
基于YOLOv5算法的道路场景目标检测应用研究
2021-11-01 08:53陈影
现代计算机 2021年26期
陈影
(合肥工业大学数学学院,合肥230009)
0 引言
简单来说,计算机视觉是处理数字可视化数据(或任何可视化数据)的算法、方法和技术。目标检测则是计算机视觉中的一个基本的视觉识别任务,旨在在给定图像中找到具有精确定位的特定目标类的对象[1]。近年来,基于深度学习的目标检测技术一直得到广泛的研究而不断发展。
常用的目标检测模型包括Faster R-CNN[2],SSD[3],YOLO[4-7]等。Faster R-CNN的网络结构可以分成两个部分。一个是用来生成候选区域(Region Proposal)的深层全卷积网络(RPN),另一部分则是Faster R-CNN检测器,其输入是由前一部分RPN网络所生成的候选区域。其中,RPN使用基础网络通过一系列卷积和池化操作来提取图像的特征,获得原始特征图,然后在原始特征图之后连接卷积层和ReLU层,来得到图像候选区域的特征图。特征图的每个点的输出包括k个锚点,是否有目标,以及k个候选区域的坐标值。
上述Faster R-CNN可以看作是经典的“twostage”目标检测器,对小目标检测效果极佳。而SSD方法不同于Faster R-CNN,是一种检测速度很快的“one-stage”方法[3]。与Faster R-CNN类似,SSD也提出了锚点的概念。卷积输出的特征图中的每个点对应于原始图像区域的中心点。然后以该点为中心,可以构造六个具有不同宽高比和不同大小的锚点(即SSD中的默认框)。对于VOC数据集而言,SSD中每个锚点对应于4个位置参数(x,y,w,h)以及21个类别概率(包括20个对象类别概率,以及一个锚点是否是背景的描述)。
YOLO由Joseph Redmon在2016年提出,自此之后YOLO系列不断迭代发展,被广泛应用于有实时性需求的目标检测场景中,例如在无人驾驶、物流分类、军事打击等领域,得到了广泛的认可。YOLO的核心思想就是将整张图片作为网络的输入,利用“分而治之”的思想,对图片进行网格划分,直接在输出层回归边界框的检测位置及其所属的类别。现在,YOLO系列包括YOLOv1,YOLOv2,YOLOv3,YOLOv4和YOLOv5。
YOLOv1基于RCNN,对输入图像仅处理一次,通过多个卷积层提取不同的特征,并且每次共享卷积核参数,最后直接在输出层回归边界框的检测位置及其所属的类别。YOLOv1使用完整图像作为环境信息,检测速度非常快,并且可以满足实时要求。但是,缺点是位置检测精度低,无法检测到小的物体。YOLOv2[5]对YOLOv1进行改进。包括主干网络上的改进,以及使用全局平均池化做预测,并提出了一种使用目标分类与检测数据集相结合来训练模型的联合训练方法。经过改进的YOLOv2虽然在小物体的检测方面精度不高,但已经在目标检测的速度和精度两方面达到了一个很好的平衡。YOLOv3[6]的改进包括很多小细节。比如SoftMax分类器被多个Logistic分类器取代。其卷积层约为YOLOv2的2.8倍,网络的深度增加了,体积也变大了,模型的准确性也提高了。为了设计一种可在实际工作环境中应用的快速目标检测系统,YOLOv4[7]在2019年出现了。YOLOv4使用了数据增强和一些目前较新的深度学习网络技巧,比如数据增强的CutMix操作方法,Mish激活函数和Swish激活函数等[8]。目前最新的YOLOv5是在YOLOv4的基础上进行改进的,其运行速度得到了极大的提高,最快的速度达到了每秒140帧。与YOLOv4相比,YOLOv5具有更高的准确率和更好的识别小物体的能力。
