
一种融合多模态特征的视频暴力检测方法
2021-11-08 02:19马境远傅慧源
重庆邮电大学学报(自然科学版) 2021年5期
马境远,刘 鲲,傅慧源
(1.北邮感知技术研究院(江苏)有限公司,江苏 无锡 214115;2.北京邮电大学 智能通信软件与多媒体北京市实验室,北京 100876)
0 引 言
互联网时代,随着视频制作成本降低,人们可以将各种各样的自制、转发视频上传到互联网,从而使视频数量呈指数级增长。这些视频中,不少充斥着大量暴力、低俗、恐怖镜头,这会给心智不成熟的未成年人身心成长造成不良影响。我国的影视业若想良性发展,必须建立分级制度,使未成年人可以远离不良的视频元素。但如何高效准确地识别出这些不良元素,对建立分级制度至关重要。要找出海量视频中包含的不良元素,靠传统电影电视监管部门人力内容审查方式,显然非常耗时耗力。因此,以检测特定视频内容为功能的智能分析系统应运而生。本文中,我们将聚焦讨论视频暴力自动检测技术。
视频暴力检测[1-10]旨在利用计算机自动精准地定位出暴力事件在视频中的起止时间。近年来,随着视频检测技术的推广和应用,暴力检测技术在很多关键领域发挥着越来越重要的作用。该技术不仅可以用于视频作品,也可以应用于很多现实场景,除了上面提到的互联网视频的内容审查,典型的应用案例包括:影视作品的内容分析、智能安防中敏感场所的视频监控等。
早期的研究工作[4-5]将暴力检测当作视频分类任务。在这种情况下,大多数方法都假设视频是剪辑好的,即暴力事件几乎持续于整个视频过程。然而,这类方法将应用范围限制为短视频片段,实际应用中不能定位未经剪辑视频中的暴力事件,因此该类方法在实践中的可用性并不强。此外,早期的暴力检测工作聚焦于特定的单一场景,往往导致解决方案的泛化能力有限。针对上述问题,本文研究的主题是如何在未剪辑视频(如影视剧、监控视频等)中检测出暴力事件。
本文提出利用多模态信息来检测视频中的暴力事件,多模态信息包括视觉和音频信息,视频信息又可以细分为视频帧特征和光流特征。与单模态输入相比,多模态可以更好地检测暴力事件。在大多数情况下,视觉信息作为直观信号,可以准确地识别和定位事件,但是在部分场景下,音频信号可以区分视觉上模糊的事件,也是视觉信息强有力的辅助信息。例如,在暴力场景中,视觉信息容易受到干扰,但可以凭借爆炸声独特的音域特征来识别事件。因此,视听融合可以充分互补信息,成为视频检测领域一种有效技术途径。但传统使用多模态信息的暴力检测方法有如下几个缺点:依赖于小规模剪辑视频数据集、使用手工设计的特征、只能识别特定单一场景下的暴力事件。与上述方法不同,本文是在未剪辑视频组成的大规模数据集上融合多模态特征来定位多个场景下的暴力事件。具体地,本文使用深度学习提取视频中的语音、光流、视频帧等特征,并提出关系网络组合不同的模态来建模不同模态之间的关系,并使用深度神经网络设计了多头注意力模块为不同的模态组合学习相应的权重。
