种可以不指定异常占比、依赖点云形态分布来提取目标点云的算法。通过观察我们发现,异常点云与真实目标点云的分布存在明显不同,最明显的是数量与密度的不同。
统计学异常点移除(Statistical Outlier detect,SOD)[15]是一种无监督学习方法,可以应用在数据异常数据检测、工业产品检测等领域。该算法有以下特点:(a)无需指定异常点占比; (b)无监督学习,无需训练样本。适用于连续数据的异常检测,检测分布稀疏且离密度高的群体较远的点、容易被孤立的离群点。
已有检测数据集X={x1,x2,x3…xn},∀xi∈X,且xi由m维度的特征构成,xi={xi1,xi2,xi3…,xim}。在点云数据中,只保存位置信息,则m=3,则xi={x,y,z}。对每个点,我们计算它到所有k个临近点的平均距离。得到所有点的平均距离向量D={d1,d2,d3…dn}。假设得到的结果是一个高斯分布,其形状由均值μ和标准差s决定。当某一点的平均距离di>n·s+μ时,可被定义为离群点并可从数据集中去除掉。算法具体流程如表1所示。

表1 异常点去除算法流程表Tab.1 Outlier removal algorithm
3.2 k与n的选取
k值代表计算一个其最临近k个点,其中k值的大小决定了SOD对异常点的敏感程度。k越小,SOD对局部特征越敏感。对于目标来说,异常点占比通常很小,也会出现局部聚集的情况,所以k不宜取过小的数。一般对于一个目标来说,假设其点云数量为a,令k=a/t,其中t代表将整个目标当做t个部分来考虑。我们使用t来控制SOD对整体与局部敏感度。
在计算k近邻平均距离后,每个点会形成新的映射关系,异常点会被映射到离散区域,如图9所示。SOD去除异常点效果如图10所示。最终
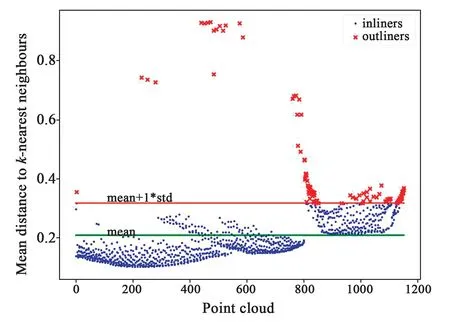