与Faster R-CNN相比,YOLO产生的背景错误要少得多。通过使用YOLO来消除Faster RCNN的背景检测,可以显着提高模型性能[6]。YOLO v3很好地吸收了YOLOv1和YOLOv2的优点,做到了比Faster R-CNN更快,并且在小目标的检测上比SSD模型更加准确。YOLOv5则解决了许多YOLO的先前版本中在目标检测时存在的问题,但仍有许多值得认真学习研究改进的地方[9]。
本文使用较小版本和中等大小版本的YOLOv5模型,即YOLOv5-s和YOLOv5-m,针对自动驾驶领域的开源数据集BDD100k,使用K-means算法查找最适合数据集的锚点(anchors)。之后,通过调整数据集中的每个图像的亮度以及模糊程度,实现数据增强。同时通过使用数据扩充,得到一个更准确的模型。
1 方法
1.1 YOLOv5网络结构
YOLOv5的网络结构主要包括三部分,即Backbone部分、Neck部分和Prediction部分,如图1所示。其中,Backbone部分,即主干网络部分,是一系列用来提取丰富的图像特征的卷积神经网络,主要包括Focus结构、普通卷积结构、BottleneckCSP结构以及SPP结构,有效地增加了主干特征的接受范围;Neck部分,用于聚合特征,是一系列混合和组合图像特征的网络层,并负责将图像特征传递到预测层;Prediction部分,即网络预测层,负责在特征图上应用anchors,并生成带有类概率、目标得分和坐标的输出向量,这里的回归损失计算采用GOU_Loss[12],并进行NMS[14]非极大值抑制处理,最后输出预测结果。
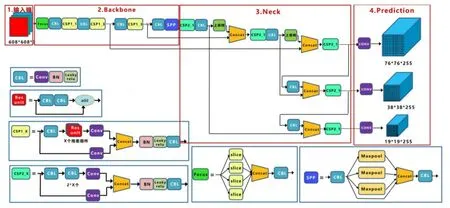
图1 YOLOv5s的网络结构图
YOLOv5具有四个版本,即YOLOv5-s、YOLOv5-m、YOLOv5-l和YOLOv5-x,分别表示YOLOv5的较小版本、中等大小版本、较大版本和超大版本。它们之间的区别只在于模型的深度和宽度设置,通过depth_multiple参数控制模型深度,通过width_multiple参数来控制卷积核的个数,从而可方便地调整模型结构及大小。
本文选择使用YOLOv5模型中的两种,即YOLOv5-s和YOLOv5-m,通过在其上应用anchors改进和数据增强策略,在BDD100K数据集上验证改进模型的有效性。
1.2 anchors聚类分析
anchors,即锚点,从YOLOv2开始,它主要用于预测边界框。虽然原始模型中预设了COCO数据集的锚点,但由于本文使用BDD100K数据集,而在BDD100K数据集中,标注数据的边界框分布范围广、宽高比分布不均并且各类目标数量差别很大,预设的锚点不能合理地直接应用,因此需要K-means算法来聚类计算新的锚点,从而生成更佳的边界框,提高边界框检测率。
