
Ceph分布式存储系统在OpenStack云平台的设计与实现
2021-11-05 14:02席磊
数字传媒研究 2021年8期
席 磊
中国广播电视网络有限公司 北京市100045
引言
随着Openstack云平台的快速推广实践,其规模也逐步扩大,上层业务系统的数据总量迅速增加。传统数据存储方式已难以满足当前企业对存储系统的需求,致使存储逐渐成为了云平台发展的瓶颈。Ceph等基于软件定义的分布式存储技术打破了传统存储系统软硬件紧耦合的状况,将软件从硬件存储中抽象出来;将存储作为云平台中按需分配、实时调度的动态资源;通过文件存储、块存储和对象存储三种不同接口方式的存储类型,支撑了云平台的多种访问方式;在扩展性、伸缩性、安全性和容错机制等方面较之传统存储系统都有很大提升。软件定义的分布式存储系统正不断替代传统的存储系统,成为企业构建云平台的首选存储架构。
Ceph是一种开源软件定义分布式存储系统,因为其优秀的设计理念及统一存储(同时提供块、对象、文件三种接口)的特点被人们接受,已发展为稳定可商用的统一存储,得到广泛的应用和发展,是目前云操作系统OpenStack环境下的主流存储系统。
2 Cpeh基本原理及架构
Ceph是一种为优秀性能、可靠性和可扩展性设计的统一的、分布式的存储系统。“统一”代表Ceph具备一套存储系统同时提供对象、块和文件系统三种存储接口的能力,可满足不同应用需求的前提下简化部署和运维。而“分布式”则意味着真正的无中心结构和没有理论上限的系统规模可扩展性。
Ceph是目前OpenStack社区中最受重视的存储方案,具有诸多优势,如扩展能力、可靠性、自维护等。文章将对Ceph的逻辑架构、核心组件、关键工作流程等进行扼要介绍。
2.1 Ceph的逻辑架构
Ceph的逻辑架构层次参见图1。自下而上的三层结构分别如下。
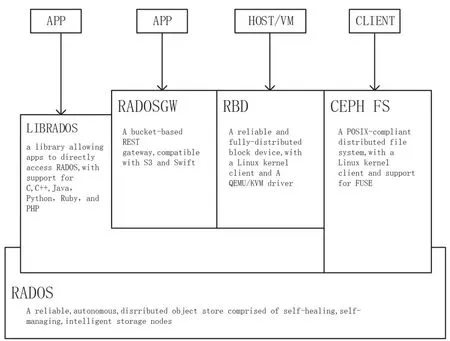
图1 Ceph存储架构图
2.1.1 RADOS基础存储系统
可靠、自动化、分布式的对象存储(Reliable,Autonomic,Distributed Object Store)是Ceph集群的基础,Ceph中的一切数据最终都以对象的形式存储,而RADOS就是用来实现这些对象存储的。RADOS层为数据一致性及可靠性提供保证。
2.1.2 LIBRADOS基础库层
