
基于混合高斯分布的广义零样本识别
2021-11-05 02:48:00李晓瑞
上海电力大学学报 2021年5期
邵 洁, 李晓瑞
(上海电力大学 电子与信息工程学院, 上海 200090)
由于数据信息的爆炸式增长和信息标注的速度缓慢,所以零样本识别成为一项重要而富有挑战的研究[1]。传统的图像识别只能识别训练集中的类别[2],然而在实际应用中,期望识别的样本包括训练的类别和不存在训练集的类别,传统的零样本识别只能识别不存在训练集的类别。为了更好地应用于实际生产生活,广义零样本识别应运而生[3]。从定义可以看出,广义零样本识别不仅要求学习训练集中存在的类别,同时还要将学习到的知识转化到训练集中不存在的类别中去。
广义零样本识别的方法是通过建立视觉特征和语义特征的联系来达到识别的目的。文献[4-7]通过将视觉特征映射到语义特征来实现零样本识别。由于视觉特征是高纬度的特征,而语义特征是低纬度的特征,所以将高纬度的特征映射到低纬度,不可避免地会造成信息丢失。为了解决这一问题,文献[8-9]提出将语义特征映射到视觉特征。由于同一个语义特征可能对应多个视觉特征,有可能直接造成映射错误,因此该方法仍存在争议。
视觉特征和语义特征交叉映射是近年来常用的且效果很好的一种方法,如文献[10-13]就是采用了这类方法。其中,文献[10]提出了利用变分自编码器(Variational Auto Encoding,VAE)创建一个共享隐藏空间的模型,通过该模型可以将视觉特征和语义特征联系起来。但是文中VAE运用了标准的高斯分布,相较于标准高斯分布,混合高斯分布可以更好地拟合样本的实际分布。
此外,注意力机制对图像处理的发展起到了巨大的推动作用。注意力机制分为硬注意力机制和软注意力机制两类[14]。目前很多方法都是应用软注意力机制,其特点是利用各个特征的关系,更新注意力层的权重,如文献[15]。文献[16]提出了硬注意力机制的概念,其特点是注意力机制层的权重往往是固定的,或者在提取特征时只提取高纬度特征的某一部分特征。文献[17]将硬注意力机制应用于图片的注释,受到注意力机制的启发,对不同的高斯分布给予不同的权重,构成了混合高斯分布,进而提升了模型的识别能力。
本文提出了一种基于混合高斯分布的广义零样本识别的方法(Multi-channel Gaussian Mixture-VAE,MGM-VAE)。通过引用混合高斯分布,建立了一个更好的视觉特征和语义特征联系。同时,结合多通道以及对应的权重层,扩大了算法的解空间,使算法在更广泛的解领域寻求最优解。
1 算法介绍
