
基于模糊运算的非结构化数据特征挖掘模型
2021-11-10 05:27:26陈彬王志英甘莹唐良运
电子设计工程 2021年21期
陈彬,王志英,甘莹,唐良运
(1.中国南方电网有限责任公司,广东广州510663;2.南方电网数字电网研究院有限公司,广东广州511455)
随着信息化技术水平的飞速发展,非结构化数据管理已经成为目前至关重要的研究内容。互联网平台也逐渐成为人们社会生活发展中的关键组成部分,随着各行业信息技术的不断创新,也逐渐涌现诸多新型数据,提出更高标准的非结构数据管理需求。基于本次研究的非结构化数据,需建立特征挖掘模型,传统数据关系模型作为模式滞后式逻辑结构,是一种基于代数关系基础形成的数据管理方法,不再能有效地处理非结构化数据。非结构化数据还拥有海量特点,所以为了能够更好地解决非结构化数据管理这一问题,在以往文献研究中提出了多种方案,譬如基于关系数据库的非结构化数据管理、列存储管理、Bigtable、数据空间技术等。在梳理汇总以往研究成果基础之上,从全新研究角度对非结构化数据管理问题进行观察分析,引入模糊运算建立非结构化数据特征挖掘模型,展开深入探索。
1 非结构数据分析
非结构化数据具有多样化,譬如常见的网页、音频、文本等相关数据,以及各企业的内部管理文档以及生物、地理和天气等相关复杂多样性数据。通过运用数据对象针对性地描述具体数据,定义每类集合内元素为数据对象,在一个物理或逻辑层面,都可以有效地区分其他数据区域的实体,其存在数据对象粒度情况,即一个数据对象作为更大数据的组成部分或包括更多数据对象。一般情况下都需要寻找适当粒度,对数据集合内的独立数据对象进行划分,所以在一般研究中也假定了其呈现数据对象的非结构化数据方式。
2 模糊运算的非结构化数据建模
为了方便表述,定义非结构化特征如下。
定义1:为了表达某数据集或某类数据共同拥有的特征共性,根据应用者的使用需求进行定义,也可以根据数据自身所表现的特性,以特征需求完成定义。
定义2:假设G的超模糊运算为“0”,那么∀a,b∈G,存在了唯一y∈G,想要满足(aob)(y)>θ,证:由于(aob)(y)=R(a,b,y),假设∃y,y1∈G,使R(a,b,y)>θ,那么可得:
∀a,b∈G,∃y,y1∈G,R(a,b,y)>θ,并且R(a,b,y)>θ,y=y1,所以存在唯一y∈G,使(aob)(y)>θ。
定义3:数据特征。数据特征作为形式化抽象性描述数据的定义,代表了数据所具备的特征意义和具体的取值特征空间域存在的主要度量关系,假若一个数据对象拥有多个特征,要让该数据对象拥有该特征类型,则需要满足以下条件:
1)通过既定依据方法,能够完成数据对象抽取,成为所属特征对象的特征数据;
2)完成特征数据抽取,与数据对象的代表意义及特征类型相符;
3)这类特征数据属于对应数据特征的取值范围。
对于这一特征值域的具体要求是无论任何特征区域均为值域,而且需要设定度量空间,满足值域空间的特征。
以模糊算法模型代码为例:

3 非结构化数据管理系统架构
在完成建模基础上,建立基于模糊运算的非结构化数据特征挖掘系统架构,如图1所示。该模型架构共计包括3 类数据库,分别为原始数据库、特征数据库、索引库。系统对于若干个数据对象处理类型库进行维护,每一个数据对象与其对应特征,也与处理类相对应,能够完成特征抽象、索引及查询。
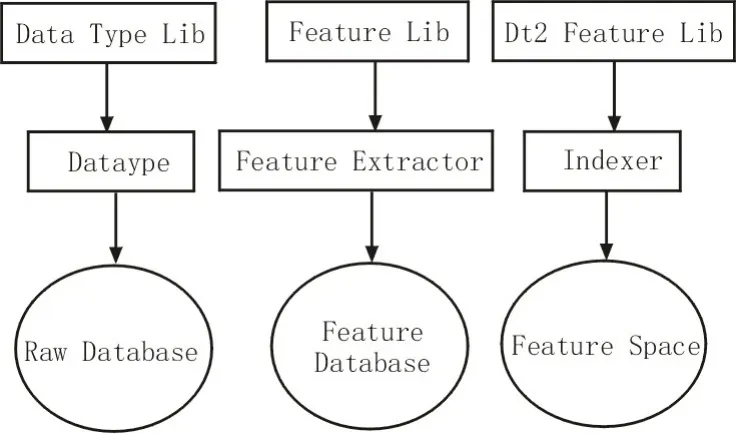
图1 非结构化数据特征挖掘系统架构
3.1 系统功能类库
在系统功能类库中,又包括了数据类型库、特征库。其中,数据类型库能够对数据类型和相对应的特征数据类型加以梳理,而特征库则包括了具备对应特征和特征类型的处理类,如表1所示。

