
一种基于并行FCN的室内视觉定位算法
2021-11-10 07:08辛喜福罗博文
西安邮电大学学报 2021年4期
孙 健,于 浩,辛喜福,罗博文,闫 婷
(1.吉林吉大通信设计院股份有限公司 铁塔分院,吉林 长春 130012;2.吉林吉大通信设计院股份有限公司 政企分院,吉林 长春 130012;3. 中国电信股份有限公司长春分公司 智慧家庭运营中心,吉林 长春 130000)
室内定位作为一种定位技术的发展方向,主要针对室内场景提供定位服务,如室内定位系统可以部署应用于商场、会议中心或其他由于卫星信号受到遮挡导致卫星定位系统无法正常工作的环境中。该系统能够弥补卫星定位方法覆盖受限导致室内应用不足的问题。因此,近年来,室内定位方法已逐渐成为定位领域内研究的热点。
在目前研究的室内定位实现方法中,文献[1-3]将惯性导航系统(Inertial Navigation System,INS)和无线传感器网络(Wireless Sensors Network,WSN)相互结合,通过传感器间的数据融合算法提高导航系统的室内定位精度。同时,定位和映射(Simultaneous Localization and Mapping,SLAM)算法[4-5]是一种与室内惯导系统原理完全不同的室内定位方法,其利用激光雷达扫描周围区域建立基于距离与角度的极坐标测量数据库,并以此为基础构造实时更新的“室内地图”。除此以外,Wi-Fi[6]、超宽带(Ultra Wide Band,UWB)脉冲信号[7]和蓝牙[8]也是较为常见的室内定位解决方案。但是,上述室内定位方法一般需要放置特殊的辅助设备,或在系统布置完成前的量测工作量过大,因此,一般仅能应用于工业厂区或尚停留于实验室测试阶段。
近年来,随着深度学习技术的突破,人工智能领域加速崛起,计算机视觉技术发展迅速。受到视觉识别算法的启发,文献[9-10]提出了一种新型的基于视觉物体识别的室内定位算法,该算法利用深度学习方法检测、识别拍摄图像中物体,并通过与数字地图匹配计算大致位置,最后利用非线性解算方法计算准确定位结果。考虑定位算法中的物体识别算法对物体识别的正确率不足,且对物体的轮廓识别精度差,因此影响了最终的定位精度。为了进一步提高基于图像物体识别算法的室内定位精度和成功率,文献[11-12]提出了将模板匹配与区域卷积神经网络(Regional-Convolutional Neural Network,R-CNN)算法相结合的物体识算法,即区域卷积网络-模板匹配联合检测(Parallel R-CNN Detection and Template Matching Refinement,PDTR)算法,该算法在一定程度上优化了图像中目标识别的成功率,即减少了误差识别,但模板匹配的引入也导致对物体识别的过程中需要对模板库中的所有样本进行依次匹配,算法的复杂度有较大提升。
为了改善上述研究中由于物体识别不准确导致定位准确度差的问题,拟提出一种改进的并行全卷积神经网络(Parallel-Fully Convolutional Neural Network,P-FCN )物体识别算法。该改进的P-FCN网络对图像中的物体进行检测与标记,将传统的全卷积神经网络(Fully Convolutional Neural Network,FCN )并行化,利用FCN网络中的上采样层和下采样层,从多个维度对图像中的每个像素进行独立分类,在有效提高物体识别率的同时,提高物体的轮廓识别精度,并在此基础上进一步在P-FCN网络中增加模糊区域确定网络,消除楼层模糊干扰,提高定位准确性。
1 基于物体识别的室内定位算法
基于物体识别的室内定位算法的工作步骤如下,具体工作过程如图1所示。
步骤1在服务器端建立室内电子地图,在地图中标记如门、窗、灯等真实物体的位置坐标,并在地图中各个位置、以不同角度产生用于描述真实物体相对空间关系,如上、下、左、右的拓扑图,即地图拓扑图(Map Graph,MG)。
