
基于图模式的犯罪情报数据集挖掘算法
2021-11-09 13:30:22唐德权史伟奇刘绪崇
中国人民公安大学学报(自然科学版) 2021年3期
唐德权, 史伟奇, 刘绪崇
(湖南警察学院信息技术系, 湖南长沙 410138)
0 引言
图是表示复杂数据的常用方法,挖掘重复子图有许多应用,如在化学信息、生物信息、高效存储半结构化数据库、高效索引和web信息管理领域模式发现[1]。在图数据库中如何高效挖掘处理大量重复出现的模式,基于不同的需求和期望找出频繁子图是目前图模式挖掘研究的一个重要问题。例如,为了应对挖掘大型网络中的集团的挑战,Shahrivari等人[2]提出了基于状态空间搜索的完全适合MapReduce框架的解决方案KCminer。大多数现有的带标记网络社团检测算法都是为了给网络提供一个固定分区,其中任何节点都应该属于一个社团。为了改进已有的聚类算法,Qi等人[3]提出了一种新的有符号网络聚类方法,即有符号真子团合并算法SQCM,该算法对网络中的重叠社区推断出某个节点属于哪些社区,并随机得到一个聚类,但聚类数量不能确定,因此SQCM不能精确计算子团结构,但是面临频繁子模式的总数量以指数形式增长,这些方法通常不能高效应对图数据集挖掘。
由于图能表示犯罪情报数据复杂结构,如何在图数据集中挖掘频率较高“公共子结构”已经成为警务数据挖掘研究领域重要问题之一[4]。针对犯罪情报数据集的特点和频繁子模式挖掘所面临的挑战[5],本文提出了一种基于k个顶点类的频繁模式挖掘算法,简称为k-频繁模式挖掘算法。该算法有效挖掘k-频繁模式,首先将图数据集预处理找出k个顶点的频繁子图类,然后找出其所有生成子图,最后挖掘频繁模式,算法的总时间复杂度为O(2nT4logTk2),其中n为图的顶点数,T为图数据集大小,k为频繁子结构图顶点个数(2≤k≤n)。通过真实平台数据集实验表明,该算法能根据嫌疑人员的特点高效的挖掘关联模式和规律,为靶向推进个案、类案精准侦办和处置提供决策依据。
1 定义、记号与问题描述
标签图G是一个无向连通图,定义为4元组G=(V,E,Σ,l),其中V是图G的顶点集,E⊆V×V是图G的边集,Σ是由数字或字母组成的具有偏序关系的标号集,l是顶点和边到标号集的映射函数,即l:V∪E→Σ。具有T个标签图组成的数据集称为标签图数据集,记为GD={G1,G2,…,GT},数据集GD的大小为T,记为|GD|=T。
如果一个标签图G=(V,E,L,l)与另一个图G′=(V′,E′,L′,l′)同构,则f:V(G)→V(G′),且同时满足:
(1)∀u∈V,l(u)=l′(f(u));
(2)∀u,v∈V,(u,v)∈E≡(f(u),f(v))∈E′;
(3)∀(u,v)∈E,l(u,v)=l′(f(u),f(v))。
给定任意两个图G′和G,如果图G′到图G的某个子图存在同构映射函数f,那么称G′与G子图同构。
对于图数据集GD,其中与图G同构子图的个数与图数据集GD中所有图的数量的比值称为图G的支持度,记为σG。
设定最小支持度阈值为Min_σ,如果图G的支持度大于或等于最小支持度(σG≥Min_σ),那么图G称为频繁图或频繁子图[6]。
在图数据集GD中,含有k个顶点的生成子图且是连通子图,称为k-子图。一个k-子图或者去掉若干边后的连通子图是GD的频繁子图,则称为k-频繁子图。含有k个顶点的所有子图的集合记为Gk,定义为:
Gk={g=〈Vk,Ek〉∈GD,Vk={v1,v2,…,vk}⊆V,Ek={(vi,vj)/vi,vj∈Vk}是Vk中顶点形成的边}
在犯罪情报图数据集中,k个顶点的子图,表示k个犯罪实体或人员的关联关系。本文研究犯罪情报图数据集中所有k-频繁子结构的获取问题,即为k-频繁子图挖掘。具体描述如下:
输入:一个大小为T的图数据集GD={G1,G2,…,GT},最小支持度为Min_σ,给定子结构顶点数为k。
输出:图数据集中的所有k-频繁子图。
2 k-频繁子图挖掘算法
2.1 图数据集预处理
本文的犯罪情报关联图集中顶点表示嫌疑人员,边表示两个嫌疑人员之间的联系,边的标签表示联系类型,联系类型根据嫌疑人之间的通话(x)、同住宿(y)、同上网(z)等联系途径设定,由若干顶点和连接顶点的边构成的图数据结构,用图模式表示嫌疑人员关联是一种直观的表示方法。k-子图包含k个顶点的子图,表示k个嫌疑人员的关联,图模式不仅表示人员拓扑信息,图上的每条边标签表示人员联系方式类型[7]。在进行k-频繁子图模式挖掘前,首先对原始图数据集进行预处理得到图数据集,犯罪情报数据集的数据来源如图1所示。
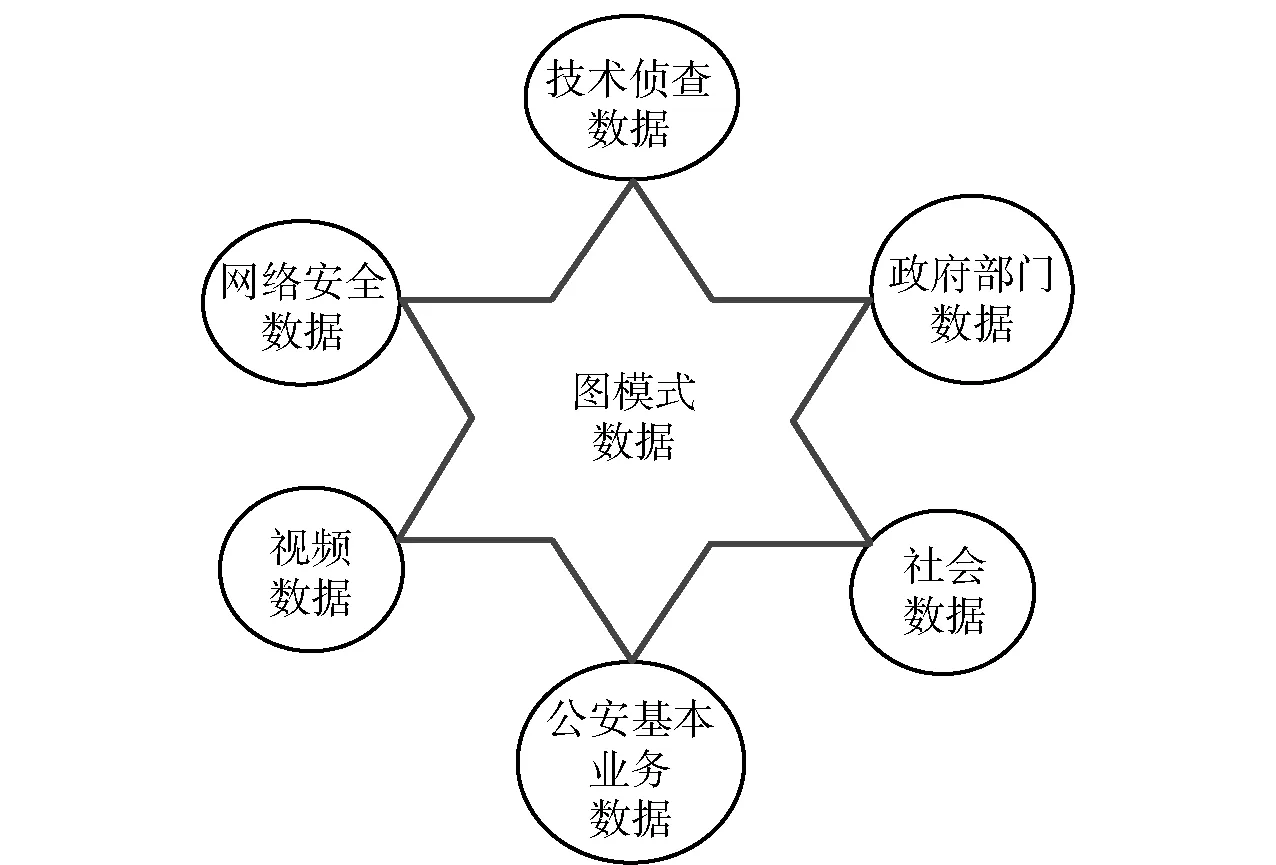
图1 图模式数据集来源
传统的人际关系应用模型中社会关系网络由多个节点和关系构成的人际圈子,其中的人际关系构成了一个简单的无向网络图。与现实世界社会关系网络比较而言,传统的模型过于简单,不能真实地反映现实世界的复杂关系情况,同时,传统的应用模型在节点关系亲疏度管理机制上存在不足,无法拓展犯罪情报数据平台的创新应用。本文提出的图模型基于现实世界人际关系,体现双向关系的图模型,如图2所示。
