
一种多尺度YOLOv3的道路场景目标检测算法
2021-11-10 11:39郁强,王宽,王海
江苏大学学报(自然科学版) 2021年6期
郁 强, 王 宽, 王 海
(1. 上海汽车集团股份有限公司商用车技术中心, 上海 200438; 2. 江苏大学 汽车与交通工程学院, 江苏 镇江 212013)
自动驾驶车辆目标检测场景具有检测场景复杂、目标边界框面积差异明显、检测难度高、实时性要求高等特点.因此直接将执行常规检测任务的神经网络检测模型移植到智能辅助驾驶计算平台上,往往会得到一个较差的结果.因此需要充分考虑自动驾驶车辆对道路多目标检测场景的实际需求,在现有检测模型的基础上设计符合自动驾驶车辆检测要求的道路多目标检测模型.
YOLO系列目标检测算法于2016 年提出.在 YOLOv3[1]提出前,已有的神经网络目标检测算法的思路都是先通过前景、背景判断提取 proposal 再进行分类和回归,也就是双阶段算法[2-4],这种方法检测精度较高,但实时性较差,不适用于对速度要求较高的场景.YOLO则是一种单阶段算法[5-7],它将目标检测问题转化为回归问题,直接在输出层回归出目标的Bounding box 的类别和位置,虽然检测精度相比于双阶段模型有所下降,但实时性好,有较强的工程价值,因此,被广泛运用于工程领域.YOLO 的检测过程主要分为3步:① 将输入图片调整成相同大小;② 对调整后的图片使用卷积神经网络提取特征并得到最终的 Bounding box 信息;③ 使用非极大值抑制算法(non-maximum suppression, NMS)对上一步生成的多个Bounding box 进行筛选,最终只保留最优的候选框.
为了平衡大、小目标的检测精度,充分发挥卷积神经网络的目标物体特征提取能力,提高目标检测网络在实际检测中的检测性能,笔者针对道路交通场景下多目标检测要求的特点,在YOLOv3算法的基础上,对特征融合模块进行重新设计,同时对检测模块进行改进,设计得到一种具有5个检测尺度的道路目标多尺度检测方法YOLOv3_5d.
1 YOLOv3模型简介
YOLOv3在YOLOv1和YOLOv2的基础上做了改进,是基于端到端的检测算法,网络结构分为骨干网络Darknet-53和检测网络,骨干网络Darknet-53是一个 53 层的卷积神经网络,其中加入了残差块,使网络的结构可以设置得更深,具有更强的特征提取能力;其次还采用了特征金字塔(FPN)[8]方式,提取多个不同尺度的特征图层(feature map) 分别进行检测,提高算法对不同大小目标的检测能力,并输出 13×13、26×26 和52×52共3种尺度的特征,送入检测网络.检测网络对3种尺度的特征回归,预测出多个预测框,并使用非极大抑制,保留最优的候选框.YOLOv3网络的检测流程如图1所示.
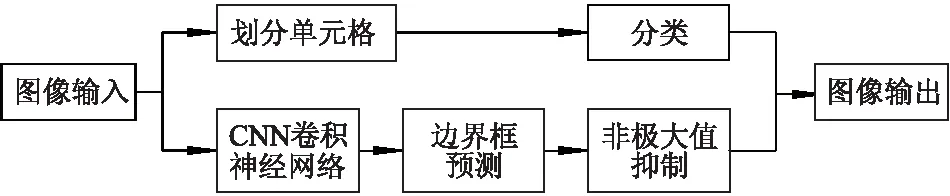
图1 YOLOv3网络的检测流程
2 改进的YOLOv3多尺度检测模型
YOLOv3目标检测网络设计的初衷在于提供一种适合大多数静态场景的二维目标检测模型,并非针对自然驾驶交通场景进行设计,没有考虑道路多目标检测的复杂性.尤其是没有对远景小目标的检测情况进行充分的考虑,导致YOLOv3目标检测网络在道路多目标检测场景中对小目标的检测效果较差.与工业检测、室内检测场景不同,现实道路交通环境中,常见目标物体(小汽车、公交车、行人、骑行者、交通信号灯、交通标志、卡车)的目标边框存在巨大的差异.现实中的一个典型道路多目标检测场景如图2所示.

图2 典型道路多目标检测场景
从图2可以看出:视野前方黑色车辆边界框和图片右方和上方交通标志的bbox面积相差大概90倍.需要指出的是,这种边界框大小差异明显的情况不止发生在不同目标种类之间,相同的目标种类也存在大量类似情形.当车辆目标位于远景时(如图2中路口对面的灰色车辆),bbox的面积相对于近景车辆的bbox面积大小差距同样明显.由于道路多目标检测场景的近、远景目标边界框面积差异巨大的特点,导致现有道路多目标检测网络不能满足自然驾驶交通目标检测对近、远景目标物体检测精度的要求,因此设计一种能够同时兼顾近景大目标与远景小目标的道路多目标检测模型是必要的.
