
领域驱动设计模式的收益与挑战:系统综述∗
2021-11-09 05:51贾子甲钟陈星周世旗荣国平
软件学报 2021年9期
贾子甲,钟陈星,周世旗,荣国平,章 程
1(南京大学 软件学院,江苏 南京 210023)
2(计算机软件新技术国家重点实验室(南京大学),江苏 南京 210023)
3(安徽大学 计算机科学与技术学院,安徽 合肥 230601)
领域驱动设计(domain-driven design,简称DDD)是一种在软件设计中应该遵循的思维方式,其目标在于加快具有复杂需求的软件项目的研发速度[1].DDD 中最重要的理念是通过构建领域模型来解决软件开发的复杂性问题[1],因为在大多数软件项目中,最困难的往往是解决业务领域复杂性,而非技术复杂性.DDD 的一个显著特征就是设计与开发的绑定,DDD 强调软件设计概念必须在开发过程中得以成功实现[2].为了实现以上这些愿景,在DDD 方法中,将一组设计实践、技术和原则合并为标准模式,即所谓的领域驱动设计模式(domain driven design pattern,简称DDDP)[1],它们则构成了领域驱动设计的主体.
自从2004年“领域驱动设计”被首次提出以来[1],这一概念随着软件开发组织的广泛应用逐渐流行起来.一些实践者为DDD 社区做出了巨大的贡献,例如:Nilsson[3]讲述了如何通过结合DDD 来构建.NET 应用程序,Vernon[4]对于DDD 的概念给出了新的解释,Millett 和Tune[5]阐释了对DDD 的实践、模式和原则的全面理解.同时,DDD 也被IBM[6]、阿里巴巴[7]等大型企业采用,以支撑大规模应用.此外,DDD 社区也活跃着多个面向工业界的会议,例如DDDSummit(https://ddd-summit.de),EXPLORE DDD(http://exploreddd.com)和DDDConference(http://www.ddd-china.com).
DDD 的立足点是解决软件开发中的复杂性问题,这顺应了当今软件系统复杂度不断提升的趋势;此外,DDD 与当前主流的分布式架构设计风格——微服务架构(micro service architecture)[8]的关系非常紧密[9,10].而近年来,微服务架构已经越来越多地应用在各类大型软件系统当中.上述技术特点和发展趋势,使得DDD 在业界越来越流行.
然而,领域驱动设计也面临着一些困境.在学术研究方面,相比于在业界实践中的流行程度,DDD 相关的研究关注度明显不足.在业界实践方面,想要成功地在软件开发中实践领域驱动设计,特别是DDDP,往往具有一定的挑战性.开发人员在应用限界上下文(bounded context)、聚合(aggregate)[4]等比较抽象的DDDP 时往往感到非常困惑,比如在分布式系统中应用限界上下文模式就存在一定困难[11],这在最近的一项微服务相关访谈研究[12]中得到了证实.
而DDDP 的实际应用情况如何?其能够为软件开发带来何种收益?又将造成什么挑战?上述问题目前尚未得到较为系统化的回答.因此,为了更加系统地了解DDDP 的应用现状、收益、挑战及相应的解决方法,本文进行了系统文献综述(systematic literature review,简称SLR)来调研已发表的基础研究(primary study).系统文献综述是软件工程领域的一种主要的“循证”方法,该方法通过合成当前研究中的高质量证据,以减少单个基础研究的偏差,从而达到辅助软件项目的决策过程的目的.自从这种“循证”方法被软件工程社区采用以来,各领域的许多重要研究都应用了系统文献综述这一方法[13−15].考虑到软件开发组织能够从这种系统文献综述中获取宝贵经验,并且目前的学术界尚未发表有关领域驱动设计的综述性文章,因此,本文的工作对于学术界和产业界均具有一定的借鉴意义.
具体而言,本研究工作的主要贡献包括以下3 个方面:首先,本文揭示了DDDP 在软件开发项目中的实际应用情况;其次,总结了应用DDDP 所带来的收益,便于实践者能够在软件项目中更好地把握机遇;再次,本文对于DDDP 应用实践中所面临的挑战以及应对挑战的缓解方法进行了论述,能够帮助实践者更好地应对挑战,并为研究者提供了未来可能的探索方向.
本文第1 节介绍DDDP 的背景知识.第2 节介绍本文所采用的系统文献综述方法.第3 节给出综述的结果.第4 节对于综述结果进行深入分析和讨论.第5 节分析本研究中存在的效度威胁.最后,第6 节给出对于应用DDDP 的总结与展望.
1 背景介绍
1.1 领域驱动设计的本质
领域模型(domain model)作为设计具有复杂业务规则的企业应用程序的一种软件设计模式,该模式可以被看作是一个具有行为和数据的领域对象模型[16].领域模型正是领域驱动设计的基础.具体而言,DDD 方法说明了如何利用DDDP 从业务中抽象出领域模型,并将其置于软件开发的核心位置[1].
DDD 具有几个基本原则.
•第一,在首先提出DDD 的书籍中[1],Evans 强调设计概念必须在代码中成功实现,否则,它们将会变成抽象的讨论.DDD 通过引入模型驱动设计(model driven design)建模范式及其构造块,弥补了模型与可运行的软件之间的差距;
•第二,DDD 还提倡迭代开发,并说明了如何借助敏捷[17]中的迭代式领域建模加速软件开发[1].领域驱动设计与具体实现过程间的紧密关系,使得DDD 比其他软件设计方法更具有实用性;
•第三,在实践DDD 的过程中,开发人员和领域专家之间需要展开紧密协作,这是因为DDD 追求的领域模型需要依靠头脑风暴的创造性和对领域的深入了解[1];
•第四,DDD 是一种软件设计方法,而任何设计出来的领域模型都应该与架构无关[4].也就是说,除了领域模型,在软件开发过程中仍然需要架构设计,比如微服务架构和六边形架构[4].
1.2 领域驱动设计模式概览
DDD 由Evans[1]作为一种大型模式语言(pattern language)引入,其由一组相互关联的模式组成.模式语言提供了讨论问题的交流术语,它定义了特定场景、特定问题的解决方案,其主要目的是帮助开发者解决在设计和编程中遇到的通用问题.模式语言在软件工程中被广泛地应用,比如设计模式(design pattern)、企业架构模式(enterprise architecture pattern)等.DDD 与DDDP 的关系,正如同面向对象设计(object-oriented design,简称OOD)与面向对象设计模式(即设计模式)的关系.
对于领域驱动设计而言,最基本的模式是通用语言(ubiquitous language),它是一种供不同涉众(如开发人员和领域专家)共同使用的语言,主要用于辅助领域建模[4].一种通用语言只适用于单个限界上下文(bounded context),后者作为一个显式的模型边界来维护模型的完整性.根据Vernon[4]的观点,除了通用语言之外的DDDP,要么属于战略设计模式(strategic design pattern),要么属于战术设计模式(tactical design pattern).
战略设计模式旨在应对具有多个领域模型的大型软件开发项目的复杂性,其中,每个领域模型都属于单独的限界上下文.具体而言,限界上下文作为一个显式的模型边界来维护模型的完整性,从而避免了模型之间的相互连接使彼此变得模糊[1].限界上下文以外的其他战略设计模式关注如何管理不同限界上下文(如上下文映射和职责分层)之间的关系,比如,上下文映射(context map)负责描述不同领域模型间的通信,而职责分层(responsibility layer)则站在更高的抽象层级来组织不同领域模型间的概念依赖关系.
战术设计模式负责根据通用语言对单个限界上下文进行领域建模[4],并结合面向对象的原则来绑定领域建模和编码实现.战术建模的典型模式包括实体(entity)、值对象(value object)、聚合(aggregate)、服务(service)、资源库(repository)等.具体来讲:实体和值对象用于对具有不同领域特征的领域对象进行建模;聚合将一组领域对象绑定为一个整体,以控制事务;服务则充当领域模型的接口,具有无状态的特点;而资源库则用于封装领域对象的数据库访问操作.
2 综述方法
本系统性文献综述根据Kitchenham 等人的指南[18]开展研究.本节首先提出驱动本工作开展的研究问题,其次描述了数据收集所遵循的详细策略和流程,最后描述了本研究的数据抽取和合成过程.
