
Traffic Engineering Based on Deep Reinforcement Learning in Hybrid IP/SR Network
2021-11-02 07:12BoChenPenghaoSunPengZhangJulongLanYoujunBuJuanShen
China Communications 2021年10期
Bo Chen,Penghao Sun,Peng Zhang,Julong Lan,Youjun Bu,Juan Shen
1 Information Technology Institute,Information Engineering University,Zhengzhou 450002,China
2 War Research Insititute,Academy of Military Science,Beijing 100091,China
Abstract:Segment Routing(SR)is a new routing paradigm based on source routing and provide traffic engineering(TE)capabilities in IP network.By extending interior gateway protocol(IGP),SR can be easily applied to IP network.However,upgrading current IP network to a full SR one can be costly and difficult.Hybrid IP/SR network will last for some time.Aiming at the low flexibility problem of static TE policies in the current SR networks,this paper proposes a Deep Reinforcement Learning(DRL)based TE scheme.The proposed scheme employs multi-path transmission and use DRL to dynamically adjust the traffic splitting ratio among different paths based on the network traffic distribution.As a result,the network congestion can be mitigated and the performance of the network is improved.Simulation results show that our proposed scheme can improve the throughput of the network by up to 9%than existing schemes.
Keywords:SDN;deep reinforcement learning;segment routing;traffic engineering;equal cost multiple paths
I.INTRODUCTION
With the development of network technologies such as 5G,Internet of Things,and cloud computing,network service providers such as operators and data centers are facing increasing service differentiation requirements,for example,high bandwidth,low latency,and low packet loss rate.The network operators improve network resource utilization by traffic engineering to solve the problem of dynamic traffic scheduling[1].However,traditional traffic engineering solutions such as MPLS and RSVP-TE[2—4]need to maintain a large amount of state information,which affects the processing capacity of routing equipment and consumes network bandwidth.
In recent years,Segment Routing[5]has been proposed as a new network technology for traffic engineering.The segmented routing is based on source routing.The source node selects the path and guides the data packet along the path through the network.The flow states are only maintained at the source node of each flow.The intermediate node does not need to store and maintain any flow state information.It can support super-largescale network traffic engineering.At the same time,it has native compatibility with SDN technology,making it easy to implement applicationdriven networks.Traffic engineering based on segment routing converts the user’s intentions(such as delay,disjoint paths,bandwidth,etc.)into a segment list,and then programs the segment list to the edge devices of the single-domain/cross-domain network to direct traffic along with the path corresponding to the segment list,so as to realize Intent-Based Networking(IBN)[6]and complete the evolution of traditional networks to next-generation network platforms.
Traffic engineering in SR is to find the segment list to carry all the flows in the network such that to achieve some objectives,for example minimize the maximum link utilization.To fully exploit the benefits provided by SR,it is necessary to compute the segment list efficiently.Such computation has to be carefully performed to achieve effective TE solutions in the whole network.
However,because of organizational,economical and technical challenges,it is impossible to migrate from a traditional IP network to a full SR one for Internet Service Provider(ISP)network.Therefore,a hybrid IP/SR network composed of SR nodes and traditional IP nodes has become the preferred scenario for network upgrades.In hybrid IP/SR network scenario,two problems need to be solved.One is that when the number of upgraded SR nodes is limited,which nodes can be selected to upgrade to obtain better network performance.The other is how to plan flow paths for traffic in the network and allocate reasonable bandwidth resources.
Segment Routing-based Traffic Engineering(SRTE)can transmit packets according to the path specified by the network administrator,which meets the differentiated needs of users.Network traffic is forwarded according to the shortest path between SR nodes.When there are multiple shortest paths with the equal-cost(Equal Cost Multiple Paths,ECMP),the traffic is evenly distributed on multiple paths.However,when a static multi-path transmission scheme is adopted,the traffic distribution in the network depends on the actual traffic matrix and network topology.This type of scheme performs poorly in heterogeneous network topology and cannot obtain better network traffic distribution[7].
In the meantime,recent advances in deep reinforcement learning have demonstrated beyond human-level performance in handling large-scale control tasks[8,9].It has been used in the field of network applications and achieved good results in scenarios such as traffic scheduling.For example,Xu et al.[10]proposed DRL-TE,which applies DRL to intra-domain traffic engineering problems by dividing the traffic engineering problem into static multi-path solving and online dynamic adjustment path diversion.Compared with traditional routing and traffic engineering algorithms,it has obvious advantages in delay and throughput.Valadarsky et al.[11]employed deep reinforcement learning to predict future network traffic based on historical traffic data,and calculated an appropriate routing configuration.The simulation results showed that for traffic matrix with obvious regular characteristics,the reinforcement learning model can achieve close to the optimal routing configuration through traffic prediction,which is superior to traffic-independent optimal routing.