表1 数据类型与处理类
对于数据类型处理类的系统特性操作接口,每类成功定义的数据类型与处理类相对应,那么该类数据处理类型在本次系统中所规定相应的数据处理接口,能够成功完成相应的数据类型操作。并且还可以实现用户接口自定义,采用特定操作处理相应的操作数据类型。
特征类型库与数据类型库相比,拥有更加复杂的类库,主要接口包括以下几类,如表2所示。

表2 特征类型处理类
一是对于抽取数据特征接口,在使用中接口面向特征类型,通过运用差异化提取数据特征的方法,能够抽取等同抽样特征,运用该接口也能够更方便地管理无关的数据特征类型;
二是数据特征索引接口,在系统中索引库的存在必不可少,作为系统核心技术需要以原本的数据特征类型为依据,完成数据信息存储,并参照原本数据特征,组织统一特征的数据对象。作为广义层面的索引,能够根据原本特征索引特征数据对象;
三是查询接口,在对非结构化数据进行查询检索的过程中,复杂化的非结构数据所采用的查询策略通常存在较大差异。但是查询这种抽象行为本身是不同的,图2为两个类型关系库的对比关系。

图2 两类类型关系库对比
3.2 数据存储
数据存储部分包括三大组成:
1)原始数据,任何存储于原始系统中的指定数据对象,能够组成原始数据库;
2)特征数据,该数据库与原始数据的数据库相对应,且各类特征数据对象也同样对应,并包括相应的数据特征信息。每类数据特征也主要由特征名称和数据两类组成;
3)索引库,特征空间所对应的特殊数据库,在每类特征维度相对应的空间特征对象都作为统一数据库,能够提供具体特征索引和相应的查询结果。
3.3 处理引擎
在数据特征挖掘处理中,系统类库负责非结构化数据管理,主要面向系统管理员、普通用户这两类用户。系统管理员对于引擎定义及特征类数据安装、定义,处理并添加新型数据处理类。对于普通用户,具体实现的引擎功能如图3所示。

图3 处理引擎功能结构
由图3可知,该引擎可以成功完成非结构数据对象的实时接收,并且可以对数据类型进行自主制定分析;根据具体的数据对象相应类型,能够成功抽取相关特征,并建立每类数据特征对象,并在对应数据库中充分存储;在特征空间中存储特征数据,能够构建特征索引;完成用户操作中查询请求的实时接收,一般情况下是在查询特征基础之上完成查询请求的实时接收,并对应完成特征查询;对于高级用户数据查询计算需求,在处理过程中应当完成自定义数据类型、特征类型。
4 系统实现
4.1 原始数据存储
通过Hadoop 系统存储原始数据,该系统作为分布式开放系统,对普通PC 端的分布式计算处理比较适用,且能够在运用过程中有较好的拓展性与容错性,解决了非结构化较大数据量的相关问题。
4.2 特征数据存储
一个数据共计包含多类特征,通过实现以上特征能够共同组成相应的特征对象,主要用于对某类特征数据对象的特征信息描述,如图4所示。

图4 特征结构表示
通常情况的特征数据类型,包括了浮点数、字符、整数、二进制数,所以运用Hadoop 系统能够完成数据特征对象存储,并存放于HDFS 中,依照具体数据存储方式,与数据存储特征正好相符,所以有利于模糊运算的非结构化数据特征挖掘应用。
5 结束语
经本次研究,以非结构化数据特征视角进行分析,建立了基于模糊运算的非结构化数据特征挖掘模型,能够提供非结构化数据管理的可行性思路,可以灵活方便地应用于非结构化数据管理。为灵活化处理非结构数据特征提供了可行性的数据处理思路。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09 11:33:52
汽车实用技术(2022年5期)2022-04-02 09:36:52
海洋信息技术与应用(2021年2期)2021-11-02 06:59:10
电子元器件与信息技术(2021年5期)2021-07-27 03:48:14
河北理科教学研究(2021年4期)2021-04-19 13:34:44
铁道通信信号(2020年4期)2020-09-21 09:15:24
计算机教育(2020年5期)2020-07-24 08:53:00
数码世界(2020年5期)2020-06-23 00:14:36
计算机工程(2015年8期)2015-07-03 12:20:35
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
