
基于U-Net的多尺度融合视网膜血管分割算法
2021-11-06 09:35易三莉杨雪莲王天伟佘芙蓉
昆明理工大学学报(自然科学版) 2021年5期
易三莉,杨雪莲,王天伟,佘芙蓉,熊 馨
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.云南省计算机技术应用重点实验室,云南 昆明 650500)
0 引言
视网膜血管分割为高血压、糖尿病和动脉硬化症等疾病的诊断与治疗提供了依据[1].由于视网膜血管形态复杂多样,医生对其进行手工标注不仅耗时而且容易造成误差,因此采用自动分割技术进行眼底血管图像处理成为人们研究的热点.近年来,研究者们提出了许多血管分割方法,这些方法主要可以分为无监督学习和有监督学习方法.
无监督学习方法是利用血管的固有结构特征进行分割,不需要任何人工事先标记的信息.如Nayebifar等[2]提出基于粒子滤波的视网膜血管跟踪方法.Hassan等[3]提出基于数学形态学的视网膜血管分割方法.无监督学习方法的优点是可以直接在血管图像上对血管结构信息进行提取,便于训练.但是该方法大部分情况下是根据经验直接设计算法模型来提取特征,使其容易受到人为因素的影响,而对特征提取造成偏差导致分割结果不理想.
与无监督学习方法不同,有监督学习方法通过将大量的标注数据作为监督信息,自动对图像血管特征进行改进学习,然后进行血管分割.在有监督学习方法中,最初使用传统机器学习方法提取和学习图像特征.如Fraz等[4]使用决策树并利用形态学变换方法进行血管分割.Ricci等[5]使用SVM分类器根据血管宽度进行分割.近年来,深度学习算法在图像领域取得较快的进步.早期卷积神经网络(Convolutional Neural Network,CNN)是通过进行卷积运算自动提取图像特征,接着Long等[6]在2015年提出全卷积神经网络(Fully Convolutional Network,FCN),它把CNN最后的全连接层换成反卷积层,得到精细的分割结果.随后,Ronneberger等[7]在全卷积神经网络的基础上提出U-Net模型,它是完全对称的编码解码结构,采用了通道拼接融合的方式形成多尺度特征,更好地恢复了编码器中所丢失的信息从而取得显著的效果.2017年,Huang等[8]提出密集卷积网络(Dense Convolutional Network,DenseNet)算法增加了图像的底层信息从而加强特征的重用.Chen等[9]提出的空洞卷积代替传统的卷积层,扩大图像的感受野,但是空洞卷积前后信息缺少依赖容易导致局部信息丢失.于是文献[10]提出空洞空间金字塔池化(Atrous Spatial PyramidPooling,ASPP)加强信息之间的依赖,能够更有效地捕捉图像中的多尺度信息.近年来,深度学习被广泛应用于血管分割领域中.如Wang等[11]提出了CNN和随机森林结合的眼底血管分割方法,然而难以准确捕捉到血管边界结构;Feng等[12]采用FCN进行视网膜血管分割,尽管能较准确地分割出绝大部分血管结构,但由于FCN模型在融合时是对应像素点的相加,没有考虑到像素之间的关系,缺乏空间一致性,得到的结果仍然不够理想,视网膜细小血管的分割能力还有待提高.
为了解决微小血管在分割中存在分叉处不连续、复杂曲度形态易丢失等问题,本文提出基于多尺度特征融合的视网膜血管分割算法.该算法对U-Net结构进行改进和优化,构造空洞空间金字塔池化模块、短跳跃连接以及多特征融合结构来学习来自不同大小感受野的细小血管特征,增强图像特征的传播,使得视网膜图像浅层信息和深层信息得到更好结合,从而提高对微小血管分割的性能.
1 相关理论和方法
1.1 视网膜血管分割网络
本文的多尺度融合血管分割算法是在UNet结构的基础上,通过将ASPP模块与短跳跃连接进行融入,并将融合后的特征输入到多尺度特征融合模块中,来充分学习视网膜血管的边缘特征和纹理特征,提高网络分割性能.网络整体框架为U型,主要分为编码和解码两个部分.网络的模型结构如图1所示.