LIBRADOS对RADOS进 行抽象和封装,并向上层提供API,以便直接基于RADOS进行应用开发,实现对RADOS系统的管理和配置。
2.1.3 应用接口层
这一层包括RADOS GW(RADOS Gateway)、RBD(Reliable Block Device)和Ceph FS(Ceph File System)三个部分,在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口。其中,RADOS GW提供对象存储应用开发接口,它有与Amazon S3和OpenStack Swift兼容的接口;RBD提供标准的块设备接口,RBD类似传统的SAN存储,提供数据块级别的访问;Ceph FS提供文件存储应用开发接口,兼容POSIX的文件系统,可以直接挂载为用户空间文件系统。
2.2 RADOS的核心组件
Ceph的高可用、高可靠、无单点故障、分布式对象存储等一系列特性均由RADOS提供。RADOS主要由OSD、Monitor、MDS(只有文件系统才需要)三类节点组成。
2.2.1 OSD(Ceph对象存储设备)
OSD是Ceph集群中存储用户数据并响应客户端读操作请求的唯一组件,负责将实际数据以对象的形式存储在Ceph集群节点的物理磁盘上,它是Ceph中最重要的一个组件。OSD的数量最多,一般与物理磁盘数量相等。OSD可以被抽象为两个组成部分,即系统部分和守护进程(OSD deamon)部分。OSD的系统部分实际为一台至少包括一个单核的处理器、一定数量的内存、一块硬盘以及一张网卡的计算机。守护进程(OSD deamon)负责完成OSD的所有逻辑功能,包括与monitor和其他OSD deamon通信以维护更新系统状态,与其他OSD共同完成数据的存储和维护,与client通信完成各种数据对象操作。
2.2.2 Monitor(Ceph监视器)
Monitor通过一系列map(包括OSD、MONITOR、PG、CRUSH、CLUSTER等的map)跟踪并维护整个集群的状态,Monitor不实际存储数据,其数量较OSD少很多。
2.2.3 MDS(元数据服务器)
MDS元数据服务器不直接提供任何数据,数据都由OSD为客户端提供。MDS用于缓存和同步分布式元数据,管理文件系统的名称空间。
2.3 Ceph数据存储流程