本文的主要贡献有①提出融合音频、光流、视频帧3种模态特征检测视频中暴力事件,并使用深度学习提取上述特征;②提出了关系网络组合不同的模态特征,建模不同模态之间的关系;③提出了多头注意力模块学习多个不同应用的权重,生成区分力更强的视频特征。在公开数据集上的实验结果表明,本文方法取得的检测准确率比文献[10]中的检测方法更优。消融实验结果也表明本文方法各个模块的有效性。
1 相关工作
1.1 视频中动作识别
动作识别是视频中暴力检测相关的任务之一,其研究为提取视频的视觉特征提供了基本方法。当前,动作识别领域主流技术是基于深度学习的方法。根据不同的神经网络架构,用于动作识别的神经网络可分为2类:单流网络架构方法[11-12]和双流框架的方法[13-14]。前者通常采用三维卷积滤波器在一定数量的连续帧上执行卷积操作来捕获时序信息;后者的基本架构在文献[13]首先提出,其双流网络架构由空间网络和时序网络组成。其中,空间网络捕获单张视频帧的静态外观特征,时序网络通过输入数张叠加的光流图来建模视频中的短时序运动信息。文献[14]在双流框架下进一步挖掘视频中的时序信息,尝试使用帧差和扭转过的光流图作为双流网络的输入,并提出了多种缓解模型过拟合的技术,从而提高动作识别的准确率。
1.2 视频中暴力检测
在过去几年中,学者提出了多种暴力检测方法。例如,BERMEJO等[4]构建了2个著名的打架数据集;GAO等[5]设计了暴力流描述符来检测人群拥挤场景下的暴力行为;MOHAMMADI等[1]提出了一种基于行为启发式的新方法来区分暴力和非暴力视频。以前的大多数工作都利用手工设计的特征来检测规模较小的数据集的暴力元素。
随着深度卷积神经网络的兴起,一些研究人员开始使用深度卷积神经网络来检测视频中的暴力行为。例如,文献[6]使用带有卷积的长短时记忆网络(long short-term memory, LSTM)识别监控视频中的暴力行为以及异常事件;类似地,文献[7]构建了双向的卷积LSTM架构检测暴力;文献[8]使用了2个深度神经网络框架学习不同场景下的时空信息,然后通过训练一个浅层神经网络对不同场景的时空信息进行聚合。文献[9]提出了一个使用分散网络的混合深度学习架构,用于检测无人机视频中的暴力行为。研究人员也尝试使用多模态或者音频检测暴力,但是大多数方法都使用手工设计的特征提取音频特征,如频谱图、能量熵、音频能量、色度、梅尔标度频率倒谱系数、过零率、音高等。手工特征容易提取,但区分能力不强而且鲁棒性不高。与之不同的是,本文方法使用基于深度神经网络的模型提取视频中的多个模态信息。更为重要的是,本文提出了一种多模态特征融合方法,聚合视频中的音频与视觉信息,进而生成区分力强的暴力特征,提高了视频中的暴力事件检测准确率。
2 多模态特征融合方法
2.1 框架概述