1.1 广义零样本模型
假设数据库D={(v,y,a(y))|v∈V,y∈Y}是由训练数据库和测试数据库构成,v表示由卷积层提取的视觉特征,y表示v所属的类别,a(y)表示语义特征,V为视觉特征的集合,Y为类别的集合。用VS和AS表示训练类别的视觉特征集合和语义特征集合,对应的标签集合为YS,即已知的类别。用VU和AU表示识别类别的视觉特征集合和语义特征集合,对应的标签集合为YU,即未知的类别。由此得出YU∩YS=Ø,YU∪YS=Y。零样本识别的目的是为了找到一个函数fZ:v→YU,广义零样本识别的目的是为了寻找函数fGZ:v→Y。
1.2 混合高斯广义零样本识别算法
MGM-VAE算法流程如图1所示。其中,浅灰色的线条和方框代表视觉特征训练过程,深灰色代表语义特征的训练过程,黑色代表识别过程。白色方框的CW代表通道权重层,视觉特征和语义特征在训练过程中分别更新各自的CW网络;Softmax分类层属于测试阶段。

图1 MGMVAE算法流程
不同于传统的编码器,本文采用了多通道编码器算法。以4层为例,编码器结构如图2所示。

图2 多通道编码器结构示意
整个算法可分为训练和识别两个过程。首先对模型进行训练,利用训练模型分别将视觉特征和语义特征映射到各自的VAE模型的隐藏空间中,再利用隐藏空间的变量恢复到对应的视觉特征和语义特征。识别过程就是将待分类样本的视觉特征和语义特征放入网络得到对应的隐藏空间,再根据隐藏空间进行样本的识别和分类。本算法的主要特点包括:一是选用了与文献[10]相同的结构建立视觉特征和语义特征的映射;二是引入了适应能力更强的混合高斯模型,以便于更好地建立两种特征的联系。同时,为了显示不同的通道在识别任务中的影响力,引入了通道权重层,加强识别率较好通道的权重,并降低识别率较低通道的权重。
1.3 loss函数
模型的loss函数可以简单地写为
L=λ1LCA+λ2LDA+LVAE
(1)
式中:λ1,λ2——参数;
LCA——交叉loss函数,表示同一个类别、不同特征恢复到另一种特征的能力;
LDA——距离loss函数,表示同一个类别、不同特征的隐藏空间的距离;
LVAE——VAE模型loss函数,表示同一个类别、同一个特征理论概率分布和实际概率分布的差距。
1.3.1 交叉loss函数
交叉重构能力是指在同一个类别条件下,从一种特征的VAE模型的隐藏空间提取特征,然后经过另外一种特征的VAE模型的解码器还原到本来特征的能力。LCA就是用于描述交叉重构后还原的特征与原特征之间的差异,具体公式为
(2)
式中:v,a——视觉特征和语义特征;