先介绍几个概念:
(1)File:客户端需要存储或者访问的对象文件。
(2)Ojbect:RADOS所 看到的“对象”。RADOS将File切分成统一大小得到的对象文件,以便实现底层存储的组织管理。
(3)PG(Placement Group,归置组):对object的存储进行组织和位置映射,可理解为一个逻辑容器,包含多个Ojbect,同时映射到多个OSD上,一个PG会被映射到n个OSD上,而每个OSD上都会承载大量的PG,PG和OSD之间是“多对多”映射关系。PG是Ceph实现可伸缩性及高性能的关键,没有PG而直接在OSD上对数百万计的对象进行复制和传播既困难又消耗计算资源。
RADOS寻址过程中的三次映射如图2所示,分别是:File到Object的映射、Object到PG的映射、PG到OSD的映射。
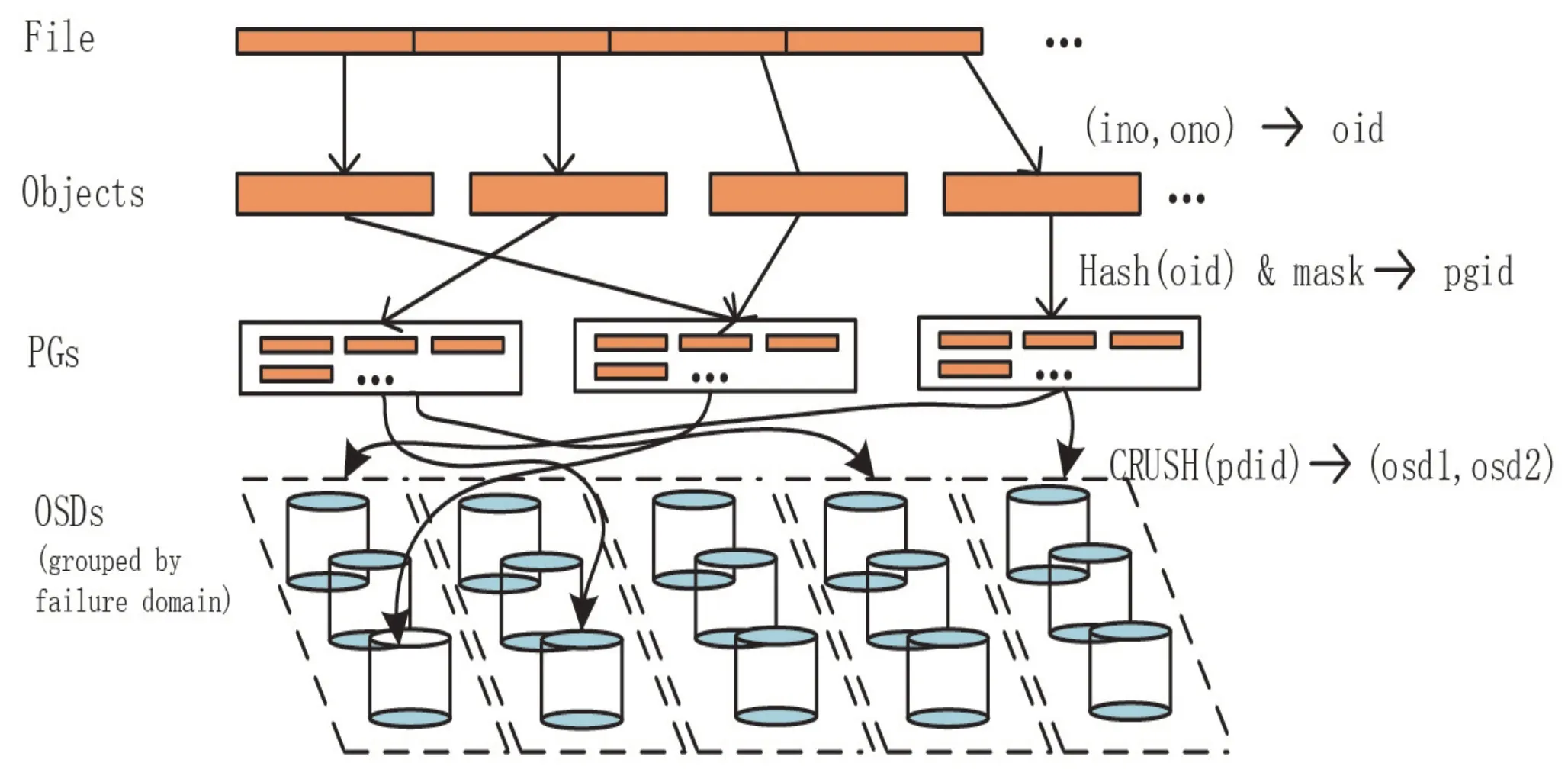
图2 Ceph存储流程示意图
2.3.1 File到object映射
这次映射将用户操作的file映射为RADOS能够处理的Object。
Client客户端先联系Monitor节点并获取cluster map副本,通过map得到集群的状态和配置信息;将文件转换为size一致、可以被RADOS高效管理的Object,一份Object拥有一个ID号。
2.3.2 Object到PG映射
通过将对象oid和PG共同经过哈希函数计算,确认对象Object存放在哪个PG中,实现Object和PG之间的近似均匀映射。Object和PG是多对一的关系。
2.3.3 PG到OSD映射
这次映射通过Crush算法将PG映射给存取数据的主OSD中,主OSD再备份数据到辅助OSD中。PG和OSD是多 对 多 的关系。至此,Ceph完成了从File到Object、PG和OSD的 三 次 映射过程,整个过程中客户端通过自身计算资源进行寻址,无需访问元数据服务器查表的数据寻址机制,实现去中心化,避免了单点故障、性能瓶颈、伸缩的物理限制,这种数据存储和取回机制是Ceph独有的。
3 Ceph分布式存储的设计与实现
大规模Ceph分布式存储系统的规划设计及实现是一个复杂的过程,要考虑的问题很多,如不同类型(块、文件、对象)存储接口的选择、存储网络设计规划、Ceph的对接方案、硬件配置如何在性能和成本之间取得平衡等等一系列问题,而这些都需在充分了解平台自身业务特性的基础上,提出个性化的解决方案。下面对Ceph在OpenStack云平 台 中的 设计、优化改进及部署实现进行论述。