图1展示了本文提出的暴力检测方法的整体框架,该框架主要由关系网络,注意力模块和检测网络3部分组成。首先使用深度神经网络提取视频中的多模态特征,包括视频帧特征、光流特征以及音频特征。上述3种特征经过不同的组合作为关系网络的输入,关系网络建模不同模态之间的关系,关系网络的输出作为多头注意力模块的输入,最终生成的视频特征则作为暴力检测网络的输入。本文聚焦于融合多模态特征来检测暴力,因此暴力检测网络采用了当前先进方法中的HL-NET[10]。
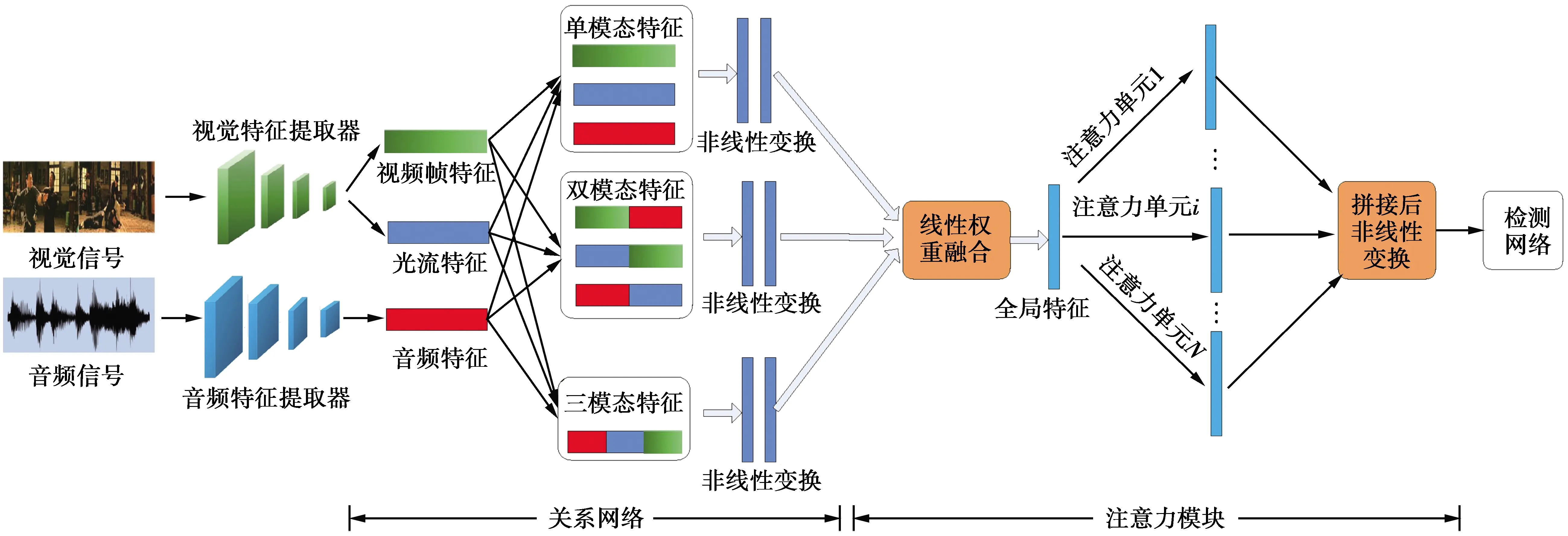
图1 本文暴力检测方法的整体框架图
2.2 关系网络
视频是一种包含多种模态的媒体,视频可以被解析为音频、图像以及随时序产生的动态特征。与文献[13-14]一样,本文用叠加的光流图来表示视频中的动态信息。本文研究的是如何融合视频中多种模态来更准确地检测暴力事件。根据人类检测暴力的常识,部分暴力事件发生时视觉信号可能会受到光照、遮挡等因素的影响,只有视觉信息时可能无法精准确定暴力事件发生的起止时间,这就需要音频信号辅助,如发生交通事故时车辆撞击的声音和爆炸的声响,都能很好地辅助视觉信息定位暴力事件。此外,不同的暴力事件可能依赖不同的模态组合,例如,射击可能依赖音频和视频帧,交通事故则可能更依赖音频和时序动态信息(光流),打架则可能更依赖视频帧和时序动态信息(光流),有些暴力事件则需要3种模态的融合。
因此,本文将音频特征、视频帧特征、光流特征进行多种组合。具体地,除了单模态,本文还将3种单模态两两组合组成3种多模态特征,此外还将全部的3种模态拼接到一起组成一种多模态特征,上述7种模态组合作为关系网络的输入来理解模态之间的关系。
针对单模态特征,关系网络首先对其进行非线性变换,然后拼接起来,过程可以表示为
T1=F1(fa)⨁F2(frgb)⨁F3(fflow)
(1)
(1)式中:F1,F2,F3分别表示一系列的线性和非线性变换,具体地,线性变换是全连接运算,非线性变换使用的是ReLu激活函数;fa,frgb,fflow分别表示音频特征、视频帧特征、光流特征;⨁代表拼接操作。
针对两两组成的多模态组合,关系网络首先将多模态特征进行线性变换,然后将变换后的特征拼接起来,该过程可以表示为
T2=F4(fa⨁frgb)+F5(frgb⨁fflow)+F6(fa⨁fflow)
(2)
(2)式中,F4,F5,F6分别表示一系列的线性和非线性变换,变换功能是充分融合相应的多模态特征,如F4(fa,frgb)就是充分融合视频中音频和视频帧特征。具体地,线性变换是全连接运算,非线性变换使用的是ReLu激活函数。
针对全部的3种模态,关系网络首先将3种模态特征拼接到一起,然后进行一系列的线性变换和非线性变换,该过程可以表示为
T3=F7(fa⨁frgb⨁fflow)
(3)
(3)式中,F7表示一系列的线性和非线性变换,线性变换是全连接运算,非线性变换使用的是ReLu激活函数。
关系网络则是将模态组合转换后的特征拼接到一起,该过程可以表示为
T=T1⨁T2⨁T3
(4)
拼接起来的特征T作为注意力模块的输入。
2.3 注意力模块