Based on the above background,in this paper we propose a TE algorithm DRL-MPTE(Deep Reinforcement Learning based Multi-Path Traffic Engineering)for hybrid IP/SR network,aiming at maximizing the network throughput.Given the network topology and the SR path,when there are multiple equal-cost paths between SR nodes in the network,DRL is used to determine the traffic split ratio of each path to maximize network utility and ensure the fairness of multi-path transmission between SR nodes.The main contributions of our paper are as follows:
1)We provide the first DRL solution in the field of multi-path traffic scheduling in SR networks.We design an intelligent SR traffic engineering network architecture by combining the global strategy deployment function of the SDN controller and the independent exploration ability of the DRL algorithm.
2)We propose the novel TE algorithm DRL-MPTE to schedule network traffic according to the real-time link status of the multipath in the SR network,which improves the throughput of multipath transmission.
3)We conduct extensive experiments and make evaluations of our proposed scheme on the OMNET++network simulator with three topologies.The results demonstrate that compared with the ECMP and shortest path first(SPF)methods,the DRL-MPTE algorithm can improve the network throughput by 9%.
The rest of the paper is organized as follows:Section II introduces the relevant background of the research content,including segment routing and deep reinforcement learning.Section III presents related work.Section IV describes the mathematical representation of the research problem.Section V is the core part of the paper,which proposes a novel algorithm DRL-MPTE for traffic scheduling.In section VI,we evaluate our proposed scheme on different network topologies with real traffic datasets.Finally,conclusions are summarized in Section VII.
II.BACKGROUND
2.1 Segment Routing
Segment Routing(SR)is a protocol designed to forward data packets on a network based on source routes,which aims to solve the complex problem of a large number of forwarding rules in the information forwarding process.Segment Routing divides a network path into several segments and assigns a segment ID(SID)to each segment and forwarding node.It is designed to insert an ordered segment list into the IP header of each data packet at the source node to guide the data packet to be transmitted according to the specified path.The intermediate nodes don’t need to store the forwarding rules,which reduces the table entry load of the network node.
Based on the forwarding plane,segment routing is divided into two types:Segment Routing MPLS(SRMPLS)that is based on the MPLS,and Segment Routing IPv6(SRv6)that is based on the IPv6.The algorithm we proposed can be applied to both SR-MPLS and SRv6.
Figure.1 illuminates an example of the packet forwarding process in segment routing network,where nodeaas source node,and nodefas destination node.The segment list is(b,e,f),which means that the node segmentsbandeare passed in the middle,and the arrow indicates the shortest path.The ingress nodeainserts segment list into IP header of the packets of flow fromatofand forwards the packet to nodeb.After nodebreceived the packet,it pops up labelband steers packet to nodecaccording to the shortest path frombtoe.Nodecforwards the packet toddirectly without processing it.Similarly,dsends the packet toe.Nodeepops up labeleand shortest path forwarding proceeds from there on to the destinationf.
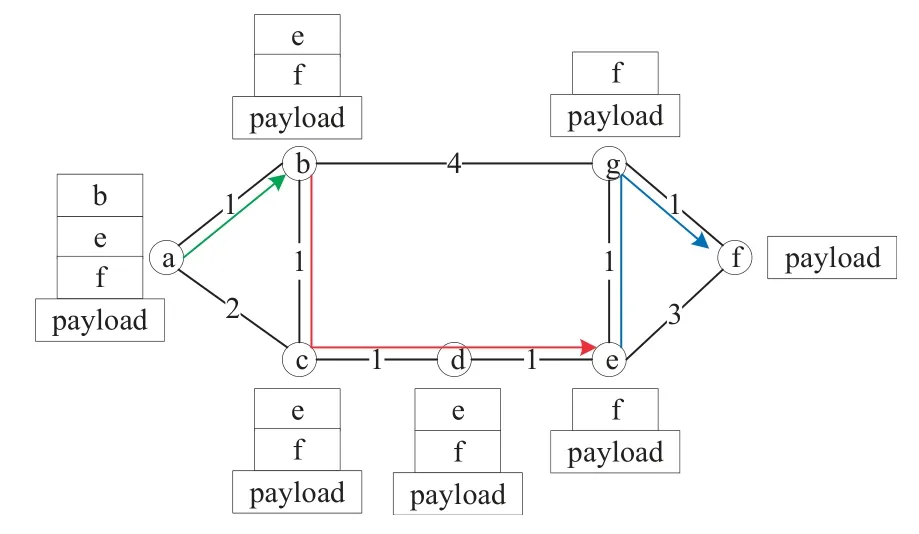
Figure 1.An example to illustrate segment routing.The number on each link is its IGP link cost.
