
基于深度学习的甲骨文分类算法研究
2021-11-01 08:53涂淳宁王贵田吉李汇嘉李婷
现代计算机 2021年26期
涂淳宁,王贵,田吉,李汇嘉,李婷
(浙江大学城市学院计算机与计算科学学院,杭州 310015)
0 引言
甲骨文是现在已知的中国最古老文字,在中国文字不断演变的历史上有着极其重要的地位。但是经过长时间的研究,直到现在只有2000多个甲骨文字符被识别,仍有超过3000个字符未被识别。得益于深度学习在特征学习方面有着极强的能力,在图像分类、语言模型等人工智能应用上取得了很好的成果[1]。针对人工识别效率低下这一问题,本文结合基于深度学习的图像分类模型及语料分析模型,提出了甲骨文未识别字符词性及相关特征的预测模型。研究的成果可望推广到其他带有图像表征的类似古文字预测中。
本次的研究选择图像处理库PIL对收集到的甲骨文字符图像做滤波处理以增强图像可读性。甲骨文的文字特征有着一字多形、异字同形、有两个或多个字刻在一起的合写特点[2],因此选择TensorFlow上的迁移学习模型使用图像特征提取模块的InceptionV3架构将甲骨文字符按造字方式分类以及是否合写进行分类预测。此外,选择CBOW模型对语料分析,在得到特征词预测的基础上计算余弦距离得到与特征词相似度高的词。图像与语料两种预测方式相结合,为未来对各类型古文字未识别字符的预测奠定了良好的基础。
1 相关模型及方法
1.1 图像滤波
图像滤波即在保留图像特征的前提下为简化图像数据,提高图像可读性而对图像进行处理。图像信号在采集、传输和保存等阶段会受到不同因素的干扰而遭受不同类型的噪声污染,噪声污染会严重影响图像特征提取等系列后续处理过程[3]。好的图像滤波处理可以有效提高图像分析的准确性,是不可缺少的图像预处理操作。研究对图片采用了平滑滤波和锐化滤波两种不同的处理方式。用平滑滤波处理甲骨文字符图像使得图像中的字符部分更加平滑。之后尝试用锐化滤波处理图像,增强图片中字符的细节,使字符的边缘更加明显。
1.2 GoogLeNet Inception网络结构