2.1 研究问题
本研究的总体目标是形成在软件开发中应用领域驱动设计模式的系统性理解,了解应用领域驱动设计模式的实践情况,包括其带来的收益、挑战及应对挑战的缓解方法.为此,本研究提出了如表1所示的具体研究问题.其中:研究问题1 是为了了解DDDP 在软件开发项目中的应用现状;研究问题2 是为了调研应用DDDP 所带来的收益情况;研究问题3 是为了总结应用DDDP 所面对的挑战以及应对挑战的缓解方法,并挖掘未来可能的研究方向.
2.2 文献收集
本小节描述了系统文献综述中的数据收集过程,包括了文献检索、文献筛选、文献整合、滚雪球、质量评估和模式识别等.文献收集的总体流程(于2019年7月进行)如图1所示.本文的3 位作者在来自手动检索、自动检索以及滚雪球过程的1 884 篇文献中最终确定了26 篇高质量的基础研究(primary study)作为研究集合.
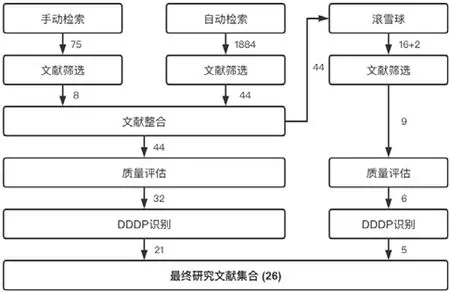
Fig.1 Literaturecollection procedure图1 文献收集过程
2.2.1 文献检索
为了尽量降低遗漏任何相关文献的风险,本文采用了多种文献检索策略.此外,根据Kitchenham 等人的指导方针[18],我们通过试点(pilot)文献综述确定了一组相关文献,以用于验证检索过程的完整性.这组已知文献包括:
•Challenges of domain-driven microservice design:A model-driven perspective[J];
•Towards a UML profile for domain-driven design of microservice architectures[C];
•Designing microservice-based applications by using a domain-driven design approach[J];
•An ontology-based approach for domain-driven design of microservice architectures[J].
接下来对检索过程的一些关键步骤进行详细说明.
(1)手动检索
为了提供更全面的自动检索字符串,本研究首先进行了手动检索.本过程所选取的两种出版源分别是:
①已知文献集合的出版源;
②软件设计和架构相关的期刊与会议.
手动检索的过程首先由本文的两位作者独立进行,之后将检索结果合并到一起,即:只要一位作者认为该文献与本研究相关,就会被纳入此阶段的文献集合中.
表2 展示了从各个出版源检索到的相关文献数量.

Table 2 Publication venues included in manual search表2 手动检索的出版源
(2)自动检索
在这一阶段,本文作者检索了3 个主要的在线学术数字图书馆:①IEEE Xplore(https://ieeexplore.ieee.org/Xplore);②ACM Digital Library(https://dl.acm.org);和③ScienceDirect(https://www.sciencedirect.com);以及一个索引系统:④Scopus(https://www.scopus.com).对于检索字符串,本文作者确定了研究问题中最普遍的关键字(即“DDD”),并决定只包含它和它的相关同义词进行检索,这些同义词是从手动检索结果和已知的论文集合中获得的.通过合并OR 操作符,本文使用的最终检索字符串如下:
(“DDD” OR “domain driven design*” OR “domain-driven design*” OR “domain driven approach*” OR“domain-driven approach*” OR “domain driven develop*” OR “domain-driven develop*”)
每个检索源的详细检索结果见表3.

Table 3 Intermediate result in snowballing表3 滚雪球过程的中间结果
(3)滚雪球
在手动检索与自动检索之后,本研究中还使用了反向滚雪球(backward snowballing,简称BSB)和前向滚雪球(forward snowballing,简称FSB)方法对检索结果进行补充.考虑到滚雪球的初始论文集决定了该过程的效率和完整性,本研究将手动检索和自动检索所得进行文献选择并合并后的结果(见图1 和表4)作为滚雪球的初始集合.注意,所有手动检索的结果都被自动检索的结果覆盖.在这个阶段,我们遵循Wohlin[19]的指导方法,并且反复迭代滚雪球的过程,直到不再有新的文献被发现.
表4 中,第1 次迭代和第2 次迭代最终分别获得16 项(5+12=17,其中1 篇文献重复,最终得到16)和2 项新研究文献.

Table 4 Intermediate result in snowballing表4 滚雪球过程的中间结果
(4)DDDP 的自动检索
为了进一步确保研究集合的完整性,本研究通过基于DDDP 名称的自动检索来补充现有的检索策略.具体来说,我们在Scopus 中执行了另一个自动检索过程,其检索的字符串由每个模式的名称以及“domain”(“领域驱动设计”的最通用术语)和“software”(软件工程最通用的术语)组成.比如,与DDDP“Entity”(及“Entities”)相关的检索字符串为如下:
(“Entit*” AND “domain” AND “software”).
对于DDDP 的完整列表,我们遵循了Evans[20]在2014年的总结,总共包含45 个模式.然而,虽然这种检索方法使用Scopus 中的字段码TITLE-ABS-KEY 检索到了7 515 篇论文,但经过文献筛选后,并未获得新的文献.两次检索所得论文数量的巨大反差,可能是因为许多DDDP 的名称在软件工程中也非常通用,比如服务(service)和资源库(repository)等.因此,本文并没有在图1 中包含此检索过程.
2.2.2 文献筛选
本系统文献综述使用的文献纳入和排除标准如下所示.注意,只有符合所有纳入标准的基础研究文献才会被纳入,而符合任何一项排除标准的文献都将被排除.
(1)纳入标准(include criteria)
•IC1:文献提供了关于DDD 的某种形式的数据.在这一阶段,我们的目标是最大限度地扩大文献范围,以确保研究的完整性;
(2)排除标准(exclude criteria)
•EC1:发表于2003年DDD 被发表之前的文献(因为DDD 于2003年被提出);
•EC2:无法获得电子版全文的文献;
•EC3:用英语以外的语言撰写的文献;
•EC4:没有经过同行评审的文献;
•EC5:存在更加完整的文献.即同一基础研究(primary study)有多篇文献,此时将最完整的文献纳入.
具体筛选过程如下:
•前期准备:按主题筛选——我们通过浏览自动检索得到的每篇文献的标题,并确定其是否属于软件工程领域.注意,这个阶段是专门为自动检索设计的,因为一些数字图书馆(例如Scopus 和ScienceDirect)不支持基于主题的筛选,或者其基于主题的筛选功能相对有限;
•第1 阶段:按标题筛选——我们通过浏览手动检索、自动检索以及滚雪球所得到的文献列表的标题,以确定哪些文献符合纳入/排除标准;
•第2 阶段:按关键词和摘要筛选——我们分析通过第1 阶段的文献的关键词和摘要,进一步确定它们是否符合选择标准;
•第3 阶段:阅读全文筛选——我们通读了通过前两个阶段的文献全文,并保留符合预先定义的筛选标准的文献.
表5 给出了筛选过程的中间结果.

Table 5 Selection details of literaturefrom different search methods.表5 不同检索阶段的文献选择情况
在分配选择任务时,我们确保每篇文献的每个选择阶段都由至少两位作者完成.此外,每篇存在争议的文献都要先由第三位作者进行评估,然后再通过讨论达成共识.如果这样还无法解决分歧,则将会和本研究的指导者进行讨论,直到达成共识为止.此外,为了增强我们对文献筛选过程的信心,本研究在自动检索所得文献的筛选过程中引入了Kappa 评分[21],并且最终Kappa 评分结果为0.722(“Good/Substantial”).另外,还有两项证据也可以证明检索和筛选过程的全面性.
•所有已知集合中的文献(来自试点文献综述)都可以通过检索过程找到,并且被选中;
•从手动检索中选取的所有文献都包含在自动检索的选择结果中.
2.2.3 质量评估与模式识别
在研究集合的确定过程中,本工作还引入了质量评估(quality assessment)来排除一些质量较低的基础研究.根据Dyba 等人[22]的质量检查表,本研究制定了质量评估标准,该标准通过了本研究指导者的审查.在质量评估过程中,我们根据评分情况排除了共15 篇质量得分较低的基础研究.
在经过质量评估之后,本研究进行了模式识别,进一步排除了没有提及任何DDDP 的基础研究(图1).之所以将模式识别作为一个环节而不是一项文献筛选标准,是因为一些目标文献可能在另一些文献的滚雪球阶段被纳入进来,而后者可能并没有提及任何DDDP 而只与领域驱动设计理论相关.这样做的目的是在收集文献时尽可能全面地覆盖相关文献.我们排除了手动检索和自动检索中的11 篇论文以及滚雪球检索中的1 篇论文,最终得到了26 篇高质量基础研究.