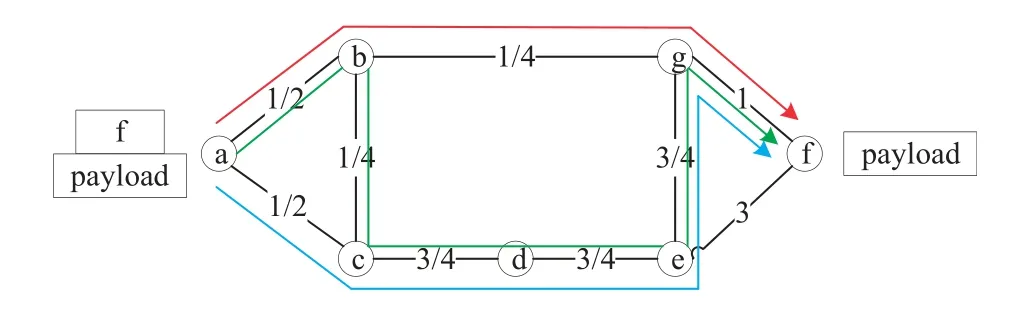
Figure 2.Traffic splitting among three ECMPs between nodes a and f.
Segment routing allows for ECMP.If the segment list is(f)from nodea,there are three equal-cost paths with a cost of 6:(a,b,g,f),(a,b,c,d,e,g,f),and(a,c,d,e,g,f).Figure.2 shows the three paths by red,blue,and green arrows.By default,traffic is split equally among ECMP when traversing an SR network.For example,if a unit flow fromatof,then the flow is divided equally at each branch node,as shown in Figure.2(the number next to each link indicates the traffic load).It can be seen from the example that the traffic is not optimally distributed on the three paths,and theb-glink is not effectively used.
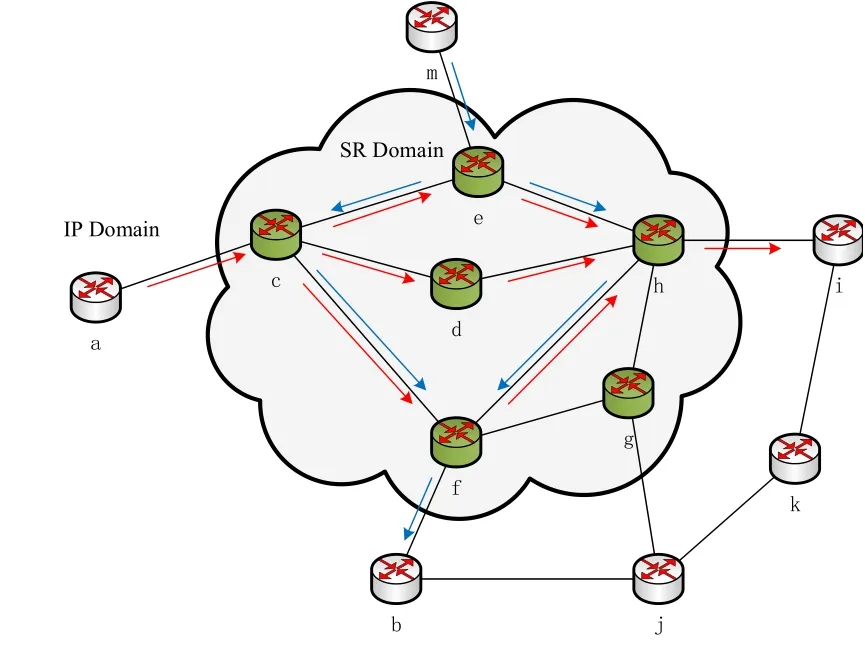
Figure 3.Example of an SR domain.
2.2 Deep Reinforcement Learning
Reinforcement learning algorithms are designed to learn long-term strategies to make decision-making actions to maximize the objective function in the optimization problem.Compared with supervised learning,reinforcement learning does not require a large number of labeled datasets.Instead,it learns the best decision-making action by exploring the state and action space and iteratively updating the strategy under the guidance of the reward function.In reinforcement learning,the state space is a set of statesS,and the action space is a set of actionsA.At each timet,the agent observes the environment statest ∈Sand takes actionsat ∈Ato obtain feedback rewardrt,simultaneously generate a new statest+1∈S.The goal of reinforcement learning is to find a strategy function,map the state to the action,and maximize the discounted cumulative reward,whereγ ∈(0,1)is
the reward discount factor.
In order to deal with the reinforcement learning problem of the explosion of storage space in the continuous high-dimensional state decision space,researchers have introduced the deep learning model that has developed rapidly in recent years into the reinforcement learning framework and designed a variety of deep reinforcement learning models.Mnih et al.[8]from DeepMind proposed DQN(Deep Q-Learning Network),using a Deep Neural Network(DNN)to replace the original Q-value table in Q-Learning to approximate the Q function.Corresponding to the DQN method based on Q function estimation is the policy gradient method.The policy gradient method uses a deep learning model as a strategy function to directly optimize the policy function by calculating the policy gradient.In order to further improve the performance of the policy gradient method and accelerate the convergence speed of the reinforcement learning model,the Q value learning can be combined with the policy gradient method,and the value estimation function can be used to predict the value of the subsequent actions in the current state and use the prediction results to train the model,which is the Actor-Critic(AC)framework[12].