步骤2应用智能手机拍摄周围环境的照片,并将照片上传服务器。
步骤3服务器端利用物体识别算法检测图像中的物体,并以相同的拓扑图产生方式为用户拍摄照片中检测出的物体产生拓图像拓扑图(Image Graph,IG)。
步骤4将IG图与生成的所有MG图根据规则进行比较,相似度最高的MG图的位置和方向被选取为拍摄用户的粗定位、定向结果。受到物体检测算法性能和物体空间关系的不唯一性的影响,粗定位结果一般精度较低,且存在多种位置解的情况。
步骤5为了优化定位精度,在得到了粗定位结果与物体匹配结果后,进一步应用图像中物体的尺寸信息计算出物体伪距,建立并求解定位方程,实现精定位。
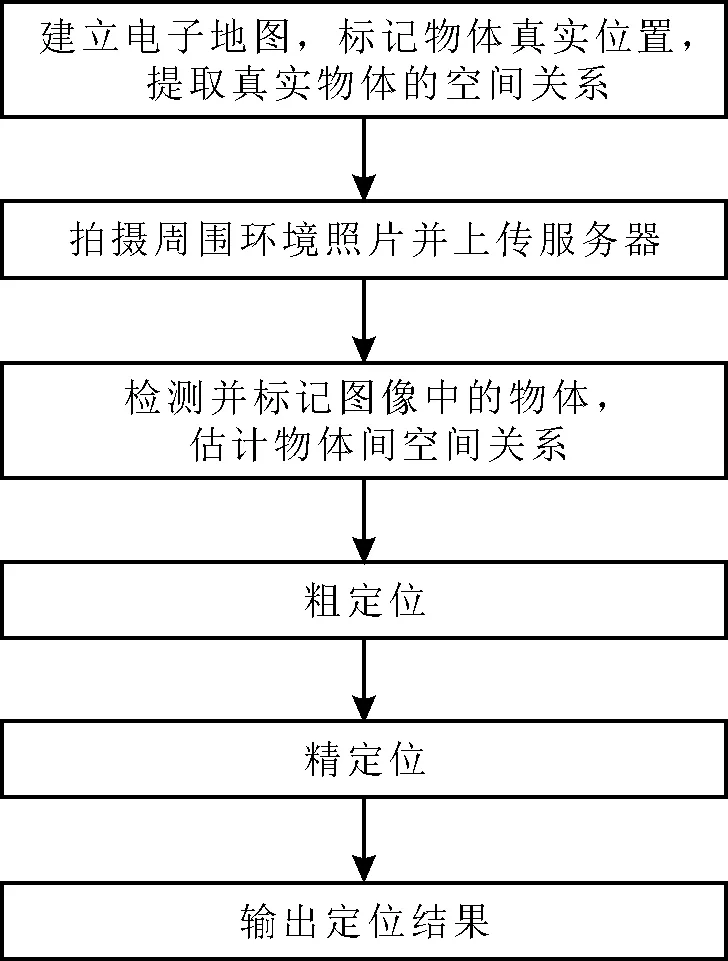
图1 基于目标的室内定位系统的工作过程
根据上述步骤,当前基于物体的室内定位算法能够在室内环境下提供米级的定位精度,但仍有较高概率发生定位失败或定位结果模糊问题,制约上述定位算法性能的原因有:首先,在步骤4中,真实环境中常见物体的重复率很高,导致物体之间的空间关系在不同位置上也有很高重复概率,进一步导致了用户粗定位结果的模糊性和不确定性,甚至可能直接导致定位失败;其次,在步骤5中,算法将成功匹配的物体视为“卫星”或“基站”,因此,可以从电子地图上获取成功匹配物体准确的绝对位置,利用PDTR算法输出的物体标记框图,计算出拍摄图像的位置相对于物体的距离,并以此实现精确定位。考虑R-CNN算法和改进后的PDTR算法输出的标记框都无法准确覆盖被检测对象,并导致相对距离计算不准确,最终导致定位精度的下降。
2 并行FCN物体检测算法
FCN网络是Jonathan在文献[13]中提出的一种新的神经网络结构,是在传统CNN网络结构的基础上进一步发展而来。一般来说,传统的CNN网络由输入层、卷积层、池化层和最后的完全连接层组成,如图2所示。对于CNN网络,输入的数据在卷积层中与不同的核数据进行卷积处理,得到不同维度下的特征信息。之后,池化层通过降采样步骤大幅降低了网络中参数的数量。在经过多个交织的卷积层和池化层后,最终的全连接层将特征信息映射为一个固定长度的向量,其中每一个值代表输入参数属于某种类的概率。CNN网络在处理图像数据时,图像中像素间的空间关系被舍弃,因此在图像识别的应用中,CNN网络一般只适用于整张图像级的分类和回归任务。如在文献[14]中,经典的Alexnet是一个典型的图像级识别网络,最终的结果是一个1 000维的向量,表示属于每个种类的可能性,可能性最高的一个被认为是输入图像的类型。
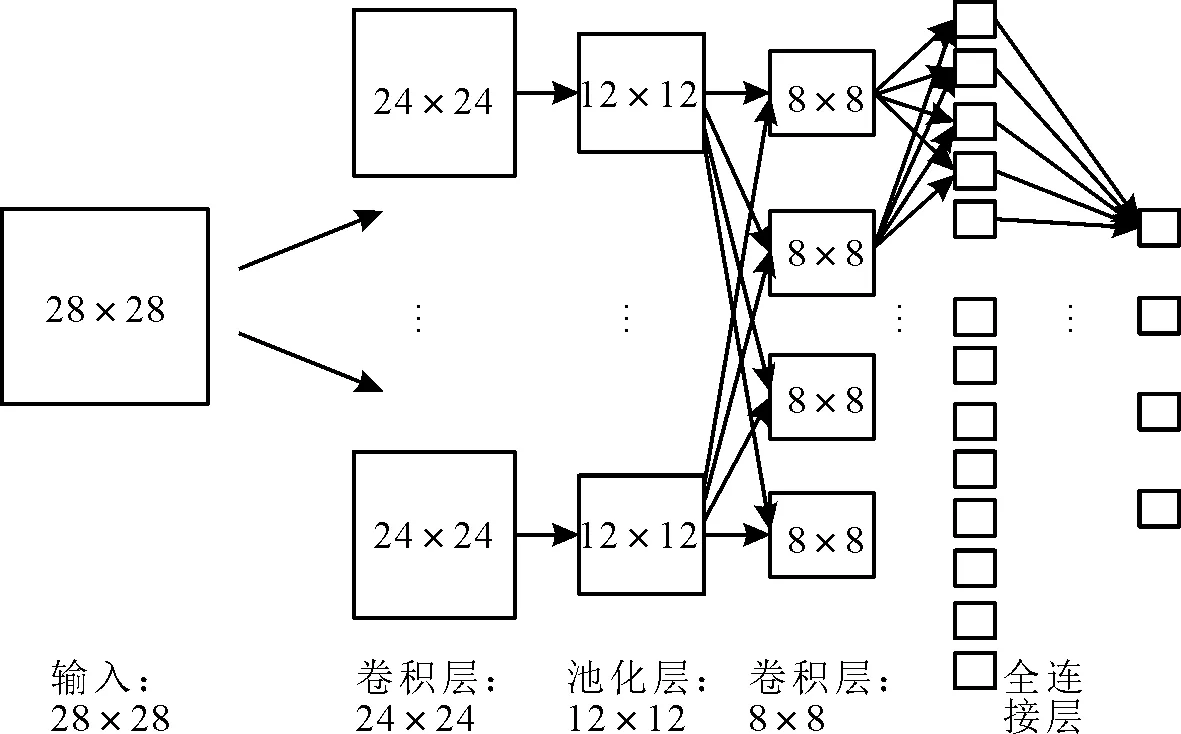
图2 传统CNN网络结构
为了实现在同一张图像中检测多种物体并对其进行分类的目的,Jonathan提出了FCN网络,FCN的网络结构如图3所示。FCN在保证CNN网络架构的基础上,增加了反卷积和反池化层,通过这两个网络层可以将降采样后的数据重新插值回原数据尺寸,同时,CNN网络中最后的全连接层被替换为卷积层,该卷积层尺寸一般为m×n,其中m为数据层数,n为类别个数。因此,当一幅H×W的图像被输入到FCN网络后,FCN网络最终的输出为H×W×n维的数组,而每个像素点对应的n维向量中数值最大的元素所对应的索引,即是对该像素的分类结果。FCN在对数据的处理过程中保留了像素间的空间信息,因此带来了像素级分类的效果。但一方面,用于像素点分类的特征值个数的减少,与CNN算法相比,FCN算法对每个像素分类精度将在一定程度上降低,尤其是对目标边缘像素点的敏感性;另一方面,用于训练的数据集中各种物体出现的频次不同,如门和窗户在室内场景更为常见,而垃圾桶和饮水机等则较少出现,这种训练数据的不平衡将会引起网络对罕见物体的特征信息收敛较差,从而进一步影响训练效果。上述原因也导致在同样的训练条件下,FCN对于目标特征的收敛性能不如基于CNN的Faster R-CNN、YOLO(You Only Look Once)[15]等识别网络。