图1 血管分割网络Fig.1 Vascular segmentation network
图中,视网膜血管图像首先经过编码部分输入到网络中,由网络自动学习和提取血管特征,然后通过解码部分将提取的特征进一步融合,最后输出分割结果.各部分具体操作如下:
编码部分包括三次下采样操作和中间层操作,每次下采样操作为Conv3×3+BN+Relu+Max pool2×2+DEA module,其中Conv3×3为3×3卷积,用于特征提取;BN为批归一化层,能够缓解梯度消失问题;Relu为激活层,用于引入非线性因素,加速网络收敛;Max pool2×2为2×2最大池化层,提取语义信息;DEA module为DEA模块,由ASPP和短跳跃连接组成,其中ASPP模块使用不同空洞率的空洞卷积进行并行连接,相较于传统卷积拥有更多的血管信息,提取多尺度血管特征;短跳跃连接将不同层次的特征信息进行合并,充分利用空间位置信息,从而可以采集到更多的血管细节.中间层操作包括Conv3×3+BN+Relu+DEA module,此时通道数最多,上下文信息更丰富,该操作进一步实现网络对图像特征的提取.
解码部分将编码部分的输出作为输入,进行三次上采样操作.上采样操作为up-conv2×2+Copy and crop+Conv3×3+BN+Relu+DE module.其中up-conv2×2为2×2上采样卷积操作,用于还原特征图大小;Copy and crop为复制和裁剪,将编码部分的粗糙特征与解码精细特征进行融合,从而更好地保留原图像的空间信息和细节信息,提高图像精度;DE module为DE模块,由短跳跃连接构成,传递不同复杂度的深浅层特征信息提高网络性能,相比于传统上采样操作,能同时提取更加丰富的细小血管和粗血管特征.最后一层用1×1卷积将特征向量映射到一个类的标签,得到分割预测图.
本文改进模型增加了U-Net网络对特征信息的利用率,不仅能够保证血管的主轮廓信息清晰,而且能提高血管细微结构的提取效果.
1.2 ASPP模块
U-Net网络中图像尺寸缩小再还原的过程中会丢失相关特征.文献[9]提出的空洞卷积代替传统的卷积层,在不增加参数的情况下提升特征图的感受野.空洞卷积的基本原理是引入扩张率,在3×3卷积核中间填充0,当每一层设置不同的扩张率就会得到不同感受野,从而获取了多尺度信息.其原理如图2所示.

图2 空洞卷积:(a)3×3卷积;(b)3×3卷积,rate=3Fig.2 Dilated convolution:(a)3×3 convolution;(b)3×3 convolution,rate=3
但是在空洞卷积中会造成卷积前后信息没有相互依赖,导致局部信息丢失.于是采用ASPP模块解决上述问题,使得信息之间具有连续性.ASPP把一个特征图从不同的角度进行特征提取,即每个尺寸提取一个固定维度的特征,然后将特征聚合成一个新的固定维度,提高了图像分割的精度.ASPP包含的空洞卷积实际卷积核大小(即感受野)的计算为:

式中:K为空洞卷积核大小,k为原始卷积核大小,r为空洞卷积参数空洞率.本文中采用r=3,r=5,r=7的膨胀率,其结构如图3所示.
在图3中,将输入分别传递到四个不同的并行通道中,并行通道由1×1卷积层和三个不同空洞率的卷积层构成.其中,1×1卷积层用于获取全局特征,不同空洞率的卷积层用于获取局部特征.在这里,分别使用空洞率为3,5,7的3×3卷积核,当r=3时得到一个7×7的空洞卷积核,r=5时得到一个11×11的空洞卷积核,r=7时得到一个15×15的空洞卷积核.将四个通道的特征进行融合获得多尺度特征,同时使用1×1用于卷积核通道数的降维,减少计算量.