III.RELATED WORK
Due to its appealing features in terms of routing flexibility,segment routing is widely used to address traffic engineering related problems[13].In this section,we briefly review the related studies of TE algorithms and the mechanisms used in fully and partially deployed SR networks.
In fully deployed SR networks,Sch¨uller T.et al.[14]analyzes the traffic engineering using SR for realworld topologies and ISP backbone network traffic.They compared 2-SR algorithm proposed in[15]with traditional OSPF-TE and theoretical optimal MCF.Evaluation results show that the SR yields close to optimal results.Li X.et al.[16]proposed for the first time the TE algorithm supporting adjacent SID,e2-LP and K-MILP,to search for the optimal k-segment path and minimize the maximum link utilization.They designed a simplified version(K-sMILP)to reduce the number of variables and constraints of K-MILP and extend K-sMILP to prevent the long segment path.Moreno E.et al.[7]proposed three ILP models and heuristics to assess the traffic engineering performance.They found that default SR behavior of exploiting ECMP may drive non-optimal solution.Moreover,it is possible to achieve very effective TE solutions by using limited segment list depth.
At present,TE based on partially deployed(i.e.,hybrid IP/SR)networks has just begun,there are few related studies.Tian Y et al.[17]proposed WA-SRTE in hybrid SR/IPv6 network,which converts the TE problem into a Deep Reinforcement Learning problem and optimizes the OSPF weight,SRv6 node deployment and traffic paths simultaneously to minimize the network’s maximum link utilization.Cianfrani A.et al.[18]defined Segment Routing Domain(SRD)as the subset of SR capable nodes and proposed two models:Single-SRD and Multiple-SRD to deploy SR into an ISP network while considering TE.The Segment Routing Domain Design problem is formulated as an ILP.The performance evaluation shows that the hybrid IP/SR network based on SRD offers TE opportunities comparable to the one of a full SR network.
IV.NETWORK MODEL
In this section,we firstly describe the hybrid IP/SR network scenario.Then we formulate maximizing network throughput as a mathematical problem.
4.1 Network Scenario
We consider a hybrid IP/SR network scenario.All nodes run the traditional network protocol stack and support IPv6 and OSPFv3 protocols.Only some of the nodes support SR.This scenario can be seen as a temporary state of an actual IP network:by updating the software of devices,the network operator provides a subset of legacy routers with SR functionalities,so as to improve the network flexibility.For simplicity,in this paper,we assume that SR capable nodes are connected subgraphs of the network topology and form anSR domain[18],which means the solution can be applied both in SR-MPLS and SRv6.And there is only a single SR domain.The flow enters the SR domain once.