图3 FCN网络结构
针对上述情况,为了进一步提高FCN算法的识别精度,特别是为了提高物体边缘像素点的分类精度,提出一种P-FCN网络架构,其采用独立训练的FCN网络识别不同的物体,并在融合器中将各个子网络输出的识别结果进行汇总和融合,从而提高目标识别的准确率和成功率。所提出的P-FCN网络的架构如图4所示,其中每个子网络仅负责检测一类对象,最后由融合器将每个子网络的输出结果进行整合并输出图像的最终检测结果。在此网络中,每个子FCN网络只需将像素分为两类,即确定像素是属于待检测对象还是背景。另外,当不同的子网络将同一像素点识别为不同的物体类别时,取可能性分数高的输出结果作为最终的分类结果。

图4 并行FCN网络结构
3 基于CNN的模糊区域确定算法
粗定位结果的模糊性和不确定性是制约基于物体的室内定位算法可用性的主要因素。产生模糊定位结果的场景如图5所示。如图5(a)和图5(b)属于两个不同楼层但位置几乎相同的图像,可以看出,不同楼层中的物体分布具有很大的近似性。如果直接应用文献[9-10]中的粗定位算法,将很难区分用户的楼层结果。在求解精确定位的非线性方程组时,错误的粗定位结果很可能导致收敛失败,最终导致定位失败。如图5(c)和图5(d)为两个不同位置,但却具有相似的物体分布,在这种情况下即便在同一楼层,粗定位模糊的问题同样有很大概率发生。

