
一种基于深度学习的煤矸石检测方法
2021-11-06 05:54赵学军李建
矿业科学学报 2021年6期
赵学军李建
中国矿业大学(北京) 机电与信息工程学院,北京 100083
煤炭是我国的主要能源,煤矿行业肩负着保障我国能源安全和民生的重任。 如何保障煤炭产品质量和进一步提升煤矿的安全生产,是煤矿行业一直备受关注的核心问题[1-2]。 从煤矿中直接开采出未经任何处理的原煤,由于其形成过程的复杂因素,或多或少含有影响煤炭品质的矸石。 为了提高煤炭纯度、改善煤炭质量,大多数煤矿企业会设置选煤厂分选原煤[3-4]。 在选煤厂的所有工序中,选矸是不可或缺的步骤,其主要目标就是将大块矸石从煤块中分选出来。 目前,国内大部分煤矿依旧使用人工排矸的方法,而人工分选存在工作环境恶劣、工人劳动强度大、分选效率低以及安全事故频发等问题。 人工排矸的工作方式已经不能满足国家倡导的建设绿色矿山、智慧矿山发展要求,急需自动化程度高、检测效果好的煤矸石检测方法[5]。
近年,随着计算机技术和人工智能技术的快速发展,赋予了机器具有类似于人类的视觉分析能力,即机器视觉技术。 目前,机器视觉技术已在社会生产生活的各个领域得到广泛应用,包括工业[6]、农业[7]、医学[8]、安防、航空航天、军事等领域,提高了各自领域的效率。 目标检测是机器视觉领域的四大主要任务之一,是近年备受关注的前沿研究方向。 目标检测是将定位和识别合二为一,既要检测出物体在图像中的位置,还需要识别出物体的类别。 传统目标检测主要分为3 步:区域选择、特征提取、分类回归[9],因此存在算法上的瓶颈。例如,区域选择策略效果差,事件复杂度高,严重依赖棘手的特征工程提取数据集的特征,无法针对任务进行端到端的学习[9],并且任务的泛化能力有限,制约了算法性能,在一定程度上阻碍了技术的发展与应用。
近年,深度学习得到蓬勃发展。 通过将深度学习引入到目标检测任务中,使得目标检测这一机器视觉领域得到了质的飞跃,无论是在检测精度还是算法复杂度上,都大大领先传统检测算法。 本文旨在利用目标检测原理,通过机器视觉技术实现煤与矸石混合体中矸石的智能检测,可以为选煤环节的分拣机器人提供算法支撑。 选煤厂视觉环境复杂,受光照条件制约以及煤尘粉粒等干扰,导致能够获取的视频图像质量较差,为后续基于图像的机器视觉分析带来了极大的挑战[10]。 传统基于人工主观设计特征工程的检测方法,如灰度阈值检测[11-12]或边缘检测[13],在此任务上的表现不尽人意,有很大的局限性。 基于深度学习的算法,借助卷积神经网络强大的特征提取能力和非线性学习能力,能够在煤与矸石灰度值严重混叠,颜色、边缘梯度区分不明显等场景下,进行有效检测。 在实际应用场景下,需要实时处理摄像头获取的视频序列,对检测算法的精度和速度都有较高要求。 为了缩减模型大小,提高运行速度和改善检测精度,本文对YOLOv3[14]算法模型的特征提取、特征融合、损失函数设计做了必要的修改,以更好地满足实际应用需求。
1 轻量级骨干网络和改进的特征融合neck
1.1 Darknet-Squeeze
出于视频检测算法实时性的需求,以及边缘设备计算能力的制约,在YOLOv3 使用的骨干网络(Backbone)Darknet-53 的基础上提出轻量高效的特征提取骨干网络Darknet-Squeeze。 在Darknet-53 网络中有53 个卷积层,其中有23 个残差块(Residual)[15]结构,每个残差块由1×1 和3×3 的卷积层加上跳跃连接构成。 为了进一步加快模型的推理速度和缩减模型尺寸,受到SqueezeNet 模型[16]的启发,使用其中fire module 模块的思想取代Darknet-53 中的残差块。 在fire module 模块中,首先使用一个由1 × 1 卷积构成的squeeze 层来减少输入通道数,然后将输出结果输入到由1 ×1 卷积和3×3 卷积混合构成的expand 层。 此外,为了进一步缩短推理时间,受MobileNets 模型[17]的启发,使用3×3 的深度可分离卷积(depth-wise separable convolution)替换原来的标准3×3 卷积。表1 展示了Darknet-53 中残差块与改进后Darknet-Squeeze 中fire module 模块的比较。