这里运用K-means算法的步骤是:①选择K个初始点作为初始的聚类中心点,并计算其余点与这K个中心点之间的距离;②根据它们与初始聚类点的距离,逐一将其分组到距离最近的聚类点;③重新计算每组对象的均值来更新获得新的中心点,即获得了新的anchors;④通过不断重复以上过程,即不断地迭代更新各聚类中心点的值,直到其中的标准测度函数开始收敛或者迭代次数已经达到最大为止,此时的K个中心点就是最终获得的anchors聚类结果。
1.3 数据增强[17-19]
在深度学习中,通常是可供学习的样本数量样本越多,那么学习到的模型的效果越好。然而,在现实应用中,通常会面临的两种困境是:①样本数量不足;②样本质量不好。针对这两方面困境,通常的做法是:①尽力获取更多的数据;②利用手边可用的数据进行数据增强。通过数据增强可以在某种程度上提高模型的鲁棒性以及泛化能力,改善模型性能。
数据增强方法可以大体上分为两类,一类是通过单个样本数据增强,比如进行几何变换(如裁剪、缩放、旋转、翻转等)和颜色变换(如添加模糊、噪声和亮度变化等);另一类是通过多个样本数据增强,利用多个样本来产生新样本,从而进行数据扩充,如SMOTE方法[16]等。
本文所涉及的道路目标检测任务,由于道路场景的复杂性,检测的目标也会涉及各种复杂的情景,例如不同的方向、位置、比例等。因此选择性地使用了一些数据增强方法增加训练样本数据,以获得更加精确的模型。
主要选取的数据增强策略包括以下两种:①针对单个样本的色彩空间增强。具体做法是对一幅图,随机改变其色调,饱和度和亮度。②针对多个样本的马赛克数据增强。可以看作是Cutmix数据增强方式的扩展。Cutmix将两张样本图片组合成一张图的操作可以定义为:
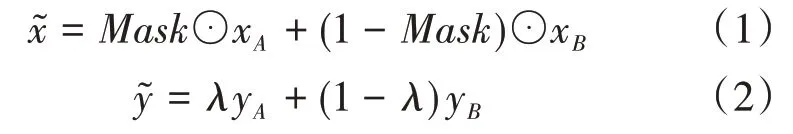
这里,x∈ℝW×H×C表示训练样本图片,y表示训练样本的标签。使用Cutmix得到的结果是两个训练样本(x A,y A)和(x B,y B)组合得到的新样本。其中,λ由均匀分布取样得到,是权衡两个图像的比例参数,用于控制标签融合的线性混合度。
Mask∈{0,1}W×H是与原图大小相同的掩码矩阵,由边界框B的位置决定,在边界框内区域元素填0,其余填1。边界框B=(r x,r y,r w,r h)在样本图片x A中的部分被B在x B的部分所替代,其坐标可以表示为:
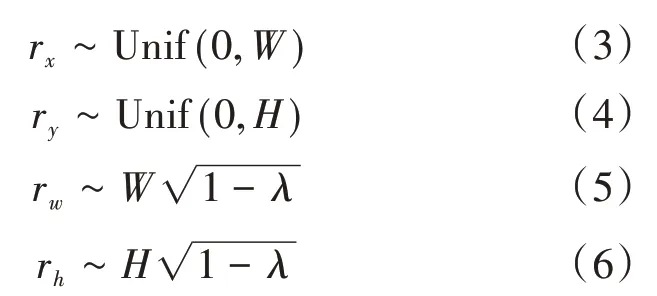
Mosaic数据增强方式,在Cutmix左右拼接图片的基础上,一次利用四张图片,将读取到的四张图片按照左上、右上、左下、右下位置拼接,通过对这样拼接得到的图片的学习,某种程度上可以说是变相增加了训练中的批数量,实验结果可以看到明显的提升。
2 实验
2.1 数据集准备
本文使用伯克利大学在2018年发布的自动驾驶数据集BDD100K。BDD100K的标签是由Scalabel生成的JSON格式,不能直接在模型训练中使用,在训练之前首先要将其转换成YOLO格式。借助于伯克利大学提供的BDD100K数据集的标签格式转化工具,先将数据集标签转换为COCO数据集格式,再进一步转换为YOLO可以读取的格式。
