
基于知识图谱的舰船信息分析识别技术研究∗
2021-11-11 14:22薛亮周游
舰船电子工程 2021年10期
薛亮 周游
(中国人民解放军91977部队 北京100000)
1 引言
在军事活动中,全面、准确掌握信息,并对信息进行准确快速的分析非常重要。本文基于舰船知识图谱,采用知识图谱技术实现舰船信息分析识别。知识图谱技术作为新兴的信息识别分析技术,有助于用户快速准确获得知识。
根据面向的知识领域不同,基于知识图谱的信息分析识别系统分为面向开放领域的信息分析识别系统[1~3]和面向特定领域的信息分析识别系统。面向特定领域的信息分析识别系统拥有更加深入和准确的领域知识,适用于特定领域的问题,相较于普适性的面向开放领域的信息分析识别系统更具有研究意义和实用性。本文将舰船领域作为所研究的特定领域,基于舰船知识图谱,对信息分析识别技术[4]进行研究,实现自动化军事信息系统,帮助舰员快速获取舰船相关信息。信息识别分析常用的方法有基于语义解析的方法(Semantic Pars⁃ing-based methods)[5~9]和基于信息检索的方法(In⁃formation retrieve-based methods)[10~14],当前主流的处理方法是将过程分为命名实体识别、属性映射和答案选择三个步骤。命名实体识别找出自然语句中的命名实体,属性映射找到问句询问的属性,答案选择结合前两步的结果查询知识图谱获得问句答案。命名实体识别和属性映射的结果决定了答案选择的结果,故提高命名实体识别和属性映射准确率是知识库问答的主要研究点。
命名实体识别问题的经典模型为CRF模型,属性映射问题可以转化为相似度计算问题,经典模型为Siamese网络,本文为这两个经典模型分别引入BERT[15]+Bi-LSTM[16]机制,以期对两个模型的正确率有所提高,进而提升信息识别分析系统的效果。
2 模型设计
本文主要对信息识别分析系统的命名实体识别和属性映射模型进行研究,以下对这两个模型进行介绍。
2.1 命名实体识别模型
信息识别分析的命名实体识别任务是指将自然语言问句中的主要命名实体识别出来,以作为在知识库中进行搜索的实体。实体识别任务往往被转化为序列标注任务。中文自然语言处理的基本单位一般是经过分词后的中文词语或者汉字字符。为了避免分词结果对后续结果产生影响,本文不对问句进行分词处理,直接将汉字字符作为输入。
命名实体识别任务是指对于中文句子X={x1,x2,…,xt},训练一个模型,由该模型判断X中每个中文字符对应的标签,得到标签序列Y={y1,y2,…,yt}。
命名实体识别任务的经典模型是CRF模型,本文在经典模型的基础上引入BERT+Bi-LSTM机制,对其进行改进。具体模型如图1所示,由BERT特征表示层、Bi-LSTM层和CRF层组成。

图1 命名实体识别模型
特征表示层使用BERT模型在大规模语料上进行预训练,得到汉字在多维空间的映射。Bi-LSTM层利用本身的优势,捕获语句的上下文信息,为字向量加入更多信息。CRF层对序列进行标注,利用相邻标签之间的影响,在句子程度上最优化句子中每个字的标签。
对于预测的标签序列y={ y1,y2,…,yt},CRF模型对其进行评分。评分依据是Bi-LSTM层的输出和标签间的状态转移概率。评分函数为

其中,矩阵P取决于Bi-LSTM层的输出,矩阵A是由标签间的状态转移概率组成的矩阵,Ai,j代表标签i转移到标签j的概率。
输入为x时的正确标签序列y的条件概率用softmax函数计算:

其中,yx是对应输入x的所有可能的标签序列组合。
模型训练时,优化函数采用最大化似然函数:
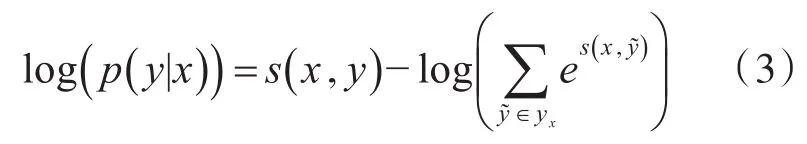
模型在预测最优标签序列采用Viterbi算法:

2.2 属性映射模型
信息识别分析的属性映射任务是指从候选属性集中选取出与不包含命名实体的问句匹配度最高的属性。属性映射任务最主要的问题是自然语言与属性之间的语义鸿沟。如何找到与自然语言最匹配的属性是该任务的关键。目前的主流解决方法是计算问句和属性之间的相似度。这种解决方法使属性映射任务最核心的研究内容转变成问句和属性的向量表征和向量之间的相似度计算。
向量相似度计算问题较为有效的模型是Sia⁃mese网络。本文在此模型上添加BERT、Bi-LSTM,以期使问句和属性的向量表征更加准确,包含更多语义信息。具体模型如图2所示,由BERT特征表示层、Bi-LSTM层和CRF层组成。

图2 属性映射模型
候选属性集由问句中实体相关的所有属性组成,对应问句中询问的内容,与命名实体无关,因此在对问句做特征表示时不包含命名实体部分。BERT表征和Bi-LSTM编码过程与命名实体识别模型类似,不做赘述。相似度计算的输入为经过BERT和Bi-LSTM处理后得到的问句语义向量和属性语义向量,对二者进行余弦相似度计算,衡量其相似度。余弦相似度计算公式如下:
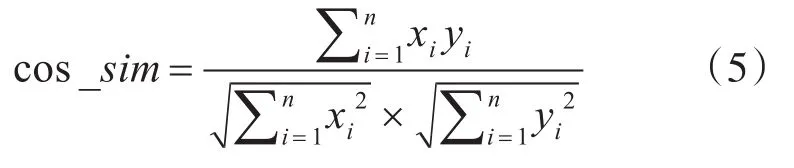
3 实验与分析
3.1 实验数据
实验选用舰船领域知识图谱作为知识库,其中包含219个实体,34个属性以及4501个三元组。知识库三元组的形式为<实体,属性,属性值>。图3展示了舰船领域知识图谱的部分数据。
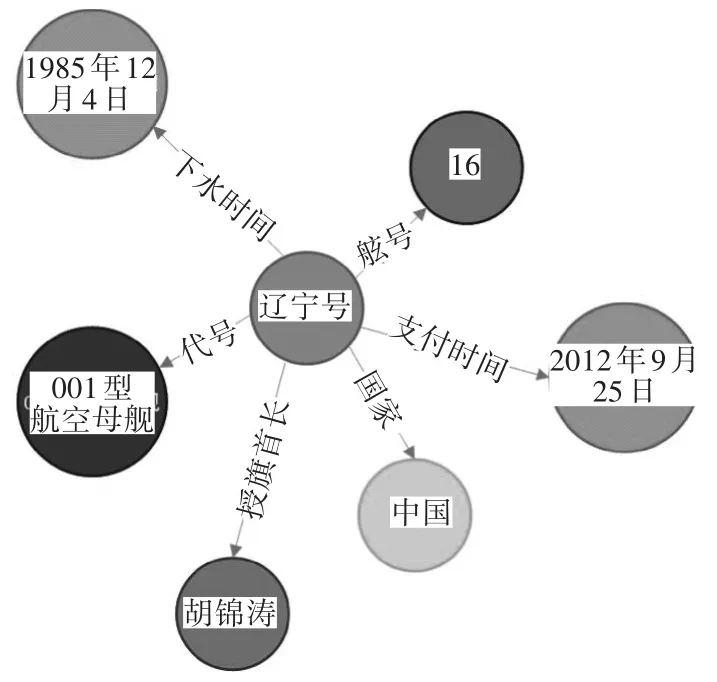
图3 局部舰船知识图谱
将每个三元组改写成一个问句,其头实体为问句中的命名实体,属性为问句的属性,尾实体为问题的答案。对问题进行BIO实体标注。完成实体标注的问句作为命名实体识别的实验数据。在实体识别数据集上,将问句中标注为命名实体的部分删除,即可得到问句的属性。将去除掉命名实体的问句作为属性映射的实验数据。以9∶1的比例将问句分为训练集和测试集。
3.2 评价指标
本文选取命名实体识别和属性映射部分得分最高的候选项作为预测结果。对某一个特定问题,预测一个命名实体和一个属性,进而通过在知识库中查询命名实体和属性得到问题的唯一答案。模型是否有效,取决于模型得到的答案与问题实际答案是否相符。若相符,则模型预测正确,否则预测不正确。因此,对于本文模型的效果评估采用准确率作为指标。命名实体识别、属性映射和最终答案预测都有各自的准确率。根据这三个准确率可以完成对模型的评估。准确率计算公式为