图3 ASPP连接结构Fig.3 The ASPP connection structure
本文在下采样中用空洞卷积代替传统卷积,在不增加网络参数数量的同时在多个尺度上捕获目标以及图像的上下文信息,得到更丰富的特征信息.同时使用并行方式将多通道结构信息连接起来,能提高网络提取血管特征信息的能力,增强毛细血管分割效果,也可以避免因网络层数过多造成的过拟合现象.
1.3 短跳跃连接
短跳跃连接能够加强特征的传播和重用,因而能够在减少模型参数的同时解决深层网络中梯度消失的问题.在图像分割中,它将图像的前层与本层的特征信息相结合作为下一层的输入,使得特征和梯度的传递更加有效,网络也更加容易训练.本文在U-Net网路的基础上,每个编码解码部分都加入了短跳跃连接结构,确保信息的最大流动.每层之间的短连接结构如图4所示.设l层的输出为xl,Fl表示一个非线性变换,则该模型第l层的输出定义为:

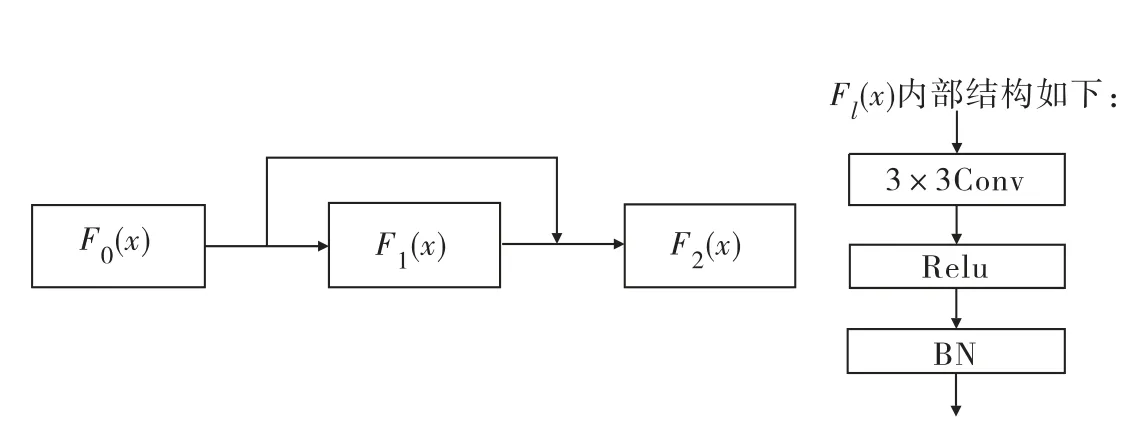
图4 短连接结构Fig.4 Short connection structure
式中:[x0,x1,…,xl-1]表示0,1,…,l-1层输出特征的合并,充分利用特征输出信息,可以实现特征重用,提升效率.F1由BN、Relu和3×3卷积操作组成,各个操作的作用同上所述.同时卷积层之间还引入了随机失活层,dropout设为0.2,表示在迭代过程中随机丢弃部分神经元,从而防止参数过拟合,有效提高模型泛化性能.本文利用短跳跃连接将浅层精细信息与深层粗糙信息相融合,得到更丰富的图像细节特征.
1.4 多特征融合的编解码结构
底层高分辨率的精细语义信息能保留更多的细节信息,于是需要最大限度地利用底层特征.针对视网膜眼底图像特征的复杂性,本文在编码和解码部分使用短跳跃连接加强特征重用,将深层和底层信息进行融合,提高网络性能,从而得到更多视网膜细小血管分割的细节,其结构如图5所示.
