
基于CNN与LSTM相结合的恶意域名检测模型
2021-10-31 06:20廖仁杰
电子与信息学报 2021年10期
张 斌 廖仁杰
(中国人民解放军战略支援部队信息工程大学 郑州 450001)
(河南省信息安全重点实验室 郑州 450001)
1 引言
攻击者通过构造恶意域名达到诱导用户点击钓鱼网站、搭建命令与控制通道等目的,并且可结合Fast-Flux和Domain-Flux技术增强恶意域名躲避检测的能力[1],如何准确、高效地检测恶意域名是网络安全领域亟需解决的问题。
基于合法域名和恶意域名在字符构成上的差异[2],通常将恶意域名检测转化为对域名字符串的短文本分类研究。目前,基于域名字符串进行恶意域名检测的方法按特征提取的不同主要分为以下两类:第1类是基于手工特征提取的恶意域名检测方法,该方法从自然语言分析角度提取语言特征,如词素指标[2],有意义字符占比[3],N-Gram语法特征的KL散度、编辑距离与Jaccard系数[4]等作为域名特征,结合机器学习进行检测,此类方法对由随机字符拼接组成的恶意域名具有较好检测效果,但检测效果依赖特征工程,对不断更新的恶意域名变种需设计新的特征集,同时对通过单词拼接方式生成的恶意域名检测误报率较高;第2类是基于深度学习模型卷积神经网络(Convolution Neural Network,CNN)和长短期记忆网络(Long Short Term Memory,LSTM)的恶意域名检测方法:基于CNN的检测模型通过卷积核提取域名字符串中不同长度字符组的局部特征,设计CNN串联、并联[5,6]结构进行检测,此类模型检测速度快,但为提高恶意域名检测准确率,还需提取域名字符串深层次序列特征[7];基于LSTM[8]的恶意域名检测模型通过提取域名字符串的序列特征进行域名检测,如以域名字符串的嵌入向量为输入的LSTM模型[9]和代价敏感的LSTM.MI[10]模型,比仅采用CNN的检测模型具有更高检测准确率,但仅考虑单字符序列特征,对单词拼接类恶意域名检测效果不佳。文献[11]设计CNN与LSTM相结合的恶意域名检测模型,采用混合词向量作为输入,通过结合域名字符串单字符和双字符序列特征提高模型多分类检测性能,但对单词拼接类恶意域名的检测准确率还需进一步提高。