2.3 数据抽取与合成
首先给出指导数据抽取过程的数据抽取项,然后描述对数据抽取结果的合成(synthesis)方法.在数据抽取和合成环节中,我们主要使用Nvivo(https://www.qsrinternational.com/nvivo)和电子表格来记录数据.
2.3.1 数据抽取
我们参照Zhang 和Budgen[23]的方法定义了数据抽取项(见表6),其主要由基础信息、研究背景以及研究问题相关信息这3 部分组成.其中:基础信息指的是文献的标题、作者以及发表时间等内容;研究背景指的是文献的研究兴趣特征,这些信息可能会影响结果的解释方式;研究问题相关信息指的是文献中与DDDP 相关的知识,包括回答研究问题所需要的数据项.除了描述每个数据抽取项之外,表6 还说明了本研究是否为这些数据抽取项提供特定的代码,如果代码为“否”,则该抽取项使用自由文本进行提取.为了进一步确保数据抽取表的可靠性,本文作者与指导者一起对其进行了审查,并且随机选择了3 篇文献进行了试点研究(pilot study),并根据实验结果对数据抽取项进行了改进.
在进行数据抽取时:首先,我们使用格式化的电子表格来统一数据抽取格式;然后,两位作者逐字逐句地阅读文献并抽取相应的数据.在此过程中,来自研究文献的原始文本被原封不动地记录到数据抽取项中.此外,正如Cruzes 和Dyba[24]所推荐的,我们也将表格和图形作为数据抽取的素材粘贴到电子表格中.
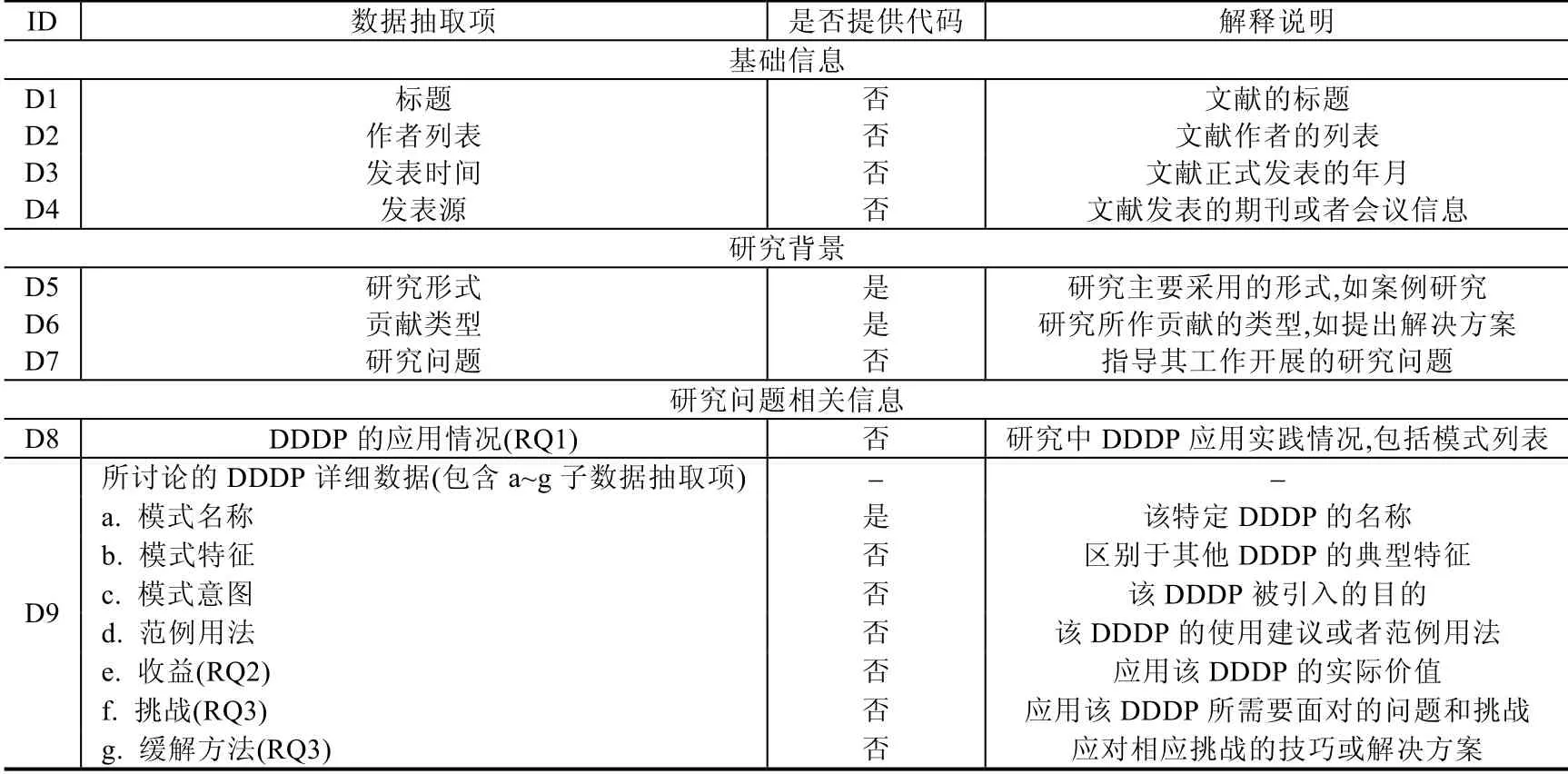
Table 6 Data extraction items表6 数据抽取项
2.3.2 数据合成方法
为了深入了解DDDP,本研究的数据抽取过程产生了大量的定性数据.此外,在DDDP 相关的基础研究中,同一个词语在不同的上下文中可能具有不同的含义,比如“服务(service)”可能表示一种DDDP,但也可能表示软件工程中非常普遍的“Web 服务”[25],这为数据合成造成了一定阻碍.因此,本研究需要使用一种合适的定性数据合成方法,来保证能够合成出语义合适的结果.
本研究在进行定性数据合成的过程中,使用了来源于扎根理论(grounded theory)[26]的两个抽象层次的编码方法,即开放码(open codes)和轴向码(axial codes)[27].本研究所使用的编码方法是Braun 和Clarke[28]提出的主题分析(thematic analysis),我们利用该方法获得了各种定性数据(见表6)的聚合结果.
这里简单介绍数据合成过程的一些细节.在熟悉了基础研究文献之后,两位作者分别对提取到的原始文本进行开放编码,即识别文本的语义内容和隐含内容,并将其与原始数据一起记录下来.例如,示例抽取数据的开放编码结果是“更好地理解领域需求”和“更有效的沟通”.当所有的数据集都完成了初始编码后,我们对不同的代码进行分析和比较,并将它们组合成主题.例如,开放编码“更好地理解领域需求”被整理成主题“促进业务理解”.之后,我们进一步对于候选主题进行了细化,比如因为证据不足而放弃了某些开放编码.在这个过程中,NVivo 被用来管理编码和主题之间的层次结构.此外,考虑到这一过程极大地依赖于经验和感知,在执行这一阶段工作之前,所有数据分析和合成的参与者都被要求仔细研读DDD 相关的主流著作[1,3,4,20,29].
3 研究结果
领域驱动设计模式的应用最终表现在一系列相关活动中,因此,本研究识别出了应用DDDP 的相关活动,并以此为基础来组织应用DDDP 所带来的收益与挑战.如图2所示,根据基础研究[30],应用DDDP 的相关活动主要分为4 类,即领域分析(domain analysis)、领域设计(domain design)、领域模型实现(domain model implementation)和普适性活动(umbrella activity),由此组成了DDDP 应用框架,并且上述这些活动与Bruegge 和Dutoit[31]所描述的传统软件开发活动,即需求获取和分析、设计和实现及测试相对应.
对于DDDP 应用框架的进一步说明如下.
•领域分析是指与领域专家一起探索领域知识的过程.经过领域分析,将得到初始的领域模型;
•领域设计是指将模型分成不同部分(每个部分对应着独立的限界上下文),然后扩展和细化每个限界上下文的过程,以此为开发实现做准备;
•领域模型实现是指将模型转换为可运行代码,这一过程还通过检查模型为模型设计提供反馈;
•普适性活动指的是应用DDDP 时,可能在领域分析、领域设计、领域模型实现这3 个阶段都会发生的横切活动,比如构建和更新通用语言.