本文使用BDD100K数据集检测13类目标,包括bike,bus,car,motor,person,rider,traffic light(green),traffic light(red),traffic light(yellow),traffic light(none),traffic sign,train,truck。BDD100K数据集中的图像已经分为3个部分:训练集(69863张图片)、测试集(10000张图片)和验证集(2 000张图片)。图2和表1分别显示了类别的分布和边界框的位置信息。
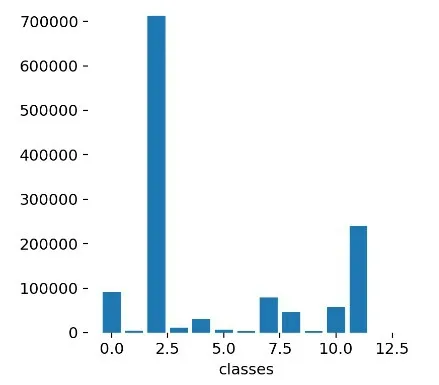
图2 训练数据集的样本分布
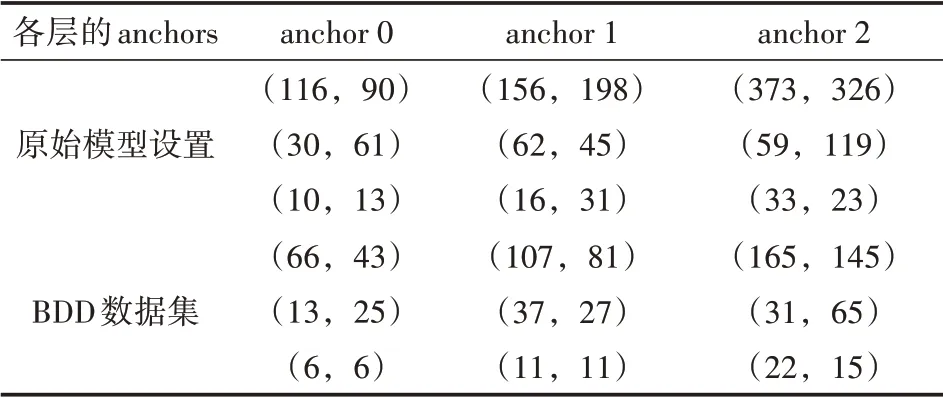
表1 更新前后的anchors对比
2.2 训练环境
训练过程使用一块内存为92 GB的TESLA V100 GPU。数据集中图像的输入大小为640×640,批处理大小设置为16。
2.3 找到合适的anc hor s
通过使用训练集中图像的标注信息,本文使用K-means方法进行聚类,从而为BDD100K数据集计算得到最佳的anchors。本文将anchors的数量保持为默认值,即以K=3进行聚类来找到合适的anchors,然后使用计算得到的anchors来进行模型训练。表1中列出了聚类分析后得到的anchors结果。
2.4 数据增强
考虑到数据集的样本数量在数据增强后快速增加,导致额外的存储压力。因此本文采取的方法是在训练时进行实时数据增强,这样也就不用考虑额外的存储问题。本文在原始样本的基础上,选择使用两种方法:一是调整图像亮度,二是使用马赛克方法,将其应用在原始样本上进行数据增强。经过数据增强方法处理后,样本不仅保有原始信息,同时也添加了一些不确定信息,提高了模型的有效性和泛化能力。
2.5 数据收集与分析
在训练过程中,使用TensorBoard来跟踪和绘制每次训练的损失。训练结束后,使用获得的最佳输出权重在测试集上进行测试,并在不属于原始数据集的图片上进行测试,从而可以了解本文模型是否对于数据集有限制。
3 结果与分析
3.1 新的anchors
通过使用K-means算法处理每个图像的标签,可以获得新的anchors,与YOLOv5提供的默认锚点相比,结果表明新的anchors更合适。表1中所列是更新后的anchors与默认设置的结果对比。与原始值相比,新的anchors在高度和宽度上的比例更小,更适合道路目标识别。新的anchors训练得到的模型mAP0.5值可以达到52.4%,高于默认anchors的准确性(51%)。
3.2 训练损失
图3和图4显示了训练过程中的损失。图3表示在有无数据增强的情况下的训练损失,其中灰色和橙色两条线表示在无数据增强情况下YOLOv5-m和YOLOv5-s的训练损失情况,粉红色和绿色两条线表示在有数据增强情况下YOLOv5-m和YOLOv5-s的训练损失情况。图4表示改变anchors前后的训练损失情况,其中,灰色和橙色两条线表示改变前YOLOv5-m和YOLOv5-s的训练损失情况,蓝色和红色两条线表示改变anchors后YOLOv5-m和YOLOv5-s的训练损失情况。训练周期均设置为150。实验表明,不使用数据增强以及不改变anchors时,损失下降得更快,但使用数据增强以及改变anchors时,损失在训练过程中变得更加平滑。
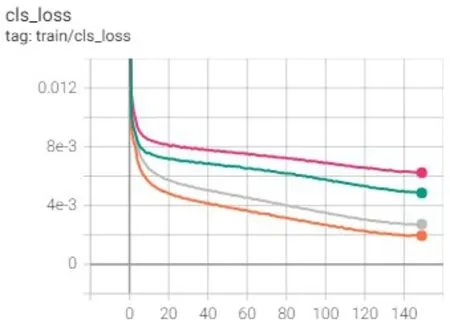
