
基于次序依赖的智能配电网损坏数据自动修复模型构建
2021-11-10 05:27:16卢俊李朝瑞肖康戚永青邓奕星
电子设计工程 2021年21期
卢俊,李朝瑞,肖康,戚永青,邓奕星
(1.国网襄阳供电公司,湖北襄阳441002;2.国电华研电力科技有限公司,广东广州510000)
智能配电网已经实现了较高效率的远距离、优电压跨地域分配,是我国实现可持续发展战略的重要成果,智能电网面对广大用电用户的用电需求程度,需要将配电网的供电寿命与供电质量提升至最佳状态,与此同时,智能配电网在运行的过程中常常因数据量的庞大等因素产生损坏数据,为此,智能配电网损坏数据自动修复模型成为近年来的重要研究热点[1-2]。
传统基于配电网自动化的模型中应用ADN 技术对智能配电网系统进行实时状态的监控与在线控制,从配电网的电源处提升故障范围的阈值,保障一定区域内的智能配电网损坏数据自动诊断能力,及时向智能配电网的控制中心发送命令性信号;传统基于拓扑结构的模型中,应用信息协同技术对智能配电网损坏数据自动修复功能进行实现,主要采用信息微处理技术对智能配电网中单个设备保护数据库与以太网结构数据库进行信息获取领域的提升,为智能配电网的控制体系与集成化体系提供稳定的数据保障。
文中构建了基于次序依赖的智能配电网损坏数据自动模型,从次序依赖的角度进行算法模块与多代理模块的构建,使智能配电网损坏数据的修复在数据集方面建立基础优势。
1 自动修复算法构建
次序依赖程序能够进入智能配电网损坏数据的属性空间中,将损坏数据的空间距离进行属性方面的改变,再应用次序算法对智能配电网损坏数据的复杂度进行计算,同时需要保证损坏数据能够应用属性优先级别重新对自动修复模型进行定义,将时间序列方面的损坏数据集表现在数据集合中,利用配电网中的智能电表读数统计时间序列的单调递增规律,时间序列损坏数据示意图如图1所示。
图1 时间序列损坏数据示意图
在时间序列数据集合的基础上进行损坏数据的自动修复多项式算法,首先定义集合中的时间数据序列为i,满足次序依赖δ=[time]→[data]序列长度,并锁定损坏数据集合中的错误数据,次序依赖数据能够应用序列的整体长度进行迭代运算,数据中满足i序列长度的赋值需要进行完整性的维护,并满足递归层次的安全系数。假设损坏数据集合为db,当db中的损坏数据经过次序依赖的安全维护后,可以利用不同长度的组数进行数据修复,若i值为3,db 中的自动修复数据通过序列的组数示例如表1所示。

表1 自动修复数据通过序列的组数示例
次序列依赖自动修复数据需要在数据集合中进行定义寻找,满足在组数确定的状态下最长序列长度与依赖次序之间的维护参数条件,对表中的组数示例进行阈值比较,符合参数条件的有:
db[i]:5021<db[i]:6200
db[i]:5034<db[i]:6200
db[i]:5123<db[i]:6200
这些数据可以应用在长度不确定的次序依赖修复过程中,满足相应的输出条件后便可将损坏自动修复算法建立在动态模型的基础上,获取相应的移动数据方程如下:
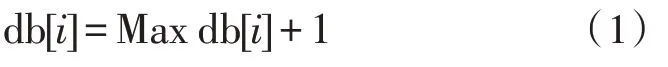
方程中的数据完成初始化计算后需要依次计算移动方程中的序列长度,得到损坏数据的集合与最长序列数据模式,采用较简单的数据方式维护智能配电网中的实时监测数据与已经产生的破坏数据层[3-5]。
在应用算法进行修复的过程中发现,不同算法的复杂度随着次序依赖的时序长度变化而变化,这种状态下的动态迭代过程会影响整体算法的配电网精准数据。设定n为智能配电网损坏数据中的迭代数据,为了使其满足次序依赖中的序列长度,将n置于序列的末尾,增加序列的整体规模,即n=db[len],若序列中末尾值等于n,则需要重新在动态规划结构中,应用二分法查找相应的n值与符合复杂度的次序依赖位置[6-7]。