值得一提的是:在这些活动中,开发团队可能对领域产生更深刻的洞察,并变更之前所做的设计决策.
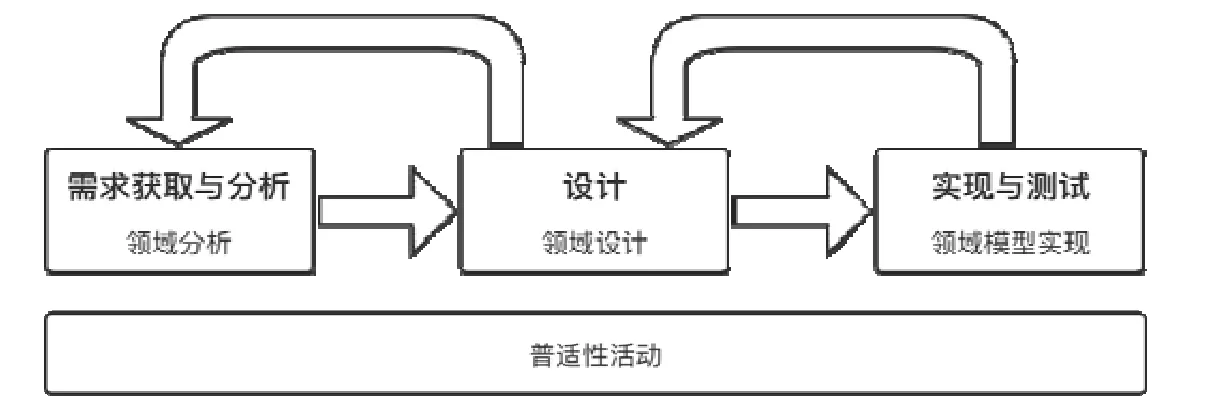
Fig.2 An overview of activities in applying DDD patterns图2 应用DDDP 的活动概览
3.1 研究文献的总体情况
经过收集,本研究总共获得了26 项基础研究,本部分将简要介绍这些相关研究的总体情况.
•出版年份
图3 显示了所收集的文献按出版年份的分布情况.统计数据显示:2006年之前,社区中没有发表过DDDP 相关的基础研究文献;而在2006年~2015年期间,文献发表数量一直保持在较低的水平(每年不超过2 篇).这说明自2003年以来,领域驱动设计及其模式在最初的十几年里并没有得到研究者的足够重视.然而2016年之后,该领域的论文发表数量逐年增加,这可能与DDD 和微服务架构在2016年的结合有关,特别是在QCon 伦敦2016年大会上[32],《Domain driven design:Tackling complexity in the heart of software》的作者Eric Evans 提出使用领域驱动设计概念能够减少微服务环境中通用语言(一种DDDP)的复杂性.本次大会上,Evans 还介绍了3 种可以帮助管理微服务的DDD 工具,并建议将每个微服务设计成一个限界上下文(一种DDDP).DDD 与微服务结合,使得该领域的研究与应用变得更加活跃,这可能是2016年后相关文献数量持续增长的一个重要原因.

Fig.3 Distribution of literatures by years图3 文献发表年份分布
•作者来源
图4 显示了所收集的文献按作者来源的分布情况.根据对于论文署名作者及其所属机构的统计数据显示:在本工作所选取的26 篇基础研究文献中,69.2%(18/26)的文献的全部作者均来自于学术界(包括高等院校以及科研机构等);但是与此同时,也有26.9%(7/26)的文献作者均来自于业界;此外,还有1 篇文献由来自于学术界和业界的多位作者共同完成.综上所述,在本文所选取的DDDP 相关基础研究中,大约30.8%的研究工作有业界的参与,这也从侧面印证了DDD 在软件开发业界的流行程度.
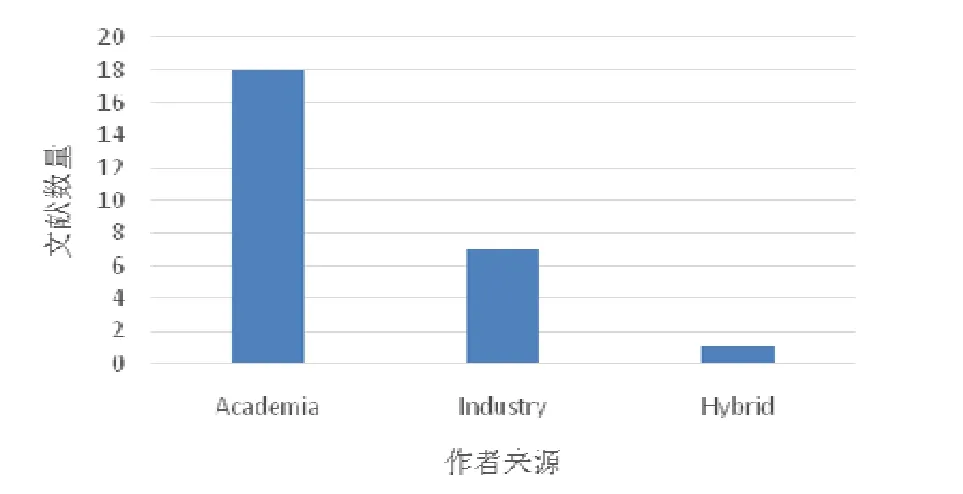
Fig.4 Distribution of literatures by authorship图4 文献作者来源分布
•研究形式
图5 显示了不同研究形式的分布情况.其中,61.5%(16/26)的文献属于案例研究(case study),当研究对象之间的联系复杂且重要时[18],案例研究是一种非常合适的研究形式.同时,在所有相关研究中,实验都不是主要方法.这可能是由于根据Easterbrook 等人的理论[33],控制实验不适合真正复杂的软件项目.此外,23.0%(6/26)的文献采用了经验报告(experience report)的形式,这种形式能够帮助读者从中获得实际经验,因此也非常受欢迎.
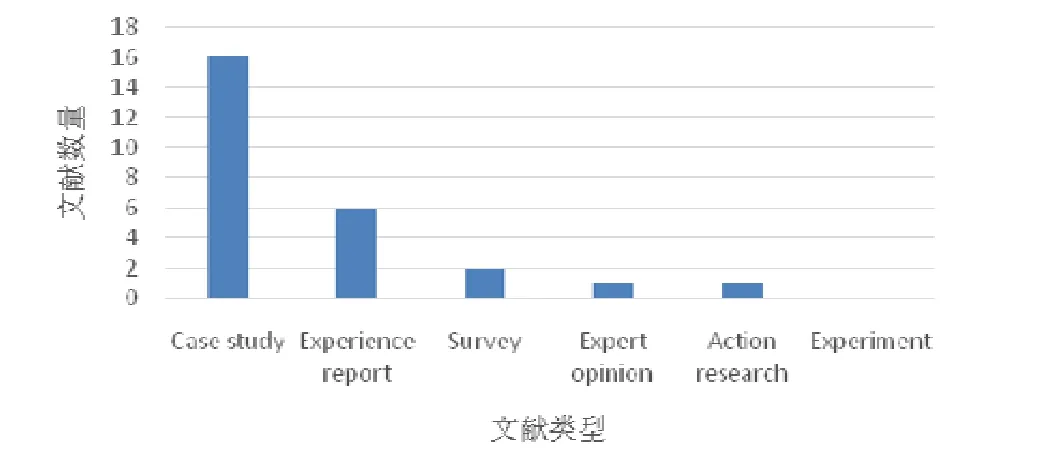
Fig.5 Distribution of literatures bystudy form图5 文献研究类型分布
•贡献类型
如图6所示,大多数研究(18/26,69.2%)提出了DDD 相关的解决方案.这些解决方案研究的目的可以分为两类,其中,77.8%(14/18)的文献致力于利用DDD 解决具体软件系统的开发问题,22.2%(4/18)文献试图解决DDD应用的局限或挑战.此外,15.4%(4/26)的文献论述了将DDD 应用于实践中所获得的经验和教训.

Fig.6 Distribution of literaturesbycontribution type图6 文献贡献类型分布
3.2 DDDP的应用情况(RQ1)
表7 总结了在基础研究集合中,出现频次到达3 次以上的DDDP,以及对应的描述和提及这些模式的研究文献.显然,这些模式出现的频次并不平衡.其中,战术设计模式被提及的频次明显高于战略设计,这与Millett 和Tune[5]的发现基本一致,即,开发人员更容易注意到领域驱动设计的战术设计模式.总体而言,目前只有31.1%(14/45)的DDDP 在基础研究中得到了探讨,这也表明了当前学术界对DDDP 的研究存在不足.