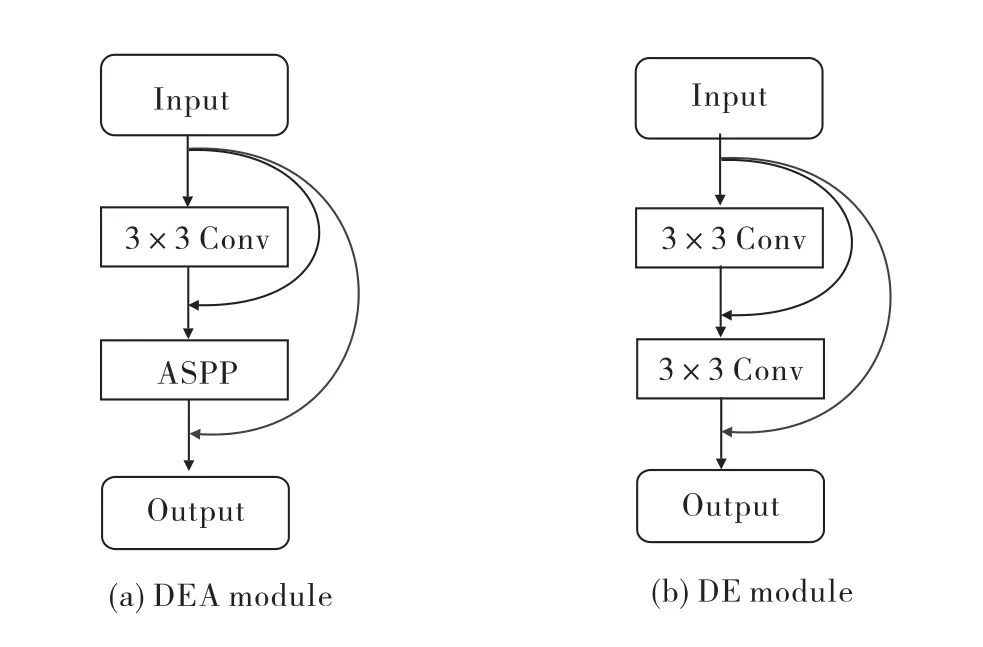
图5 编解码结构:(a)编码结构(DEA module);(b)解码结构(DE module)Fig.5 Encodering and decoding structure:(a)Encodering structure(DEA module);(b)Decoding structure(DE module)
本文编码结构首先使用3×3卷积进行特征提取,接着经过由ASPP构造的学习块学习有效的图像特征.但由于ASPP中利用空洞卷积选取像素点时并不密集,有大量信息被抛弃,于是使用短跳跃连接将每个层的输出与输入进行拼接,增强特征图信息的利用,进一步实现网络对图像特征的提取.同样,解码结构采用跳跃连接能充分利用深浅层不同复杂程度的特征信息,减少微小血管分割不全和分割断裂的现象.
2 实验结果与分析
本实验的仿真平台为PyCharm,使用keras及其TensorFlow端口,运用python语言编程.计算机配置为Intel(R)CoreTM i7-9700K CPU@3.6 GHz,64.0GB内存,NVIDIA GeForce GTX 1070 Ti,采用64位操作系统Windows 10.
2.1 数据集及预处理
本文实验采用公开数据库DRIVE.它包括40张彩色眼底图像,训练集和测试集各20张图像,图像尺寸均为565×584,每幅图像对应两位专家的手动分割结果作为分割标准.
由于DRIVE数据集的图像较少,需要对图像进行数据扩充,具体包括图像翻转、空间平移以及图像缩放等操作,将数据扩充到原来的50倍.在眼底图像中,因为绿色通道血管对比度高、清晰,故在实验中选取眼底视网膜图像的绿色通道进行处理.然后对图像进行了直方图均衡化、标准化以及伽马变换等预处理,预处理图像如图6所示,可以看出预处理过程能增加图像的对比度,突出血管形状信息.