在试验数据集BDD100K[9]中,YOLOv3目标检测网络模型标注边界框基于K-means算法[10]聚类训练集物体边界框标注信息后得到9个anchor,大小分别为(7,13)、(16,20)、(10,36)、(29,37)、(20,79)、(52,64)、(79,119)、(133,176)、(199,310).此时,anchor边界框和样本标注边界框的平均交并比(average intersection over union,AvgIOU)为65.20%.当anchor box 的数量为12和15个时,由K-means算法聚类得到的标注值和anchor boxAvgIOU及大小物体的占比如表1所示.
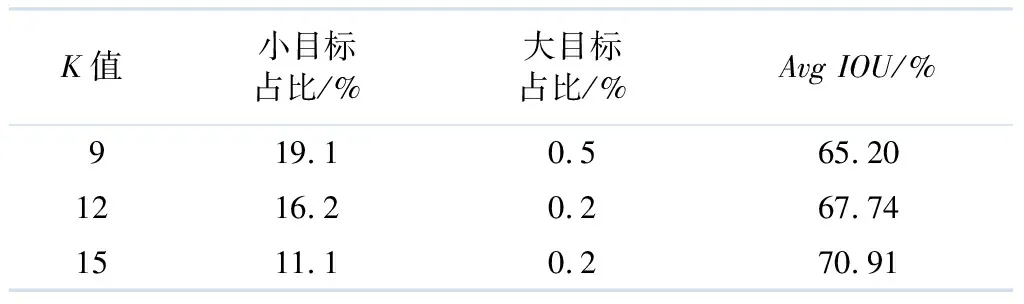
表1 聚类中心数与BDD数据集标注值交并比
表1中的小目标占比是以最大输出特征检测图最小anchor box的边界框大小为基准,训练数据集标注值边界框小于这个面积所占的比例;大目标占比是以最小输出特征检测图最大anchor box的边界框大小为基准,训练数据集标注值边界框大于这个面积所占的比例.从表1可以看出:随着K均值聚类的聚类种子点数量的增加,大、小目标在数据集中所占的比例均有所下降,而相应的AvgIOU逐渐增加.这说明随着K值的增加,anchor box覆盖标注边界框的IOU增大,意味着标注值目标边界框回归时的收敛速度会加快.
依据卷积神经网络在大尺度特征图上检测小目标效果好的特点,在YOLOv3原有的3个检测尺度的基础上,对特征融合部分和yolo检测层进行重新设计,增加了2个检测小目标的大尺度特征输出图,经过重新设计的道路多目标检测模型称为YOLOv3_5d,改进后的整体结构如图3所示.

图3 YOLOv3_5d整体结构
与原始YOLOv3网络结构相比较,为适应新增检测层导致所需的特征图的尺度变化,对特征融合网络进行重新设计,在原先3个浅层特征融合模块的基础上新增了2个特征融合模块.最初的3个检测图13×13、26×26、52×52与原始YOLOv3构架相同,添加的尺度为104×104的检测图是将网络第108层的输出52×52进行1次上采样,提升分辨率至104×104,接着添加特征融合层将第11层的特征图拼接到110层输出特征图的通道上,在特征融合后得到的特征图上初始生成3种不同尺度的锚点框,随后交替使用3×3、1×1的卷积操作映射得到104×104下的张量数据;尺度为208×208的检测图是将网络第120层的输出进行1次上采样,提升分辨率至208×208,接着添加特征融合层将第4层的特征图拼接到121层输出特征图的通道上,同样在特征融合后得到的特征图上初始生成3种不同尺度的锚点框,随后交替使用3×3、1×1的卷积操作映射得到208×208的张量数据.YOLOv3_5d网络结构在完成特征融合之后网络输出5个尺度的检测图,较YOLOv3增加了104×104和208×208,添加的2个尺度的检测图为小目标的检测提供重要特征,改进后的网络较YOLOv3在远景小目标的检测上考虑更加充分,同时又没有影响大目标的检测.
3 试 验
3.1 试验数据集和试验环境
使用的训练数据集为加州大学伯克利分校AI试验室发布的BDD100K数据集.BDD100K是目前为止规模最大、内容最具多样性的公开驾驶数据集,是目前自动驾驶领域最为通用的数据集之一.BDD100K数据集包含10万段高清视频,每个视频约40 s,分辨率为1 280×720,帧率为30帧·s-1.每个视频的第10 s对关键帧进行采样,得到10万张图片,并进行标注.其中7万张有标签图片划分为训练集,1万张有标签图片作为验证集.