Table 7 Distribution of DDD patterns in literatures表7 研究文献中DDDP 的分布情况
作为一种模式语言,DDD 由一组相互关联的模式组成(即DDDP).Vernon[4]指出:如果在实践中忽略通用语言和DDD 战略设计,而仅仅使用部分战术设计模式,就可能导致领域概念之间的紧密耦合,这样的问题被称为“DDD-Lite 陷阱”.本研究发现:在研究集合中,仅有文献[30,41,42]明确地应用了通用语言、战略设计模式和战术设计模式.有2 项研究可能落入了DDD-Lite 陷阱,因为它们只展示了战术模型,而没有提出任何与战略层面实践相关的观点.比如文献[35]在文章中论述了他们如何演进通用语言、战术领域模型以及持久化策略等实现细节,而并没提及战略设计.与此同时,5 篇研究文献在研究中只采用了战略设计,而没有关注战术设计.具体而言,这些研究专注于企业架构层面,主要分析如何利用战略模式(如限界上下文和上下文映射等)来组织具有多个领域模型的大规模结构.此外,基础研究[40]较为特别,它既没有论述战略设计,也没有论述战术设计,而是分析了如何通过映射具有相似语义的领域概念,将两种不同的战术领域模型集成到一起.
3.3 应用DDDP所带来的收益(RQ2)
为了便于读者理解,本文以表格形式展现了将DDDP 应用到DDD 活动中的收益与挑战.表8 展示了应用DDDP 所带来的收益在领域分析、领域模型实现以及普适性活动中的体现情况,并展示了相关模式和研究文献的证据覆盖范围.除领域分析之外,本研究在DDD 活动的各个阶段均发现了应用DDDP 所带来的收益.
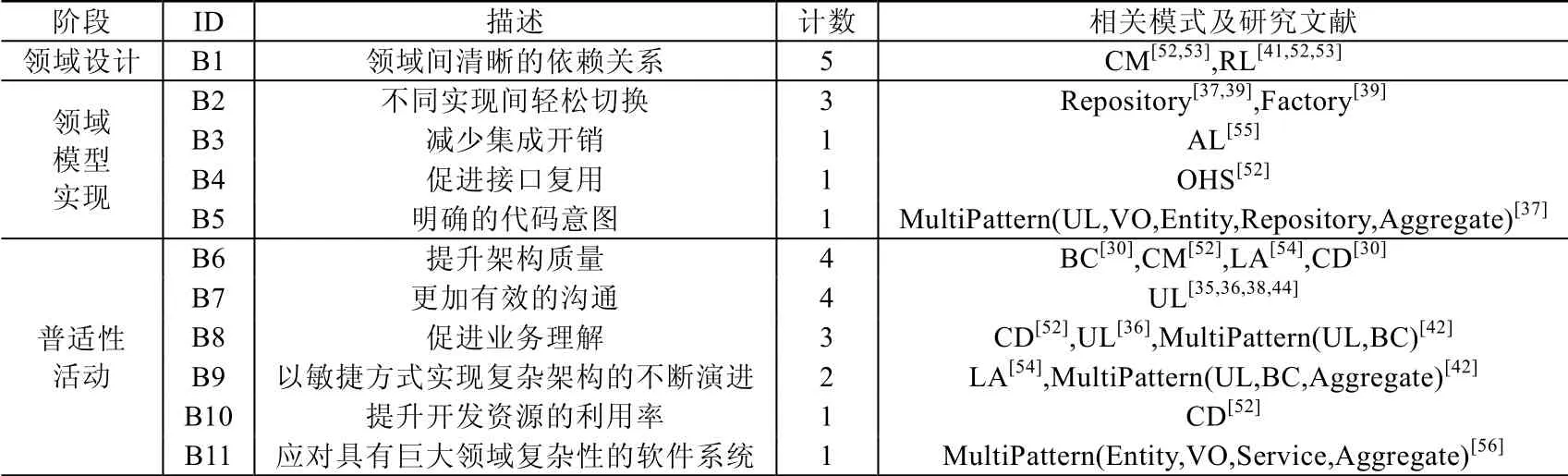
Table 8 Benefits of applying DDD Patterns表8 应用DDDP 所带来的收益
值得注意的是:一些研究文献所提到的显著收益可能来自于其对于多种DDDP 的综合作用,而不是某一种DDDP 的作用.接下来,本文将分阶段讨论应用DDDP 所带来收益的细节.
3.3.1 领域设计
在领域设计中,应用DDDP 的收益在于能够使各个领域之间的依赖关系更加明确(B1).上下文映射(context map)和职责分层(responsibility layer)用于组织系统的不同部分:前者表示不同限界上下文之间的关系,每个上下文表示一个特定的领域;后者则根据领域对象的职责,将它们组织成具有清晰依赖关系的层次结构.借助这些DDDP,我们能够清晰地认识领域之间的关系和依赖.本质上,正如基础研究[53]所宣称的,我们可以利用这些模式了解功能之间的依赖关系.因此在确定系统边界时,不同领域的战术设计知识以及领域之间的关联关系将变得更加明确.理清领域之间的依赖关系还可以帮助开发人员更加深入地了解系统,降低认知复杂性[52],有助于分析系统架构.
3.3.2 领域模型实现
应用DDDP 有助于领域模型的落地实现.比如应用资源库(repository)和工厂(factory)模式分别可以将存储和初始化的复杂逻辑从领域模型中剥离出来[37,39],因此能够改善软件开发的效率,使得开发人员能够在存储和初始化的不同实现方案之间的更加轻松地进行切换(B2).一方面,借助资源库模式,当需要更改系统时,往往只需要更改相关的代码实现,而不必去检查整个对象模型[37];另一方面,工厂模式隐藏了复杂的初始化逻辑,因此可以在不引用具体实现的情况下轻松地切换实现方式[39].
当涉及到限界上下文之间的通信时,防腐层(anticorruption layer)封装了两个上下文之间领域概念的转换,从而避免一个上下文过多地掌握另一上下文的知识.正如基础研究[55]所指出的:通过将领域模型从执行与其他系统相关的任务中解放出来,防腐层允许实践者在不改变领域模型的情况下集成外部系统,从而减少系统集成的开销(B3),这对于需要与遗留系统或第三方系统进行集成的应用程序至关重要.此外,开放主机服务(open-host service)通过一组服务提供了对限界上下文的访问[1],即,将这些服务发布为设计构件.这样一来,接口的重用性(B4)和松耦合得到了极大改善.
让代码意图更明确(B5),也是应用DDDP 带来的一个显著收益.DDD 强调对于模型和实现的绑定,所以在编写代码时需要使用与领域建模过程相同的术语[37],也就是通用语言.这样一来,由于整个团队将通用语言作为相互沟通的基础,能够使代码的业务逻辑将变得更加清晰[37].与此同时,借助于通用语言这种模式,不同涉众之间可以直接基于代码而不是海量的文档进行信息交换,这使得团队的沟通、协作效率大大提升.
3.3.3 普适性活动
应用DDDP 可以提升软件架构的质量属性(B6),如可维护性、可扩展性、可重用性和可测试性等.这一观点在现有研究文献中被广泛认可.首先,限界上下文和上下文映射将一个复杂的领域分解为几个部分,帮助系统实现模块化.文献[52]的经验表明:实现上下文映射可以帮助开发人员对系统产生更深刻的认识,从而进一步改进系统架构;其次,识别和关注核心域(core domain)可以提高资源利用率,从而以更高效的方式改善软件架构;再次,分层架构(layered architecture)能够将领域模型与其他关注点分离开来,有助于探索领域知识,也有助于确保各层之间的高内聚和低耦合[54].
由于DDDP 中的通用语言能够作为团队内部的共享术语来降低沟通中的噪声,所以在设计领域模型和分析代码的过程中,通用语言能够为不同的涉众提供高效的通信方式(B7).正是因此,领域专家的参与度得以大大提升,使得更多高价值的领域业务见解在团队内部分享和传递.更好地理解业务(B8)能够使得软件与其所在的领域保持一致,这也正是领域驱动设计的基本观点[4,29].另一方面,对于领域模型特别是核心域的关注,使开发人员能够更好地理解正在开发的软件和其未来愿景,有助于架构决策的制定,如开发资源的高效利用(B10)和系统级优化.