xa,xv——a种属性和v种属性对应的样本,属于同一个类别;
Ev——v种属性VAE模型的编码器;
Da——a种属性VAE模型的解码器。
1.3.2 距离loss函数
视觉特征和语义特征经过编码后映射到各自的隐藏空间,LDA的作用就是计算两个隐藏空间的EM(Earth-Mover)距离,其近似计算公式为
(3)
式中:μv,μa,σv,σa——对应属性的μ层和σ层。
1.3.3 VAE模型loss函数
LVAE的公式为
(4)
式中:k——样本特征的类型,k=v,a;
E——期望;
q,p——先验分布和后验分布;
zk——隐藏空间;
DKL,β——KL(Kullback Leibler)散度及其影响程度。
1.3.4 通道权重层的更新
通道权重层不同于传统的神经网络,同一通道的每一个权重值都相同,同一通道的值可能不同。针对这种网络采用了更新策略,具体如下
(5)

βo——学习率,取为0.001;

Q——通道数目。
2 实验分析
本文利用由Imagenet预训练的RES-101网络提取视觉特征,对语义特征进行编码,最后将两种特征放入各自对应的VAE模型中训练。通过训练可以得到能提取隐藏特征的两个VAE模型,识别时将待识别的视觉特征和语义特征放入MGM-VAE编码器中得到对应的隐藏特征,最后用一个Softmax分类器,即可达到广义的零样本识别。
2.1 数据库介绍
本实验调用了3种常见的零样本识别数据库,分别为CUB[19],AWA2[20],SUN[21],其具体信息如表1所示。

表1 数据库具体信息
2.2 实验结果及分析
参照其他实验分析,用S表示训练类别的准确率,U表示不存在训练类别但存在于测试类别的类别准确率,H=2SU/(S+U) 表示S和U的综合表现。为了验证算法的有效性和稳定性,本文将实验复现了15次,将15次关于H参数实验结果的平均值HAV用于分析算法的稳定性,最大值Hmax用于分析算法的有效性。
近年来较为先进的广义零样本学习算法的性能比较如表2所示。其中,DGAN,ReViSE,CADA-VAE都是应用了交叉映射的思路。DGAN采用一个条件VAE、一个回归网络和一个分类器实现了视觉特征和语义特征的交叉映射。ReViSE利用自编码网络实现了视觉特征和语义特征的联系。CADA-VAE改用VAE代替了自编码网络,实现了视觉特征和语义特征的联系。
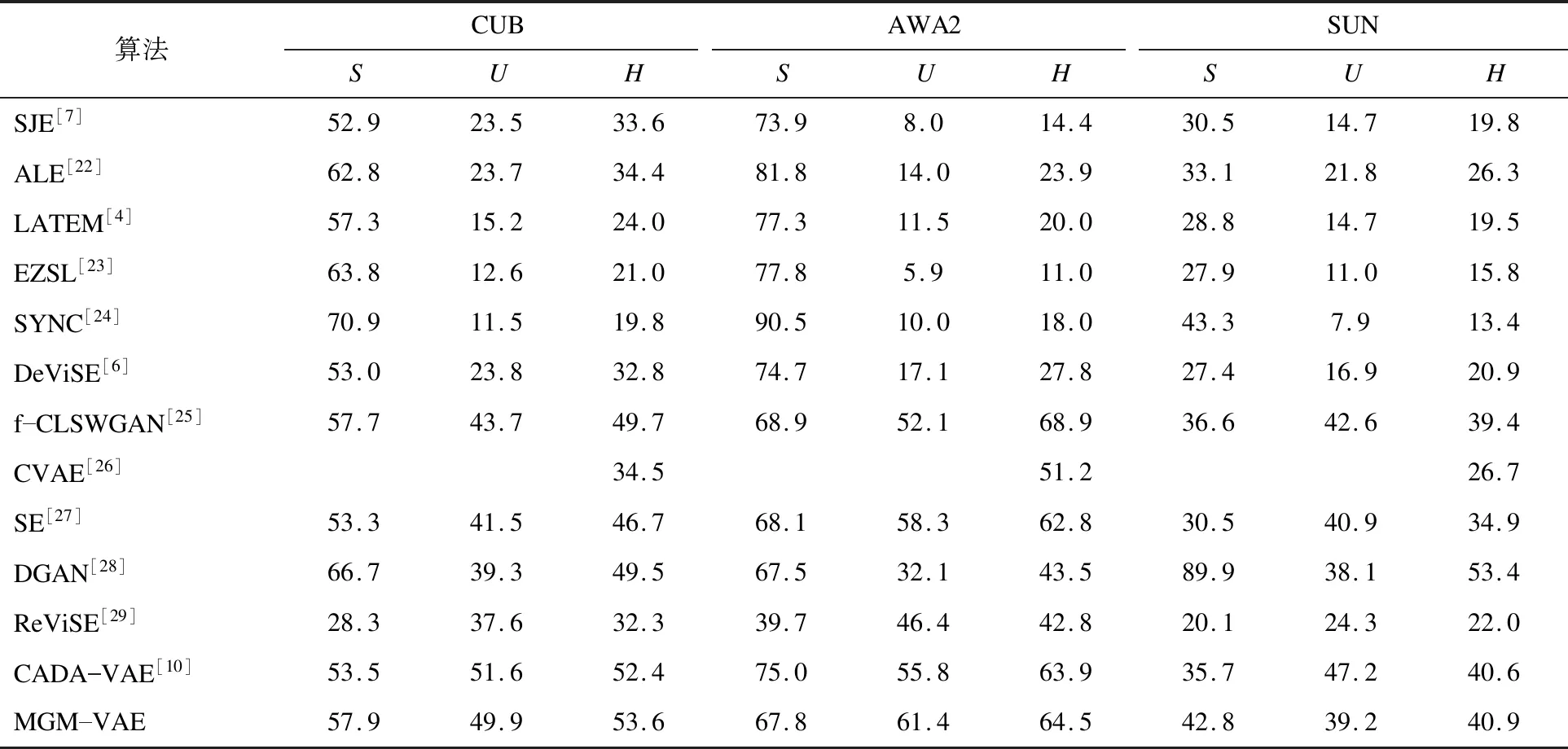
表2 不同广义零样本学习算法的性能比较