综上,为提高深度学习模型检测恶意域名的准确率,考虑域名字符串中不同长度字符(单字符与多字符)组合的序列特征差异,在文献[11]的基础上,提出一种CNN与LSTM相结合的包含多条特征提取分支的恶意域名检测模型。其中,CNN用于提取域名不同长度字符组合的局部特征,LSTM用于提取不同长度字符组合局部特征的序列特征,同时引入注意力机制为LSTM不同位置输出的序列特征动态分配权值,通过特征加权降低填充字符对特征提取的干扰并增强序列特征提取能力。实验表明,结合域名不同长度字符组合的序列特征进行域名检测可有效提高恶意域名检测准确率,尤其是单词拼接类恶意域名的检测准确率。
2 基于CNN与LSTM相结合的恶意域名检测模型
2.1 模型组成
基于CNN与LSTM提取域名单字符和多字符组序列特征进行恶意域名检测的模型组成如图1所示。
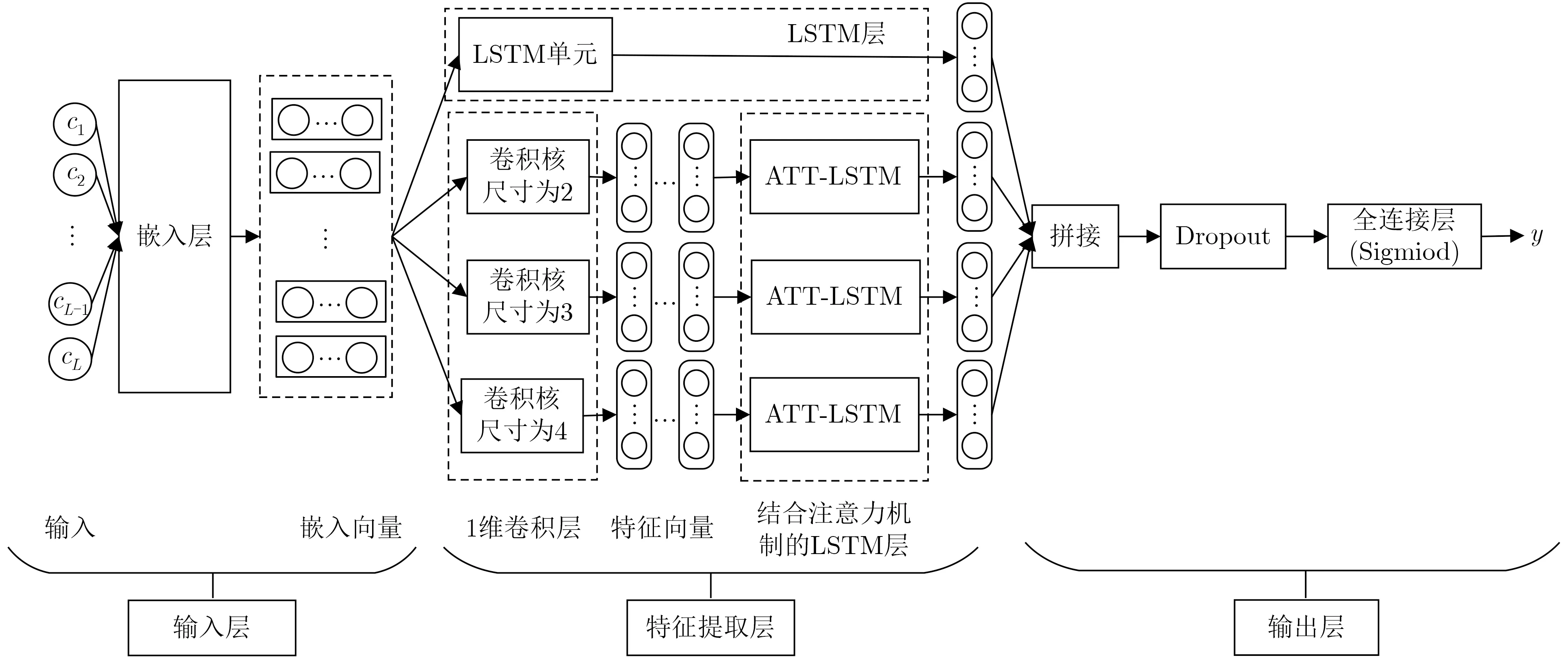
图1 基于CNN与LSTM相结合的恶意域名检测模型(LSTM-Parallel CNN ATT-LSTM,L-PCAL)
该模型由输入层、特征提取层和输出层构成。其中,输入层将域名字符串转换为能被深度学习模型处理的数值向量,包含字符串长度补齐、onehot编码和嵌入向量学习3个阶段,输出域名字符串的嵌入向量。
特征提取层包含LSTM层、1维卷积神经网络(One-Dimension Convolution Neural Network,1D-CNN)层和结合注意力机制的长短期记忆网络(ATTention-based LSTM,ATT-LSTM)层,其中LSTM层用于提取域名字符串单字符序列特征;1维卷积神经网络层采用不同尺寸卷积核提取域名字符串中相邻字符局部特征,该层可看作域名字符串的N-Gram特征提取器;结合注意力机制的长短期记忆网络层采用LSTM提取1D-CNN输出的深层次序列特征并结合注意力机制降低填充字符对序列特征提取的干扰。
输出层将LSTM层输出特征与多个ATT-LSTM分支输出特征进行拼接,再经过Dropout层和激活函数为Sigmoid的全连接层处理,输出域名检测结果y。
2.2 输入层
本层的输入为2级域名标签。首先,将输入字符串长度统一为L,根据域名标签第1个字符必须为字母的限制,在长度不足L的域名标签前端填充“0”字符,得到长度为L的域名字符串,记为