2 自动修复模型
文中设计的基于次序依赖的智能配电网损坏数据自动修复模型主要应用于单元模块之间的数据通信技术,减少不同地区智能配电网损坏数据之间的误差精度,由于数据通信之间的信道延迟可以延缓数据恢复的时间,从而进一步减少故障所发生的控制结构空间。应用次序依赖算法还能够对全局化智能配电网损坏数据进行历史性的预测与提取,实时性地进行不同层次的数据优化与提取。基于次序依赖的分层数据采集优化结构如图2所示。
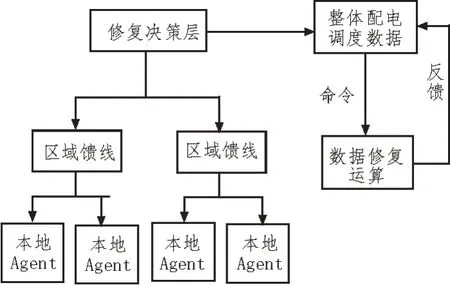
图2 基于次序依赖的分层数据采集优化结构
在智能配电网的通信通道中,需要依靠大量的故障数据作为故障恢复性算法的运算基础,将故障区域分散在相应的算法范围内。当配电网络中采用全局化损坏数据修复算法的过程中没有对全局化数据进行优化性处理,需要在控制中心的馈线上传输故障处理的协调性信号,使智能配电网中的电源分布在配电主动性上具有自我调整的能力。损坏数据自动修复模型的构建过程中需要使其能够对智能配电网内部数据进行实时监控、自我调整等,文中则应用全局化损坏数据优化结构将损坏数据进行修复性的过渡[8-9]。优化结构如图3所示。
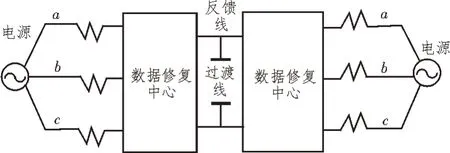
图3 全局性优化结构
智能配电网中产生大量的损坏数据是一项极小概率的事件,在智能配电网的损坏数据自动修复模块实现过程中需要充分考虑到智能配电网对外部环境的抵御情况,并对智能配电网的硬件设备进行数据方面的弹性分析,设损害数据的目标函数为:

式中,X代表目标函数中具有环境性损坏数据的约束强度,能够改善智能配电网中电压水平、电流水平等参数[10-11]。智能配电网中损坏数据自动修复可以对配电网中的支路进行目标函数方面的适应度测定,将故障数据中存在的配电网支路作为整体故障数据运算编码[12-13]。算法运行流程如图4所示。
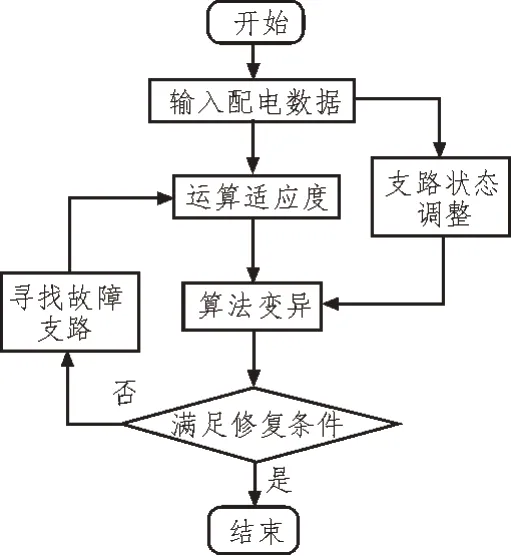
图4 算法运行流程
根据次序依赖的智能配电网损坏数据自动修复的仿真计算模型,可以得出智能配电网中损坏最多的数据类型为失去负荷性的环境灾害,当整个智能配电网中的负荷程度小于规定的阈值,则损坏数据自动修复模型不能够对单独的支路进行衡量修复[14-15]。在较大的负荷损坏程度中需要考虑到配电网中弹性功能的负荷损坏模拟状态,从智能配电网中建立辐射状态的配电网支路路径,应用用电客户端对智能配电网控制中心内的数据提取功能,分析故障数据所发生的支路位置以及损坏数据自动修复所进行的支路位置[16]。
3 实验与研究
在构建以上模型后,对构建的模型修复性能进行研究,并设置对比实验。将该文基于次序依赖的智能配电网损坏数据自动修复模型构建方法与传统智能配电网损坏数据自动修复模型构建方法进行对比,设置实验参数表如表2所示。

表2 实验参数表
根据上述实验参数表进行实验设置,对自动修复模型进行管理,并设置数学操作模型执行管理任务。将遗传算法与启示算法相结合,进行配电网重构操作,加强对重构系统的改良力度,不断调节不同机制内部的修复模型性能。集合一级联络开关,将开关状态调整至开合状态,连接相连的馈线,对比馈线连接方式进行集中式线体连接操作。转移模型中的电网负荷,将其负荷电量传输至电网的各个角落,并对配电网辐射状态进行研究,构建配电网辐射结构如图5所示。
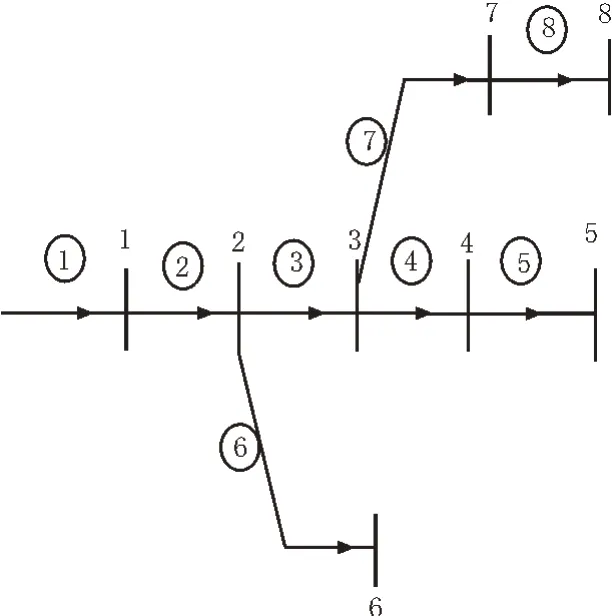
图5 配电网辐射结构