通过关系网络后,我们得到了特征集合,分别是单模态特征、2种模态的组合、3种模态的组合。
常见的聚合操作有平均池化、最大池化、用线性权重融合等。但注意力机制的输出通常聚焦于视频的特定部分,如关注视频中一段特定的视频帧或声音。通常,一个单一的注意力单元只能反映视频的一个方面。但是,视频作为一个复杂的包含多个模态的媒体,由多个注意力单元来关注视频的不同模态,共同描述整个视频可能更为有效。因此,要能够表示视频的多个方面,需要多个注意力单元来聚焦视频的不同方面。多个注意力单元关注同一输入,但多个单元之间参数相互独立。
基于上述思路,本文提出了多头注意力机制,首先使用线性权重融合上述的特征集合,得到一个全局特征,然后学习多组参数来关注全局特征的不同方面。具体地说,学习多组的成对的标量,第1个标量对全局特征进行线性缩放,第2个标量则作为偏置,引入非线性因素。上述过程可表示为
Vi=wi*(aT)+bi
(5)
(5)式中:a表示融合特征向量T的线性权重,aT表示上述的全局特征;wi和bi表示第i个注意力单元学习到的标量参数对。
得到注意力单元输出的特征Vi后,对其执行L2正则化,将所有单元得到的特征拼接起来,经过非线性变换,作为多头注意力模块的输出,即检测网络的输入。过程可以表示为
V=F8(V1⨁V2⨁…⨁Vi…⨁VN)
(6)
(6)式中,F8表示线性或非线性变换操作,线性变换是全连接运算,非线性变换使用的是ReLu激活函数。
2.4 检测网络
由于本文聚焦于融合多模态特征来检测暴力,因此暴力检测网络采用了当前先进方法中的HL-NET[10]架构。该架构主要包括3个部分:整体分支捕获视频中的长时序信息,定位分支建模视频中的局部位置关系,评分分支则预测发生暴力的分数。更详细的情况请查阅文献[10]。
比较两组患者并发症发生率,试验组患者并发症发生率为8.82%(3/34)显著低于对照组患者24.24%(8/33),差异有统计学意义(P<0.05)。见表1。
3 实验分析
3.1 数据集和评测指标
XD-Violence[10]是最近提出的用于检测暴力行为的大规模视频数据集。该数据集包含4 754个视频,总时长为217 h,涵盖6种暴力行为:虐待、车祸、爆炸、打架、暴乱和枪击。数据规模比以往暴力检测数据集都大。此外,该数据集中的样本均包含音频信息,可以用于融合多模态特征检测暴力事件。该数据集另外一个特色是数据采集于多个场景,如影视剧、体育运动、手持摄像机、监控摄像头、车载摄像头等。
与文献[10]一样,我们采用帧级的精度召回曲线(precision-recall curve,PRC)和平均精度(average precision,AP)作为评测指标,没有采用受试者工作特征曲线(receiver operating characteristic curve)和曲线下的相应面积(area under curve, AUC),因为AUC在类别数据不平衡时实验结果表现不够客观,而PRC则能更好地关注正样本(暴力事件)。