图9 t=3,n=1时,点云k临近距离统计。Fig.9 Point cloud k proximity statistics at t=3, n=1.
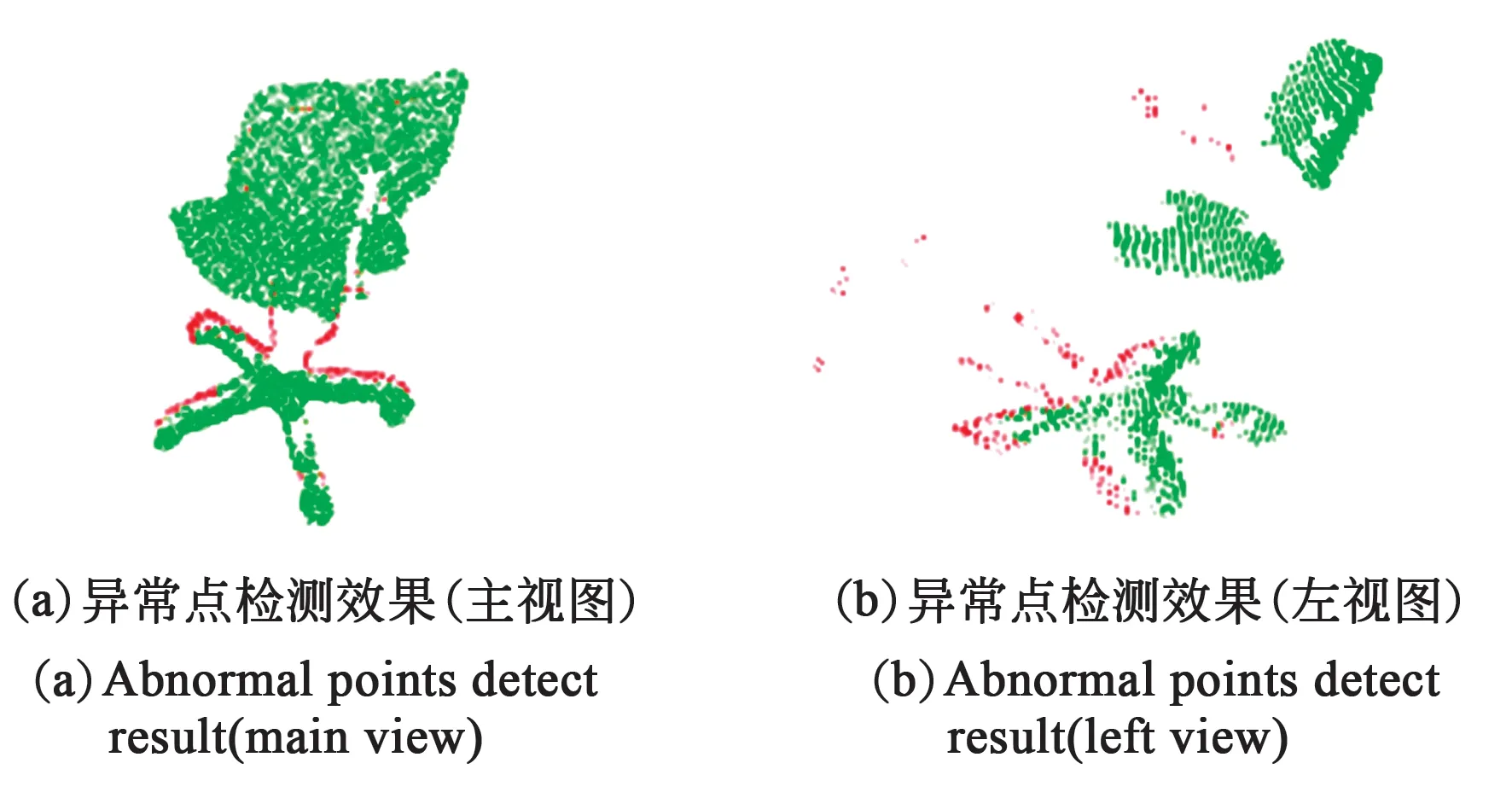

图10 自适应SOD去除异常点云,红色点被判定为异常点。Fig.10 Adaptive SOD removes the abnormal point cloud, and the red points are determined as abnormal points.
将异常点进行移除,得到目标精细点云,同时获得了目标的准确的空间位置信息。
4 实验结果与分析
实验分别使用了TUM数据集[16]与KITTI数据集[17-18]。TUM数据集由尼黑工业大学的Computer Vision Lab制作。采集设备使用Kinect,主要针对室内的办公室场景,于是使用飞行时间法(TOF),点云较为稠密。KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。该数据集用于评测立体图像(Stereo)、光流(Optical flow)、视觉测距(Visual odometry)、3D物体检测(Object detection)和3D跟踪(Tracking)等计算机视觉技术在车载环境下的性能。3D物体检测包含7 481张训练图片和其对应的点云。由于KITTI-3D object数据集中物体只有三维框与二维框标注,并无实例分割标注,所以我们使用了COCO作为训练集。COCO中包含类别人与车,并使用KITTI训练集作为验证集进行性能评估。