图3 数据增强前后的损失对比
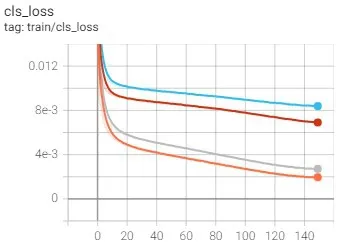
图4 改变anchors前后的损失对比
3.3 精度和速度
图5和图6是训练时的精确度对比情况。图5表示在有无数据增强的情况下的训练精确度,其中绿色和粉红色两条线表示使用数据增强情况下的YOLOv5-m和YOLOv5-s的mAP值情况,灰色和橙色两条线表示不用数据增强情况下的YOLOv5-m和YOLOv5-s的mAP值情况。图6表示改变anchors前后的训练精确度,其中,红色和蓝色表示改变后的YOLOv5-m和YOLOv5-s的mAP值情况,灰色和橙色表示改变后的YOLOv5-m和YOLOv5-s的mAP值情况。
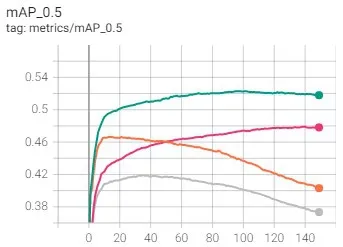
图5 数据增强前后的精度对比
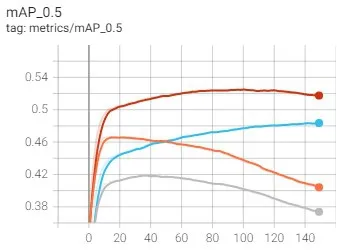
图6 改变anchors前后的精度对比
表2和表3给出了训练模型的一些测试运行结果。可以看出,通过数据扩充与改变anchors,模型效果均得到了提升。并且,与数据扩充相比,anchors的调整带来的准确性提高幅度要低一些。图7所示是模型结果应用在一幅测试图像的输出结果。其中,图(a)是在不修正anchors并且不使用数据增强的模型训练后的检测结果,图(b)是模型改进后的检测结果,图中可以明显看出主体部分,即bus对象在修正后的模型被检测出来了,并且图(a)中没有检测出的一个交通标志在图(b)中也被检测出来了。通过大量实验结果的对比,可以发现,模型修正后,在单幅多个目标对象的图像中,目标对象被全部检测出来的概率得到提高,并且准确度也得到提高。
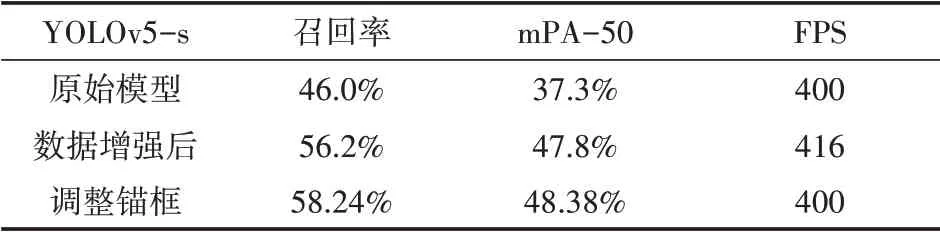
表2 YOLOv5-s模型方法的性能对比
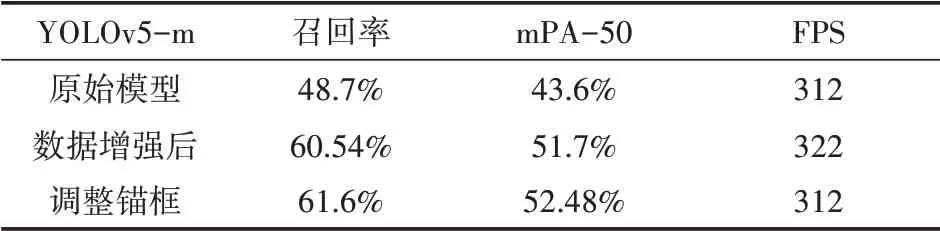
表3 YOLOv5-m模型方法的性能对比

图7 测试图像的目标检测结果
4 结语
对于自动驾驶来说,目标检测算法的实时检测速度和高精度至关重要。基于YOLOv5模型,本文提出一种改进算法,通过使用anchors调整和数据增强,从而使得BDD100K数据集的训练过程相比原始模型设置更加有效和准确。在TESLA V100 GPU上训练150个周期之后,输出模型就可以达到一个较佳的准确率。本文模型在目标检测与识别的实时性方面具有重要意义,对于自动驾驶应用的广泛使用具有重要贡献。
猜你喜欢
农业工程学报(2022年14期)2022-10-19
——《艺术史导论》评介
美育学刊(2022年5期)2022-10-18
今日农业(2022年15期)2022-09-20
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
移动通信(2020年5期)2020-06-08
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小天使·二年级语数英综合(2019年10期)2019-11-08
移动通信(2019年6期)2019-07-31
中国新通信(2017年9期)2017-05-27