其中,ci为域名字符串中第i个 字符,ci∈{[a-z],[0-9],-},i∈{1,2,...,L}。然后,建立以域名字符串中字符为键,one-hot向量为索引值的字典D,并根据字典将域名字符串S转化为数值向量,记为

其中,D(ci)为字符ci在D中 的索引值,i∈{1,2,...,L}。S D由one-hot向量组成,其特征维度大、特征值分布稀疏的特点将影响模型检测效果,采用Word2Vec技术[12]将S D转换为低维、稠密的嵌入向量,记为

其中,ei∈Rd为第i个字符的嵌入层向量,i∈{1,2,...,L},d为字符嵌入向量维度。
2.3 特征提取层
本层通过深度学习网络提取域名字符串的不同长度字符组合的序列特征,该层由LSTM层、1D-CNN层和ATT-LSTM层构成。
2.3.1 LSTM层
该层用于提取域名字符串单字符序列特征[9],将域名字符串嵌入向量 SE=[e1e2...eL]按e1至eL的顺序输入到LSTM单元进行特征提取,将输入eL后的输出作为域名字符串的单字符序列特征,记为

其中,LSTM()表示LSTM单元的特征运算,hL-1=LSTM(hL-2,eL-1)为输入eL-1时LSTM隐藏层输出,dLSTM为LSTM单元隐藏层输出向量维度。
2.3.2 1D-CNN层
域名字符串的N-Gram统计数据反映合法域名与恶意域名在不同长度字符组合的差异,是恶意域名检测的常用特征,但传统N-Gram特征存在随N值增大,特征维度指数增加、特征值稀疏分布的问题。为避免该问题,采用1D-CNN将域名字符串中相邻字符组合转化为维度固定、数值分布稠密的特征向量。考虑已有研究和计算开销,选取尺寸为2,3,4的卷积核提取域名字符串的2-Gram,3-Gram和4-Gram特征。
对于域名字符串嵌入向量 SE=[e1e2...eL],1D-CNN通过尺寸为k,k∈{2,3,4}的卷积核w,w∈Rk×d进行特征提取包含以下两个步骤:卷积运算,将卷积核看作数据处理窗口,提取 SE中与卷积核尺寸相同的数据与卷积核进行点积运算,再通过非线性激活函数运算得到对应位置的特征输出;卷积核移动,改变卷积核在 SE的位置进行卷积运算得到不同位置的特征值,输出SE中长度为k的字符组合特征x
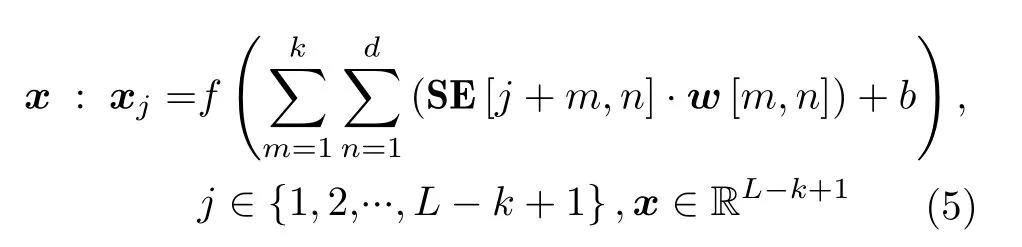
其中,j为卷积核w的 位置参数,m与n为卷积运算参数,·为乘运算,f为非线性激活函数,b为偏置项,w与b通过模型训练进行更新。在实际中,采用多个尺寸相同但参数不同的卷积核进行特征提取,记宽度为k的卷积核个数为Nk,将Nk个卷积核所提取到的特征向量拼接,记为

其中,xi为第i个 卷积核提取得到的长度为k的字符组合特征。
2.3.3 ATT-LSTM层
为利用域名字符串上下文语义信息进行域名检测,采用LSTM提取1D-CNN输出多字符组特征包含的序列特征。考虑输入层用于字符串长度填充的“0”字符对特征提取造成的干扰,引入前向反馈注意力机制[13],通过引入注意力自学习函数动态为不同位置的LSTM单元输出分配权重,增强序列特征提取过程中抗干扰能力[14],结合注意力机制的LSTM单元如图2所示。