3.1 基于ISCSI的Ceph块存储实现
ISCSI(Internet Small Computer System Interface)是 一 种成熟的技术方式,常见的各种系统(包括操作系统和应用系统)一般都对ISCSI有很好的支持。
Ceph集群支持三种形式的存储接口:文件、对象、块,其中块接口(RBD)与SCSI块设备读写所要求的接口一致,因此可以作为ISCSI服务的后端存储设备。基于ISCSI的Ceph块存储在OpenStack云平台中的实现方法,对接方式为Ceph分布式块存储集群通过ISCSI对接虚拟化层,虚拟化层再通过相应驱动 对 接OpenStack的Cinder、Nova组件,为虚拟机提供本地系统和数据盘服务。
ISCSI是 一 种SAN(Storage area network)协议,使用TCP/IP协议来传递SCSI命令与响应,它定义了SCSI指令集在IP网络中传输的封装方式。ISCSI为C/S结构,客户端称为Initiator,服务端称为target。
3.1.1 ISCSI target
即磁盘阵列或其他装有磁盘的存储设备。它是一个端点,不启动会话,而是等待发起者的命令,并提供所需的输入/输出数据传输。
3.1.2 ISCSI initiator
就是能够使用target的客户端,它是启动SCSI会话的端点,发送SCSI命令,通常是服务器。也就是说,想要连接到ISCSI target的服务器,必须安装ISCSI initiator的相关功能才能够使用ISCSI target提供的硬盘。
Ceph基 于ISCSI协 议 对 接 虚拟化层的逻辑架构分为三层,分别是ISCSI客户端(计算节点)、ISCSI网关、Ceph集群。ISCSI target对 接Ceph的RBD接口,为上层计算节点ISCSI initiator提供服务,实现计算节点通过ISCSI访问底层存储,进行卷的创建、修改、删除等管理性操作。如图3所示。
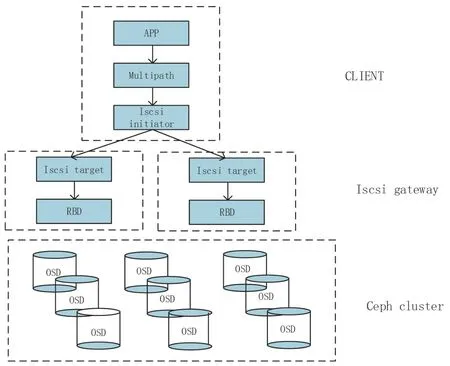
图3 ISCSI协议使用Ceph RBD基本架构图
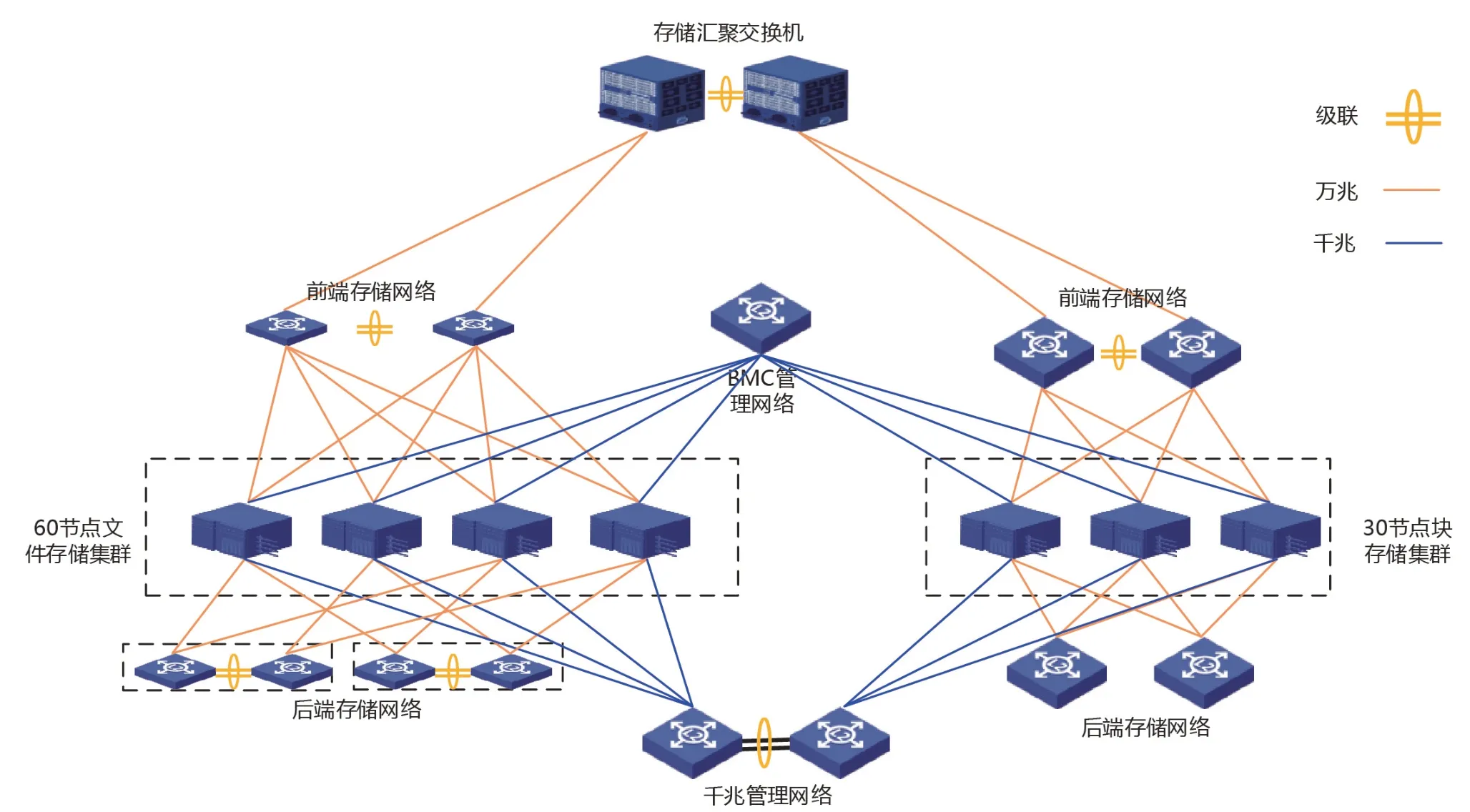