表1 Darknet-53 中的残差块与Darknet-Squeeze 中的fire module 模块比较Tab.1 Comparison between the residual block in Darknet-53 and the fire module in Darknet-Squeeze
通过使用fire module 模块替换Darknet-53 中的残差块,其余部分遵循原来的架构,得到Darknet-Squeeze 骨干网络。 Darknet-Squeeze 由23 个fire module 模块和其间的几个负责下采样的卷积层构成。 相比Darknet-53 骨干网络,Darknet-Squeeze在保障特征提取能力的同时,极大地缩减了模型尺寸,加快了推理速度。 Darknet-Squeeze 的总体架构如图1 所示。
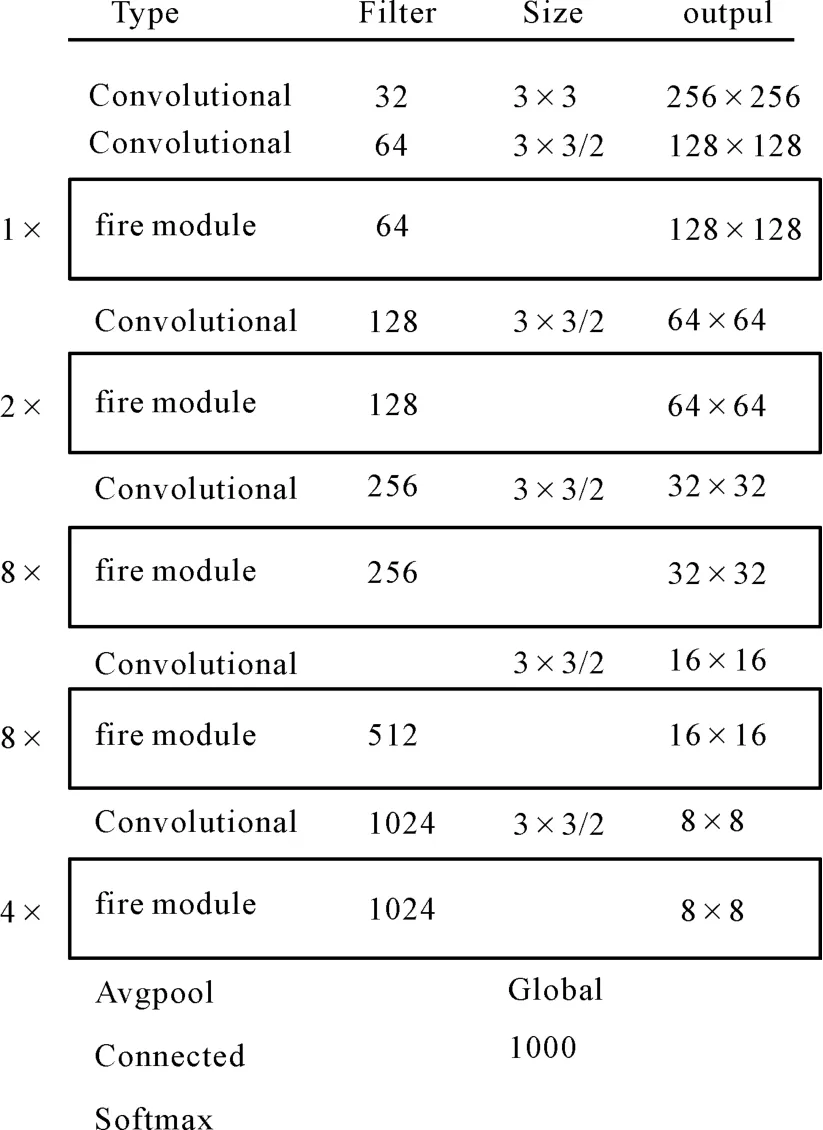
图1 Darknet-SqueezeFig.1 Darknet-Squeeze
1.2 改进的特征融合neck
相较于大多数目标检测任务,煤矸石检测任务有其特殊性。 煤矸石检测基本上对应的是小尺度物体,且煤与矸石在颜色、纹理、形状等特征上差异较小,增加了检测难度。 因此,煤矸石检测要求检测模型能够有效地融合各级特征,改善小尺度物体的检测性能。 骨干网络后的特征融合neck 部分,是提升不同尺度的物体检测性能的关键。 因此,一个设计良好的特征融合neck 模块对于检测模型的整体性能至关重要。 在YOLOv3 模型的上采样部分,使用4×4 的转置卷积(transpose convolution)代替原最近邻(the nearest neighbor)的采样。 原基于最近邻插值的采样方式,是一种人为设计的特征工程,然而,基于转置卷积的上采样方式有可学习的权重参数,是通过网络学习的一种较优的上采样方法。 空间金字塔池化(Spatial Pyramid Pooling,SPP)结构[18]最早提出解决的2 个主要问题:
(1) 有效地避免需统一输入图像尺寸对图像区域进行剪裁、缩放操作导致的图像物体信息丢失以及形状扭曲失真等问题。
(2) 解决了卷积神经网络对图像特征重复提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
在YOLOv3 中引入SPP 结构不是为了解决上述2 个问题,而是借鉴金字塔池化的思想进行多级特征图的信息融合。 特征图经过局部特征与全局特征相融合后,丰富了特征图的表达能力,有利于煤与矸石图像中待检测物体之间特征差异较小、小物体偏多的情况,对于检测的精度有明显的提升。 跟随文献[19]中的设置,在检测前引入SPP 结构,采用3 个核大小分别为5×5、9×9、 13×13 的最大池化和一个跳跃连接,将经过池化后的特征图重新串联到一起。 采用的SPP结构如图2 所示。