深度学习在图像识别分类任务上不断取得新的进展[4]。图像识别作为深度学习应用的任务之一,特点是在识别分类时应用了由卷积层、池化层、全连接层连接组成的卷积神经网络[5]。Inception系列网络结构与传统神经网络结构相比以全局平均池化层代替全连接层以降低参数量,通过设计在保持计算量不变的情况下增加网络宽度和深度。相比VGG等神经网络逐层卷积,Inception网络连接大小不同的卷积核以实现不同大小的特征融合,在利用密集矩阵的高计算性能同时保持网络结构稀疏性,网络结构如图1所示。
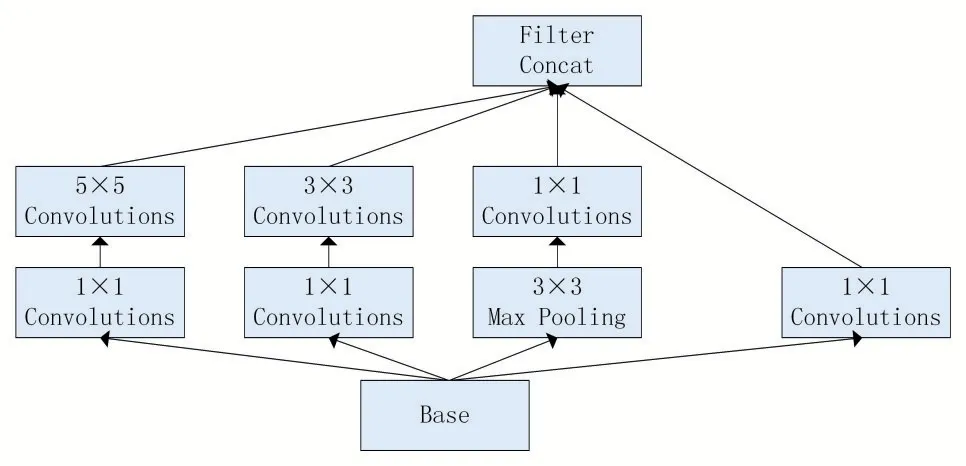
图1 Inception V1网络结构
Inception V2网络结构对Inception V1网络结果做出改进,用两个3×3的小卷积代替5×5的大卷积运算。利用多个小卷积代替大卷积的优势是保持表达能力的同时减少参数,提升了计算速度[6]。Inception V2网络结构如图2所示。
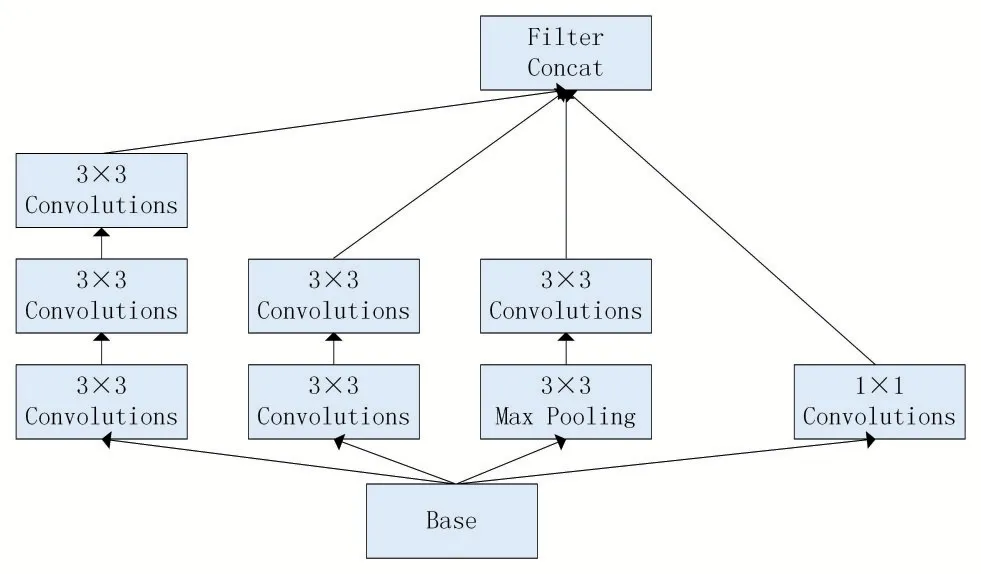
图2 Inception V2网络结构
第三代模型Inception V3与该系列之前的模型相比将一个二维的n*n卷积层分解成了n*1和1*n两个卷积,这不仅减轻了过拟合还降低了参数的数量。另外,Inception V3网络还提出了批标准化这一方法以达到加快训练速度的目的。
1.3 词向量模型
因为计算机只能处理识别结构化数据而文本属于非结构数据,所以研究首先需要将文本转变为可以识别处理的结构化数据。这一过程即是将自然语言映射为向量[7]。当前常见的文本表示技术是谷歌于2013年提出的一种生成词向量的神经网络模型——Word2Vec。Word2Vec模型生成的词向量映射包含语料的语义,在各项自然语言处理任务中都起着重要作用[8]。Word2Vec模型在自然语言处理应用中包括连续词袋模型CBOW和跳字模型Skip-gram两种不同的结构[9]。模型先将单词设置为一个N维的随机向量,最后经过模型不断地训练获取每个单词的最优向量[10]。相比通过简单的数字来表示各个词,词向量映射重点考虑了词和词之间的关联关系[11]。
CBOW模型是由特征词上下文文本的N个词来预测特征词的概率(N一般为2)。模型结构如图3所示:
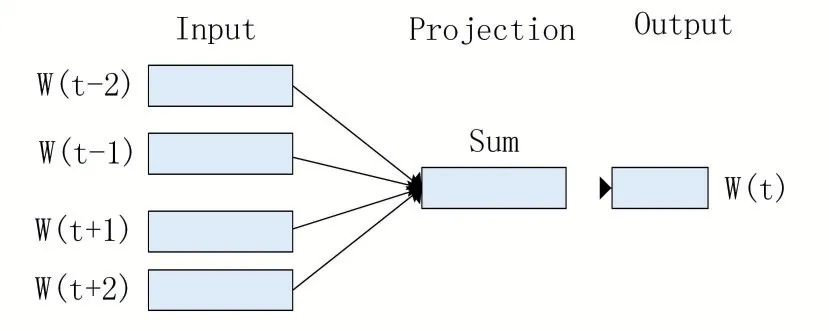
图3 CBOW模型结构
模型结构共分为3层。第一层为输入层,输入某个特征词的上下文词映射向量。第二层为映射层,该层将上下文文本的映射向量相加求和,通过上下文输入的词来计算各个特征词与上下文之间相符合的概率。第三层为输出层,输出映射层计算后得到的概率最大的特征词。
模型训练时采用负采样技术,在训练中引入了负例使每次训练只更新一部分的词向量权重,相比对所有权重进行更新大幅降低了计算量,大幅提升了模型计算性能。如图4所示为采用负采样后的CBOW模型:
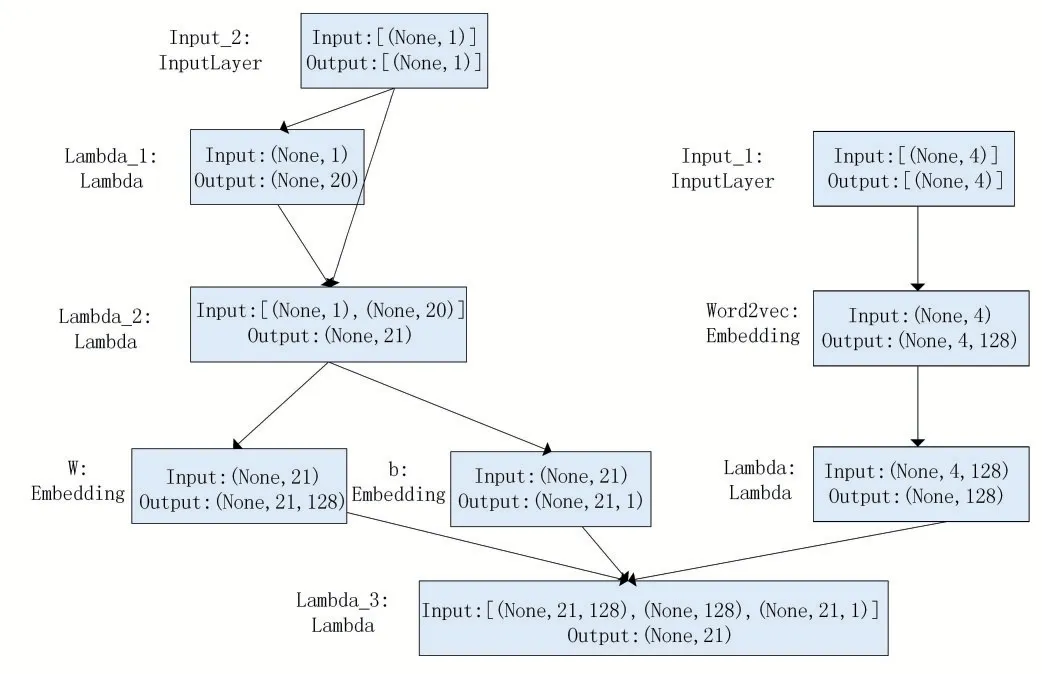
图4 采用负采样的CBOW模型
设置每个词的词向量维度为128,根据特征词(将预测的词)上下文2个文本来预测特征词。随后进行抽样,随机构造20个与预测词不一样的词作为负样本与预测词拼接作为输入层输入,嵌入下一层得到权重和偏置。Softmax函数对每一个输出分类都赋予一个概率值,结果表示识别为特定类的概率,模型输出的Softmax值表示模型随机抽取对预测词及其20个负采样样本的预测概率,之后利用梯度下降算法Adam作为优化器计算模型的损失函数。Softmax公式如公式(1)所示:
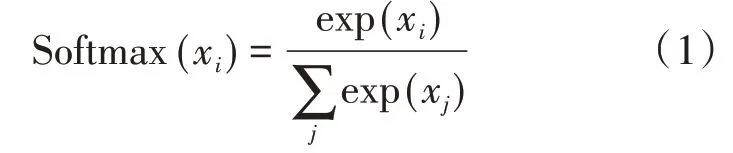
2 实验及结果分析
2.1 实验数据采集及预处理
基于甲骨文有一字多形和异字同形的特点,实验按照造字方式和字符是否合写进行分类,收集了字形不同的甲骨文字符图片共2313张。之后收集了甲骨文语料共1653个句子。对于语料中未识别但已分析出大概的语义的词用人名、地名、祭祀名等词代替。Word2Vec模型训练英文语料时可以根据词间的空格对词进行划分,但这一方法并不适用于中文语料。所以使用Word2Vec模型训练中文语料时需要进行对语料分词[12]。由于本次实验基于字形图像和语义两个方面进行研究,所以在分词时按照单个字符作为一个词进行划分。分词完成后建立单词到向量以及向量的映射字典。实验的整体框架如图5所示:
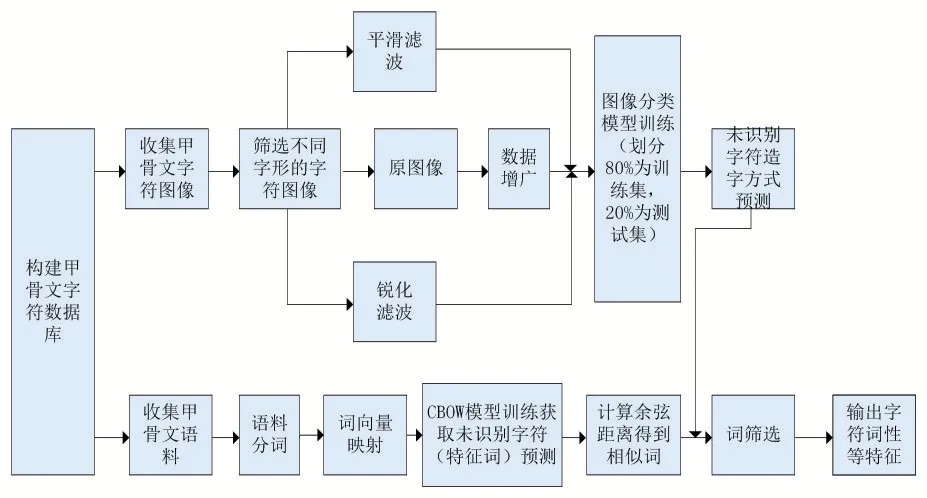