To better understand that how an IP packet is forwarded in SR domain,let us consider the case shown in Figure.3,where nodesc,d,e,f,g,andhare SR capable nodes and form an SR domain.The rest nodes are in IP domain.In this case,there is a flow from nodesatoi.With ECMP enabled,the actual path is as the direction of the red arrow.A flow sent from nodeaand directed to nodeifollows the shortest path until it reaches the nodec,i.e.,the Ingress SR Edge.Nodecadds an SR header to the packets of the flow and specifies the segment list.Then the flow is split into three paths equally to nodeh,i.e.(c,e,h),(c,d,h),and(c,f,h).After the packet reachesh,it is forwarded by means of the IGP shortest path to node
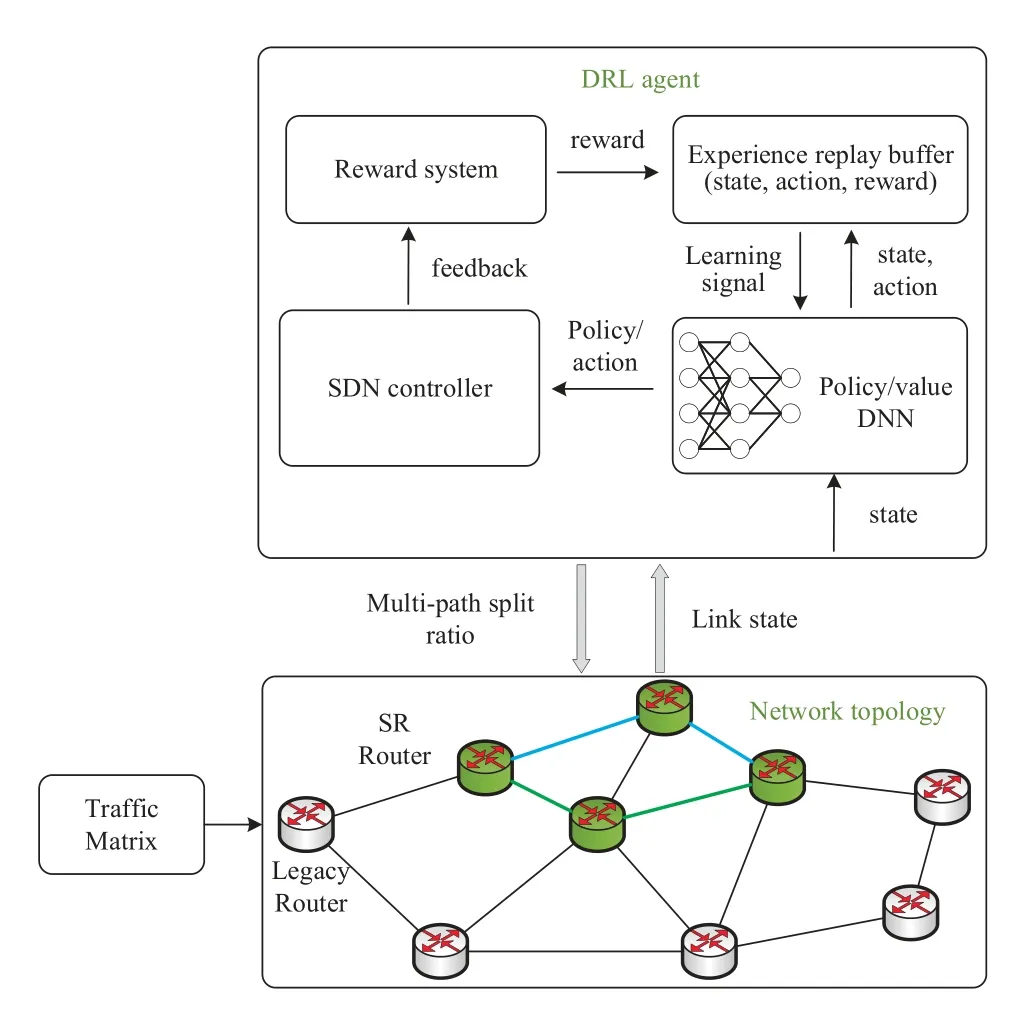
Figure 4.DRL-MPTE framework.
i.
4.2 Problem Formulation
Table 1 summarizes the parameters and variables used in this paper.The hybrid IP/SR network is modeled as a graphG=(V,E),whereVrepresents the set of nodes in the network,corresponding to the router or switch.Erepresents the set of interconnected links between nodes.Each linke ∈Ehas a capacityc(e).Here we consider that a Traffic Matrix T represents a long-term forecast of the traffic demand in the network.Kijrepresents the number of weighted shortest multi-paths between nodesiandjin the SR domain.The number of multi-paths for different node pairs may be different,and the number of multi-paths needs to be determined in advance based on network topology analysis.As shown in Figure 3,the number of multi-paths between nodeaandiisKai=3,and the number of multi-paths between nodemandbisKmb=2.

Table 1.Notation and Definition.
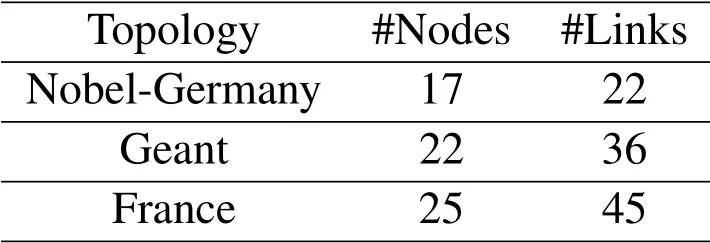
Table 2.Experiment topology.
The goal of this paper is to maximize network throughput by optimizing the multipath traffic split ratio of each flow in the SR domain to improve network performance.
Our TE problem can be formulated as follows.
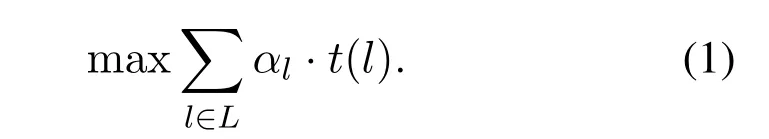
Subject to:

Eq.(1)is the objective function of the problem.Eq.(2)constraints that the flows carried on each link do not exceed its capacity.With Eq.(3),the flow conservation is ensured.Eq.(4)is the calculation of throughput factor of demand f.Eq.(5)ensures that the flow is routed completely.Eq.(6)is some numerical constraints.[19][20]showed that the TE problem is NP-hard and can’t be solved in polynomial time.So in this paper,we try to solve it with deep reinforcement learning.
