
基于NAR-KF的心音信号仿真研究
2021-11-04 10:25周克良王威郭春燕
现代电子技术 2021年21期
周克良,王威,郭春燕
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引言
心音信号即心脏产生的声音所形成的信号[1],是通过人体血液流通使心脏瓣膜打开或关闭时振动产生的声音,是人体不可或缺的生物信号。为了更加精确地了解人体心音信号的特征[2],近年来,大量学者对心音信号的预处理进行了研究。
心音信号的预处理包括去噪、包络提取、分段定位以及特征提取[3]。在去噪方面,文献[4]提出了基于小波变换的心音信号降噪方法,对于心音信号的降噪有较为明显的效果,但是由于阈值函数的复杂程度导致适应性不足,方法普适性存在缺陷。针对该缺陷,文献[5]提出了双自适应提升的小波变化去噪算法,在一定程度上令心音信号的预测过程与更新过程都有了适应性。文献[6-7]都是在小波变换去噪的基础上对前文进行了改进,并且有一定的成效。但是对于小波变换而言,由于硬阈值函数的不连续以及软阈值函数对于特定函数的不适用性都一定程度上限制了小波去噪的性能。
本文所运用的卡尔曼滤波算法需要对心音信号进行数学模型的建立。心音信号由第一心音信号(S1)、第二心音信号(S2)、第三心音信号(S3)、第四心音信号(S4)组成[8],由于S3与S4大多数情况下检测不到,一般对心音信号的分类研究与建模在于对S1与S2的研究。文献[9]采用HHS-EMD算法对心音信号进行特征提取与分类识别,获得了84.5%的精确度。文献[10]运用MFCC-SVM方法对心音信号进行特征提取与分类,精确度高达92%,然而文献[9]与文献[10]所选用的特征提取算法对信号的频率与帧数要求较高,多帧数据易造成信息的损失。文献[11]运用MFSC-CNN对心音信号进行扩维与分类,精确度达89.6%,虽然该文献所用的方法在普适性上得到了提升,但精确度对比文献[10]有所下降。
本文将采用非线性自回归(NAR)神经网络对心音信号样本进行训练,构建心音信号图(Phonocardiogram,PCG),并通过该模型作为卡尔曼滤波的实际值对心音信号的样本进行滤波。由于NAR神经网络对时间序列的反馈和记忆功能,所建立的数学模型在普适性以及精度上预计会有明显的提升。最后通过与理论值进行对比,计算信噪比、最小均方误差等性能参数,得出该算法的优缺点。
1 心音信号的系统模型
为了便于对心音信号的各个波段进行详细的了解,医学上对心音信号的各个波段进行了详细的命名:第一心音信号(S1)产生于等容收缩期,第二心音信号(S2)产生于等容舒张期,而第三心音信号(S3)与第四心音信号(S4)存在于心脏的舒张充盈期。通常在正常成人体内靠S1与S2进行听诊,S3与S4持续时间极短,不易进行病理判断,故本文不对S3与S4进行研究。正常心音信号如图1所示。
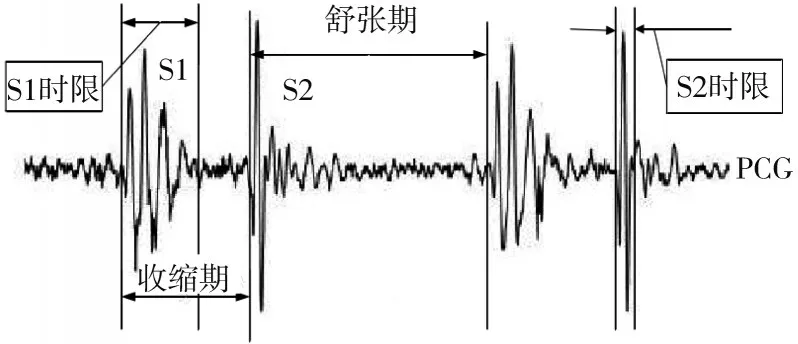
图1 正常心音信号模型图
2 NAR神经网络系统辨识
本文通过收集一系列心音信号数据(数据来自于赣州某医院),将该类心音信号作为样本输入神经网络中。
典型的时间序列神经网络包括NAR与NARX神经网络。NAR神经网络中,时间序列y(t)仅与历史值相关,根据历史值进行预测,其关系如下:

式中:t表示时间;n为时间序列的延迟阶数。
NAR神经网络一般由三层神经网络构成,其分别为输入层、隐含层与输出层,其基本构成如图2所示。

图2 NAR神经网络结构示意图
将已经收集好的心音信号输入至NAR神经网络。其中,心音信号由wav格式读取,选取隐含层节点个数为2,函数逼近方式为梯度下降法,其定义如下:
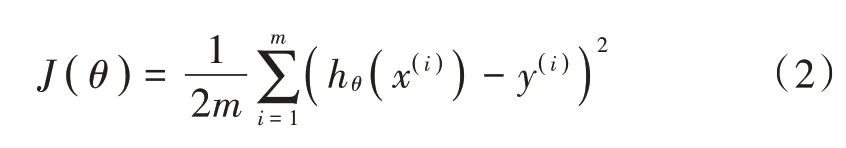
令J(θ)最小,即模型预测心音信号与实际心音信号之间的误差达到最小值。实验结果如表1所示。

表1 神经网络延迟阶数与性能参数
由表1可得,延迟阶数与均方误差、训练时长没有明显的对应关系,由于延迟阶数过大可能导致过拟合现象,故本文采集延迟阶数m为2~6之间的数据。由实验数据可得,选用m=4的实验性价比更高。
3 卡尔曼滤波算法
卡尔曼滤波一般适用于线性离散化系统,运用实际测量值与模型值之间的关系,根据前一步的协方差矩阵决定下一步各个数据的权重值,从而决定卡尔曼预测值。其中,离散线性的状态方程以及观测方程的一般形式可表示为:
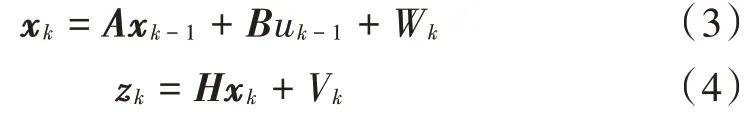
式中:xk为系统状态矩阵;zk为观测矩阵;W(k)~N(0,Qk-1)为随机高斯白噪声输入;V(k)~N(0,Rk)为观测噪声;B为噪声驱动矩阵;uk为输入量,而对于心音信号来说,没有驱动信号时刻影响状态方程,故省略该项。
对于上述线性化模型(3),模型(4),进行状态预计更新,在本文中只需代入预测值为由NAR神经网络建立的模型值即可,无需逐步更新预测值,而实际值为需要进行降噪输入的心音信号。接下来需要对协方差矩阵进行更新,即:
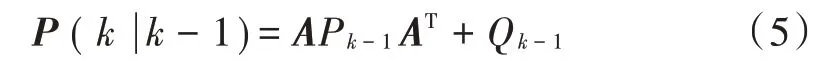
计算该系统的卡尔曼增益Kg,该值由上一状态的协方差决定。

由于卡尔曼滤波需要根据上一步的预测偏差决定下一步的预测值,故预测偏差由下式给出:

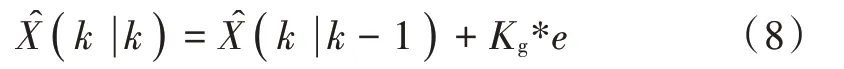
对协方差矩阵P(k|k)进行更新:

之后令k=k+1,将各预测值代入相应的方程中,回到式(5)重复估计,直到k=N停止运算,得出卡尔曼预测心音信号曲线。
4 实验验证与分析
4.1 实验数据设置
本文选用的实验数据为正常青年临床采集的心音信号数据(数据来自于赣州某医院),数据集包括1 000个样本,医院已做好分段工作,故本文选取500个第一心音信号样本与500个第二心音信号样本,按照本文第2节介绍的方法对心音信号进行建模。每一组数据设置训练样本占总样本数的70%,验证集为15%,测试集为15%,由于训练集与测试集是分开的,故在一定程度上避免了过拟合的现象。
4.2 实验环境设置
本文使用的NAR神经网络在Matlab中Neural Net Time Series中实现,卡尔曼滤波算法由Matlab编程实现。所有训练和测试都是在PC中完成,处理器为Intel Core i7,内存为8 GB。
4.3 实验结果
神经网络的训练向网络输入一定量的样本,在一定算法的调节下,不断优化网络权值,使网络的输出与预期值相符。训练神经网络主要包括:网络架构的调整、各层激活函数的选择、模型编译优化器的选择,训练中既要使训练样本均方误差不断减少,提高训练精度,也要使验证集准确率提高,防止模型过拟合。
本文所用的性能评估指标选用信噪比(Signal-Noise Ratio,SNR)、均方误差(MSE)评价心音信号的降噪效果。其中,信噪比即为信号的平均功率和噪声的平均功率之比,以分贝(dB)作为度量单位,即:
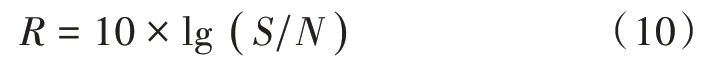
均方误差是表现预测数据与实际数据对应点误差的平方和的均值,其计算公式为:

将NAR神经网络训练好的模型值代入卡尔曼滤波的预测值中,再将收集到的心音信号数据输入至实际值中,得出的结论如图3所示。根据图3可以明显看出,经卡尔曼滤波后的第一心音信号噪音比原采集的心音信号噪声有明显的降低。接下来需要将降噪性能量化,得出降噪前与降噪后的噪音评估指标。表2为第一心音信号在降噪前经过NAR建模以及通过模型进行卡尔曼滤波降噪的噪声评估指标值。

图3 滤波前后第一心音信号对比图
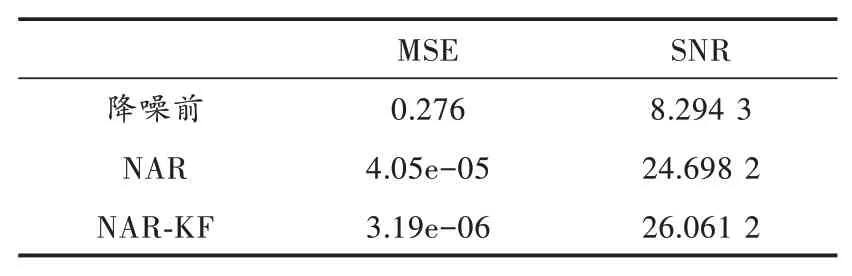
表2 S1各阶段的噪声评估参数
由表2可直观得出降噪前的均方误差值较大,达到了0.276,信噪比仅有8.294 3,而经过神经网络建模预测后的心音信号对比真实值的噪音有明显的降低,均方误差值为4.05×10-5,信噪比达到了24.698 2。而将神经网络建模后的预测值代入卡尔曼滤波中,再输入需要降噪的心音信号值,可见误差值达到了10-6级数,而信噪比更是大于26,可见经过神经网络建模与卡尔曼滤波后的心音信号在噪音级数方面得到了大幅度降低。
同理,将第二心音信号的样本输入至神经网络中,再通过卡尔曼滤波进行降噪,结果如图4与图5所示。