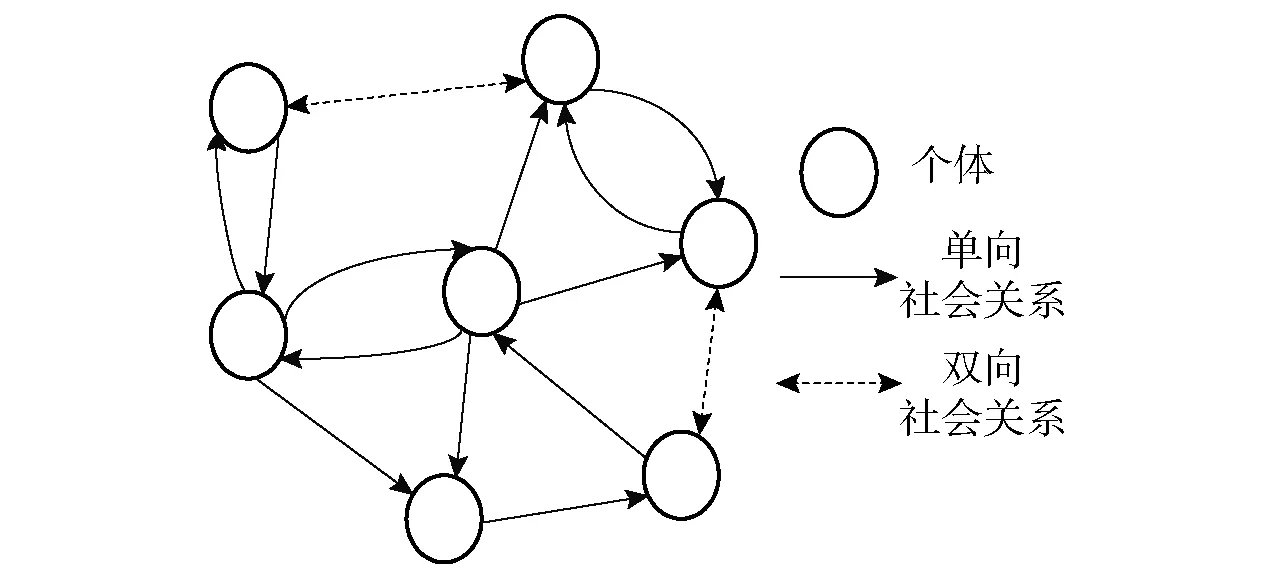
图2 图模型
2.2 求Gk类的k-子图算法
对犯罪情报数据集建立了图模型以后,本文的主要任务是基于图模式情报数据集挖掘重点人员或核心组织,这也是实现智慧警务风险排查管控功能中的重点人员管控功能的关键技术。风险排查管控主要是以人的管控为核心,只要管住了人,也就管住了重点场所、重点车辆、重点企业、重点组织、重点案事件。下面主要介绍挖掘重点k类人员的算法。
算法1. 求Gk类的k-子图
输入:图数据集GD,|GD|=T。
输出:所有k-子图。
(1)从k=2~n,找出具有k个顶点子图类Gk;
(2)从G2~Gn,对每一类图Gk找出所有k-顶点生成子图g;
(3)按所有生成子图的边数从小到大进行排序Gk={g1,g2,…,gT};
(4)GD′={Gk}+GD′;
(5)输出GD′={G2,G3,…,Gn};
(6)结束
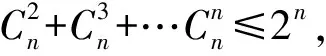
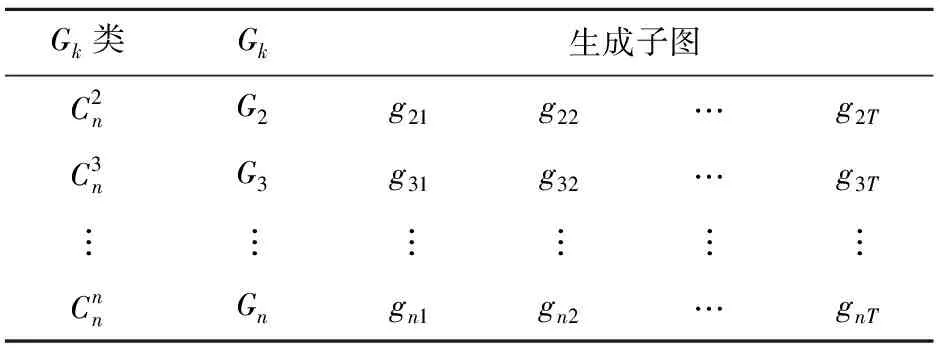
表1 Gk与g的数量关系
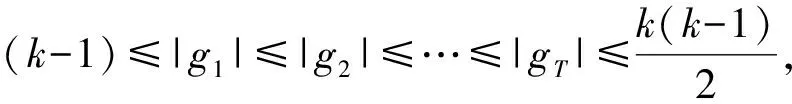
2.3 有效得到k-频繁子图
求出所有生成k-子图以后,根据k-频繁子图定义,下面求出一个k-子图或者去掉若干边后的连通子图是否为频繁子图。
算法2. 挖掘k-频繁子图
输入:图数据集GD′,最小支持度阈值Min_σ。
输出:k-频繁子图
(1)k=2 ton, 对GD′中的每个Gk:
(2)Gk={g1,g2,…,gT}
(3)i=1 toT
(4)以gi为模式图,从gi+1到gT进行子图同构测试;
(5)如果gi的支持度大于或等于Min_σ,则gi为k-频繁子图;
(6)Fk=gi∪Fk;
(7)重复第1步和第6步,直到输出所有Gk的频繁子图F={F2,F3,…Fn};
(8)输出F,算法结束。
重点人员动态管控以支撑情报部门动态研判和民警动态管控为出发点,以“一人一档”的方式,整合资源建立反映重点人员动态管控全过程的“电子档案库”,集中展现重点人员的基础信息、动态信息、管控信息、现实表现信息、积分信息、关系人信息、关联信息、文本情报信息、人工研判信息、流程控制等信息,清楚地体现研判过程,直观、准确地展现出重点人员在不同时间节点、不同地域范围的行为轨迹、活动规律和可能异常动向,有效筛选违法犯罪嫌疑度高和对社会稳定危害性大的重点人员,以便采取针对性的分类管控措施,提高重点人员积分预警的科学性、高效性,满足重点人员积分升降、颜色变化的要求。图3表示挖掘结果有4个重点人员电话联系子图,上面的实体人员有姓名和证号信息,下面有电话号码信息,图中的权重数字表示重点人员联系的频率。