图2 结合注意力机制的LSTM单元(ATT-LSTM)
图中特征向量为卷积核尺寸为k的卷积层提取得到的特征向量输入到LSTM单元得到不同位置的隐藏层输出,记为

其中,ht为输入(:,t)时的隐藏层输出,中第t列数据构成的向量。为计算不同位置隐藏层输出的权重,引入自学习函数,记为

其中,f为tanh函数,Wα为网络权重,bα为偏置项,Wα和bα通过模型训练进行参数更新。采用Softmax函数对权重进行归一化,得到归一化权重,记为

将隐藏输出h与归一化权重α进行加权求和,得到字符数量为k的多字符组序列特征,记为
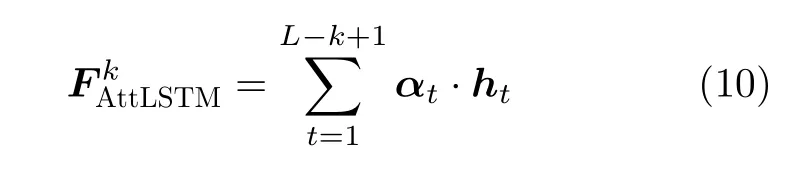
2.4 输出层
将3个ATT-LSTM分支输出的多字符组序列特征向量与LSTM层提取的单字符序列特征向量进行拼接,得到域名字符串的特征向量F

将F输入到激活函数为Sigmoid的全连接层,输出域名判别结果y,其中y∈[0,1]。在训练过程中加入Dropout层,即按照一定概率忽略域名字符串特征向量中部分位置的特征值,以降低模型训练过拟合的风险。采用交叉熵损失函数对检测模型训练效果进行量化,定义为

其中,N为训练样本数量,为样本真实标签,yi为模型预测标签。
3 实验与结果分析
本节验证L-PCAL的有效性,选用Tensorflow 2.0和深度学习库Keras,GPU为NVIDA GTX 860M,使用Python语言实现检测模型搭建、训练与测试。
3.1 数据集
数据集中合法域名样本来自Alexa统计的域名列表[15],随机选择35000条数据构成合法域名数据集;恶意域名样本来自360网络实验室[16],考虑到不同恶意域名样本数量不均衡(如madmax类仅含1条数据,emotet类包含370747条数据)对模型训练和检测效果的影响,进行以下处理:对于样本数量大于2000的恶意域名类别,随机选取2000个样本作为实验样本,其次,删除样本集中数量小于5的恶意域名类别,最终构成包含41个类别,样本总数为35199的恶意域名数据集。将恶意域名与合法域名数据集合并后按5:1:1的数量比例拆分为训练集、验证集和测试集,其中合法域名标签设置为0,恶意域名标签设置为1。
3.2 模型对比与实验参数设置
选取Bi-Gram DT,LSTM[9],Bi-LSTM[5],Stack-CNN[5],Parallel-CNN[6],L-PCL,PCAL和CAL-PCAL作为L-PCAL的对比模型,其中Bi-Gram DT为基于域名字符串Bi-Gram特征的决策树检测模型、L-PCL为图1模型中去除注意力机制后构成的模型,PCAL为图1模型中去除LSTM层后构成的模型,CAL-PCAL为图1模型中将LSTM层替换为卷积核尺寸为1的卷积层与ATT-LSTM单元串联构成的模型。
实验参数设置如下:模型参数:LSTM隐藏层输出维度为64;CNN中非线性激活函数为线性整流函数(Rectified Linear Unit,ReLU),均添加偏置项,不同尺寸卷积核数量均为32;Stack-CNN中卷积核尺寸为3和2;Parallel-CNN中卷积核尺寸为2,3,4;Dropout层丢失率为0.5,其余网络参数均为默认设置。输入层参数:域名字符串长度L为60,嵌入向量维度为32。模型训练:每轮迭代训练样本数量为100,为防止训练过拟合,将在验证集上取得最小损失值的模型作为最终模型。
3.3 评价标准
在测试集上进行模型性能评估,结果统计为以下4类:
TP(True Positive):被正确判别为恶意域名的样本数;FP(False Positive):被错误判别为恶意域名的样本数;TN(True Negative):被正确判别为合法域名的样本数;FN(False Negative):被错误判别为合法域名的样本数。实验参考的判别标准为