图4 ceph存储网络系统网络拓扑图
3.2 巧用Crush分组,避免存储后端网络瓶颈
在存储网络规划中,首先需将各网络平面分开,一般划分4张网络平面,分别是IPMI管理网、千兆带内管理网、存储前端网络(万兆)、存储后端网络(万兆)。IPMI管理网及千兆带内管理网流量较低,我们不做讨论。不论是存储前端或后端网络,一般情况下依据各分布式存储集群的数量,每个集群后端采用数量不等的48口万兆交换机采用两两级联的方式提供服务,网口采用双网口绑定Bond4的方式提供。其中,存储后端网络由于存在大量的数据重构,流量极高,需要进行针对性的设计考虑。下面介绍一种在大规模Ceph集群组网过程中,利用Crush分组机制避免交换机成为后端网络瓶颈的设计思路。
对于节点数量少于48的分布式存储集群,使用2台48口万兆交换机AB即可,AB之间使用主备模式,各节点的两万兆后端网络也使用bond4模式进行双上联,后端网络的重构数据不会跨交换机流动。
但对于节点数量大于48而小于96的分布式存储集群,存储后端存储网络共使用4台48口万兆交换机ABCD,使用2根40Gb/s级联线将交换机AB连接一起做堆叠,交换机CD之间同理,这种情况下,后端网络的重构数据将在交换机AB之间流动,极端情况下可能形成网络拥塞。
针对该问题,可以通过Ceph分布式集群进行Crush分组进行规避。以集群规模为60节点为例,按照20节点为一组,分为三组,仍提供一个数据存储池。其中前2组连接一个万兆交换机A,第三组连接第二个万兆交换机B,A与B使用两根40Gb/s级 联线 连 接,Crush分 组原理决定了各个分组之间几乎没有数据流动,因为一份数据的副本或纠删块均在一个组内。所以两交换机之间的级联线只会有心跳数据通过,不会存在业务数据量通过,也就不会成为网络瓶颈。如图5所示。
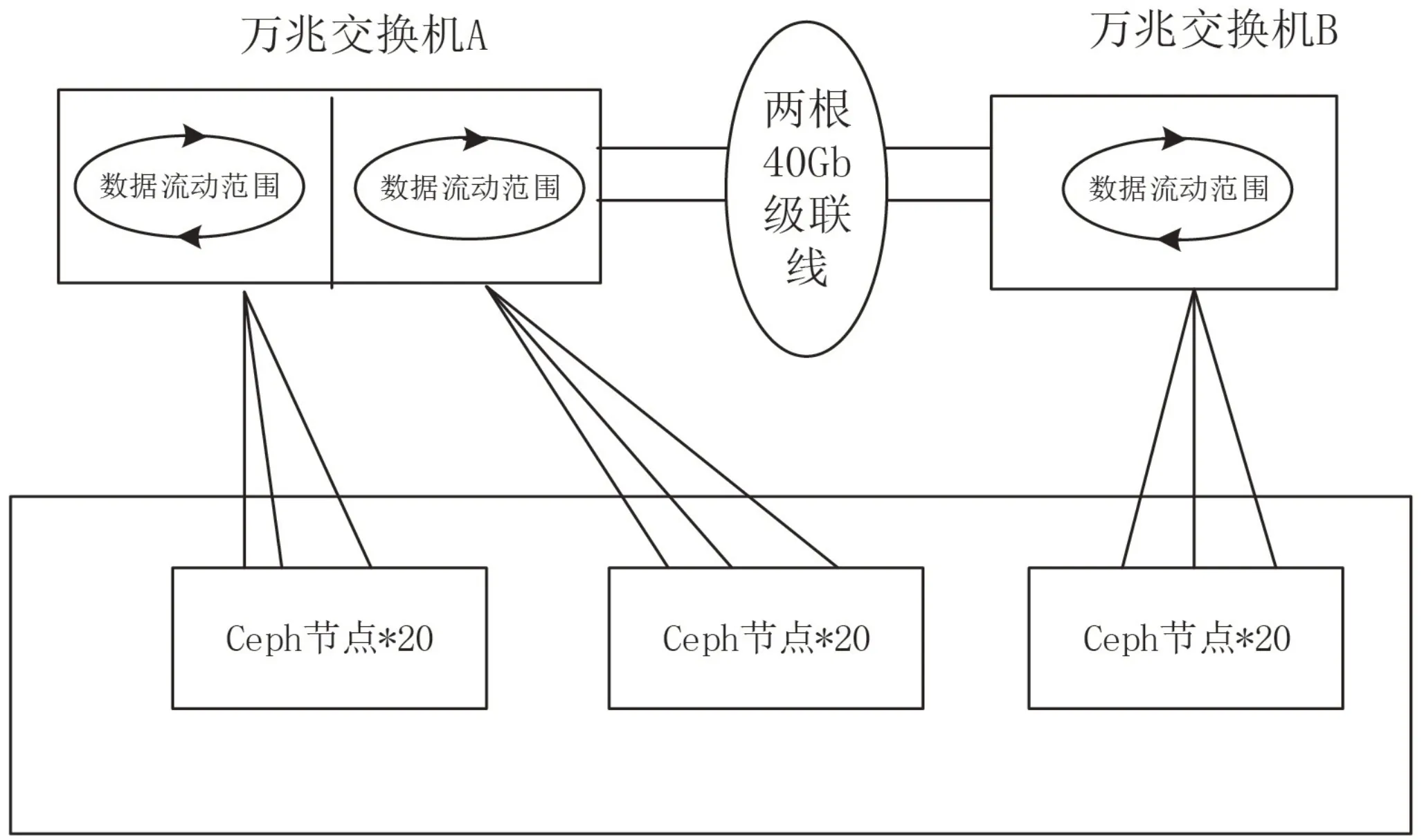
图5 Ceph存储后端网络示意图
3.3 SSD+HDD灵活混搭,匹配全业务需求