In hybrid IP/SR network scenario,the choice of SR node has a great impact on network performance.To this end,in this paper we propose a mechanism to evaluate the importance of each node.This mechanism considers two parameters.One is the degree of the node.A node with a higher degree has more alternative paths when converted to an SR node.The other is the number of shortest paths through nodev,because the more the paths through the node,the more network flows you can control[21].The node importanceR(v)is defined as
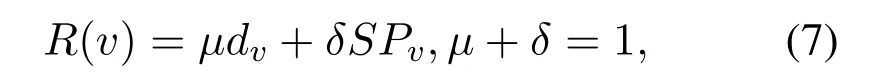
wheredvrepresents the degree of nodev,which is the number of edges connected to the node,SPvrepresents the number of shortest paths through nodev,andμandδare the weight coefficients ofdvandSPv,respectively.

Algorithm 1.DRL-MPTE.1:Initialize actor network π(·)and critic network Q(·)with random θπ,θQ 2:Initialize target actor network π′(·)and target critic network Q′(·)with random θπ′,θQ′,where θπ′ =θπ,θQ′ =θQ 3:Initialize replay buffer 4:for episode t=1 to T do 5:Get Initialized network state s0 6:for i=1 to N do 7:Choose action at based on ϵ-greedy strategy 8:Execute action at,get next state st+1 and reward rt 9:Store transition sample(st,at,rt,st+1)into replay buffer 10:Sample N transition samples from replay buffer(si,ai,ri,si+1)11:Calculate the target value of critic network:yi =ri+γQ′(si+1,π′(si+1|θπ′)|θQ′)12:update weights θQ of critic network Q(·)13:update weights θπ of actor network π(·)14:update weights θπ and θQ′ of target actor network π′(·)and target critic network Q′(·)θπ′ ←τθπ+(1-τ)θπ′θQ′ ←τθQ+(1-τ)θQ′15:end for 16:end for
V.DRL-MPTE SOLUTION
In this section,we introduce our DRL-based Multi-Path Traffic Engineering(DRL-MPTE)algorithm.We optimize the split ratio of the multipath in SR domain with DRL algorithm Deep Deterministic Policy Gradient(DDPG)and try to get the maximum throughput.
5.1 Framework
We first introduce the framework of DRL-MPTE,which is shown in Figure.4.The nodes consist of SR routers and legacy routers in the network,corresponding to SR domain and IP domain.Routing in a partially deployed SR network has two phases:i)IP-SR inter-domain routing,ii)SR intra-domain routing.IPSR inter-domain routing includes two subpaths:from source nodesto the ingress SR node and from egress SR node to the destination noded.For simplicity,we assume the routing from source nodesto destinationnodedis based on the shortest path first algorithm.To make the problem simplicity,we also assume that the IP-SR inter-domain routing path is a unique path.While in the SR domain,when there are several shortest paths available,traffic is split among multi-paths by applying the DRL-MPTE algorithm.
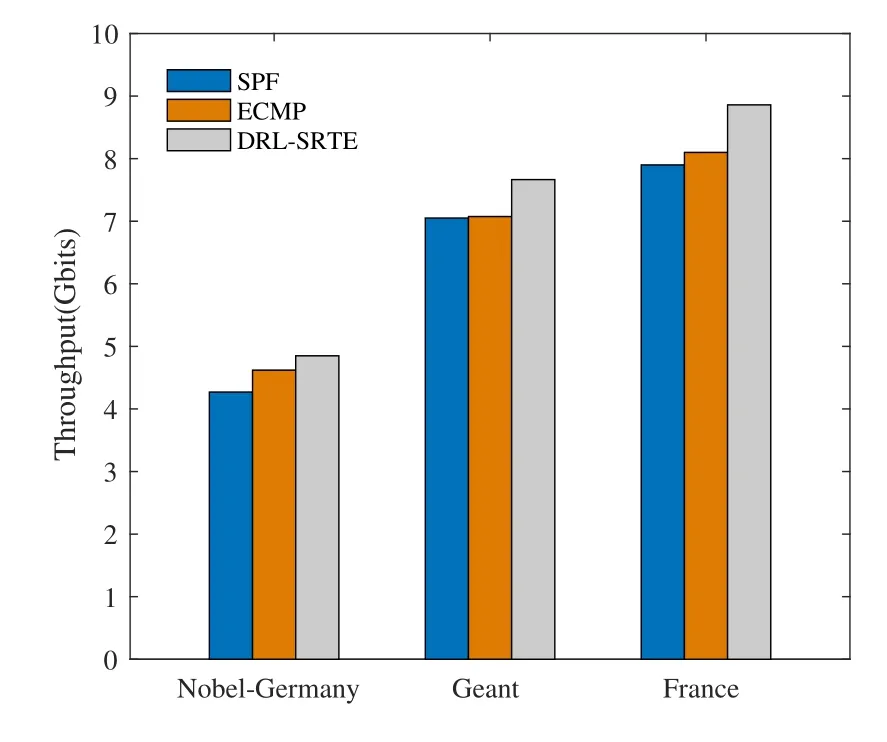
Figure 5.Comparison of throughput of three algorithms under different topologies.