图5 图像分类模型框架
为提高实验模型的性能,对数据进行以下预处理:①在分词时选择按照单个字符作为一个词进行划分。②对甲骨文字符图像滤波处理以期提高图像的可读性,最大限度地简化数据。③由于数据量过少会导致过拟合,所以训练时的数据量对深度学习网络训练结果的优劣起着至关重要的作用[13]。针对数据量较难达到训练深度学习模型量级的情况,对甲骨文图像进行边缘随机修剪来扩充数据集。④训练时划分80%的图片做训练集,20%的图片做测试集。在训练出最优模型后利用测试集衡量模型的性能。
2.2 模型训练
基于InceptionV3架构实现对甲骨文字符图像分类训练。为字符图像训练分类器,分析每一个图像并求每一个图像的瓶颈值;计算完成后训练8000个步骤,每次步骤随机抽取一百个训练图像,从缓存中找到图像瓶颈后输入到最终层获取图像预测。随后比较预测标签与实际标签,通过反向传播更新模型权重。随着深度学习模型的继续,训练的准确度逐渐提高。所有训练步骤完成后得到一个基于所有训练图像的预测精度。
训练CBOW模型找出特征词。载入模型,提取各个单词的词向量,将词向量归一化后相乘得到各个单词之间的余弦距离,找出与特征词最相近的10个词。
2.3 结果分析
由表1的分类准确度可发现图片经过不同的处理方式后的分类准确度也并不相同。经过平滑处理后得到的字符保持了更好完整性,分类结果总体上也比原图像和经过锐化处理后的图像更好。
表1 图像处理后的分类准确度
图像训练完成后,可以对未识别出的甲骨文图像进行造字分类识别,通过载入训练模型以及分类的类别名称,对图像进行分类。实验随机从网络找了一些甲骨文字符图像来验证模型,部分结果如图6所示,每张图都有造字判断概率以及是否合写判断概率,可看出模型有着较高的识别率。

图6 部分结果展示
由于语料较少,所以预测后只能得到一个预测词是不够的,利用CBOW模型找出与预测词词性最相近的10个词。如图7所示为甲骨文语料中各词向量间的余弦距离图。相似的数词及动物名等词之间的余弦距离接近,可以认为模型能够对词向量较好分类。
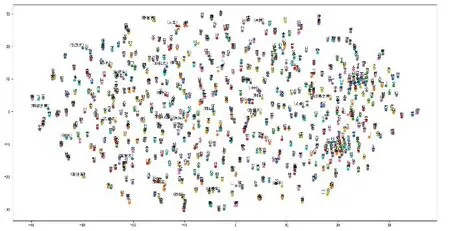
图7 词向量之间的余弦距离图