图3 电话联系类4-子图
为了减少重复的子图,尽快使算法收敛,提高算法效率,提出了下面定理。
定理1算法2中计算Gk中k-子图的支持度具有向下闭合性质。
证明:由算法1的第5步可知,将所有生成子图按边数从小到大进行排序|g1|≤|g2|≤…≤|gT|。 又知所有生成子图的顶点数相同为k,g1~gT,小的模式是大的模式的子模式;gT~g1,大的模式是小模式的超集。 若子图g与某一大的模式没有同构子图,则与小的频繁模式中肯定没有同构子图,定理得证。
根据定理1,可以对算法2的第4步子图同构测试进行优化,在计算Gk每个子图g支持度的过程中不断对搜索空间进行有效的剪枝。
3 实验分析
本文采用的实验环境为单机Intel(R) Core(TM) i7-5600 2.6 GHz CPU, G内存,500 GB硬盘,Windows 10 Professional操作系统,所有算法使用C++语言实现,G++编译器编译通过。由于未见挖掘k-频繁模式的相关算法,主要是通过不同顶点规模及不同参数条件下验证理论分析的结果及算法执行的效率。
本文数据来源“神鹰”平台数据集,该平台以公安大数据中心为基座,融合公安经济侦查信息库、公安内部信息库、社会行业信息库、互联网信息库等资源库,汇集公安内网数据1 008类1 104亿条、公安外网数据37类5亿余条,建设了与税务、市场监管、公共资源交易等部门的数据专线。本文算法实验数据集从中提取了与公安业务相关的9大类犯罪模型,共53个顶点数据标签,按数据集来源将其分为内网数据集(Intranet datasets)和外网数据集(Extranet datasets),分别包含320和410个图的数据集。
算法结合了“云”计算技术,对大数据进行高性能处理,对资源检索目标达到秒级。通过“云”计算技术,内置图模式数据挖掘算法、统计分析工具,实现对海量的信息服务资源的横向关联、毫秒查询、批量比对,满足于各专业警种的应用。