图5 产生模糊定位结果的场景
虽然图5(a)和图5(b)、图5(c)和图5(d)在检测到的物体分布上具有相似性,但是从图5中可以观察到,在不同区域下,不同图像中的背景相差较大,这些差异主要来源于不同室内场景的装修、墙面涂刷和布局等因素,而这些因素可以用来判断拍摄图像的大致位置。因此,提出在上一节中并行FCN网络的基础上再增加一个CNN子网络用于对输入的图片进行区域分类,该子网络称为模糊区域确定网络(Ambiguous Zone Determination-CNN,AZD-CNN)。
根据P-FCN的介绍,P-FCN网络的输出为与输入图像大小相同的分类图谱,并且那些未被识别为物体的像素可以被视为背景。因此,可以通过对输入图像进行简单的图像处理,以保证输入CNN网络中的数据均为背景,减少物体对结果的影响,图像中某像素点的原始值表达式为

(1)
其中:k为像素点的索引;c(k)为P-FCN网络输出的该像素点的分类结果,当c(k)=0时,表示像素点被分类为背景。
经过式(1)处理后的图像仅保留原图中的背景信息,且图像尺寸保持不变。将图像输入到CNN网络中,CNN网络的输出为特定位置的区域。需要说明的是,AZD-CNN的训练输入数据是去除目标后只包含背景的图像,其输出为结果所拍摄图像的位置区域,而训练数据集则是通过人工将物体消除后的图像数据,与数字地图相对应的位置区域如图6中所示,在训练数据集中,每个区域平均包含150张照片。

图6 实验场景中的区域划分
AZD-CNN网络的输出将对粗定位结果进行修正,即当粗定位结果落入AZD-CNN输出的相应区域时,粗定位结果被认为是正确的,并可以作为精确定位步骤中的初始位置。相反,当粗定位结果落在AZD-CNN输出的相应区域之外时,粗定位结果被认为是不正确的,因此被舍弃。所提P-FCN网络的完整结构如图7所示。
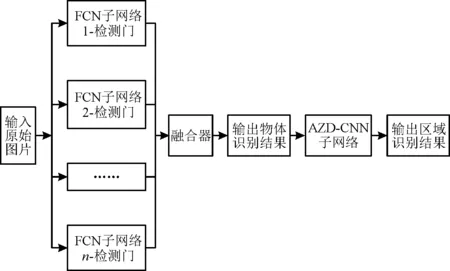
图7 P-FCN网络最终结构
4 实验介绍
为了验证所提的P-FCN算法的性能,在室内环境中进行了实验测试,实验测试的范围分别为2.4 m×33 m、2.4 m×52 m的走廊和多间7 m×7 m的房间。在测试环境中分布着包括饮水机、垃圾桶、桌子、柜子、窗户和灯等多种室内物体,部分物体用不同标志标记于图8所示的二维图中,在实验中共包含通过智能手机摄像头拍摄的500张图像,其中420张照片在通过研究人员的处理和人为标记后为网络提供训练数据。另外,80张照片作为定位算法的验证。实验中,对图像中的10种物体,包括门、垃圾桶和灯等进行标记,表1中展示了训练数据集中包含的物体类型,以及与每种物体在所有500张照片中的出现次数。另外,为了建立物体数字地图库,共记录了94个物体及其在地图中的位置。
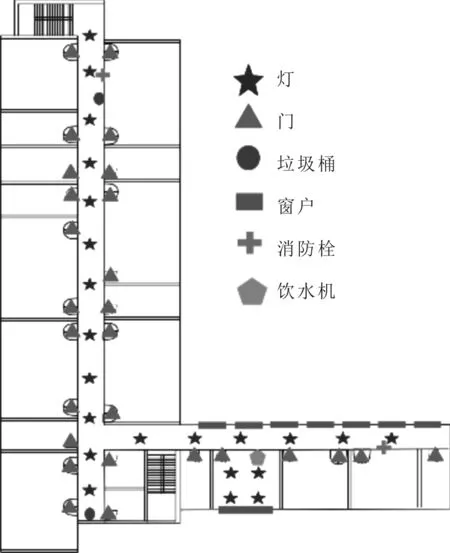
图8 部分物体在实验场景中的分布示例