配置相应的电网信息流,将电网内部流量与损坏数据进行分支改造,逐层分析不同电网的空间状态,并对电网的修复状态进行修复模型整理,离散化整理模型内容,同时加大对内容的设置力度,分化设置空间,将设置模型空间内部的电网配电量进行整合。将整合后的数据进行记录,并构建记录存储空间,获取存储的结果数据,并构建修复完整度对比图,如图6所示。
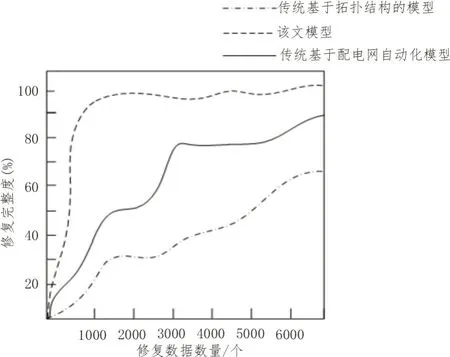
图6 修复完整度对比图
由图6可以看出,该文基于次序依赖的智能配电网损坏数据自动修复模型构建方法的修复完整度均高于其他两种传统智能配电网损坏数据自动修复模型构建方法。由于该文在模型构建的过程中分析了不同修复模型的修复性能,并调整了模型的结构模式,在优化模型配置的同时加强了对配电网系统的管理力度,逐渐增强管理的空间形式能力,在分配修复模型关系的过程中调整配电网中心的配电环节,并将调整后的数据输入到修复系统中,对比修复参数进行修复审核,获取相应的修复数据,利用修复数据间的关联性对比修复的损坏数据信息,及时管理损坏数据的内部关联程度,将关联程度信息与修复模型相联立,按照联立的综合数据进行基础性调节,实现对整体修复模型的构建,在一定程度上强化了修复模型内部的修复性能,转化修复信息,具有较高的修复能力,并完善了修复模型的完整性,因此,其修复完整程度较高。
在实现首次实验操作后,根据取得的实验结果进行二次实验研究,进而提升对该文模型构建方法性能的研究。选择相关程度较高的操作模型对修复模型进行数量调节,强化对调节后数据的整合力度。启动启发式规则,将规则程序录入管理系统中,同时加强对规则信息的管理,执行内部管控指令。加大对修复模型的分析力度,时刻强化修复模型的管理性能,同时对管理后的模型进行标记,将标记数据与系统数据相调配,整理出相应的调配系数,获取调配结果参数,并构建损坏数据收集精准度对比图,如图7所示。
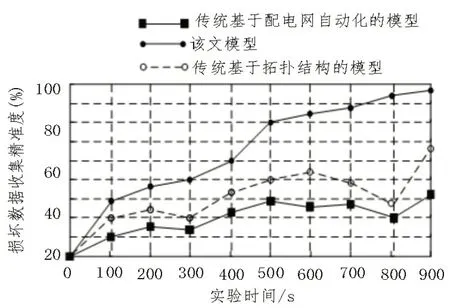
图7 损坏数据收集精准度对比图
从图7中可以看出,该文基于次序依赖的智能配电网损坏数据自动修复模型构建方法的损坏数据收集精准度均高于传统方法。造成此差异的主要原因在于该文模型构建方法针对不同的配电网损坏数据信息进行数据间的模式处理,强化对操作程度较低数据的集中处理力度,并时刻分配操作信息,在调整模型修复内容的同时匹配修复参数,进一步调节了损坏数据的录入机制,具有较强的数据收集能力。因此,提升整体模型的损坏数据收集精准度,为后续修复处理提供良好的数据基础。
4 结束语
文中基于次序依赖的智能配电网损坏数据自动修复模型构建方法具有较强的修复能力,在缩减修复时间的同时提升整体模型的修复效率,控制处于修复阶段的损坏数据信息,平衡配电网运行过程中产生的电流数据,具有较为良好的发展空间。
猜你喜欢
历史教学问题(2023年6期)2024-01-18 08:45:06
学生天地(2020年5期)2020-08-25 09:09:08
经济技术协作信息(2018年32期)2018-11-30 01:43:16
电子测试(2018年10期)2018-06-26 05:53:36
小天使·六年级语数英综合(2017年8期)2017-08-04 00:44:51
汽车博览(2016年9期)2016-10-18 13:05:41
电测与仪表(2016年5期)2016-04-22 01:14:14
河南电力(2016年5期)2016-02-06 02:11:24
交通建设与管理(2015年15期)2015-03-20 15:19:15
小天使·五年级语数英综合(2014年11期)2014-11-06 09:49:03