最后,应用DDDP 能够帮助复杂软件架构以更加敏捷的方式实现演进(B9),并且能够帮助团队应对具有较大领域复杂性的软件系统开发难题(B11).
3.4 应用DDDP所面对的挑战(RQ3)
总结现有研究中对于应用DDDP 所带来的挑战,能够为学术界提供一些未来的研究方向.然而对于实践者而言,其往往更关心应对挑战的策略和方法.尽管我们难以在现有研究中找到应对DDDP 所带来挑战的“银弹”,但研究文献中所提出的一些方法,却能够帮助实践者在一定程度上缓解应对挑战的难度,我们将其称为挑战的缓解方法.在本研究中,我们首先在基础研究中提取了应用DDDP 的17 个挑战,之后,3 位研究者根据所得到的挑战列表和系统文献综述过程所收集的证据,独立抽取并合成应对挑战的缓解方法,经过分析、讨论与整合,最终得到了17 个应对挑战的缓解方法.
表9 列出了在领域分析、领域设计、领域模型实现和普适性活动这些活动中,应用DDDP 可能面临的挑战以及相应的缓解方法.接下来,本文将分阶段对其进行详细介绍.

Table 9 Challenges of applying DDD Patterns表9 应用DDDP 所需要面对的挑战

Table 9 Challenges of applying DDD patterns(Continued)表9 应用DDDP 所需要面对的挑战(续)
3.4.1 领域分析
在领域分析部分,本文发现了一种应用DDDP 的挑战(C1),但是并没有在研究文献中找到能够缓解该挑战的方法,因此在本部分的缓解方法中,本文根据经验总结出了两条应对建议.
•挑战
领域驱动设计及模式致力于帮助开发组织深入理解软件的业务领域,以便在系统开发中充分发挥创造力[39].为了更加深入地了解相关领域,无论是形成统一语言还是确定限界上下文和核心域,都强调领域专家与开发人员之间的紧密协作.然而,让领域专家参与领域驱动设计实践并非易事(C1),这成为了阻碍DDDP 成功应用的一个主要障碍,特别是在所开发的软件系统非常复杂,需要不同领域的多个领域专家共同参与的情况下.Vernon[4]也认同了这一观点,他认为:让领域专家参与软件开发过程,一直以来都十分困难.
•缓解方法
在本研究所搜集的基础研究文献中,并没有针对领域分析阶段所遇到的C1 提出任何解决方案.显然,C1 更像是一个组织问题,而不是技术问题.结合Vernon[4]的观点,我们为应对C1 提供了两条建议:①如果软件开发组织决定应用领域驱动设计,那么就应该充分认识领域专家的重要性;②领域专家指的不是一个职位,而指的是非常了解业务线的人,因此,领域专家可能是销售人员,也可能是产品设计师[4].
3.4.2 领域设计
在领域设计部分,本文发现了8 种应用DDDP 所带来的挑战(即C2~C9),并且对于其中除了C3,C4 和C7 之外的5 项挑战都发现了一些对应的缓解方法(M1~M12).
•挑战
通过引入限界上下文模式,可以将复杂软件系统拆分为不同部分,拆分后的每个部分都可以独立建立具有清晰边界的领域模型.正如Newman[8]所建议的:借助限界上下文将相关业务功能组合为业务能力,以此来确定微服务粒度.这一方法已被软件开发社区广泛接受[51].然而对于限界上下文本身的粒度,DDD 并没有提供任何有助于实现高内聚、低耦合(C2)的指导方法.近期的一项相关研究[59]证实了这一挑战,该工作宣称:使用限界上下文对软件系统进行拆分是非常困难的,因为不同业务功能之间的界限通常并不明显.
将一个领域拆分为多个子域之后,应首先识别出系统中最具决定性的子域,即核心域,并侧重对核心域的投入,以实现收益最大化[4].但在实际中,对开发人员而言,识别系统的核心域往往非常困难(C3),尤其是在开发大型系统时.此外,基础研究[52]还发现,在实践中可能会同时存在多个核心域,因此进一步加剧了这一挑战.
在每个限界上下文内应用战术设计模式主要面临两个挑战:其一,确定聚合的粒度非常困难(C4),这需要在执行单个事务的成本和强一致性两者之间取得平衡[58];其二,使用分层架构(layered architecture)将领域模型与其他模块进行对应时,DDDP 中并未对领域层之外的其他层,如用户界面层、应用程序层和基础设施层等,提供任何相关规范(C5)[1].本质上讲,领域驱动设计强调使用领域模型来展示领域的功能视图,但并没有考虑其他方面[30].然而,这种对领域层之外规范的缺失,将会为实践者带来一定的困扰.
在模型中表达领域知识时,Evans[1]强调可以利用各种媒介进行沟通(不仅是UML[31])来最大化模型表达的效率.但这就带来了另一项挑战,即,领域驱动设计缺乏对模型的形式化表达的支持(C6).文献[44]指出:DDD 的定义不仅缺少形式化基础,还在某些情况下具有不同的表达方式.在应用微服务架构构建应用程序时,领域模型将分散在不同团队中,因此具有相同语义的领域对象可能会在不同团队中独立演变,从而变得完全不同.这样一来,很可能使得不同团队对相同的领域概念产生不同的理解[47].
在基础研究文献中还提到了其他的一些挑战,如基础研究[46]所描述的,领域模型的建模过程需要领域专家的参与,但却无法保证领域专家能够理解建模过程中使用的全部技术(C7),这对于通用语言的实践造成了一定困难.此外,当前的建模工具还不能完全适用于领域驱动设计(C8).最后一点,虽然DDD 提供了多种模式,但是领域模型的复杂度依然会影响模型本身的可理解性(C9).
•缓解方法
为了确定限界上下文的合理粒度(C2),多个研究文献给出了相关建议.首先,文献[30,44]认为,应该考虑团队的组织结构.其次,文献[41]建议找到职责的边界,并将其作为该领域的业务功能.文献[49]建议通过分析用例的工作流将相关功能聚集在一起,并将其划分为不同的领域,也就是限界上下文;此外,通过将领域专家和开发人员召集在一起来讨论业务领域的事件风暴[60],也是一种行之有效的重要手段.通常而言,限界上下文往往需要经过多次迭代才能够最终确定,根据文献[42]的经验,比较来自于不同团队的领域模型,有利于使领域边界更清晰.
为了应对微服务场景中的C5,也就是领域驱动设计在其他层中没有提供任何规范这一挑战,需要添加其他工件来弥补规范的缺失[30].根据Fairbanks[61]的建议,在决定向系统中增加新的工件时,需要仔细考虑项目中存在的风险.例如:当使用DDD 构建基于微服务的Web 应用程序时,文献[30]根据用户体验设计的指导原则来定义用户界面和交互,根据行为驱动开发(behavior-driven development)来确定应用层的需求,并使用Spring 框架搭建基础设施层.
为了使建模语言更加形式化(C6),基于在领域驱动设计中应用UML 元素情况的调研,文献[44]定义了一种用于建模的UML 配置文件(profile),并充分考虑到了各元素的语法和语义.应用这种UML 配置文件的案例表明,其能够将基于这种配置建模的领域模型映射到微服务中.文献[48]的研究工作进一步验证了这种UML 配置文件的有效性.除此之外,本体论是一种在特定领域中描述语义的方法,其能够对系统结构进行形式化建模,比如实体和关系等[62].基于本体论,基础研究[47]提出了一种表达领域模型语义及关系的元模型,以此来确保整个团队对分布式领域驱动微服务设计中的相关领域概念具有相同的理解.
对于建模工具(C8)而言,文献[44]在Eclipse 和Papyrus 建模环境的基础上实现了UML 配置文件;文献[56]在Eclipse 平台上开发了Elihu 项目,能够对于领域对象相关的应用功能进行建模,而无需考虑基础设施方面的问题.此外,文献[48]建议使用另一个基于Eclipse 的工具——AjiL 来实现微服务的图形化建模.AjiL 能够通过建模得到初步的领域模型,并通过代码生成器将模型转化为微服务的具体实现.
对于模型复杂度(C9)而言,概念架构视图[9]被引入并用于将模型拆分为多个领域视图.这样一来,建模者能够从不同视图进行领域建模,而其中每个视图都代表了特定涉众的观点.
3.4.3 领域模型实现
在领域模型实现部分,本文发现了5 种应用DDDP 的挑战(即C10~C14),并且对于其中的C12 和C13 寻找到了对应的缓解方法(M13,M14).