3D目标检测需要同时实现目标定位和目标识别两项任务。通过比较预测框与真值框之间的交并比(Intersection over Union,IOU)来计算重叠程度。通过置信分数和IOU来确定检测结果的性能,最终使用单类别平均精度值(Average precision, AP)来评估单类目标检测的结果如图11所示。其中2D边界框的性能也使用AP来衡量,IOU阈值使用KITTI标准。由于算法机制不同,我们估算物体位置使用了最小外包立方体,而远处目标的点云数量稀少且只有物体表面被激光雷达捕捉到,所以在远处物体的3D预测边界框会比真值3D边界框小很多,所以随着IOU增加AP会降低,如表2所示。在表3中,我们对比了不同算法在KITTI上的AP得分,经比较,我们的算法可以只使用2D数据集进行训练,在AP得分上,与主流的算法比较有一定差距。在测量精度上,当前主流的深度感知设备激光雷达Velodyne HDL-64E误差<2 cm,深度相机RealsenseD435i在<4 m的距离下误差不超过2%。
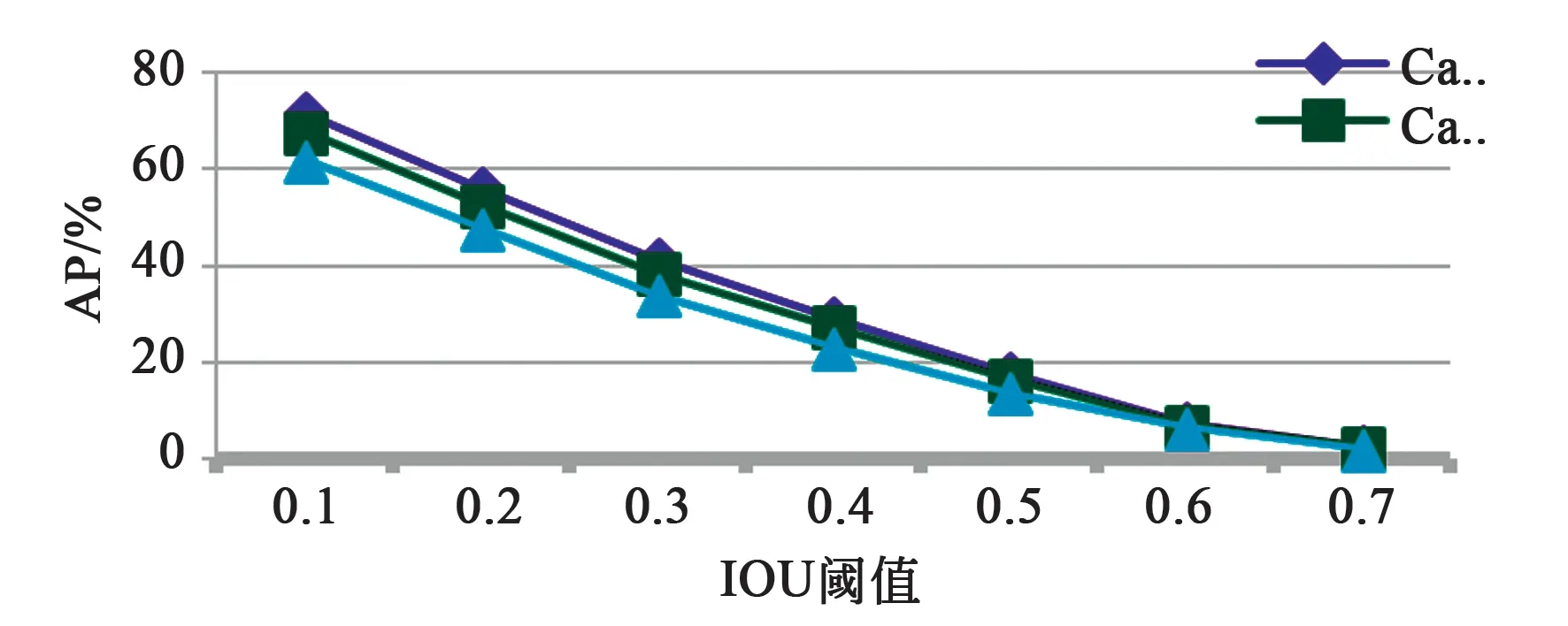
图11 不同IOU阈值下的车辆AP值(3D)Fig.11 Car AP at different IOU thresholds (3D)

表2 不同IOU阈值下的KITTI数据集上的APTab.2 AP on KITTI dataset with different IOU threshold (%)
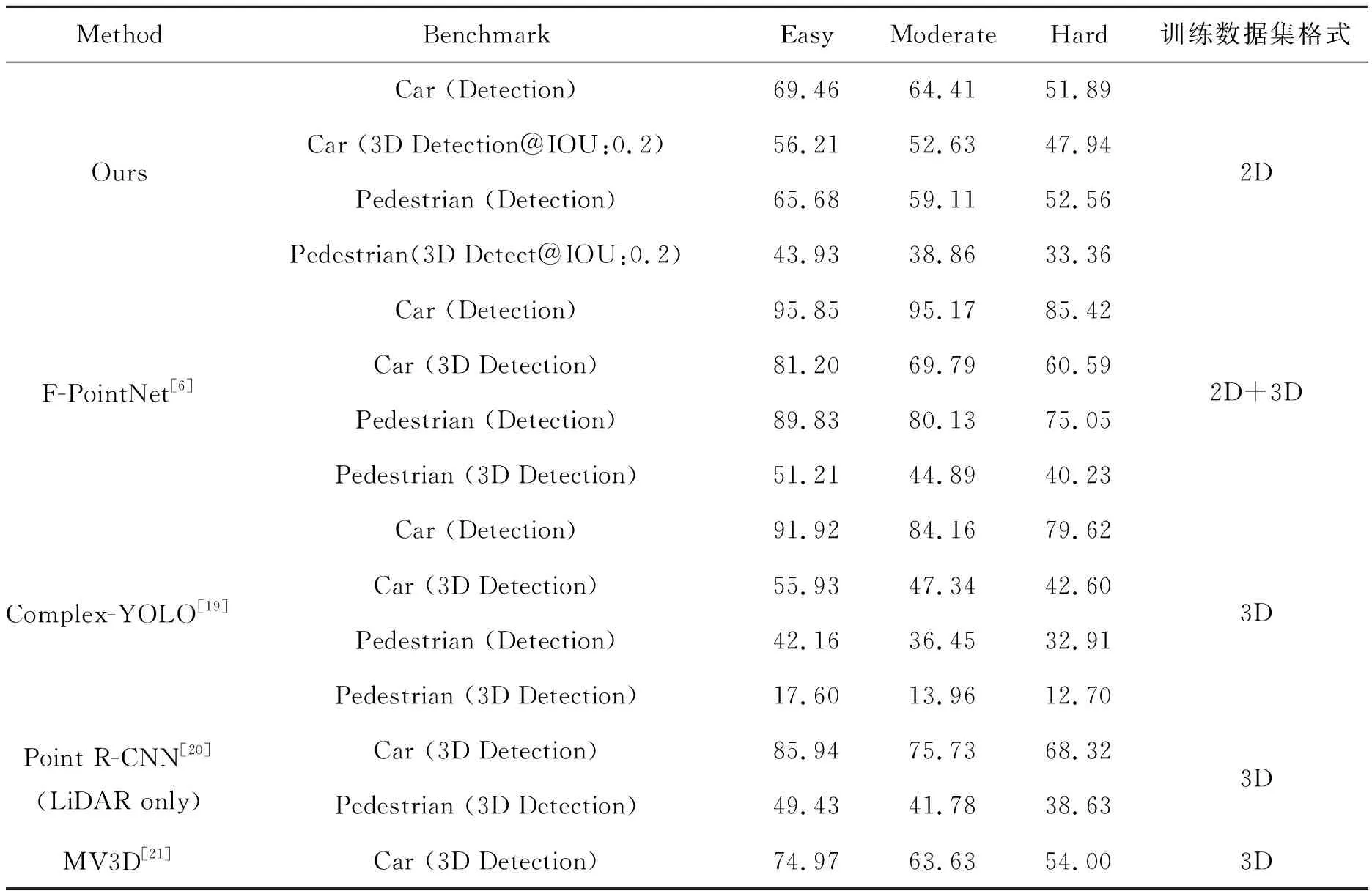
表3 在KITTI数据集上的性能对比Tab.3 Performance comparison on KITTI dataset (%)

图12 在KITTI上的检测结果与真值对比Fig.12 Detection results vs. ground truth on KITTI

图13 TUM数据集上的检测结果Fig.13 Results of TUM dataset
