
基于组合模型的城市住房租金预测研究
2021-11-02 02:19谭静
中国房地产·综合版 2021年9期
关键词:机器学习


摘要:针对我国住房租赁市场存在的信息不对称、租金不够透明问题,提出基于互联网数据和机器学习的住房租金预测方法。以深圳市居住小区租金为例,系统比较了支持向量回归、前馈神经网络、XGBoost、随机森林、K近邻5种机器学习回归算法的预测绩效,并采用集成学习理论对模型有效性进行了增强,同时从机器学习的角度对住房租金影响因素进行了分析。结果显示:随机森林和XGBoost在住房租金预测问题上的预测性能优于其他机器学习模型,而基于集成学习理论构建的组合预测模型则优于个体机器学习模型。进一步地,基于树集成方法的特征重要性分析发现,交通、教育以及区位条件是影响住房租金的关键影响要素。
关键词:互联网数据;住房租金预测;机器学习;集成学习;组合模型
中图分类号:F293 文献标识码:A
文章编号:1001-9138-(2021)09-0053-61 收稿日期:2021-08-05
作者简介:谭静,中国科学院深圳先进技术研究院&深圳市房地产评估发展中心,博士后。
基金项目:中国博士后科学基金第68批面上资助项目“新时代背景下区位导向性政策‘内卷化困境及突破路径研究”(2020M682958)。
在人口城市化进程不断加快、大城市“房价高企”以及“租购并举”的背景下,住房租赁市场发挥作为住房买卖市场重要补充的角色越来越迫切。其中,住房租金是影响住房租赁市场能否健康平稳发展的关键因素。当前,住房租赁市场普遍存在信息不对称、租金不透明问题。部分大中城市由于住房租金涨幅过快或波动较大,增加了居民租房压力,不利于住房消费稳定,同时透支城市居民未来消费能力,成为国内扩大需求的障碍之一。2020年中央经济工作会议提出要“解决好大城市住房突出问题”“对租赁价格水平进行合理调控”。构建一套科学合理、可操作性强的住房租金预测体系,掌握精细化尺度的住房租金水平及其空间分布,对规范和发展城市住房租赁市场具有重要意义。
互联网和大数据的发展为不动产交易或房屋出租等带来了越来越多便利,互联网房租数据可以为研究提供大规模的住房信息。房屋租金通常由住房租赁市场供需等宏观因素以及位置地段等房屋商品特征因素综合决定,但是对于租房这个相对传统的行业来说,信息严重不对称一直存在。因此,利用实时更新的互联网大数据,构建一种低成本、高效率、准确性高且可推广的住房租金预测模型,就显得十分重要。既有关于住房租赁市场的研究主要集中于住房租赁制度和租金影响因素,住房租金预测相关的研究较少。机器学习是人工智能领域的新兴研究方向,对建模数据的分布无严格限制,具有适用性强的优势。国内外不少研究将机器学习引入到房地产预测领域,但研究对象主要集中于房价,在住房租金预测领域研究中的应用仍然非常有限。
本文基于互联网数据和机器学习相关方法,构建组合预测模型实现对城市住房租金的精细化预测。为了验证所提出方法和模型的准确性,以深圳市居住小区租金为对象,采用在线房地产网站挂牌租赁数据对模型进行了实证检验。进一步地,基于机器学习模型的特征重要性,对影响住房租金的关键因素进行了分析和讨论。本研究为城市住房租金批量预测提供了可借鉴、操作性强的思路和方法,可为政府制定房屋政策提供重要的决策依据。
1 相关理论基础
1.1 特征价格理论
特征价格理论是研究异质性产品价格形成的一种经典理论,主要包含Lancaster 1966年提出的消费者理论和Rosen 1974年提出的市场供需均衡模型两方面内容。其核心思想是异质产品是由大量内在属性构成的,消费者对产品的需求是基于产品本身的各种属性或特征,而非产品本身,这些属性的组合影响了消费者的效用,进而影响消费者的支付意愿。基于该理论,房地产价格相关研究往往将住房价格或住房租赁价格的影响因素划分为建筑特征、邻里特征以及区位特征三大类。特征价格理论为确定住房租赁价格的影响因素提供了理论指导。