•挑战
本研究发现:在领域模型的实现过程中,防腐层(anticorruption layer)与服务(service)的实现复杂度较高(对应C10 与C11).对前者而言,文献[41]提到,实现防腐层的最大挑战在于控制转换复杂度,也就是开发人员必须充分理解两个限界上下文及其关联;而对后者而言,文献[43]指出,应确定服务的粒度来确保能够提供合理的对相关领域的访问.由于DDD 主要关注领域模型,并没有对服务实现给出详细指导,因此为实现过程造成了一定的困难.
此外,由于DDD 侧重于业务领域而非技术领域,这也带来了两项挑战.
•第一,DDD 中的领域模型没有指定后续的实现规范(C12).举例而言,领域对象的属性可能是无类型的,或者缺少具体的行为方法[48].但是这类信息对于后续实现而言往往是必要的,而由于这类信息的缺失,使得从模型清晰地推断出技术特性变得非常困难;
•第二,领域模型并不包含基础组件或部署视图中的基础设施(C13),但这类视图或组件信息有时会在很大程度上影响软件系统,特别是在微服务场景中.因此,这类信息需要使用文档加以记录来作为对模型的补充.
模型驱动开发(model-driven development)能够提高领域模型到代码转化的效率,在DDD 中得到了较广泛的应用.然而,即使在将领域模型正确转换为代码之后,由于领域建模过程的不断迭代,仍然有可能需要重复这一过程.因此,模型到代码转换的自动化(C14)十分必要.而为了使得模型与代码始终保持一致,则需要在建模的每个迭代过程中持续地关注各个领域元素[1].尽管在DDD 中引入了模型驱动设计,但如何在模型的细化过程中保证代码和模型的一致性[44],仍然是一个难题.
•缓解方法
建模规约(convention)[48]意味着为建模过程设置需要遵守的规则.建模规约通过为领域模型赋予更多形式化内容,来应对DDD 中领域模型缺乏实现规范的挑战(C12).文献[48]中提供了一些规则示例,比如在建模时禁止双向关联、事先规定引入微服务接口的DDDP 等.针对领域模型中缺少基础组件的情况(C13),文献[48]建议利用来自模型驱动开发[63]的中间模型来表示技术特性,如接口模型和部署模型等.前者用于对服务接口进行建模,后者用于对可部署工件进行建模.这些中间模型能够展示特定角度的技术特性,有助于接口类型和部署技术的进一步实现.
3.4.4 普适性活动
在普适性活动部分,本文发现了3 种应用DDDP 的挑战(即C15~C17),并且对于其中的每个挑战寻找到了对应的缓解方法(M15~M17).
•挑战
文献[37]提到:在形成通用语言的过程中,由于不同涉众使用的语言不同,往往难以对于同一术语形成统一认识(C15).这使得团队在沟通过程中可能会产生误解,想要定义通用语言往往需要付出更多的努力.
领域模型的获取与变更管理,是应用DDDP 的另一项挑战.Vernon[4]建议由单个团队来开发和维护一个限界上下文及其对应的模型.但是,管理不同团队对领域模型的权限也会遇到挑战(C16),因此必须确定团队对领域模型的权限范围.此外,是否允许团队更改其他团队的领域模型也很重要.以上决策将直接影响到模型的变更情况[38].比如:如果允许团队更改其他团队的限界上下文,服务之间的依赖会变得更加复杂.因此,应该权衡每个决策所带来的损失和收益,从而做出最终决策.
最后,C17 与应用DDDP 进行软件开发的过程相关.领域驱动设计的核心原则是,使应用程序与领域模型保持一致.正是这一特点,使得领域驱动设计区别于其他传统的软件开发方法[1].然而,虽然这一方法目前已经被广泛接受,但是其对于如何在系统性软件开发过程应用DDDP 并没有提供详细描述[30].这使得应用领域驱动设计的活动变得模糊不清,成为实践者们面临的主要挑战,从而影响了适用性.
•缓解方法
解决C15[37]的一种途径在于聚焦于信息架构[64],并在沟通中使用统一定义的术语(通用语言).为了提供对模型访问和变更管理的支持(C16),文献[48]论述了在分布式微服务开发背景下架构决策的优缺点,包括完全模型访问和部分模型访问,并提倡采用明确的策略来规范模型管理.为了应对C17,文献[30]初步确定了DDD 开发活动集,并与需求确定和分析、设计和实现以及测试[31]等传统软件开发活动保持一致.
4 讨论
本节综合了基础研究文献中关于应用领域驱动设计模式的现有证据,对于应用DDDP 所面对的3 个问题进行了讨论,包括应选择战术设计还是战略设计、存在哪些机遇以及如何应对挑战.
4.1 战略设计与战术设计
在DDDP 中,从战略设计和战术设计角度分别提供了一系列方法.战略设计更关注业务的宏观战略方向[4],而战术设计则聚焦于特定领域模型.本研究发现:相比于战术设计,在DDD 社区中,实践者更趋向于应用战略设计(18.2%VS.45.5%).这可能是由于:对于企业而言,软件系统的战略设计决策更具有影响力.举例而言:战略设计能够降低分析软件架构时的认知复杂度,并能够促进系统的组件化.
需要强调的是:实践者不应只关注战术设计,而忽略战略设计.过分专注于技术层面可能会导致领域对象之间的细微差异被忽略,从而导致模型的错误融合,甚至会使系统变成大泥球(big ball of mud)[4].Millett 和Tune[5]认为,这正是许多应用DDD 的项目失败的原因.因此,本文建议实践者应该同时兼顾战略设计和战术设计,同时,根据自身业务场景来权衡战略性设计和战术设计的使用.
4.2 存在的机遇
现有经验证据(empirical evidence)证明了DDDP 在软件开发实践中的实际应用价值.然而,在目前的基础研究文献中,仅有10 种DDDP 被明确指出对软件开发有所帮助,而其他模式的实际价值还缺少相关证据的支持.
此外,诸如CQRS(command query responsibility segregation,命令查询的责任分离)[65]等DDDP 的新兴模式经过社区的发展已经日趋成熟,但由于这些模式并未包含在Evans 在2014年所提出模式列表中,因此学术界目前还缺少相应的研究工作.本文关注的基础研究文献中也缺少对这些模式的相关证据.
需要注意的是:虽然DDDP 是领域驱动设计标准化设计的重要内容[1],但对于DDD 而言,深入理解领域知识、迭代建模、统一模型与实现等整体愿景更为关键[1].为了实现以上愿景往往需要综合应用多种DDDP,同时也需要保持团队组织形式与软件设计理念的一致性.
虽然应用DDDP 可以为软件开发带来良好的效果,但从现有研究来看,它对其他方面的帮助并不明显.一方面,DDD 强调开发人员和领域专家及其他涉众的协作,那么应用DDDP 来改善团队组织结构似乎是合理的,比如上下文映射能够明确地展示不同组织之间的动态关系,因此它可能适用于组织大型软件项目的开发工作;另一方面,Vernon[4]认为,应用DDD 可能会使软件过程的治理问题暴露出来.总的来说,现有研究缺乏对DDDP 的这些方面的讨论,DDDP 在这些方面的具体作用仍需要更多的实证研究来验证.
4.3 应对挑战
正如Vernon[4]所说的,使用DDD 时仍需要面对诸多挑战.在本研究的统计数据中,与挑战相关的数据的来源研究文献比较集中,这表明在目前的学术界研究中,还没有对于应用DDDP 所面对的挑战达成一致共识.这可能是因为现有的大多数研究工作所关注的主题都比较分散.我们推测:随着DDD 研究的不断深入,社区将对于应用DDDP 所面临的挑战逐渐会达成共识.
经过聚合分析[28],可以将本文所报告的应用DDDP 所面对的挑战划分整理成4 种类型,见表10.