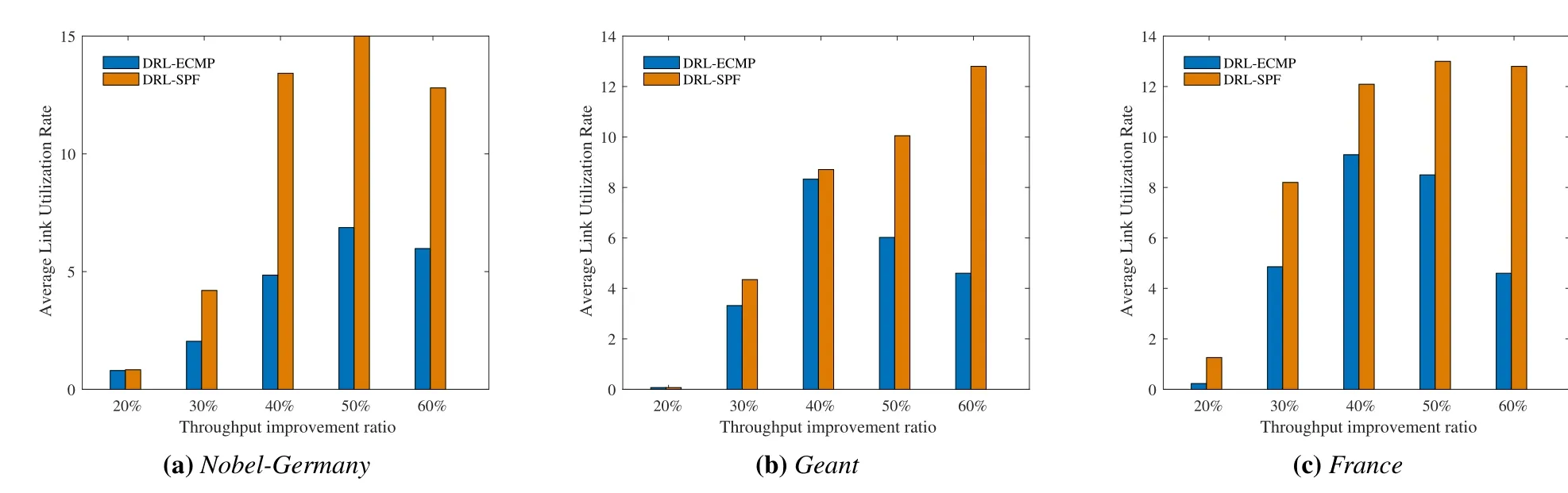
Figure 6.Ratio of throughput improvement for different topologies under different average link utilization.
The intelligent SRTE architecture employs SDN technology to collect network link states and control traffic distribution.The DRL agent runs on the SDN controller to intelligently schedule network traffic.
The SDN controller collects the link utilization rate from the network topology as the statest,which is used as the input of the policy/value DNN.The DNN module reads the network statestand outputs the traffic scheduling policy.Then SDN controller takes the corresponding action at according to the scheduling policy,namely traffic split ratio of multipath in SR domain.The reward system receives the feedback of the output action of the SDN controller and generates the corresponding rewardrt.st,at,andrtare stored together in the experience replay buffer to generate training data and update the DNN.
Lakhina et al.[22]did a research on network traffic analysis and pointed out that Origin-Destination(OD)flows in network traffic had periodic flows as the main component.For example,in Data-set Sprint-1,more than 90% of its traffic content has a periodic feature.Therefore,time-relevance is one of the most indispensable traffic features in a transmitting network.In our design,we use GRU(Gated Recurrent Unit)and fully connected network as the DNN to exploit such feature in traffic.GRU is a very popular version of RNN(Recurrent Neural Network),which is designed to process sequence data.The cell size of GRU is set to 96.The fully connected network has three hidden layers and the neurons are 160,90,90.We use SELU(Scaled Exponential Linear Unit)as the activation function.
5.2 Algorithm Design

As the traffic scheduling is a continuous control problem,we choose DDPG(Deep Deterministic Policy Gradients)[23],the most widely used algorithm in the continuous control field,as the DRL algorithm in this paper.Different from other reinforcement learning algorithms such as DQN,the output of DDPG is not discretized as a small set of fixed actions.This character makes DDPG suitable for the generation of continuous actions.In traffic engineering problems,we need to adjust the link weight of each link to manipulate all traffic flows in the network.The link weight value space should be large in a scaled network,which makes continuous control algorithms such as DDPG suitable for TE strategy design.