由表2可以看出,对于体现模型的综合性能参数H来说,本文算法几乎领先所有的先进算法。与CADA-VAE相比,在数据库CUB中本文算法的Hmax提升了1.2,在数据库AWA2中提升了0.6,在数据库SUN中提升了0.3。
接下来将分别讨论几个主要参数对实验结果HAV的影响。为了便于分析,本文以数据库CUB为例。
2.2.1 隐藏空间维度
隐藏空间维度对性能参数HAV的影响如图3所示。由图3可以看出,当隐藏空间的维度小于100时,随着维度的增加,HAV的值越来越大,即算法的表现越来越好;当隐藏空间的维度超过180时,随着维度的增加,算法的表现越来越差。
2.2.2 通道权重层最大值
在编码器中有多个通道,不同通道的权重可能不同,同一个通道的权重值均相同。为了便于寻找一个最优解,需要赋予通道权重层一个合适的初值,将多个通道中的一个值设定在0.2~5.0,定义为通道权重层最大值;其他通道设为0.1。通道权重层最大值对HAV的影响如图4所示。由图4可以看出:当通道权重层最大值小于1时,随着通道权重层最大值的增大,算法的表现越来越好;当最大值大于1时,模型的表现随着最大值的增大而越来越差。
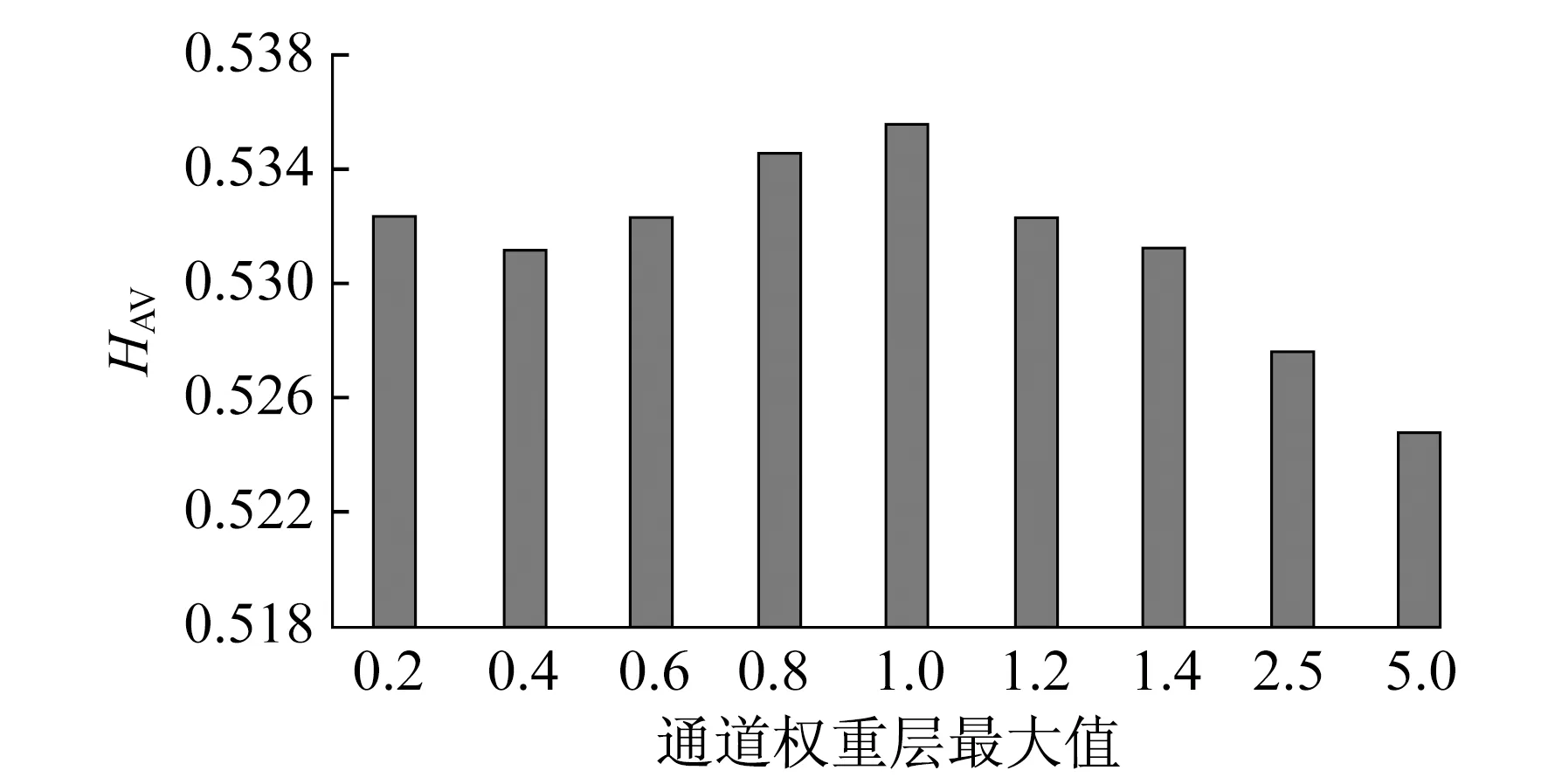
图4 通道权重层最大值对性能参数HAV的影响
2.2.3 通道层数
根据前文的分析,将隐藏空间的维度设定为100,权重层最大值为1.0。通道层数对HAV的影响如图5所示。由图5可以看出:当通道层数小于6时,随着通道层数的增加,算法的表现越来越好;层数超过6时,算法的性能开始下降。

图5 通道层数对性能参数HAV的影响
3 结 语
本文提出了一种基于混合高斯模型的广义零样本识别的方法,通过在VAE模型的编码器中引入多个通道,可以更好地将视觉特征和语义特征映射到隐藏空间。同时,为了区分不同的通道对识别结果的影响,加入了通道权重层。最后,通过实验分析验证了算法的特性和有效性。
猜你喜欢
数字通信世界(2021年3期)2021-04-09 02:05:00
湖北理工学院学报(2020年4期)2020-08-22 06:43:26
开放教育研究(2020年2期)2020-03-31 01:54:14
计算机应用与软件(2017年4期)2017-04-24 10:39:07
现代语文(2016年21期)2016-05-25 13:13:44
新校长(2016年8期)2016-01-10 06:43:59
大连民族大学学报(2015年2期)2015-02-27 08:28:11
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