图4 原第二心音信号
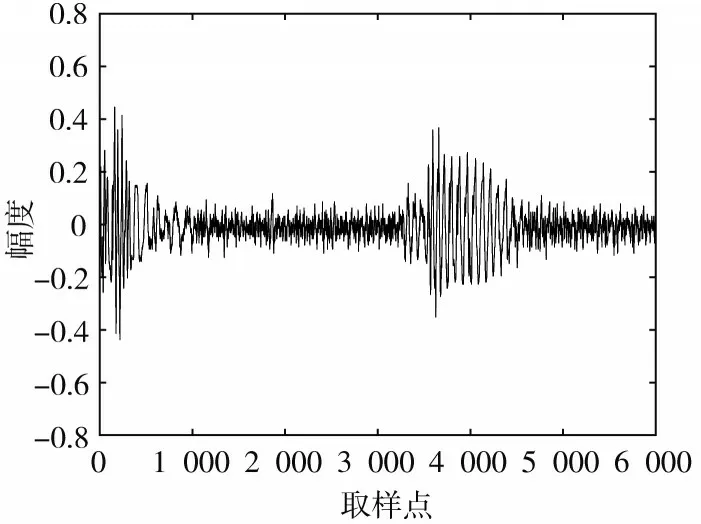
图5 经降噪后的第二心音信号
由于第二心音信号较第一心音信号更为复杂,故从直观角度来看降噪效果比第一心音信号逊色一些。表3为第二心音信号在降噪前,经过NAR建模以及通过模型进行卡尔曼滤波降噪的噪声评估指标值。
由表3可以得出,经过NAR建模后的均方误差明显降低,信噪比也有明显的提升,而经过卡尔曼滤波后的效果却不如第一心音信号明显,这是由于第二心音信号较第一信号而言更为复杂一些,通过建模得来的数据有过拟合的可能性,故卡尔曼滤波的预测值与实际值之间相差不大,这也是之后研究中需要解决的问题。
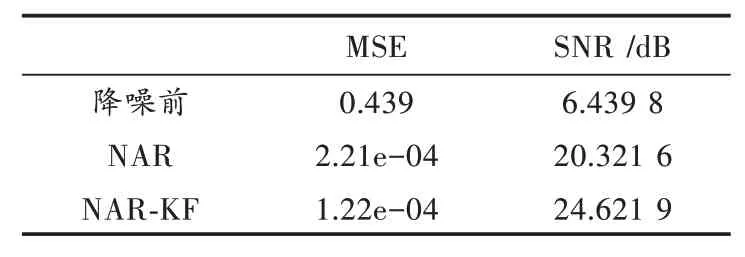
表3 S2各阶段的噪声评估参数
5 结论
本文通过对医学知识的先验理解,对心音信号进行了详细区分,即S1、S2、S3与S4,其中,S3与S4在临床检测中一般不常被获取到,故本文不做详细的研究,而对S1与S2进行了详细的研究与仿真。首先将来自医院的数据放入NAR神经网络框架中进行训练与测试,在同时考虑精度与训练时间的情况下得到了一组较为理想的模型,再将该模型输入卡尔曼滤波的预测值中,通过原心音信号进行滤波,得到的第一心音信号滤波值的均方误差为3.19×10-6,对比降噪前的0.276与经过神经网络的预测值4.05×10-5都有较为优越的降噪性能。而得到的第二心音信号对比降噪前的0.439也有较为明显的提升,然而对于NAR神经网络预测值而言没有级数上的优越性,如何解决NAR神经网络对于第二心音信号出现的轻微过拟合的问题将成为下一个研究的重点方向。
注:本文通讯作者为王威。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
今日中国·法文版(2020年7期)2020-07-04
计算机技术与发展(2018年5期)2018-05-28
计算机技术与发展(2017年12期)2017-12-20
北京航空航天大学学报(2017年9期)2017-12-18
无线互联科技(2017年6期)2017-04-26
电源技术(2016年9期)2016-02-27
电源技术(2015年1期)2015-08-22
电力建设(2015年2期)2015-07-12
深圳大学学报(理工版)(2015年5期)2015-02-28