3.3 对比模型
命名实体识别对比模型如下。
1)CNN+CRF:Collobert等[14]提出的模型,该模型采用CNN获取语义信息,CRF进行标签预测。
2)Bi-LSTM+CRF:Lample等[15]提出的模型,该模型基于Bi-LSTM和CRF完成实体识别任务。
3)Bi-LSTM+CNN:Chiu等[16]提出的模型,该将字符级别的特征和词级别的特征通过CNN结合,然后基于结合后的特征,运用双向LSTM进行命名实体识别。
4)CNN+CNN+LSTM:Shen等[17]提出的模型,该模型对字符和单词进行卷积编码,对编码后的特征利用LSTM进行标签解码。
5)BERT+Bi-LSTM+CRF:本文提出的模型,本模型基于BERT预训练字向量进行文本向量表征,利用Bi-LSTM和CRF进行命名实体识别。
属性映射对比模型如下:
1)Word2Vec+Bi-LSTM:使用Word2Vec模型训练词向量,使用Bi-LSTM获取文本高级特征。
2)Siamese+Word2Vec+Bi-LSTM:使用Word2Vec模型训练词向量,使用Bi-LSTM获取文本高级特征,使用Siamese结构获取特征相似性。
3)BERT+Bi-LSTM:使用BERT训练字向量,使用Bi-LSTM获取文本高级特征。
4)Siamese+BERT+Bi-LSTM:本文采用的模型,使用BERT训练字向量,使用Bi-LSTM获取文本高级特征,使用Siamese结构获取特征相似性。
3.4 实验结果与分析
实验结果如表1、表2所示。

表1 命名实体识别准确率
本文提出的命名实体识别模型在训练集和测试集上分别取得了91.58%和90.24%的准确率,优于其他对比模型;属性映射模型在训练集和测试集上分别取得了89.65%和87.36%的成绩,同样优于其他对比模型。由对比试验结果可知,对自然语言进行向量表征时引入BERT和Bi-LSTN有利于获取更多语义信息,更好地构建多维向量。
信息分析识别系统最终在命名实体识别和属性映射的基础上进行答案选择。将命名实体识别的结果作为头实体,属性映射的结果作为属性,查询知识图谱得到尾实体,将尾实体作为问句的最终答案。将尾实体与标准答案进行对比,得到正确率为78.93%。最终答案选择的准确率远低于命名实体识别和属性映射各自的准确率,原因是前两步的结果共同决定了最终答案,需要两步均得到正确结果的最终结果才是正确的,错误累加会使准确率进一步降低。
4 结语
本文对基于舰船知识图谱的舰船信息分析识别技术进行了研究,提出了基于BERT+Bi-LSTM+CRF的命名实体识别技术和基于Siamese+BERT+Bi-LSTM的属性映射技术的信息分析识别模型。在舰船领域知识图谱上进行的仿真实验表明,本文提出的模型可以达到较高的准确率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
华人时刊(2020年21期)2021-01-14
健康体检与管理(2021年10期)2021-01-03
新城乡(2018年6期)2018-07-09
东方女性(2018年3期)2018-04-16
中国诗歌(2017年12期)2017-11-15