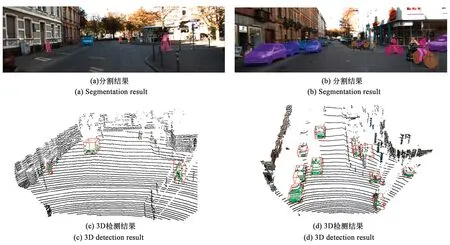
图.14 KITTI数据集上的检测结果Fig.14 Detection results of KITTI dataset
5 结 论
使用二维检测器驱动的三维物体检测可以得到非常好的效果,经过试验,在KITTI数据集上的AP可以达到50%以上。以Mask R-CNN作为检测器,在2080 Ti上可以达到15 FPS。
对于远距离、重叠、复杂的目标来说,点云已经无法分辨其轮廓形状,二维检测器可以提供一个强有力的前端策略,来获取目标的点云。同时,本文使用了无监督学习来对异常点云进行检测,整个算法不需要任何的三维数据作为训练样本,轻量化,更加易于部署应用于各个环境。其中轻量化体现在硬件轻量化与训练集轻量化。硬件轻量化是指以图像为主,对点云质量要求不高,可以降低硬件成本。训练集轻量化是指仅使用了二维数据集,相比三维点云数据集,容易获取容易标注。
对于二维驱动的三维物体检测来说,其前端可以搭载强大的二维检测器以达到更多功能的拓展。比如骨架识别、人体姿态识别、全景分割等。并且目前主流的三维目标检测方法都使用了RGB数据与点云数据的多模态融合,这也是三维物体检测的发展趋势。RGB提供丰富的语义信息,而点云数据提供准确的位置、轮廓信息。多模态的融合可以优势互补,但网络也会变得复杂,也更难应用于实时处理当中。
猜你喜欢
通信学报(2019年5期)2019-06-11
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
数学大世界(2018年1期)2018-04-12
通信技术(2018年3期)2018-03-21
中等数学(2017年2期)2017-06-01
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28