3.2 实现细节
1)音频特征。利用在大规模数据集YouTube上预训练的VGGish[15-16]网络作为音频特征提取器。音频被划分为有重叠的960 ms/段,其中,每段都有唯一的对应结束时间对齐的视频片段。从每段中计算得到的梅尔对数谱图块作为VGGish网络的输入,每段音频最终转化成128维的特征。
2)视觉特征。考虑到I3D在视频动作识别上的良好性能[11],使用I3D网络作为视觉特征提取器,视觉特征包括视频帧特征和光流特征。提取在Kinetics-400数据集上预训练的I3D的全局池化层特征,并使用TV-L1[17]算法在GPU上计算光流图。所有视频的帧速率设为24帧/s,并将滑动窗口的长度设为16帧。
3)网络架构。网络架构包括关系网络和多头注意力模块。关系网络,即(1)—(3)式中的F主要由全连接层、非线性层和Dropout层组成,多头注意力模块由一维卷积、全连接层和Dropout层组成。
4)训练细节。使用PyTorch完成深度神经网络的训练。对于网络优化,使用Adam作为优化器。初始学习速率设置为0.001,并且在第50个周期和和第100个周期减半。该网络总共训练了200个周期。批量大小为128,关系网络和注意力模块中的Dropout层Dropout率为0.8,注意力模块中的头数设置为32。
3.3 消融实验
本文聚焦于融合多模态特征进行暴力检测,为了公平比较,所有的实验中检测网络均采用文献[10]中的框架。本节首先展示多个模态特征融合后文献[10]的实验结果,验证简单地融合语音、视频帧、光流并不能大幅地提升准确率。然后通过实验验证了本文提出方法中使用单个模块进行暴力检测的有效性,最后分析了部分超参数对实验结果的影响。
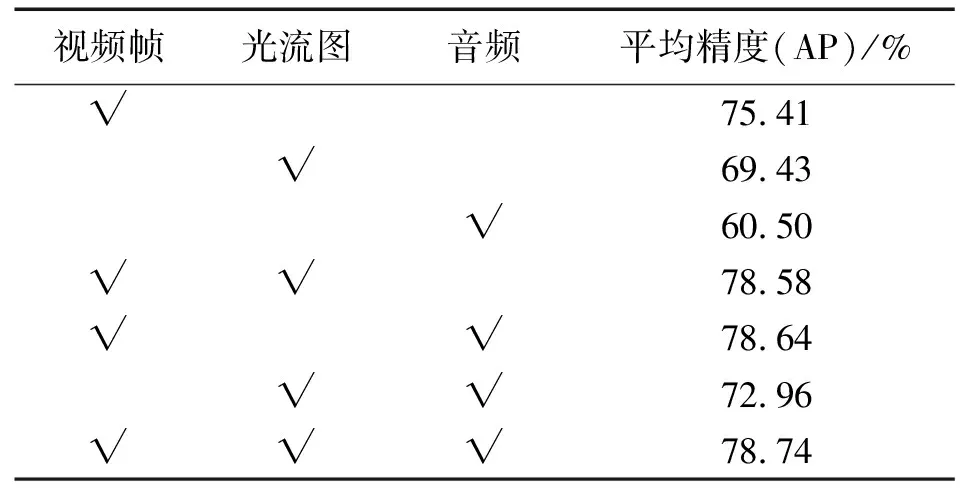
表1 不同模态在XD-Violence数据集上的实验结果
表2展示了基础方法、本文方法中单个模块和全部模块的实验结果。从表2可知,与基础方法比较,只使用关系网络和只使用多头注意力模块都能带来性能上的提升,验证了2种模块的有效性。此外,共同使用2种模块带来的增益大于单个模块,这也表明本文方法中的2种模块是相辅相成的,共同使用可以将多模态结合得更加紧密,得到的视频特征区分力更强。此外,我们发现多头注意力模块带来的增益比关系网络大,因此,探索一个高效的注意力模块来融合视频中多模态特征可能是暴力检测值得研究的方向。

表2 使用不同模块在XD-Violence数据集上的实验结果
表3给出了多头注意力模块中注意力头数对检测准确率的影响。从表3可以看出,注意力头数为32时取得的准确率最高,头数为16时由于参数不足导致模型的拟合能力不够,头数大于32时由于模型参数过多,且训练集规模不大,导致了模型过拟合,进而准确率有一定程度的下降。因此,实验中采用头数为32的注意力模块。

表3 不同注意力头数模块在D-Violence数据集上的实验结果
3.4 方法比较