其中,查准率和误报率反映模型判别结果的可信度;查全率反映模型的漏报情况;F1分数反映模型综合性能,F1分数值越大说明模型性能越好。
3.4 测试集分类结果与分析
为验证L-PCAL的有效性,采用测试集测试不同模型的恶意域名二分类准确性,结果如表1所示,表中测试时间为模型检测10000条域名数据的处理耗时,各模型分别运行10次,最终结果取平均值。
由表1可知,Bi-Gram DT的各项检测性能指标与基于深度学习的检测模型差距较大,主要是由于Bi-Gram字符特征仅包含域名相邻距离为2的字符组特征且不包含域名字符串序列特征,从而导致较高误报率和较低的F1分数;由CNN构成的检测模型可提取域名字符串的局部特征,但需设计更深层的网络提取域名字符串长距离语义信息以提高检测准确性;由LSTM构成的检测模型可提取域名字符串序列特征,F1分数较由CNN构成的检测模型提升较大,其中,Bi-LSTM模型具有较低的误报率3.38%和较高的查准率96.49%,说明通过LSTM提取域名序列特征进行域名检测能有效提高检测准确率。

表1 模型检测性能对比表
L-PCAL与L-PCL,PCAL,CAL-PCAL的对比实验采用控制变量的方法展开,L-PCAL与L-PCL的对比结果验证了引入注意力机制的有效性、与PCAL的对比结果说明了引入单字符序列特征的有效性、与CAL-PCAL的对比结果说明采用未结合注意力机制的LSTM用于单字符序列特征提取可取得较优的检测性能。L-PCAL结合域名字符串单字符序列特征和多字符组序列特征进行域名检测,具有最高的召回率93.91%和最高的F1分数0.9466。
在检测时间消耗方面,由于影响各模型运行耗时的因素包括模型参数规模、模型运算操作数、数据存取带宽等,故采用整体检测耗时作为模型检测效率的评价指标。Parallel CNN完成1次运算的操作数为62433次,测试耗时为0.57 s;LSTM完成1次运算的操作数为1491201次,测试耗时为4.46 s;L-PCAL为提高检测准确率,引入CNN与LSTM相结合的特征提取分支和注意力机制增加了模型的参数复杂度,其运算耗时主要集中在4个用于序列特征提取的LSTM单元,完成1次运算的操作数为5981408次,测试耗时为12.67 s。L-PCAL虽有较高计算复杂度,但其可在最高F1分数下达到789个/s的恶意域名检测速度,具有较高的检测效率和准确性。
3.5 误报率分析
检测模型的误报率和查全率的综合性能可采用观测者操作特性(Receiver Operating Characteristic,ROC)曲线进行衡量,其中ROC曲线与横坐标面积(Area Under Curve,AUC)越大,说明模型性能越好。在相同的测试集下,不同模型在恶意域名检测二分类任务中的ROC曲线如图3所示。

图3 ROC曲线对比图
为刻画不同模型ROC曲线的差异,表2给出了不同误报率情况下,各模型的TPR和AUC对比结果。
由表2可知,L-PCAL在相同误报率情况下较对比模型具有最高的TPR和AUC值,说明模型通过多分支结构提取域名字符串不同长度字符组合的序列特征,可在较低误报率情况下有效区分合法域名与恶意域名,确保模型检测结果的可靠性。