要满足虚拟机上各业务系统对所挂载的云硬盘差异化性能需求,如对IO需求、延迟大小、网络吞吐能力、并发访问等,使用单一配置的Ceph存储节点难以达到要求,建议在官方文档提倡使用SSD+HDD混搭的模式的基础上,将SSD和HDD以不同比例进行混搭,形成不同能力的存储资源池,从而在性能和成本之间取得平衡。具体项目中可通过调整Ceph分布式块存储集群Crush-Map,设置Crush ruleset来将不同类型磁盘划分到同一个存储资源池,从而制作成高速(highpool)、中速(midpool)、低速(lowpool)三组逻辑存储池,对外提供不同性能的云硬盘服务;并结合基于带宽、IOPS两种策略的QoS,达到更加合理、均衡的使用块存储服务。
3.4 小文件聚合存储,优化存储性能
如果存储系统中存在海量小文件,每个小文件存储都会执行一次全写流程,当大量小文件并发访问时,将导致磁盘压力加剧,Ceph系统性能下降。
针对该问题,可设计一种将小文件聚合存储的功能,将小对象聚合为大的,基本思路是将新创建的小文件以紧密排列的方式(以4KB对齐)写入到一类特殊的文件(聚合文件)中。在读文件时也不再读取小文件的对象,而是从聚合文件的对象中读取源文件数据,每个聚合文件包含多个聚合对象(4MB)。客户端发送的读请求会将小文件所在对象读入缓存,提高后续小文件的缓存命中率,有效地缩短了I/O路径。
小文件聚合存储有效降低小文件写入磁盘次数、减轻写数据压力;方便落盘和减少磁盘碎片化,同时提升小IO的性能;提高磁盘使用率,读小文件时将所在对象读入缓存,提高读命中率、缩短读I/O路径。
结束语
总体而言,Ceph作为目前OpenStack环境下的最受关注的存储系统,通过有针对性的设计与优化,可以满足Iaas平台对于存储系统的需求。但Ceph在管理便捷性、性能优化、业务场景适配等方面仍有许多可发掘的空间,同时企业对于自身存储需求也需要不断的发掘,最终使Ceph性能得以最大化,为企业提供更加稳定可靠的存储服务。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
传媒评论(2019年5期)2019-08-30
网络安全和信息化(2019年7期)2019-07-10
发明与创新·大科技(2019年12期)2019-03-17
电子制作(2019年24期)2019-02-23
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
传媒评论(2018年2期)2018-06-06
中国公共安全(2017年11期)2017-02-06
中国教育信息化(2015年12期)2015-08-24