DDPG algorithm is an actor-critic algorithm that uses deep neural networks and deterministic policy gradients for continuous control.The core idea of DDPG is to maintain two functions at the same time:one is used as a parameterized actor functionπ(st|θπ)to generate actiona.The other is a parameterized critic functionQ(st,at|θQ),used to evaluate the action selected by the actor function.The Actor function is implemented through a deep neural network,which takes state as input and outputs the best action.The critic function is also implemented by a deep neural network,taking state-action pairs as input and outputting the correspondingQvalue.
Algorithm 1 shows the logical steps of DRL-MPTE.
VI.EVALUATION
In order to verify the effectiveness of the DRL-MPTE algorithm proposed in this paper in a hybrid IP/SR network,we have conducted experimental evaluations on the performance of various network topologies and carried out experiments with the ECMP algorithm and the shortest path algorithm(Shortest Path First,SPF)for comparative experiments.The experimental environment is constructed based on OMNET++network simulator.We implement DRL-MPTE with Keras and TensorFlow.Experiments are performed on a desktop computer with Intel Core i7 3.0GHz CPU and 32 GB of memory.The algorithm is trained for 100 episodes and each episode has 1000 steps.The size of the experience replay buffer is set to 3200.
For the network environment,in this paper,we carry out experiments on three actual telecommunication network topologies of different countries in SNDlib[24].Table 2 shows the detailed topology information.The bandwidth of the link in the topology is 1Gbps.The demand for each flow in the traffic matrix is randomly generated at(10,100)Mb/s,and the source node and destination node of the flow are also randomly generated.
Figure.5 shows the comparison of the network throughput of the three algorithms under different network topologies.It can be seen that the DRL-MPTE algorithm proposed in this paper is significantly better than the ECMP and SPF algorithms.Compared with the ECMP algorithm,it can increase the overall throughput by up to 9%.While the SPF algorithm can increase the throughput by up to 12%(France topology).Among the three network topologies,the France network topology has the largest performance improvement,indicating that with the increase of network topology and the increase of SR multipath in the network,the DRL-MPTE algorithm can bring higher throughput improvement.
Figure.6 shows the ratio of throughput performance improvement of the DRL-MPTE algorithm proposed in this paper at different average link utilization rates compared to ECMP and SPF algorithms in the three network topologies.It can be seen from the figure that when the average link utilization is low,the network link basically has no congestion.At this time,the performance improvement ratio of the DRL-MPTE algorithm is small.When the throughput gradually increases,the performance improvement of DRLMPTE algorithm over ECMP and SPF gradually increases.But when the network throughput reaches a certain threshold,the performance improvement ratio of DRL-MPTE algorithm compared to ECMP gradually decreases.This is because when the network link utilization is low,there is no congestion in the network,and no need for traffic scheduling.However,when the traffic in the network is increasing,some links are congested.At this time,using the DRL algorithm for intelligent traffic scheduling can avoid some congested links.But when the network traffic further increases,more and more links are congested,and fewer and fewer flows can be scheduled using the DRL algorithm.
VII.CONCLUSION
In this paper,facing the problem of hybrid IP/SR network traffic scheduling,we propose a traffic engineering algorithm based on deep reinforcement learning,DRL-MPTE.This algorithm analyzes the link bandwidth utilization in the network and outputs the traffic split ratio on the multipath in the SR domain.It overcomes the problems of unbalanced link utilization caused by the average traffic distribution of traditional ECMP,and control the network traffic distribution according to the network traffic model to achieve better network performance.Experiments and evaluation based on three well-known network topologies demonstrate that when there are multiple paths in the SR domain,the DRL-MPTE algorithm is smarter than the ECMP,and effectively increase network throughput,thereby increasing the overall network performance.
In the future,we will further study intelligent TE algorithms for hybrid IP/SR network and fully SR network with changing traffic or failure recovery.
ACKNOWLEDGEMENT
We gratefully acknowledge anonymous reviewers who read drafts and made many helpful suggestions.This work is supported by the National Key R&D Project(No.2020YFB1804803),the Research and Development Program in Key Areas of Guangdong Province(No.2018B010113001).

- China Communications的其它文章
- Catalyzing Random Access at Physical Layer for Internet of Things:An Intelligence Enabled User Signature Code Acquisition Approach
- Time-Domain Dual Component Computation Diversity Based on Generalized Hybrid Carrier
- On the Performance of Active Analog Self-Interference Cancellation Techniques for Beyond 5G Systems
- Multi Object Tracking Using Gradient-Based Learning Model in Video-Surveillance
- A Task-Resource Joint Management Model with Intelligent Control for Mission-Aware Dispersed Computing
- Research on Online Education Consumer Choice Behavior Path Based on Informatization