BDD100K数据集类别存在不均衡的情况,数据集中Car有1 021 857个实例,而类别Train只有179个实例,这样训练集类间分布不均衡的情况在神经网络训练中对Car这种大数量的实例目标,网络的特征提取能力会增强,但是对小数量的实例目标,网络的特征提取能力会下降.同时由于道路多目标检测模型的构建目的为准确地检测自然驾驶场景中常见的目标物体.因此,从BDD100K中选取有标签的8×104个数据集并将Train的标注去除,组成6个类别(Traffic_light、Traffic_sign、Car、Bus、Truck、Person).并将其中的6×104个划分为训练集,2×104个划分为验证集.
试验平台为 Intel酷睿i7 8700k处理器,64 GB内存,操作系统为Ubuntu18.04,使用的运算显卡是 GTX1080Ti.
3.2 训练参数及结果
为了准确选择道路多目标检测网络最高精度所对应的权重,当平均损失函数不再下降时停止训练.
训练时设置超参如下:块大小为64 个;学习率为0.001;最大块尺寸为106个.
在YOLOv3训练过程中,YOLOv3目标检测算法训练中随着损失函数的逐渐平稳, 50%置信度条件下平均准确度均值mAP@0.5稳定在0.490 0左右.本试验取mAP@0.5最大值为0.498 9所对应的权重文件yolov3-bdd60k-92000.weights作为基于YOLOv3的道路多目标检测网络在BDD60K数据集上的最优权重.
在YOLOv3-5d训练过程中,由第2节所述关于BDD60K训练集预选anchors的尺寸选择的方法为K-means聚类算法.指定聚类中心数K值(K值为预选anchors的数量),经聚类算法聚类得到最终预选anchors的尺寸.但是因为K-means算法的聚类结果严重依赖初始聚类种子点的选择,同时预选anchors尺寸的选择影响最终检测网络检测效果的好坏.所以使用了改进的K-means聚类算法K-means++算法对K-means初始种子选择的缺点进行修正.K-means++算法的主要步骤如下:
1) 从数据集中随机选取1个样本作为初始聚类中心c1.
2) 计算每个样本与当前已有聚类中心之间的最短距离,此距离用D(x)表示.
3) 计算每个样本被选为下一个聚类中心的概率P,即
式中:X为所有可选的聚类中心点.
4) 按照轮盘法选择出下一个聚类中心,重复上述步骤直至选择出共K个聚类中心.
基于K-means++算法聚类BDD60K试验训练数据集物体边界框所得的15个anchors分别为 (5,13)、(10,11)、(11,20)、(9,35)、(24,18)、(19,30)、(16,62)、(33,42)、(52,61)、(30,110)、(73,93)、(69,207)、(112,128)、(158,215)、(217,348).15个anchors与数据集目标边界框标注值的AvgIOU为70.91%.
通过试验发现,mAP@0.5随着损失函数的逐渐收敛而逐渐增加,并最终在100 000次mAP@0.5稳定在0.580 0左右.因此试验取100 000次iterations所对应的权重文件yolov3_5d-bdd60k-100000.weights作为YOLOv3_5d的最优权重文件.
4 试验分析
4.1 不同场景下2种检测网络分析
YOLOv3道路目标检测网络训练最优权重yolov3_bdd60k_92000.weights和改进的道路目标多尺度检测算法YOLOv3_5d网络最优权重yolov3_5d_bdd60k_100000.weights在数据集BDD10K测试数据集6个目标种类及整体检测平均精度如表2所示.

表2 2个检测模型检测精度对比
从表2可以看出:与基于YOLOv3的道路目标检测算法在测试集中取得的最大mAP@0.5值为0.498 9对比,基于YOLOv3_5d的道路目标多尺度检测算法在测试集上mAP@0.5为0.580 9,检测精度增加0.082 0.
从检测模型改进前后各类别的mAP@0.5变化分析可以看出:YOLOv3_5d 对小目标的检测精度获得了较大提升,对于交通标志(Traffic_sign)、交通信号灯(Traffic_light)这2种自然驾驶交通检测场景中的典型小目标,分别取得了0.048 8和0.073 7精度提升;同时对于小汽车(Car)、行人(Person)这类可大可小(位于远景时较小,近景时较大)的检测目标,YOLOv3_5d同样获得了较好的表现,2类别分别获得了0.099 6和0.162 5的精度提升;对于公共汽车(Bus)、卡车(Truck)这类边界框较大,这种检测难度较大的目标,YOLOv3_5d的检测精度也分别有0.046 3和0.060 9的精度提升,这表示YOLOv3_5d可以在充分提升小目标检测精度的同时兼顾常见大目标的检测精度.