表1 训练样本中的物体种类和个数
5 实验结果与分析
在实验中,首先比较了PDTR、传统FCN和P-FCN算法在目标识别和标记精度方面的性能,上述算法被分别用于检测相同照片中的物体,原照片如图9(a)中所示,PDTR、传统FCN和P-FCN算法的检测结果分别如图9(b)、图9(c)、图9(d)。从图9中可以看出,与传统的FCN相比,PDTR和P-FCN在目标识别的成功率上具有更大的优势。这主要是由于传统的FCN在同一个网络中有许多特征信息需要收敛,因此训练效果差。然而在PDTR和P-FCN中,每个子网只负责检测一个物体,网络中的参数可以更好地收敛到物体的特征。

图9 不同算法的物体检测结果对比
另外,训练集中的对象数目不相等,不同识别算法的物体标记准确度比较如表2所示。FCN网络对物体的收敛效果参差不齐,如在图9(c)中很容易观察到不同物体的检测性能的差异,FCN算法对于垃圾桶有较好的识别能力,但对于门和灯均无法很好地辨识。虽然PDTR和P-FCN在目标检测方面具有相同的性能,但在标记精度方面,P-FCN具有像素级别的分类能力,能更准确地标记目标。

表2 不同识别算法的物体标记准确度比较
表2中展示了3种算法对80张测试图像的物体识别率和标记准确率。其中,标记精度的计算表达式为

(2)
其中:s∩表示算法计算得到的物体标记结果与研究人员手动标记框(视为真实值)的交集面积;s∪表示两个标记结果的总面积。从表2可以看出,与另外两种算法相比,P-FCN算法的识别率分别提高了28%和9%,对物体的平均标记准确率分别提高了9%和17%。
除了对目标检测算法的性能进行比较外,还对定位精度进行了比较。不同算法的定位结果比较情况如表3所示。错误率表示输出的定位结果与用户真实的位置的空间差大于3 m,模糊位置率表示输出了多个可能的用户位置。其中包含了用户正确的位置,成功率则表示输出位置唯一且正确。需要说明的是,只有定位成功时才计算平均定位误差。

表3 各算法的定位结果比较
从表3可以看出,与现有的基于PDTR的室内定位算法相比,P-FCN的定位成功率提高了13%,平均定位误差降低了1.2 m,上述定位性能显著提高的原因不仅在于识别算法带来了更精确的目标识别结果,还在于P-FCN中的子网络AZD-CNN能够修正多位置模糊问题。此外,从表3的结果可以看出,P-FCN算法的模糊位置率和模糊定位结果次数都有明显的降低。
6 结语
为了改善传统基于视觉物体识别的室内定位算法中物体识别不准确导致定位精度低的问题,提出了一种改进的P-FCN物体识别算法。该改进算法利用并行FCN网络对室内物体进行检测和标记,并结合AZD-CNN网络减少了粗定位的区域模糊概率。实验结果表明,相比于传统的基于PDTR的算法,基于P-FCN的室内视觉定位算法的定位成功率提高为85%,平均定位误差降低为1.4 m。这一算法能够提高图像中物体识别的准确率、轮廓识别精度和粗定位准确性,并能提高最终的定位成功率和定位准确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中国外汇(2019年20期)2019-11-25
海峡姐妹(2018年2期)2018-04-12
人大建设(2018年12期)2018-03-21
杂文选刊(2018年1期)2018-01-09
少儿科学周刊·儿童版(2015年2期)2015-07-07
科普童话·百科探秘(2015年4期)2015-05-14