表4中列出了本文方法与现有方法在XD-Violence数据集上的比较。值得注意的是,被比较的方法也是多模态输入。被用来比较的方法有如下特征。
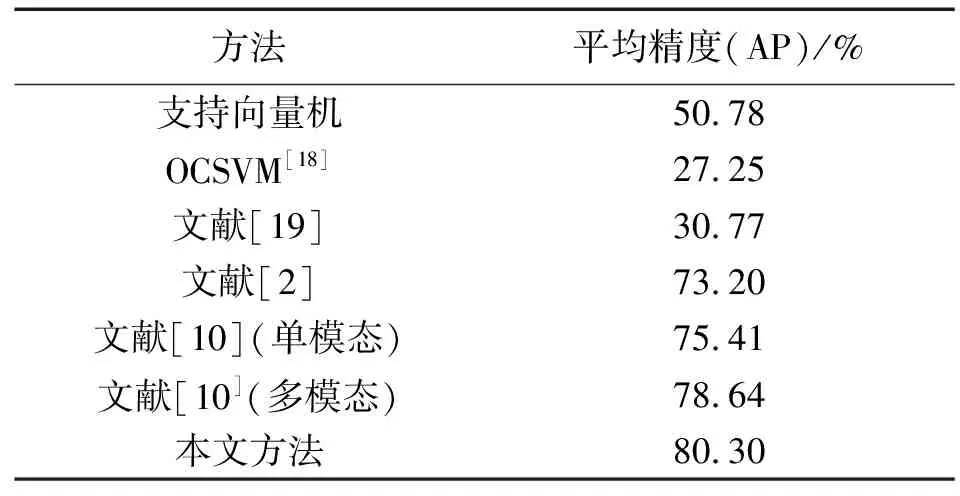
表4 不同方法在XD-Violence数据集上的实验结果
1)将暴力检测定义为视频分类问题,训练支持向量机作为分类器的基础方法;
2)文献[18]采用类似的方法,即基于改进的支持向量机的异常检测方法;
3)文献[19]在很少或没有监督的情况下端到端地训练一个基于自动编码器的全卷积深度网络模型,来学习局部特征与分类器,捕捉视频中动作的规律并用于识别视频中的不规则行为;
4)文献[2]使用多示例学习算法来解决未剪辑视频中异常检测的弱监督问题,针对异常的稀疏性和时序连贯性提出了2个新的损失函数;
5)文献[10]提出了3个平行的网络分支,来建模视频片段之间的关系和整合视频特征。
根据表4,在平均精度评测指标下,本文方法优于其他方法,比之前最好的方法(文献[10]方法)在单模态与多模态下分别高4.89与1.66个百分点,表明了本文方法的优越性。首先,与基于单模态特征的方法相比,本文方法使用了视频的多个特征,比如音频信息可以在视频低质或者有遮挡的情况下提升检测的准确率,这就使得本文方法的性能比单模态方法更好,鲁棒性也更强。其次,与其他基于多模态特征的方法比较,我们设计了关系网络来建模不同模态之间的关系,还设计了多头注意力模块为不同的模态组合学习相应的权重来生成区分力更强的视频特征,因此,本文方法的精度要比其他基于多模态特征的方法高。
4 结 论
本文提出使用深度神经网络提取并融合视频音频特征、光流特征、视频帧特征3种模态或3种模态组合方法检测视频中暴力事件。提出的方法主要包括关系网络和多头注意力模块,关系网络用来组合不同的模态特征,建模不同模态之间的关系,多头注意力模块为不同的模态组合学习相应的权重,生成区分力更强的视频特征。公开数据集上的实验结果表明,本文方法中各个模块的有效性,取得的检测准确率超过了现有方法。基于本文提出的暴力检测方法,可以更高效地识别视频中的暴力元素,实现互联网视频内容审查,协助视频分级,净化网络环境。同时,在影视作品的内容分析、智能安防中的视频监控等方面有广泛的应用推广前景。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
环球时报(2022-03-09)2022-03-09
作文成功之路·小学版(2020年3期)2020-04-21
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
传媒评论(2017年3期)2017-06-13
电子制作(2017年9期)2017-04-17
小学生必读(低年级版)(2017年11期)2017-03-15
第二课堂(课外活动版)(2016年2期)2016-10-21
人间(2015年8期)2016-01-09