•建模本身的复杂性:C2~C4,C10,C11.建模是软件设计的一项重要活动,它决定了子系统的结构、接口、对象等.例如,C2 就与子系统结构的决策相关.设计决策是软件设计的基础,因此也存在许多相关研究,比如文献[66−69].尽管这些挑战背后的设计决策具有一定的特殊性,但一些观点仍然可以为实践者提供参考.比如在决策过程中,理性分析和主观经验都需要得到重视[27].具体而言,前者是根据预先定义的标准对备选决策进行评估和选择,比如应用DDD 战术设计模式进行实体与值对象的划分时就需要理性分析;而后者则是根据经验形成令人满意的解决方案,比如在应用DDD 战略设计模式来划分限界上下文时,无法完全脱离设计者的主观经验.因此,本文建议实践者在应对建模问题时既要进行理性决策,也要采纳一些合理的主观经验;
•理解领域的困难:C1,C7,C9,C15.领域驱动设计要求在建模时与领域专家进行紧密配合[1],然而在具体实践中,想要让领域专家持续地参与建模过程并非易事,这需要软件开发组织为领域专家增加一笔额外的开销[4].此外,即使有领域专家的参与,开发团队仍需要面对与领域专家进行沟通(如C7 和C15)和领域认知(C9)方面所存在的挑战.本文建议实践者增加对于理解领域这一过程的投入,并应用一些创新方法,如尝试从多个角度(M12)来管理复杂性;
•对于除领域外的其他方面关注过少:C5,C12,C13.这些挑战的重点在于,DDD 强调通过关注业务领域的建模来解决软件开发的复杂性问题,因此,DDDP 也主要涉及建模方面,而缺少对其他方面(比如实现)的明确指导.上述挑战可以通过补充工件或更加完善的规范来解决,比如领域层之外的工件(M6)和来自MDD 的中间模型(M14)等;
•DDD 理论的成熟度欠佳:C6,C8,C14,C16,C17.无论是通用语言还是战略和战术设计模式,都是DDD 所提供的抽象指导,实践者仍然缺乏应用这些DDDP 进行软件开发所需要的工具、方法以及过程管理等成熟能力.因此,在DDD 领域未来的研究工作中,可以考虑通过提出创新性解决方案(如M7)或者参考其他软件工程社区中已有方法(如M17),为将DDDP 规范化地应用于软件开发过程提供更完善的支持.

Table 10 Classification of the challenges of applying DDD patterns表10 应用DDDP 的挑战分类
为便于理解,本文将这4 类挑战对应到领域驱动设计方法及其模式在软件开发中扮演的角色,如图7所示.

Fig.7 Relation ship between four categories of challenges图7 4 类挑战的关系
作为一种软件设计方法,领域驱动设计旨在加速具有复杂领域逻辑的软件项目开发[1].领域驱动设计利用一系列DDDP 从领域逻辑中抽象领域模型的过程,从本质上看,可以理解为用户应用软件的领域(即问题空间)到可运行的软件(即解空间)之间的映射和转换.这个过程大体上可以分为两个阶段:对问题空间的理解和基于对问题空间的理解设计解空间.相应地,应用DDDP 面临着理解问题空间时“理解领域的困难”挑战以及基于对问题空间的理解设计解空间时“建模本身的复杂性”挑战.另外,这个过程还面临着“DDD 理论的成熟度欠佳”挑战.由于软件开发除领域逻辑外还需解决技术等其他难题,在实际软件项目开发中落地DDDP 还面临着“对于除领域外的其他方面关注较少”挑战.
对于应对实践DDDP 时所面临挑战的缓解方法而言,既有积极的一面,也有消极的一面.
•在积极的一面,这些缓解方法代表了实践者为应对DDDP 所带来的挑战而做的努力:首先,一些缓解方法代表了DDD 实践者当前的最佳实践,比如利用事件风暴(event storming)来探索领域(M4)和建模规约(modeling conventions)(M13);其次,为了更好地应用DDDP,领域驱动设计的实践者们付出大量努力,包括提出UML 配置文件(M7)和元模型(M8)等解决方案;最后,一些缓解方法中展现了从其他方法论中借鉴来的智慧,如中间模型(M14)和领域视图(M12)等;
•在消极的一面,DDDP 的应用中仍然存在很多问题:首先,尽管针对C6 的缓解方法,也就是UML 配置文件(M7)和元模型(M8)具有一定效果,但它们违背了Evans 的初衷[30],具体而言,虽然M7 和M8 可以在一定程度上使领域模型标准化,并减少歧义,但由于它们增加了更多的规则约束,所以也降低建模过程的创造性;除此之外,一些缓解方法仅仅根据案例研究进行了评估,还缺少进一步的验证,比如C8 的建模工具和软件开发过程概览(M17);最后,一些缓解方法本身并不容易实施,因为这些方法既没有给出系统性的指导,也没有给出具体实施的提示.
4.4 对研究者的启示
在目前关于DDDP 的学术研究中,已发表研究文献的主要关注点是对DDDP 详细内容的完善和在软件项目中应用DDDP 两类,主要贡献也集中于提出新的方法或者总结应用DDDP 的实践经验.然而,在软件工程中是“没有银弹”的,任何理论方法都会存在一定的局限性和缺点,DDDP 也是如此.相比于已经广泛应用DDD 理论的软件工业界而言,对于DDDP 应用的反思,在学术研究文献中还比较少见.
此外,DDD 应用实践时除了需要掌握以领域为中心的思考方式之外,还应该能够熟练地掌握正确应用包括战略和战术设计方面在内的各种DDDP.然而,相关研究文献以及著作中所论述的DDDP 应用策略都比较抽象,这使得在实际情况下应用DDDP 还缺少系统性的指导方法和良好实践,DDDP 的应用在很大程度上仍依赖于主观经验.因此,未来研究者可以考虑细化应用DDDP 的指导方法,并提出或总结更多可供参考的良好实践.
5 效度威胁讨论
本系统文献综述的工作中存在的效度威胁来源于文献筛选、数据抽取及数据合成过程中可能存在的偏见.
为了消除检索字符串及数据库选择中存在的偏见,我们在自动检索之前进行了手动检索并确保:①手动检索中出现的每个DDD 同义词都已被合并到检索字符串中;②手动检索获得的每篇文献都包含在自动检索结果集合中.之后,我们通过滚雪球过程对于每个DDDP 所执行的单独自动检索结果进行补充.此外,本研究还预定义了一个已知的论文集合,以检查检索过程的全面性和准确性.为了避免文献筛选出现错误,每篇文献均由至少两名作者独立筛选与评估,然后通过二次审核过程进行合并.在这个过程中,我们使用了Kappa 分析确保足够的可靠性[18].
在数据抽取与合成部分,效度威胁主要源于抽取过程中可能遗漏了有价值的文本数据,从而导致合成过程得出不准确的结论.为了避免遗漏有价值的文本数据,本研究在进行数据抽取过程之前先进行了小规模实验,并按照作者的理解对数据抽取形式进行了调整.基于实验调整后的数据项形式,两名作者独立地对每篇研究文献进行数据抽取,并在最后进行合并.为了减少数据合成过程中得出的不准确的结论,作者们首先对DDD 相关书籍[1,4,18,70−72]进行学习和探讨,从而熟悉DDD 社区.之后,两名作者独立进行编码过程,并与第三名作者协商解决这一过程中存在的冲突或疑问.同时,在本研究中通过对于编码结果的两次复核,保证了对结果的改进.
6 总结与展望
本文面向领域驱动设计模式这一主题进行了系统文献综述,通过对2003年~2019年7月的研究文献进行识别、检索、筛选和分析,最终综合26 篇高质量基础研究来回答所本文所提出的研究问题.本文提供了学术界对于DDDP 应用的研究现状概览,同时比较全面地综述了基础研究中应用DDDP 带来的收益、挑战以及应对挑战的缓解方法.
一方面,本文的研究表明:由于重视领域知识,实践者往往能够借助DDDP 设计出良好的软件,并享受到其所带来的收益,如架构质量改善和代码意图清晰.另一方面,本文的数据综合结果表明:46.4%的基础研究认为在DDDP 的实践中存在很多困难,并将其总结为17 个挑战.本研究中还发现了17 种缓解方法,用于应对上述提到的部分挑战.虽然这些缓解方法还不足以完美地支撑DDDP 的应用实践,但是它们代表了实践者所付出的努力.正是这些该领域的理论和研究的不完善之处,为研究者和实践者们提供了更加广阔的探索空间.
目前,应用领域驱动设计模式在实践中的价值得到了比较广泛的认可,但对于如何更好地享受其所带来的收益,以及更加合理地应对其带来的挑战,则需要研究者进一步探索.与此同时,在软件工程中,没有任何一种技术能够称为“银弹”,因此,应用各种DDDP 所带来的局限或者挑战,仍需要未来进一步探索和反思.
猜你喜欢
交通科技与管理(2021年5期)2021-06-13
专利代理(2016年1期)2016-05-17
铁路通信信号工程技术(2015年4期)2015-02-28
城市轨道交通研究(2015年5期)2015-02-27
当代体育·扣篮(2014年8期)2014-05-23
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