图6 图像预处理:(a)原图像;(b)预处理图像Fig.6 Image preprocessing:(a)Original image;(b)Preprocessed image
2.2 网络参数设置
对于视网膜血管的分割,本文算法基于图像块即patch的处理,训练块的大小设为64×64,训练50次.运用Adam算法作为网络的优化算法,其学习率为0.001,并采用交叉熵损失函数使网络获得更有效的收敛,提高训练效果.
2.3 评价指标
为了更好地定量分析视网膜血管分割效果,本文采用准确率(Accuracy)、灵敏度(Sensitivity)、特异性(Specificity)、ROC曲线下方的面积AUC几个指标来对模型进行分析.计算如下:

式中:TP指图像中标注为血管像素、预测结果也为血管像素的总个数;TN指图像中标注为背景像素、预测结果也为背景像素的总个数;FP指图像中标注为背景像素、预测结果为血管像素的总个数;FN指图像中标注为血管像素、预测结果为背景像素的总个数.
准确率(Acc)表示正确分类的血管和背景像素占图像总像素的百分比;灵敏度(Sen)表示正确分类的血管像素占真实血管像素的百分比;特异性(Spe)表示正确分类的背景像素占真实背景像素的百分比;ROC曲线表示灵敏度和特异性之间关系,AUC为ROC曲线下的面积,表示图像分割结果的预测准确性,AUC越接近1,说明算法的分割效果越好.
2.4 实验结果
视网膜血管分割的任务是确定视网膜图像中属于血管区域的像素点,本文模型在DRIVE公共数据集上的实验结果与其他模型比较如表1所示,结果说明本模型具有较好的视网膜血管分割效果.

表1 不同分割方法在DRIVE数据集上的性能对比Tab.1 Performance comparison of different segmentation methods on the DRIVE dataset
1)不同算法的实验结果比较
本文将有监督学习和无监督学习方法在视网膜数据集DRIVE的分割效果进行了对比.通过表1可以看出,有监督学习的分割效果比无监督学习方法更好.此外,在有监督学习方法中,本文算法准确率为0.957 2、特异性为0.983 3、灵敏度为0.810 0、AUC为0.981 1,与其他深度学习方法相比各项指标均为最高.因此可以看出本文所提方法能够取得更好的视网膜分割效果.同时,本文算法ROC曲线如图7所示,ROC曲线可以直观表示AUC值,其值为0.981 1,与1很接近,说明本文算法能够对血管像素和背景像素进行正确分类,模型表现也更好.

图7 DRIVE数据集上的ROC曲线Fig.7 ROC curve on the DRIVE dataset
2)消融实验对比
为了验证所提方法的有效性以及算法的每一步改进对于分割结果所产生的具体影响,本文在该数据集上分别做了三组对比实验进行验证.Model 1是采用原始的U-Net网络不做任何修改;Model 2是在编码解码部分仅采用DE module;Model 3是在编码和解码部分分别使用DEA module和DE module.不同模型在准确率Acc和AUC等性能方面比较如表2所示.

表2 消融实验对比Tab.2 Comparison of ablation experiments
由表2可知,Model 1中使用原始的U-Net对视网膜血管分割已经有了较好的效果,其准确率、特异性与AUC值分别为0.955 9、0.980 7和0.979 9,但由于下采样缩小特征图大小、上采样还原特征图大小过程中会造成原图像的细节信息丢失,因此分割效果还需要进一步提升;Model 2是在U-Net网络的基础上利用短跳跃连接构建的DE module进行上下采样,由于短跳跃连接能够实现层与层之间的信息传递,充分利用之前提取的所有血管特征,因此其各项性能指标都有一定的提升;Model 3在编码和解码部分分别使用DEA module和DE module,其中DEA module是在DE module的基础加入了ASPP学习块,该学习块不仅可以学习局部的血管细节信息,而且可以将全局的血管特征信息加以利用,从而捕获到更复杂的血管结构特征.综上,通过评价指标可以看出,本文改进模型极大地改善了原始U-Net模型的综合性能.
3)分割结果图比较
为了清晰直观地证明本文算法的优势,图8展示了本文不同模型在DRIVE数据集上的部分图像的分割效果图.