表2 不同模型TPR与AUC对比表
3.6 单词拼接类恶意域名检测准确率对比与分析
攻击者为躲避不断升级的恶意域名检测技术,以mastnu和suppobox为代表的恶意程序从预存单词列表选取单词,通过单词拼接的方式生成恶意域名,如face-calculate.com。此类恶意域名在字符构成上与合法域名相似度较高,导致基于特征工程和基于深度学习的检测方法检测此类恶意域名误报率较高。
为验证L-PCAL检测单词拼接类恶意域名的检测性能,选取恶意域名样本中mastnu和suppobox构成单词拼接类恶意域名样本集,表3给出了不同深度学习检测模型在该样本集上的检测准确率。
对比表3和表1可知,基于深度学习的恶意域名检测模型对于单词拼接类恶意域名的检测准确率明显降低,尤其对于matsnu类别,部分深度学习模型检测准确率为0,说明此类模型无法区分单词拼接类恶意域名与合法域名的字符构成差异,从而将此类恶意域名误判为合法域名。单词拼接类恶意域名与合法域名在词语搭配方面存在差异,例如,合法域名“nationaljournal”为名词与名词搭配,而matsnu类的恶意域名“attempttrust”为动词与动词组合,语义信息难以理解。为有效检测单词拼接类恶意域名,L-PCAL首先通过不同卷积层提取域名不同长度字符组合的局部特征差异,再通过LSTM单元提取整体序列特征对域名做进一步区分,并引入注意力机制降低填充字符造成的干扰。L-PCAL在两类单词拼接类恶意域名样本检测中,检测准确率分别为25.58%和85.34%,较对比模型中表现最好的LSTM在两个类别的检测准确率分别提升24.8%和3.77%,有效提高单词拼接类恶意域名的检测准确率。

表3 单词拼接类恶意域名检测准确率对比表
3.7 注意力可视化
ATT-LSTM层引入注意力机制的目的如下:(1)降低输入层用于长度填充的“0”字符对多字符组序列特征提取的干扰;(2)增大域名字符串中部分字符组合所处位置的序列特征在输出特征中所占权重。为验证引入注意力机制的有效性,选取合法域名baidu,nationaljournal和恶意域名iwtiojtudnjkrgallso,attempttrust作为L-PCAL输入,将ATT-LSTM单元中注意力结果输出并采用热力图进行可视化,如图4所示,图中每一行数据代表一条注意力分支在位置41~60的注意力取值。
由图4(a)可知,3个注意力分支权重在“baidu”字符串左侧填充字符“0”所处位置注意权值较小,故可有效降低在序列特征提取过程中填充字符造成的干扰。其次,合法域名字符串的权重仅在少数位置取得较大数值,如图4(b)中“nationaljournal”的权重在包含元音的字段“ourn”所处位置取得较大数值,而恶意域名字符串的权重较大值出现在随机字符组合对应位置和单词拼接类恶意域名的单词连接处,如图4(c)中字段“jkrgal”所处位置和图4(d)中“attempt”与“trust”连接处。通过注意力权值可视化一方面验证了引入注意力机制在消除干扰和增加部分字符组序列特征权重的有效性,另一方面为L-PCAL的序列特征提取过程提供一定的可解释性分析。
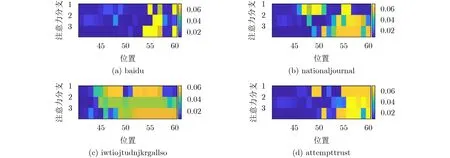
图4 注意力权值可视化
4 结束语
本文提出一种基于CNN与LSTM相结合的恶意域名检测模型。该模型采用多个分支提取域名字符串中不同长度字符组合的序列特征刻画域名字符串的字符构成差异,并引入注意力机制降低特征提取过程中的噪声干扰。实验结果表明,所提模型能有效提高恶意域名检测准确率,尤其对恶意域名matsnu的检测准确率提高较大。下一步工作将引入模型压缩方法,以降低模型参数规模和模型运算时间。
猜你喜欢
无线互联科技(2020年11期)2020-12-01
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
中国教育网络(2018年12期)2019-01-18
少儿美术(快乐历史地理)(2018年7期)2018-11-16
计算机与网络(2018年10期)2018-02-15
燕山大学学报(2014年1期)2014-03-11
测绘科学与工程(2013年6期)2013-03-11
互联网天地(2012年6期)2012-03-24