在具有标注信息的BDD100K测试集上选取2张典型交通场景下的图片,利用2个网络的最优权重进行检测,并将检测结果与实际标注信息进行对比分析.场景1和场景2下2种检测网络效果对比如图4所示. 图4a-c分别为场景1(路口,多实例小目标)目标物体的标注边界框信息、YOLOv3_5d检测出物体信息、YOLOv3_检出物体信息;图4d-f除了场景(雨天,小目标模糊检测)不同外,其余相同.不同场景下目标标注真值与2类检测算法检出情况具体如表3所示.

图4 场景1和场景2下2种检测网络效果对比

表3 场景1和场景2下YOLOv3和改进网络检测结果 个
由图4可以看出:十字路口这种自动驾驶交通检测场景的小目标较多,其中多为Traffic_light、Traffic_sign之类的目标.这种检测场一般比较考验检测网络的小目标检测能力.
从表3可以看出:对于Car、Person这类较为显著的检测对象,YOLOv3_5d和YOLOv3这2个检测网络均有较好的表现,都成功将所有的2类目标检测出;对于Traffic_light、Traffic_sign这类面积较小且不易检测的非显著性检测对象,2个网络的检测效果有明显的差距;对于场景1中的Traffic_light,标注真值共有8个实例,YOLOv3共检测出6个实例,漏检2个实例,而改进后的YOLOv3_5d检测网络共检测出7个实例,相较于YOLOv3成功地检测到了场景中路口右侧较难的Traffic_light实例,漏检1个实例;对Traffic_sign,YOLOv3共检测出4个实例,漏检2个实例,YOLOv3_5d检测出6实例,没有漏检;针对场景1,YOLOv3_5d检测网络要优于YOLOv3网络.
从图4场景2(雨天、小目标模糊检测)可以看出:由于天气(雨天)的原因,导致检测场景中部分目标模糊,在这种情况下,对于检测网络的鲁棒性具有较大的考验;除去模糊这种影响因素外,还出现了上文提到的远景小目标的情况.
从表3场景2的检测结果可以看出:针对模糊较严重且远景小目标实例较多的Car这类目标,改进的YOLOv3_5d检测网络成功地检测出了所有的实例,且位置回归,目标分类准确无误; YOLOv3检测网络漏检了2个Car实例,观察图4可知,漏检的2个目标均为Car的远景小目标实例.
由以上分析可以看出:对于异常天气导致检测难度加大的场景,改进的YOLOv3_5d检测网络鲁棒性要明显优于YOLOv3检测网络;对于远景小目标实例较多导致的检测困难,YOLOv3_5d检测网络的表现同样优于YOLOv3检测网络.
4.2 YOLOv3_5d与主流检测算法检测性能对比
表4为YOLOv3_5d检测网络与目前主流检测算法的检测性能对比,采用的测试数据集为BDD100K测试集,共有1万张图片.

表4 YOLOv3_5d与各检测算法在BDD100K测试集上的性能对比
从表4可以看出:以Faster RCNN为代表的二阶段检测算法在BDD100K测试集均有较好的检测精度,但是二阶段的检测算法往往不具备实时性,例如Faster RCNN的算法运行速度仅为10.7帧·s-1,不能满足自动驾驶感知系统对检测算法30.0 帧·s-1的实时性要求.
以SSD检测算法为一阶段目标检测算法的代表算法.从表4可以看出:SSD针对BDD100K测试集有着较为不错的速度表现,但是检测的准确度表现较差;YOLO系列检测算法在速度与精度2个方面均有较好的表现,本研究提出的YOLOv3_5d检测算法,检测精度达到0.580 9,同时,检测速度达到了45.4帧·s-1.虽然检测速度较YOLOv3有小幅度下降,但是一般认为,在满足自动驾驶检测实时性的情况下,精度的提升更为重要.
综上,YOLOv3_5d道路目标多尺度检测算法在BDD100K测试集上的表现最优.
5 结 论
针对现有自动驾驶交通目标检测算法存在的大、小目标检测不平衡的问题,在现有实时目标检测算法YOLOv3的基础上,对YOLOv3目标检测算法的特征融合模块进行重新设计,并对检测模块进行改进,设计得到一种新的具有5个检测尺度的道路目标多尺度实时检测算法YOLOv3_5d.并将改进前后的检测算法分别用BDD100K数据集进行训练测试,最终测试结果表明:改进后的YOLOv3_5d在检测精度上有提升,相比于原始YOLOv3,mAP@0.5增加了近0.082 0,到达了0.580 9,检测精度较高;其次通过程序统计检测每张图片的时间对算法运行速度进行统计,检测速度达到了45.4 帧·s-1,提出的基于YOLOv3神经网络的道路多目标检测方法可以满足实时性的要求.各类别检测结果表明YOLOv3_5d检测算法有效提升了交通检测场景目标的检测精度.
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
太空探索(2016年5期)2016-07-12
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
时代英语·高三(2014年5期)2014-08-26
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
雕塑(2000年2期)2000-06-22