图8 DRIVE数据集分割结果:(a)原始图像;(b)标准图像;(c)Model 3分割结果图;(d)Model 1分割结果图;(e)Model 2分割结果图Fig.8 DRIVE dataset segmentation results:(a)Original images;(b)Ground truth images;(c)Model 3 segmentation result images;(d)Model 1 segmentation result images;(e)Model 2 segmentation result images
将图8中各算法(c)、(d)、(e)的结果与专家标注(b)的结果进行对比可以看到:第一行的红框中(d)和(e)相较于(b)没有分割出应有的细小血管信息,而本文算法(c)与(b)几乎一致,能够很好地将毛细血管提取出来,细节特征信息并未丢失;第二行的红框中(d)和(e)存在血管细微部分不够完整,(c)与(b)的结果一致;第三行的红框中(d)提取到的轮廓信息不够清楚,并且(d)和(e)出现分割断裂不全的情况,而(c)能很准确地分割出粗血管和细小血管,并且保证提取的主轮廓清晰,在血管分支处不会出现断裂的情况.综上所述,本文算法不仅在血管的连接处保证了血管的连续性,而且在细小血管部分也保证了血管的完整性,能有效地捕捉图像中的复杂结构信息,从而说明本文所提方法具有良好的分割性能.
4)分割细节对比
图9选取了DRIVE图像中血管交叉处和细小血管的局部区域进行放大对比.观察分割图,可以明显看到:(1)中的(e)与(f)分割出的血管是断裂的,而本文算法(d)则较好地保证了血管的连续性;(2)中红框处标准分割图(c)中具有细小的分支血管,但在(e)与(f)的分割结果中,却没有分割出这条血管,而本文算法(d)则能够分割出这条血管,使分割结果更加完整.

图9 分割细节对比:(a)原图像;(b)局部原图像;(c)标准图像;(d)Model 3局部分割图;(e)Model 1局部分割图;(f)Model 2局部分割图Fig.9 Segmentation detail comparison:(a)Original images;(b)Local original images;(c)Standard images;(d)Model 3 local segmentation images;(e)Model 1 local segmentation images;(f)Model 2 local segmentation images
从本文算法与其他已有算法各项指标比较以及消融实验结果来看,本文所使用的每个模块均能对视网膜血管的分割产生影响,从而说明本文算法具有显著优势,能理想地分割出大部分血管且保证血管整体轮廓清晰,同时减少血管误判和漏判的机率,保证了血管分割的连续性与完整性.
3 结论
本文基于U-Net网络结构提出了一种多尺度特征融合视网膜血管分割算法,该方法使用空洞空间金字塔池化模块和短跳跃连接,不仅可以扩大血管图像的感受野,而且能在进行高层次信息与低层次信息的融合时能最大程度地提取图像的血管特征,得到更全面的细节信息.结果表明,本文算法在DRIVE眼底图像数据库上能够分割出不同形状和大小的血管,提高了细小血管分割的准确率,同时能保证血管分割的连续性和完整性,为视网膜血管分割方法提供更可靠的借鉴.在下一步工作中,针对细小血管的直径、弯曲度等特点,将继续探索视网膜血管分割方法,提高血管分割精度.
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
北京航空航天大学学报(2021年9期)2021-11-02
中医眼耳鼻喉杂志(2021年1期)2021-07-22
中医眼耳鼻喉杂志(2021年2期)2021-07-21
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
故事作文·高年级(2017年2期)2017-03-01
湖南中医药大学学报(2016年1期)2016-12-01
新闻传播(2015年20期)2015-07-18
电视技术(2014年19期)2014-03-11
