
融合特征信息的混合推荐模型
2021-11-07 10:35李增晖
电脑知识与技术 2021年25期
关键词:深度学习
李增晖

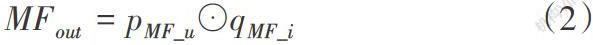
摘要:传统的矩阵分解模型仅通过用户-项目的评分矩阵来对用户进行项目推荐,由于未能使用用户与项目的特征信息从而造成了信息損失,使得模型的评分预测误差较大。为了更加充分地满足个性化推荐的需求,利用因子分解机以及深度神经网络改进传统的矩阵分解模型,融入用户与项目的特征信息。对改进后的模型在数据集MovieLens-1M上检验模型的效果,采用RMSE作为评估指标,实验发现改进后模型的RMSE值降低,模型的评分预测误差减小,评分预测结果更加准确。
关键词: 矩阵分解;因子分解机;深度学习;推荐模型
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2021)25-0017-03
Abstract:The traditional matrix factorization model only uses the user-item rating matrix to recommend items to users.The failure to use the feature information of users and items causes information loss, which makes the model's rating prediction error larger.In order to more fully meet the needs of personalized recommendation, the factorization machine and deep neural network are used to improve the traditional matrix factorization model and incorporate the characteristic information of users and items.To test the effect of the improved model on the data set MovieLens-1M, using RMSE as the evaluation index, the experiment found that the RMSE value of the improved model is reduced, the models scoring prediction error is reduced, and the scoring prediction result is more accurate.
Key words:matrix factorization;factorization machine;deep learning;recommendation model
随着科技的不断发展,数据的产生呈现几何倍数式的增长。数据的增加是信息技术发展的必然趋势,但是如此海量的数据已经远远超于个人或者系统所能有效利用的范围,造成了信息过载的问题。而推荐算法是目前解决该问题的有效方案之一。
传统推荐算法包括基于内容推荐算法、协同过滤推荐算法和混合推荐算法。随着数据的迅猛增长以及使用场景的多种多样,传统的推荐算法遇到了冷启动、稀疏矩阵等挑战[1]。
近年来,深度学习在图像处理及语音识别等人工智能领域上的表现十分出色[2],使得许多学者开始尝试将深度学习与推荐算法领域进行结合。张[3]等人称在推荐系统中使用深度学习技术可以提高推荐质量。与传统推荐体系结构相比[4],深度学习技术为推荐模型提供了更好的用户与项目的交互表示[5],同时有助于挖掘用户的兴趣偏好。利用深度学习技术来学习用户与项目的特征信息,不仅可以有效地获取特征表示,还可以降低数据的稀疏性,使推荐效果能够显著地提升[6]。
事实上,近年来许多公司也都投身于深度学习方法的研究,来改善推荐算法的表现。例如,谷歌公司推出了Wide&Deep模型用于更好地实现手机应用的推荐,Yahoo News采用了基于RNN的推荐模型向用户进行新闻推荐,美国奈飞公司采用深度学习推荐算法向用户进行影片推荐等等。
1 矩阵分解模型
协同过滤推荐算法是目前应用最广泛的推荐技术[7]。协同过滤推荐算法主要有以下两类:
第一类为基于近邻的协同过滤推荐算法,虽然此类算法具有很强的解释性,但是其计算量比较大,随着数据量不断加大的情况下,难以实现向用户进行实时的推荐。针对此问题,第二类即基于模型的协同过滤推荐算法被提出,通过对评分数据进行分析并训练出相应的预测模型以用于推荐,相较于第一类算法,此类算法的计算量更小,预测所需时间较短,是更好的一种方案,矩阵分解是此类算法中的常用模型之一。
评分预测可以视作一个将共现矩阵中未评分的数据补全的过程,而矩阵分解是实现这一过程的一类方法。矩阵分解方法所基于的假设是用户的行为可以由嵌入的潜在因子决定。
矩阵分解过程如图1所示,将共现矩阵RM×N分解为用户潜在因子矩阵PM×K与项目潜在因子矩阵QK×N。其中M为用户数,N为项目数,K为潜在因子的个数(图1中M=4,N=4,K=2)。
共现矩阵R中用户未给出评分数据的预测值可以通过矩阵P中用户u的行向量和矩阵Q中项目i的列向量计算,其表达式如公式(1)所示:
其中qi表示项目i的隐向量,pu表示用户u的隐向量。
2 模型设计
2.1 模型结构
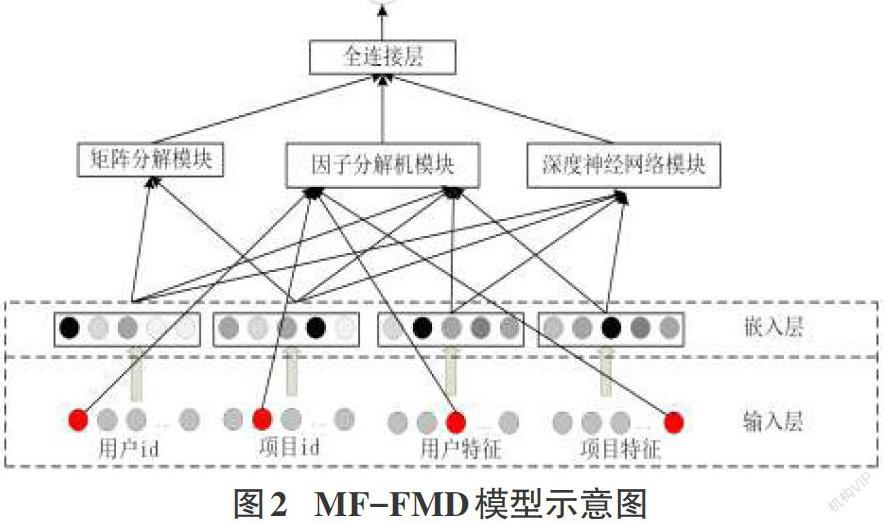
从矩阵分解的过程中可以看出该方法仅仅采用了用户-项目评分的共现矩阵,忽略了用户和项目的特征信息,造成了信息损失,从而影响了评分预测的准确度。针对此问题本文设计了一个融入多个模型的混合推荐模型命名为MF-FMD模型(如图2所示)。首先,加入因子分解机来融合用户与项目的特征值。但是由于因子分解机仅能获得到较低阶的特征交叉,三阶及以上的更高阶的特征交叉会造成模型中的权重数量以及训练复杂度过高,因此同时引入深度神经网络来获取更高阶的特征交叉信息。
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
考试周刊(2016年64期)2016-09-22