1.2 集成学习理论
集成学习是机器学习领域的一个庞大的分支,也是当前的研究热点之一。但严格意义上,集成学习(Ensemble Learning, EL)并非机器学习的一种算法,而是集成不同模型的一种策略或框架。根据學习理念的不同,集成学习可以大致分为装袋法(Bagging)、提升法(Boosting)和堆栈法(Stacking)。三种集成学习策略的共同点在于:通过对多个弱学习器(基础学习模型)进行集成实现知识融合以提升预测性能。区别在于,装袋法通常考虑的是同质弱学习器,且不同学习器之间的训练或学习是并行的,不存在互相依赖,模型最终结果按照某种确定性平均过程给出,代表性算法为随机森林;提升法面向的通常也是同质弱学习器,但不同学习器之间的学习是有序进行的,后一个弱学习器重点关注在前一个学习器中误差较大的样本,代表性算法为XGBoost;堆栈法则通常集成的是异质弱学习器,不同学习器之间并行学习,并通过一个元学习器(元学习模型)将弱学习器加以组合,根据不同弱学习器的预测结果输出集成模型的最终结果。受大数定律启发的集成学习被验证为一种可有效提升机器学习模型性能的有效途径,在解决不同领域的实际问题中显示出了明显优势,但其在住房租赁市场的应用还相当有限。
2 研究设计
本文选择K近邻、支持向量回归、前馈神经网络、随机森林和XGBoost 5种常见的机器学习回归算法来构建住房租金组合预测模型。在系统比较个体机器学习模型预测绩效的基础上,基于集成学习理论中的堆栈法构建集成学习模型,试图说明集成学习模型在住房租金预测问题上的优势。
2.1 数据来源及预处理
2.1.1 数据来源
本文选择用于实证分析的目标城市是我国四大一线城市之一——广东省深圳市,它是国内最发达、最活跃的住房租赁市场之一,也是全球住房租赁占比最高的城市之一。以深圳市的居住小区作为基本分析单元,以小区住房租金作为被解释变量(模型输出),以影响住房租金的影响因素作为解释变量(模型输入)训练租金预测模型。数据主要来源于两方面:
一是在线房地产网站租赁清单。住房租金数据以及小区层面的特征数据,从乐有家(leyoujia.com)、链家(lianjia.com)、房天下(fang.com)、Q房网(qfang.com)四家最受欢迎和规模最大的在线房地产市场网站获取。主要字段包括出租房屋“所在区域”“小区名称”“建成年代”“容积率”“总楼层”“租赁价格(总租金)”“出租建筑面积”“项目总户数”“朝向”等,时间跨度为2020年8-12月。
二是POI数据。本文基于POI数据构建空间变量集合以增强住房租金模型的预测性能。POI(Point of Information)是一种附带名称、地址以及类别属性的点位置数据,可以提供特定位置的关键社会经济信息。本文POI数据来源于高德地图开放平台(http://lbs.amap.com/),包括交通站点(地铁站、公交站)、商业场所(购物中心、大型连锁超市)、教育设施(大学、高中、初中、小学)、医疗设施和风景名胜区等。
2.1.2 变量选择
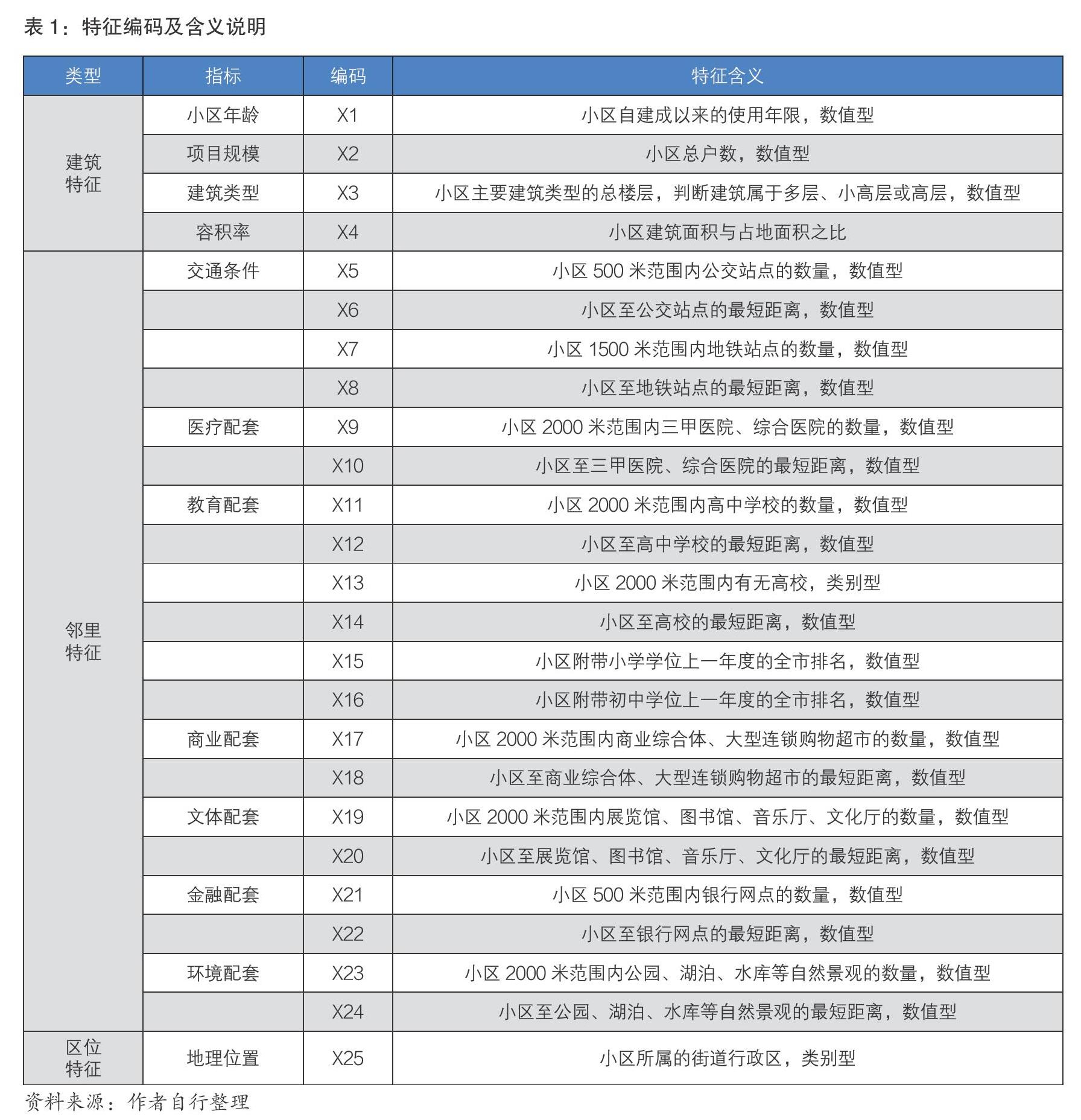
本文依据特征价格理论并借鉴住房租金影响因素相关研究成果,选择建筑特征、邻里特征和区位特征三大类因素作为构建住房租金预测模型的输入变量,具体指标见表1。关于指标体系的简要说明如下:
①建筑特征。是房屋自身的属性,本文选取“小区建筑年龄”“项目规模”“建筑类型”以及“容积率”来体现小区本身的特征或品质,代理指标基于在线房地产网站小区信息构造。
②邻里特征。居住小区周边的配套或服务情况。本文选取交通、医疗、教育、商业、文体、金融、环境七类配套设施的数量或距离来体现房屋周边配套设施或服务的可及性和便利性,代理指标主要基于POI数据构造。对于教育分类中的初中和小学,本文认为采取初中/小学学校的教育水平优质程度来反映其对住房租金的影响更为适合,代理指标选择学校在上一年度的全市排名来构造。
③区位特征。房屋所处地理位置的优劣程度。例如距离市中心的距离、距离海岸线的距离等。由于区位特征过于宽泛不好量化(例如许多城市具有多中心结构、海岸线通常很狭长等),本文采取间接的方式,通过在模型中纳入小区所在街道行政区这一变量来捕捉因区位特征差异导致的对住房租金的影响。由于建筑本身具有位置固定性,这一度量方式具有合理性。
2.1.3 數据预处理
原始数据存在大量杂质,需要对其进一步处理。数据预处理包括数据清洗、特征组合或编码及数据归一化。
①数据清洗。识别并去除重复记录,删除关键字段如“总租金”或“出租面积”缺失的样本;以“总租金”除以“出租面积”得到“月租单价”字段,剔除面积对租金的影响,根据“月租单价”排除虚假租赁记录或信息明显登记错误的情况。最后将“月租单价”聚合到小区层面作为该居住小区的平均租金,即被解释变量。最终一共获得2643条居住小区层面的数据。
②特征编码。主要针对类别型(分类)特征进行,采用独热编码(One–Hot)方式将类别型变量转换为哑变量,数值型变量直接采用其数值。
③数据归一化。归一化可以消除不同量纲的影响,同时提高模型预测精度。经归一化后的数据分布在0到1之间。数据归一化的计算公式如式(1):
2.1.4 特征约简
在机器学习问题上,当变量维度过高时,并不是所有的变量与预测结果都是相关的,一些不相关变量可能会形成噪音,对模型预测精度产生负面影响。因此,需要通过特征选择筛选对住房租金真正有影响的特征以提高模型精度,规避过拟合的现象。本文采用套索法(Lasso)进行特征选择。套索法与传统普通最小二乘(OLS)方法相当接近,不同于OLS通过最小化残差平方和求解系数值,套索法求解的目标方程(式2)在残差平方和的基础上加上了系数的绝对值之和(L1范数),后者迫使重要性较低的变量系数取值为0。因此,套索法天然地是进行特征选择的一种方法。按照Lasso回归的结果,系数为0的变量则被剔出建模过程中输入模型的影响因素集合。
其中 是系数向量的一阶范数,是常数,控制对冗余变量的惩罚度力度。
2.2 模型构建流程
本文住房租金预测模型的理论架构是首先应用套索法作为前置模型对输入预测模型的特征集合进行预处理,在保证信息完整的情况下删除冗余属性;然后以约简后的、解释能力强的关键特征作为机器学习模型的输入,对模型进行训练和预测;最后基于堆栈法集成学习策略对个体机器学习模型进行融合,得到组合模型。在数据预处理后,具体建模步骤如下:
(1)输入输出变量确定。以居住小区租金作为模型输出,以套索法约简后的特征集合作为模型输入。
(2)数据集拆分。按一定比例将数据集拆分为训练集和测试集,同时训练集再次拆分为学习集和验证集。其中,训练集用于训练模型,测试集用于验证模型的预测性能。
(3)机器学习模型设计。超参数的选择对机器学习模型的结构乃至预测结果有着较大的影响,本文采用网格搜索结合K折交叉验证方法自动寻优确定超参数,完成每一个机器学习模型的建立。交叉验证将训练集分为k个子集(称为折),对训练的模型进行训练和评估k次。每次选择k-1折进行训练,剩余1折用来评估模型。K折交叉验证结果表示为包含k个评估分数的数组。