可以得出结论无论图像分类模型和词向量模型都对甲骨文有着准确的识别。最后将图像分类模型与词向量模型的预测相结合,在找出的十个单词中筛选符合预测词造字方式的词,再在数据库中分析这几个词出现最多的词性以及其他文字特征。
如表2所示为假设“二”作为特征词后提取的十个最相近的词。由表2可以看到其中包含了与“二”一样的“三”、“五”、“六”、“八”、“十”等数词。
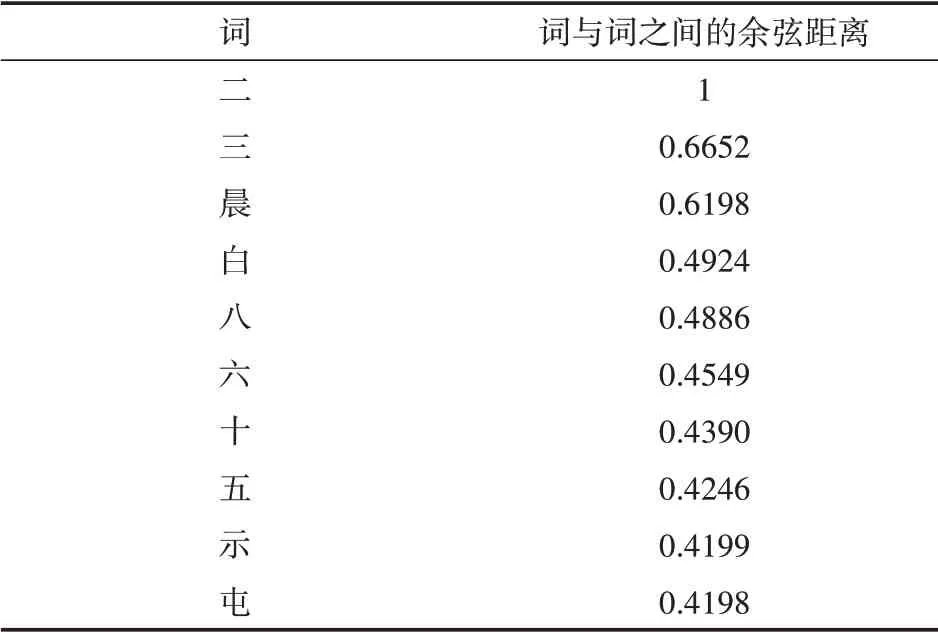
表2 词“二”的近似词
最后将图像分类模型与词向量预测模型相结合,在找出的十个词中筛选符合特征词造字方式的词,再在数据库中分析这几个词出现最多的词性以及其他文字属性。词性可分为主词性和其他词性(主词性即该词最常用最有可能的词性,其他词性即除了主词性外该次还有可能的词性)。表3和表4为筛选与“二”最接近词中造字方式也相同的词的词性。次数为数据库中单词为该词性的数量,也可看作为该词预测词性的可能性。

表3 预测词的主词性
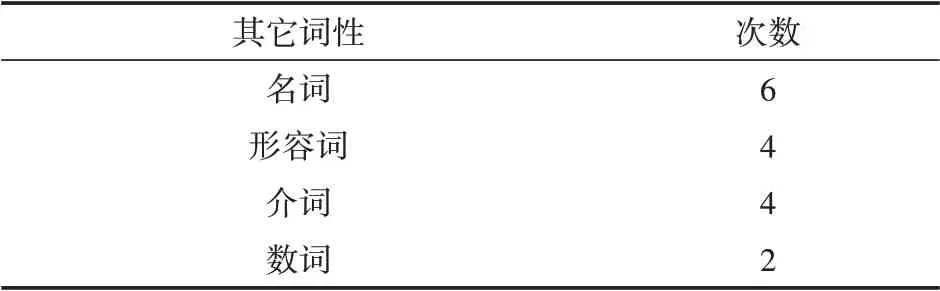
表4 预测词的其它词性
3 结语
本文提出了一种关于甲骨文的分类识别方法。针对甲骨文字符中仍有大量字符未被识别这一问题,通过图像识别及自然语言处理的综合运用,对未识别字符的词性及其它特征进行了预测。研究成果可以降低古文字研究的人工工作量,提升工作效率,在其它的中文古文字识别中也具有一定的参考价值。未来将继续对模型进行优化和改进,使之能够更好地应用于甲骨文字符的识别工作中。
猜你喜欢
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
长江丛刊(2019年25期)2019-11-15
科学导报(2019年62期)2019-11-05
电脑知识与技术(2019年23期)2019-11-03
电脑爱好者(2019年8期)2019-10-30
科学与财富(2016年30期)2017-03-31
儿童故事画报·智力大王(2016年6期)2016-09-14
儿童故事画报·智力大王(2016年4期)2016-07-20
农机使用与维修(2014年10期)2014-10-23