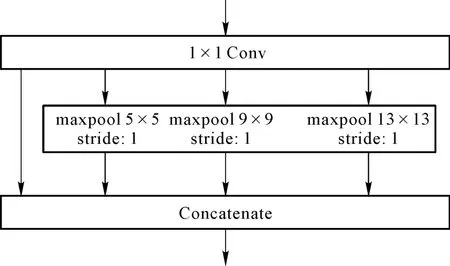
图2 空间特征金字塔池化结构Fig.2 Spatial Pyramid Pooling(SPP)
2 平衡损失函数和距离IoU 损失函数
2.1 平衡损失函数
目标检测器需要执行分类和定位两个任务,因此在训练工程中会整合分类损失函数和定位损失函数来指导模型收敛。 但是,如果整合的两个任务没有做到恰当的平衡,将会导致其中一个任务受到抑制,影响模型的整体性能[20]。 实验数据在标注过程中难免有误标注和漏标注的情况,产生难训练样本,进而出现不平衡学习。 在不平衡的学习任务中,容易训练样本产生的小梯度易被难训练的样本产生的大梯度所掩盖,从而限制了模型性能的进一步提升。 因此,为了使得模型能够更好地学习收敛,需要重新平衡所涉及的任务和样本。 为了更好地平衡学习分类和定位任务,采用在文献[21]中提到的平衡L1 损失函数(balanced L1 loss)。 由于矸石检测是一个单分类任务,所以仅在定位任务上使用平衡L1 损失函数。 在YOLOv3 中,分类和定位任务是在多任务损失的指导下被同时求解,其总体损失可表示为
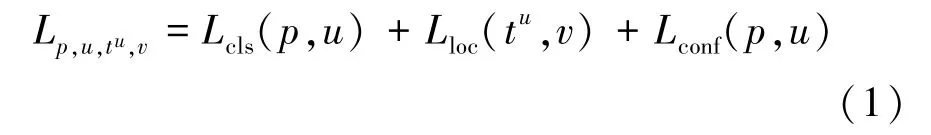
式中,Lcls、Lloc、Lconf分别为分类、定位和目标置信度损失函数;p、u分别为预测值和实际值;tu为对应类u的回归结果,u≥1;v为回归目标。
在平衡L1 损失函数中,将损失大于等于1.0的样本叫作离群值(outliers),其他样本叫作内部值(inliers)。 离群值可视作难训练样本,会产生比较大的梯度值,有损训练过程;内部值可视作易训练样本,对总体梯度贡献较小。 具体来说,每个内部值相比离群值只贡献了30% 的梯度[21]。 为了解决此问题,平衡L1 损失函数采取提升来自内部值的回归梯度,以重新平衡相关样本和任务,从而实现在分类和定位任务上的平衡训练,同时也尽量消除数据误标注和漏标注带来的影响。 平衡L1 损失函数的定位损失Lloc可以表示为
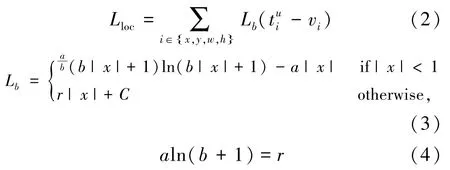
式中,a为控制内部值梯度提升的因子;r为控制整体提升量的参数,用于调整回归误差的上界,有助于目标函数更好地平衡所涉及的任务;b为用于确保式(3)两个分支在Lb(x=1)的情况下有相同的值。
2.2 距离IoU 损失函数
在煤矸石检测任务中,经常出现煤与矸石、矸石与矸石之间重叠遮挡的情况,加大了精确定位待检测物体的难度。 为进一步提升煤矸石检测的定位精度,充分考虑待检测物体间的位置关系,将距离交并比(Intersection over Union,IoU)作为损失函数来指导模型回归训练。 大多数目标检测算法中,边界框回归是定位目标物体矩形框的关键步骤,交并比是最常用的度量回归边界框的指标,可表示为