先验证在最小支持度阈值Min_σ从10~100变化的情况下,本文算法在两个数据集上的运行时间。从图4中可以看出,当最小支持度阈值由小增大其运行时间效率显著提升,这是因为随着支持度的增大,算法输出的k-频繁模式数量急剧减少,图数据集预处理的时间减少了。图5是显示k值与算法运行运行时间关系,从图中可以看出,在两个数据集上k的大小对算法运行时间的影响,最小支持度阈值Min_σ=50%的条件下,随着k的不断增大,算法运行时间速度会有很大提升,这是因为随着k值增大,输出的k个顶点的频繁模式数量会减少。

图4 运行时间与支持度阈值关系

图5 运行时间与k的关系
为了进一步验证提出的CGMA算法的有效性,在实际数据集上取p=10,与本文挖掘目标相近的PageRank算法[8]进行了比较,图6显示在不同k值下CGMA算法和PageRank算法的性能比较,结果可以看出在几乎所有情况下本文算法都比PageRank算法运算速度快。

图6 算法比较
最后根据情报关联性,从实验结果的k-频繁模式中总共输出2 360条关联规则,其中满足用户阈值的有337条,为监测预警、犯罪形势分析报告、行业风险评估报告、维稳形势分析报告等提供依据,为制定防范化解金融风险对策、打击经济犯罪提供参考。
4 结语
本文研究了如何在图模式情报数据集找出k-频繁模式问题,提出了一种高效挖掘k顶点频繁子模式挖掘算法,通过确定k个顶点的生成子模式快速得到k-频繁模式,解决了犯罪情报数据集包含子模式空间大且难于挖掘的问题。通过在犯罪情报两个数据集上实验研究,结果表明本文提出的算法能够高效地从图模式犯罪情报数据集中找出k-频繁模式,可为今后如何利用图模式挖掘研究犯罪嫌疑人员的关联规律提供有力支持。
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:49:18
现代装饰(2022年4期)2022-08-31 01:42:30
现代装饰(2022年3期)2022-07-05 05:59:04
中等数学(2021年9期)2021-11-22 08:06:58
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
山东科学(2018年6期)2018-12-20 11:08:58
电子科技大学学报(2016年2期)2016-08-31 02:50:00
小天使·一年级语数英综合(2015年10期)2015-10-14 06:37:12
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:50
采矿技术(2011年5期)2011-11-15 02:53:12