(4)组合模型构建。①对于步骤(3)确定的每一个具有最优超参数的机器学习模型(个体学习模型),基于训练集对模型进行训练并采用测试集对模型预测能力进行打分,按照预测性能高低进行降序排序;②从具有最优预测性能的模型开始,依次选择两个或多个个体学习模型,采用堆栈法集成学习策略构建组合模型,按照上述组合方法,5种个体学习模型最终形成4个组合模型,可记为stack #1~stack #4;③以个体学习模型的输出作为组合模型的输入,居住小区租金作为组合模型输出,训练并评价不同组合模型的预测性能,得到最优组合模型。
2.3 模型评价指标
本文采用均方根误差(Root Mean Squared Error,RMSE)、平均绝对百分比误差 (Mean Absolute Percentage Error,MAPE)、可决系数R2来比较不同模型的预测性优劣。RMSE和MAPE的计算过程如公式(3)至(5):
其中,N是测试数据集的样本数量,yi,true是第i个样本租赁价格的真实值,yi,pred是模型对第i样本的租赁价格预测值。是样本平均值。
3 实证结果分析与讨论
实证过程采用Python语言下的skicit-learn库进行模型构建和实现。样本拆分环节训练集和测试集的比例设定为7:3。为保证公平评价,应用K折交叉验证检验预测模型的性能,模型得分以交叉验证的结果为准。考虑到计算时间,k设定为10。下文首先对5种机器学习模型的预测性能进行评价,接着讨论组合模型的预测性能相对单个机器学习模型是否有所提升,最后根据随机森林和XGBoost的特征重要性排序结果对住房租金的关键影响因素进行分析和讨论。
3.1 个体机器学习模型预测分析
表2汇集了5种经典机器学习算法的关键参数设置和预测性能评估指标,也汇集了特征价格模型的预测结果,作为性能对比的基准以便比较。结果显示,无论是哪一种评估指标进行评判,机器学习模型的预测性能均优于特征价格模型(RMSE=17.88,MAPE=16.97%,R2=0.59)。可能的原因在于,住房租金和各种影响因素之间存在非线性关系,而特征价格模型为线性模型,不如机器学习模型在处理多变量和非线性特征方面有优势,因此其预测性能略逊一筹。
从RMSE来看,各个机器学习模型的RMSE从小到大排序为XGBoost (5.63) XGBoost和RF本质上都是基于决策树的集成模型。决策树算法容易过拟合,泛化能力不强,样本发生轻微改动就可能导致树结构的剧烈改变。理论上,经过集成的XGBoost和RF可改善决策树的缺陷。就本实证得到的结果来看,以Boosting策略构建的XGBoost性能略优于以Bagging策略构建的RF。相比决策树,XGBoost在特征粒度上实现并行优化,并且采取正则化项防止过拟合,不仅降低了过拟合,而且提高了计算效率。 由于对数据维度不敏感,既有实践倾向于认为SVR相比其它机器学习算法更稳健和精确,本文的实证结论一定程度上与既有研究吻合,SVR取得相对较好的预测绩效,排序第三,其RMSE为8.78,MAPE为6.57%,R2为0.90。 至于神经网络,理论上具有三层网络结构的BPNN模型已经可以无限逼近任何非线性函数。然而在实际应用方面,由于网络结构的设计可能导致梯度下降算法陷入局部最优解,导致泛化能力低。本文实证中采取了一些策略(例如Early_Stopping)防止模型过拟合,取得一定效果,但BPNN的整体预测性能处于5种算法的中等水平(RMSE=9.38,MAPE=7.98%,R2=0.89)。 KNN作为一种懒惰学习算法,没有一般意义上的学习过程。