
基于自然语言处理的职务犯罪文书数据库系统设计与实现
2021-10-30 05:19金宇杰周彦君高谷刚印杰
网络安全技术与应用 2021年10期
◆金宇杰 周彦君 高谷刚 印杰
基于自然语言处理的职务犯罪文书数据库系统设计与实现
◆金宇杰 周彦君 高谷刚 印杰通讯作者
(江苏警官学院 计算机信息与网络安全系 江苏 210012)
职务犯罪的隐蔽性强,犯罪嫌疑人往往具有强反侦查能力,因此案件通常难以暴露。本课题基于《监察法》视角,利用爬虫技术在线搜集职务犯罪判决文书,进一步利用自然语言处理技术对文本进行关键词分析,按数据库关键词段提取文本,进而建立职务犯罪文书数据库系统。该数据库包含职务犯罪核心信息,从而体现犯罪类型、现状和发展趋势,对研究职务犯罪特征,针对性完善侦查和防范措施意义重大。
职务犯罪;爬虫;自然语言处理技术;数据库系统
国家机关、单位人员利用已有职权,徇私舞弊,贪污贿赂,对社会则具有腐蚀危害性。该类犯罪隐秘性高,犯罪嫌疑人往往具有强反侦查能力,案件难以暴露,是重要的一类智能型犯罪。
涉警职务犯罪隐蔽性更强。与普通的职务犯罪案件嫌疑人不同,该类案件嫌疑人作为公安民警,其身份的特殊性、职务便利和职业经验,具备较强的法律意识,熟悉相关案件办理流程与查证手段,相关犯罪线索更难以发现。嫌疑人明显具备了高素质、涉猎广、阅历深、心理素质好的特点,应对监察委调查活动的反侦察能力较强,一般情况下都难以短时间突破获取重要证据。
对上述现象,通过建设职务犯罪文书数据库,可回溯职务犯罪侦查中的关键措施和证据的运用和收集,对进一步研究职务犯罪特征意义重大。本文引入网络爬虫与自然语言处理技术,通过网络爬虫来获取批量判决文书,再利用自然语言处理技术从下载的判决文书中提取关键信息作为数据库关键词段内容,最终形成职务犯罪文书数据库,为进一步研究涉警职务犯罪特点提供基础数据和关键信息。
1 网络爬虫
1.1 网络爬虫技术概述
网络爬虫是能够自动从网页上解析、下载数据的程序。网络爬虫本质是互联网资源的抓取、分析、过滤、存储的过程。网络爬虫的实现原理及过程可以简要概括如下(见图1)。
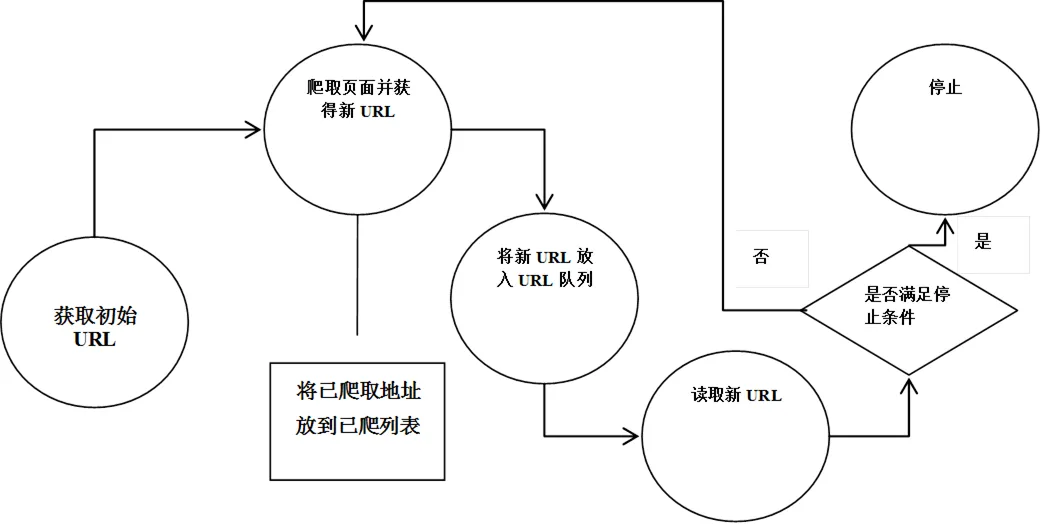
图1 网络爬虫的实现原理流程图
先设定URL,之后根据该URL获取该页面下的子页面URL,将其放入到URL队列当中。读取队列中的URL,对获取到的页面进行数据解析以及持久化存储,获取重复上述的操作,直到满足一定条件才停止。
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫增量式网络爬虫、深层网络爬虫[1]。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。本文基于通用网络爬虫技术对相关文本数据进行获取。
1.2 Selenium处理动态网页
网络爬虫在短时间内大量访问,占用了服务器带宽。该过程可能会阻碍正常用户访问,甚至导致服务器崩溃。另外,数据已成为一个公司的核心资产,企业需要保护自身的核心数据,以维持或提升自身的核心竞争力,因此反爬虫非常重要。常见的反爬虫手段包括统计IP访问限制、单个session访问量以及单个User-agent的访问,基于网站流量统计和日志分析反爬虫,添加验证码限制等。
早期简单网页采取静态网页方式,内容都包含在Html源码里,爬虫通过伪造请求,获取网页Html源码并分析Html源码,就能提取出自己想要的数据[2]。随着网页技术的发展,动态网页[3]逐渐成为主流。有些网站采用Ajax技术,即异步JavaScript和XML。该技术与服务器交换数据,在不重新加载整个页面的情况下,能够更新部分页面,也是一种很好的反爬虫手段。在爬虫程序中如果未传任何参数,只是单纯访问、分析Html源码,将无法获取有效的数据。
处理动态网页主要有下面这些方法:可以根据网页Ajax请求进行分析,用爬虫直接请求其对应接口获取数据,但是这种分析较复杂,更简便的方法是使用Selenium[4]。Selenium是基于Python的第三方Web应用程序库,最初是一个自动化测试工具。其本质是通过驱动浏览器,达到模拟浏览器的操作。可以通过代码控制与页面上元素进行交互,也可以获取指定元素的内容。无需进行API分析,抓包,数据分析等操作,便于使用。
通过Selenium使得浏览器完成自动化的操作,可以有效解决网页动态加载问题。其访问形式跟正常用户使用浏览器大体相似,不容易被反爬虫检测到。不足之处是Selenium需要生成一个浏览器环境,才可进行下一步的相应操作。所以速度相较于构造请求慢一些。
2 自然语言处理技术
2.1 自然语言处理技术概述
随着人工智能的飞速发展,自然语言处理技术在生活中的应用处处可见。自然语言处理(Natural Language Processing,简称NLP)是人工智能和语言学交叉领域下的分支学科。该领域主要探讨如何处理及运用自然语言、自然语言认识、自然语言生成系统,以及自然语言理解系统[5]。
“自然语言”指的是生活中沟通所使用的文字、语音、视频等。人们所使用的语言,如:汉语、英语、法语、日语等语言都是属于这个范畴。至于对“处理”,则是将文字语音等信息数字化处理的一种技术。
如图2所示,自然语言处理的工作原理可以大致主要分成如下几个步骤:第一步获取语料。第二步对语料进行形式化描述,即对语料建立数学化模型。第三步算法化,将数学模型表示为算法的过程。第四步模型训练,包括传统的有监督、半监督和无监督学习模型等,可根据应用需求不同进行选择[6]。第五步就是实用化,对训练出来的模型进行测评改进,最终满足现实需求。