式中,Bgt={xgt,ygt,wgt,hgt}为目标边界框的实际值;B={x,y,w,h}为预测的目标边界框;ln范数用来度量边界框B和Bgt之间的距离[22]。
在文献[23]中,使用基于欧式距离的ln范数损失函数的前提是假设4 个坐标变量相互独立,但实际上它们是相互关联的,因此不是一个合适的选择。文中提出直接使用IoU 作为损失函数,可表示为

然而,LIoU损失函数仅在两个边界框重叠的情况下起作用,无法优化两个不相交的边界框。 为了解决LIoU损失函数存在的问题,文献[24]中提出一个广义的IoU 损失函数(Generalized IoU,GIoU):
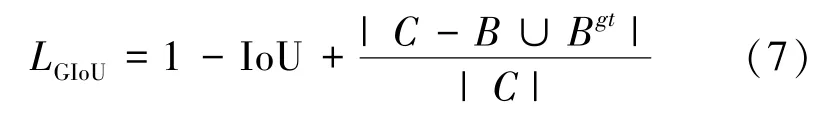
式中,C为两个框最小外接矩形面积。
GIoU 损失函数在IoU 损失函数的基础上添加了一个惩罚项,虽然GIoU 损失函数可以处理两个边界框不相交的情况,但当目标边界框完全包含预测边界框时,GIoU 损失函数会退化为IoU 损失函数,导致训练过程收敛慢。 为了解决GIoU 损失函数存在的不足,文献[25]提出一种距离IoU(Distance-IoU,DIoU)损失函数,同时考虑两个框的重叠面积和中心的距离两个几何因素来加快收敛速度和回归精度,可表示为

式中,b、bgt分别为边界框B和Bgt的中心点;ρ(·)为两个中心点间的欧式距离;c为可以同时覆盖边界框B和Bgt的最小矩形的对角线距离。
DIoU 损失函数通过对预测框与目标框之间的归一化距离进行建模,直接最小化两者之间的距离,加快训练时模型的收敛速度。 通过在模型中引入DIoU 损失函数,在实验中显著地提高了模型预测精度,并且不会产生过拟合问题。
3 实验及分析
为了使实验数据尽可能地与实际选煤厂工作环境相一致,在选煤厂实地进行数据采集。 从采集到的视频中截取1350 张煤与矸石混合场景下的图像,并采用labelImg 标注软件对图像进行详细的人工标注,选取其中1137 张图像用于模型训练,其余的213 张图像用于模型测试,所有对比模型在训练时均使用水平翻转和随机裁剪等图像增强方法。实验环境为pytorch1.2、python3.6,使用一张GTX 1080Ti 显卡。 实验中用到精度(Precision,P)、召回(Recall,R)、F1 值、mAP(mean Average Precision)值、帧率(FPS)、推理时间(Latency)、FLOPs 值和Params 值等评价指标。 TP(true positives)表示真正例,FP(false positives)表示假正例,FN(false negatives)表示假反例,TN(true negatives)表示真反例。 相关评价指标计算公式为

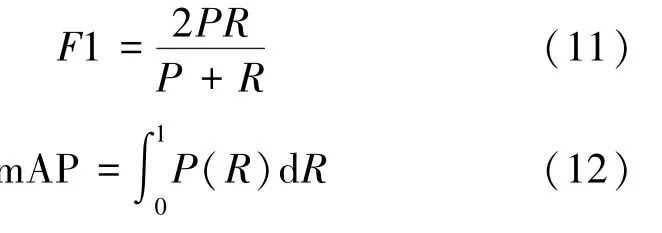
精度值P越高,表示检测结果的准确度越高;召回值R越高,表示检测结果的漏检率越低;F1 值越高,表示检测结果越好;mAP 值越高,表示检测结果越好;帧率越高,表示推理速度越快;推理时间Latency 越低,表示模型速度越快;FLOPs 值越低,表示计算量越小;Params 值越低,表示模型参数量越少。
3.1 骨干网络Darknet-Squeeze 分析
为了与原YOLOv3 模型进行比较,同时训练Darknet-53 骨干网络和改进后的Darknet-Squeeze骨干网络检测模型,训练过程中使用同样的Adam优化器,参数均使用默认值,2 个模型同样训练50个epoch,见表2。 使用Darknet-53 检测模型最终得到66.8 的mAP 值,使用Darknet-Squeeze 的检测模型得到67.5 的mAP 值,比修改前增加了0.7个点,推理时间和模型参数量都大幅减少。 图像分辨率为416 像素×416 像素,推理时间Latency 和FLOPs 为在一张GTX 1080Ti 显卡上的测试结果。