研究表明,在数据质量好的情况下,KNN也能取得令人满意的结果。但当存在样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)时可能效果不佳。KNN在本文对5种机器学习模型的比较分析中表现最差(RMSE=17.15,MAPE=13.25%,R2=0.62)。 3.2 组合模型预测分析 5种个体机器学习模型存在多种构建组合模型的方式。根据各个模型的RMSE对其进行升序排列(则预测性能降序):XGBoost 对于每一种个体学习模型组合,我们循环SVR、BPNN、XGBoost、RF和KNN作为元模型构建组合模型,结果发现BPNN作为元模型能得到最高预测精度。本文以效果最好的BPNN作为stack #1到 #4的元模型。4种组合模型的预测评价指标值汇集于表3。通过结合XGBoost和RF (stack #1),预测误差(拟合优度)減少(提高)到小于(大于)两个个体学习模型中的任何一个(RMSE =5.49,MAPE =5.43%,R2 =0.89)。当进一步增加模型,即SVR,stack #2 的RMSE和MAPE进一步减小,R2进一步提高;同样地,BPNN的加入改善了stack #3模型的预测性能,此时组合模型的RMSE达到了4.57,MAPE 4.19%,R2提高到0.93。然而,第4个模型KNN加入却不能促使组合模型的性能进一步改善,stack #4的RMSE (7.72)和MAPE (7.13%)均高于stack #3,R2 (0.88)则低于stack #3,意味着stack #4相比stack #3性能更弱了。总体而言,XGBoost、RF、SVR和BPNN集成的模型stack #3预测性能最优,高于任一个体机器学习模型。尽管 stack #4的预测性能相对其他组合较差,其预测性能依旧高于大部分个体学习模型,包括BPNN和KNN,说明组合模型比个体机器学习模型有效。
3.3 特征重要性分析
通过特征重要度可以识别影响住房租金的关键特征。基于决策树的机器学习算法,包括XGBoost和随机森林,具有自然的变量选择结构。本文模型实现基于Python的skicit-learn库,该库已内置了树模型的特征重要性排序函数。在模型训练完成后,基于对应函数提取了各个特征对于预测模型的重要度,依据随机森林模型和XGBoost模型得到的重要性排名(从大到小)及对应权重如表4所示。
结合表4中的随机森林模型和XGBoost模型的特征重要性排序结果,可以识别影响深圳市居住小区租金的关键影响因素为交通、教育、医疗、小区品质以及区位等,以下根据重要性依次进行分析。
交通配套方面,X7 (小区附近地铁站点的数量)在两个模型中重要性均排前列。地铁站点数量/密度衡量了小区居民对地铁的总体可用性和机会,丰富的地铁配套提高了出行便利度,大大缩短了通勤时间。教育配套方面,X12 (小区至高中学校的最短距离)和X16 (小区附带初中学位全市排名)均排在前列,说明小区周边的教育资源对住房租金有显著影响,这与现实情况相符合。其他配套方面,X10 (小区距离最近三甲/综合医院的距离)和X17 (小区附近商业配套数量)也体现了一定重要性,医疗和商业与居民生活密切相关。对居民而言,住宅周边是否存在医院,喜忧参半。医院的存在可能导致小区周边人口流动性大,产生交通拥堵且可能存在病菌感染威胁,而距离医院过远则在必要时难以享受到便利的医疗服务。因此,居住小区租金与其到医院的距离之间可能体现为非线性关系,例如住房租金随距离的增加先上升后下降。