图2 自然语言处理流程图
针对上述五个步骤进行简单的介绍:文本获取大多采用网络爬虫或本地文本数据集。语料预处理阶段主要包括对收集来的语料、文本进行分词、词性标注和去停顿词等操作。特征化处理过程是对完成预处理的文本进行向量化,将完成分词的词语以向量形式表示,以便计算机能够对其进行计算。在模型训练环节,训练方法主要有监督、非监督和半监督学习模型等,具体使用的模型需要根据不同的应用场景进行选择。针对建模后的效果进行评价,常用的效果评估指标有准确率、召回率等[7]。
2.2 自然语言统计模型基础介绍
文本当中关键词能够表示文本的主题思想,是本文建立数据库字段关键参考依据。当前对于文本关键词提取,大多数采用人工标注的手段。随着海量数据以及需求增长,该方法消耗大量人力与时间,效率不高。于是借助计算机自动进行关键词提取的方法受到了越来目前针对文本关键词的提取,为了取得良好的效果,大都采用专家标准的方法,但是面对日益增多的海量文本信息和迫切的应用需求,人工标注已经显得力不从心。于是借助计算机自动进行关键词提取的方法受到了越来越多的重视,已经成为自然语言处理领域的一个研究热点[8]。下面介绍两种关键词提取模型。
(1)条件概率与朴素贝叶斯模型
贝叶斯定理主要是用来描述两个条件概率之间关系的问题。用来计算事件B在事件A发生时的概率情况。记为:P(A|B),该条件概率可表示为:

可以根据公式(2.1)归纳出n个随机变量的联合概率分布公式:



(2)TF-IDF算法





最后,按照下面的公式计算出每一个特征词的特征权值:

关键词提取方法主要分为监督学习和非监督学习两种。监督学习指的是通过大量数据训练模型,利用该模型进行关键词判断。监督学习需要事先标注高质量的训练数据,人工预处理的代价较高[9]。非监督学习无需进行数据训练,简单快速。其中TF−IDF算法即为非监督学习算法的一种。词语在特定文本出现的频率与其TF−IDF值成正比,与其在整个文本中出现的频率成反比。因此其比较偏向选取文档区分度较大的词,过滤掉常见词语。TF-IDF计算特征相对简便,因此本文便使用该算法进行关键词提取。
3 系统设计与实现
3.1 总体架构
总体架构如图3所示。由下至上主要由数据采集层,数据预处理层,数据存储层构成。
数据采集层:主要是通过爬虫程序中Selenium自动化测试工具,从裁判文书网获取相关数据。
数据预处理层:利用自然语言处理技术中TF-IDF算法计算特征权值,找出对应关键词。
数据存储层:在提取出关键词后,利用关键词作为数据库字段参考,使用SQL Server数据库进行职务犯罪文书数据库系统的建设,并且具备管理、检索功能。

图3 系统功能模块图
3.2 数据采集
近些年来被查处的涉警职务犯罪案件数量逐步上升,这几年正是中央打击腐败、惩治受贿类犯罪的关键年,职务犯罪的调查处理覆盖较为全面,查处案件较多。相关的职务犯罪类案件判决文书也在网上公布,如中国裁判文书网、北大法宝等相关文书网站。本文先是利用“职务犯罪”、“民警”、“警察”等词作为关键词,利用爬虫程序进行数据批量的获取,之后利用自然语言技术提取部分关键词,获取到具体职务与罪名,如:先将“交通警察”,“公安局民警”,“贪污贿赂”,“滥用职权罪”等几十个关键词,然后将其进行排列组合后,再分别作为索引的关键词来进行数据的爬取。
以爬取中国裁判文书网为例,获取裁判文书网数据需要登录获取权限才能继续访问网页。针对这种情况,爬虫需要构造并携带cookies信息。同时网站会对账号访问记录进行统计,在一段时间内超过一定访问次数,用户的IP地址便会被禁止访问一段时间。针对这种情况解决方法,第一种是构建自己的cookies池[10],按照一定频率切换,但是部分网站的cookies信息具有时效性,因此较为麻烦。本文直接使用Selenium模拟浏览器操作,跳转到登录按钮,自动输入用户账号密码,进行登录,并且Selenium必须等页面渲染加载出来才能进行下一步操作,访问速率较低,基本不会遇到IP被禁的问题。
再利用Selenium完成对法律文书页面源代码有效获取之后,将直接利用Python语言中自带的lxml库,利用该库中的etree.HTML类对网页源代码进行相应处理,由此自动生成一个可使用lxml库中自带的xpath方法完成解析处理的对象[11]。其中,xpath方法在对被选择对象进行处理时,采用的方法类似目录树,在HTML文档的路径中直接对源代码结构进行准确描述,并使用"/"将上层级路径和下层级路径相互分隔[12]。对某页面标签进行定位后便可对相似的信息进行路径的有效使用。例如,文章的标题与具体内容网页链接是存放在’./div/h4/a’标签下text与href属性当中的。便可批量获取a标签,进行元素提取。
具体爬虫代码如下:
建立一个spider函数,传入相关参数,包括所需要爬取的页数pagenumber参数,爬取的网站url_1参数,以及索引用的关键词keyword1参数、keyword2参数等。传入参数后调用spider函数即开始爬取相关网页,最后将获取的内容保存在字典中,存储到本地。
3.3 关键词分析与文本提取
第一次利用“职务犯罪”、“民警”、“警察”等关键词作为索引依据进行数据爬取。获取到粗略的相关文本后,利用TF-IDF算法对文本进行关键词提取,计算出关键词的词频TF以及逆文档频率IDF,两者相乘得到特征权值,最后将特征权值按照大小排序组成一个新集合。将排序完成的所有关键词的特征权值组成一个新的集合,记作={H,H,H,······,H},为候选关键词的个数。在此过程中,要注意特征权值和关键词的一一对应。
Python的中文分词工具jieba,jieba中文分词工具内置多个算法,支持多种模式进行分词。jieba.analyse.extract_tags中封装了TF-IDF算法,利用jieba.analyse.extract_tags函数直接调用TF-IDF算法来对content中的内容进行关键词提取。
def analyse(file_name,topK):
content = open(file_name, 'rb').read()
tags = jieba.analyse.extract_tags(content,topK=topK)
print(",".join(tags))
3.4 数据库设计
(1)E-R模型
建立职务犯罪文书数据库E-R图可以更加有效地在概念模式下设计数据库,E-R图如图4。