表2 Darknet-53 与Darknet-Squeeze 比较Tab.2 Comparison between Darknet-53 and Darknet-Squeeze
3.2 改进的特征融合neck 分析
在骨干网络Darknet-Squeeze 的基础上,为进一步增强YOLOv3 的neck 部分的各级特征融合能力,以适应煤矸石图像中小尺度物体较多的特点,引入SPP 结构,并采用转置卷积进行上采样。 在同样的实验环境和训练设置下,实验结果见表3。 其中,输入图像分辨率为416 像素×416 像素,推理时间Latency 和FLOPs 为在一张GTX 1080Ti 显卡上的测试结果。 改进后的特征融合neck 模型在小幅增加模型大小的情况下,取得69.2 的mAP 值,在原来的YOLOv3 模型基础上提升了2.4 个点,在Darknet-Squeeze 模型基础上增加了1.7 个点,证明了该方法的有效性。

表3 精度、速度和大小比较Tab.3 Comparisons of accuracy,speed and size
3.3 平衡损失函数与距离IoU 损失函数
为了平衡训练过程中的各项任务,进一步增强检测目标的定位准确性,尽量消除数据误标注和漏标注带来的影响,减轻难训练样本对最后模型精度的影响,在之前的模型基础上加入平衡L1 损失函数和DIoU 损失函数,在训练中参数a=0.5,r=1.5。 由于引入的损失函数仅在训练时起到优化模型的作用,因此不会改变模型的大小和推理时间成本。 实验结果表明,在不引入任何推理时间成本的前提下,模型检测精度大幅增加,mAP 值达到72.7,相比原来的YOLOv3 模型提升了5.9 个点,相比实验3.2 设置下的模型提升了3.5 个点,并改善了漏检现象。 各项具体参数比较见表4,图像分辨率为416 像素×416 像素,帧率(FPS)是在一张GTX 1080Ti 显卡上的测试结果。 矸石检测的可视化结果如图3 所示,图3(a) 对应原始的YOLOv3 模型检测结果,图3(b)对应改进骨干网络、特征融合neck、引入平衡L1 损失函数和距离IOU 损失函数后的最终模型的检测结果。由图3 可见,改进后的模型在检测结果和定位精度上明显好于YOLOv3 基准模型。 实验结果表明,无论是检测精度还是推理速度,本文提出的方法都能较好地满足实际运行需求。

图3 矸石检测结果Fig.3 Detection results of coal gangue

表4 最终模型的检测结果Tab.4 Detection results of final model
4 结 论
(1) 通过引入fire module 模块替代原来模型中的残差结构,改进原来的特征提取骨干网络,在同样的实验设置下,改进后的Darknet-Squeeze 模型在mAP 值、推理时间和模型大小上都优于原模型。
(2) 使用转置卷积替换最近邻上采样,引入空间金字塔池化SPP 模块来改进多级特征融合机制,在相同的实验设置下mAP 值进一步提高,达到69.2。
(3) 引入平衡损失函数和距离IoU 损失函数,在没有增加推理时间成本的情况下,改善了模型训练过程,在相同的实验设置下mAP 值进一步提高,达到72.7。
(4) 在一张GTX 1080Ti 显卡下,改进后的模型检测速度可达89 FPS,检测mAP 值可达72.7。极大地缩减了模型尺寸,加速了模型推理,并大幅提高了模型的检测精度。
实验表明,该方法能够较好地处理选煤厂中煤与矸石混合的复杂场景,具有较高的适应性和检测准确性,能够较好地满足生产现场的实际需求。
猜你喜欢
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
能源环境保护(2022年3期)2022-06-25
煤炭科学技术(2022年3期)2022-04-29
应用能源技术(2022年3期)2022-03-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
应用能源技术(2021年6期)2021-07-02
小天使·二年级语数英综合(2019年10期)2019-11-08