另一个值得注意的特征是度量地理位置优劣度的小区所在街道行政区,可以看到Street27、Street33、Street45、Street31和Street32出现在了排名前十五的位次,其中Street27、Street33排到了前五。小区所在街道行政区本质上属于区位因素,好的區位往往意味着各种优势资源,其中有些是难以通过具体指标一一量化或列举的,这些潜在的优势资源显然会影响租金。建筑特征中,X1 (小区建筑年龄)以及X3 (建筑类型)对租金也有一定影响。小区越老旧,装修情况以及相应的配套设施往往越差,同样地段的情况下,租房者对老旧小区的租赁支付意愿更低。建筑类型对租金的影响逻辑体现在高层建筑通常配置电梯,年代较新,居住状况较好,自然影响租金。
4 结语和启示
针对我国大城市住房租赁市场的租金预测问题,本研究收集了2020年8月至12月深圳市在线房地产网站租赁数据和POI等相关数据,结合特征价格理论、机器学习方法以及集成学习理论,系统对比了不同机器学习回归算法在住房租赁市场租金预测这一问题中的实证绩效,并基于机器学习中的集成学习理论构建组合模型尝试增强预测模型的有效性。同时,基于随机森林和XGBoost模型,从机器学习的视角识别了各个影响因素在住房租金预测问题中的重要性。本研究证实了通过互联网数据和机器学习相关方法实现高效率、低成本的城市住房租金预测的可行性,为住房租赁管理部门制定政策提供了技术参考。
参考文献:
1.顾建发 王烽.探索房地产市场基础性制度和长效机制——以发展住房租赁市场为重点.上海房地.2017.06
2.黄燕芬 王淳熙 张超 陈翔云.建立我国住房租赁市场发展的长效机制——以“租购同权”促“租售并举”.价格理论与实践.2017.10
3.崔娜娜 崔丹 肖亮.城市住房租金价格影响因素的空间计量分析——基于GWR模型对北京市数据的分析.价格理论与实践.2020.05
4.Jerez J M , Molina I , P J García-Laencina, et al. Missing data imputation using statistical and machine learning approaches in a real breast cancer problem.Artificial Intelligence in Medicine.2010
5.王阿忠 李倩.基于粗糙集神经网络的房产税基批量评估研究.福州大学学报(哲学社会科学版).2019.33 (05)
6.陈诗沁 王洪伟.基于机器学习的房地产批量评估模型.统计与决策.2020.36 (09)
7.Lancaster, Kelvin J.A New Approach to
Consumer Theory.Journal of Political Economy.
1966.74 (2)
8.Rosen S.Hedonic Prices and Implicit Markets: Product Differentiation in Pure Competition.Journal of Political Economy.1974.82 (1)
9.Montero J M, Mínguez R, Fernández-Avilés G. Housing price prediction: parametric versus semi-parametric spatial hedonic models.Journal of Geographical Systems.2018.20 (1)
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