图4 E-R图
(2)数据库逻辑结构设计
职务犯罪文书数据库系统主要面向检察院、法律部门,以及犯罪侦查工作者。因此在设计数据库时候需要注意符合相关特色,设计了裁判文书表、关键词表、职务表、以及罪名表。裁判文书表字段包括裁判时间、文书内容、法院层级、文书标题、裁判程序、裁判理由、罪名、职务、案件类型,以及编号,如表1所示。关键词表字段包括罪名、案件类型、职务,如表2所示。职务表字段包括职务、所属单位、以及编号,如表3所示。罪名表字段包括罪名、犯罪缘由编号,如表4所示。
表1 Document(裁判文书表)

表2 Keyword(关键词表)
表3 Profession(职务表)

表4 Charge(罪名表)
该数据库系统具备管理、检索功能。管理功能是指,相关用户可以根据文书序号来进行基本的数据库管理,具备增删改查等基本操作。并且可以适当调整数据库字段内容、以及字段长度。检索功能:即检索文献,也是本数据库设计的特色。使用者可以根据文书标题、裁判理由、罪名、职务、案件类型、关键词等确立单条件、多条件、模糊检索等功能。大大提高检索的准率,在一定程度上节省使用者的宝贵时间与精力。
4 结语
随着文本获取技术与自然语言处理技术的不断发展,相关的应用也逐渐融入人们的日常生活当中,给人们带来许多便捷。本文利用爬虫技术与自然语言处理技术进行职务犯罪法律文书数据库建设。系统设计主要包括文本获取、关键词提取、数据库建设三个部分。
(1)由于传统的直接请求方法无法获得对应的网页源代码,本文文本获取模块考虑到网站采用Ajax动态加载技术,文使用Selenium自动化测试工具,不需要做复杂的抓包、构造请求、解析数据,解决动态网页内容抓取问题。
(2)传统的监督学习提取关键词方法需要对训练数据集进行高质量标注,该过程人工预处理的代价较高。本文使用TF-IDF非监督学习关键词提取方法,该方法选取文档区分度较大的词,能够过滤掉常见词语,速度较快,节约人工成本。
[1]张松. 同一新闻事件识别研究[D].河北大学,2017.
[2]韩贝,马明栋,王得玉.基于Scrapy框架的爬虫和反爬虫研究[J].计算机技术与发展,2019,29(02):139-142.
[3]ZHENG Qinghua,WU Zhaohui,CHENG Xiaocheng, et al.Learning to crawl deep Web[J].Information Systems,2013, 38(6):801-819.
[4]洪芳.基于Selenium2的Web UI自动化测试框架的设计与实现[D].成都:西南交通大学,2017.
[5]唐聃. 自然语言处理理论与实战[M].电子工业出版社.2018.
[6]赵京胜,宋梦雪,高祥.自然语言处理发展及应用综述[J].信息技术与信息化,2019(07):142-145.
[7]何铠. 基于自然语言处理的文本分类研究与应用[D].南京邮电大学,2020.
[8]牛永洁,田成龙.融合多因素的TFIDF关键词提取算法研究[J].计算机技术与发展,2019,29(07):80-83.
[9]夏天.词语位置加权TextRank的关键词抽取研究[J].现代图书情报技术,2013(09):30-34.
[10]李代祎,谢丽艳,钱慎一,等.基于Scrapy的分布式爬虫系统的设计与实现[J].湖北民族学院学报(自然科学版), 2017,35(3):317-322.
[11]刘清.网络爬虫针对“反爬”网站的爬取策略分析[J].信息与电脑(理论版),2019(03):23-24.
[12]杜晓旭,贾小云.基于Python的新浪微博爬虫分析[J].软件,2019,40(04):182-185.
《监察法》视角下的涉警职务犯罪治理对策研究(2020LX004);江苏警官学院大学生实践创新创业训练计划项目(WA2020006);浙江大学CAD&CG国家重点实验室开放课题《异质多源网络威胁情报数据分析与可视化》(A2102)
猜你喜欢
房地产导刊(2022年10期)2022-10-18
邯郸学院学报(2022年2期)2022-07-05
现代信息科技(2021年21期)2021-05-07
安徽警官职业学院学报(2020年6期)2020-07-21
西夏学(2019年1期)2019-02-10
电子制作(2018年2期)2018-04-18
人大建设(2017年2期)2017-07-21
电子制作(2017年9期)2017-04-17
学习月刊(2016年2期)2016-07-11
学习月刊(2015年20期)2015-07-09
