
无监督学习的多语言神经机器翻译模型
2021-10-29 12:18文丽颖
电子设计工程 2021年20期
文丽颖
(1.武汉邮电科学研究院,湖北武汉 430000;2.南京烽火天地通信科技有限公司,江苏南京 210000)
近年来,机器翻译技术取得了令人瞩目的成就,尤其是神经机器翻译(Neural Machine Translation,NMT)极大程度地提升了机器翻译的译文质量,这种变革式的发展使得神经机器翻译成为机器翻译的新范式[1]。然而,神经机器翻译(NMT)系统依赖大规模的适用于训练此类系统的平行语料库数据,如果没有或缺乏平行语料库,则会经常出现训练质量不佳的情况,甚至不能进行正确的翻译[2]。文献[3-4]提出了不需要任何类型平行语料库的NMT 系统,通过使用单语语料库在源语言和目标语言之间进行跨语言嵌入和迭代反向翻译;从架构的角度来看,这些方法结合了一个编码器和一个或两个解码器。文献[5]提出在有监督的NMT 系统中联合训练多种语言,该系统成功地提高了神经机器翻译性能。受文献[3-5]的启发,文中提出一种多语言无监督神经机器翻译方法,该方法通过训练多语言无监督NMT 模型,可实现一个源到多个目标和多个目标到一个源的翻译。实验结果表明,该模型可以改善双语无监督NMT 模型,并且该模型无需对网络进行多对多翻译训练,网络就可以在参与训练的所有语言之间进行翻译。
1 模型构建
文中基于编码器-解码器框架构建多语言无监督NMT 模型[6],该模型使用一个共享编码器和多个解码器联合训练多种语言,即通过对每种语言的降噪自动编码以及英语和多种非英语语言之间的反向翻译,产生了一个可以将参与训练的任何语言编码成一种语言间表示的通用编码器,以及多个特定语言的解码器。
1.1 双向门控循环单元
循环神经网络(Recurrent Neural Network,RNN)的诞生为了更好地处理具有序列特性的数据,但该网络当前时刻的隐藏状态由该时刻的输入和上一时刻隐藏层的值共同决定,这就会带来梯度爆炸和梯度消失的问题。长短期记忆(Long Short Term Memory,LSTM)网络可以解决RNN 带来的问题,还可以从语料中学习到长期依赖关系。LSTM神经网络模型通过引入门函数来去除或增强信息到达单元状态的能力,门函数包括遗忘门、输入门和输出门。
门控循环单元(Gated Recurrent Units,GRU)神经网络模型与LSTM 非常相似,但相比于LSTM,GRU网络模型只有更新门和重置门两个门函数。GRU网络模型更新门的作用与LSTM 网络模型的遗忘门和输入门作用大致相同,更新门的作用在于通过设置参数值的大小决定当前状态有多少状态信息来自于前一时刻;重置门的作用也是通过设置参数值的大小决定前一时刻有多少状态信息可以遗忘或忽略。与LSTM 网络模型相比,由于GRU 网络模型只有两个门函数,少了一个门函数,因此GRU 网络模型参数更少,训练速度更快。图1 所示为GRU 内部结构图[7]。
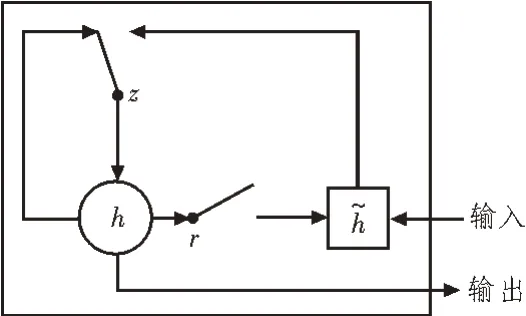
图1 GRU内部结构图
在t时刻输入为xt,GRU的隐藏层输出为ht,其计算过程为:
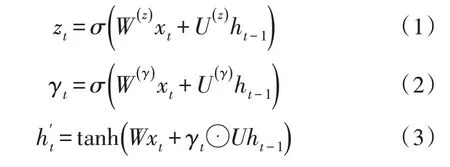
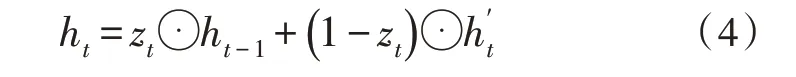
其中,W为连接两层的权重矩阵,σ和tanh 为激活函数,z、γ分别为更新门和重置门。
文中的共享编码器和解码器使用双向GRU 神经网络模型。如图2 所示,网络包含左右两个序列上下文的两个子网络,分别是前向和后向传递。
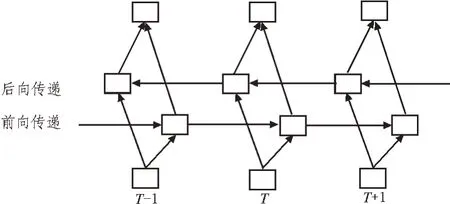
图2 双向GRU神经网络模型
双向GRU 神经网络的输出计算过程为:

文中使用基于元素的和来组合正向和反向的输出。
1.2 双语无监督NMT基线模型
双语无监督NMT 模型架构有一个共享编码器和两个语言特定的解码器,并通过以下两个步骤以无监督方式训练NMT 系统。
1)降噪自动编码。降噪自动编码就是把某种语言的句子加一些噪声(随机交换一些词的顺序等),然后用共享编码器编码加噪声后的句子,最后用该语言的句子解码恢复它。通过最大化重构出的概率来训练共享编码器和该语言的解码器。加噪声的目的是让解码器学会分析语言的结构、提取语义特征,学到一个好的语言模型[8]。
2)反向翻译。反向翻译是把伪平行语料当作训练数据来训练模型的过程。语言L1的句子s1先用编码器编码,然后用L2解码器贪心解码出s2,这样就造出了伪平行句对(s1,s2),这时只作推断,不更新模型参数;然后再用共享编码器编码s2,用L1解码器解码出s1,这里通过最大化来训练模型(也就是共享编码器和L1解码器的参数)[9]。
1.3 多语言无监督NMT模型
文中提出的多语言无监督NMT 模型首先通过跨语言嵌入映射将多种语言映射到一个共享潜在空间;然后使用共享表示,通过去噪和反向翻译,在共享编码器和特定语言解码器的帮助下,仅使用单语语料库来训练NMT 模型。
根据文献[10]创建跨语言嵌入,这是一种完全无监督的对齐单语单词嵌入的方法。首先,学习两个单语嵌入空间X和Y;然后,使用对抗性训练[11],学习矩阵W将X映射到Y。训练一个鉴别器以区分WX和Y,而W被训练成使鉴别器难以判别出是WX还是Y。通过使用W,可以学习小型常用词汇双语词典。求解正交普鲁克问题(Orthogonal Procrustes Problem,OPP),得到了一个在X和Y空间之间转换的新的矩阵W:
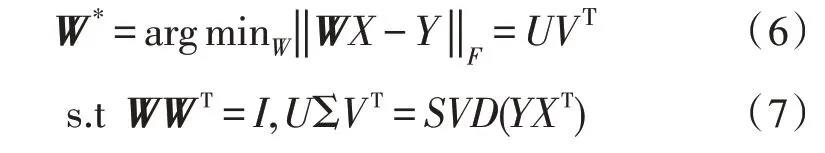
以上步骤可以重复多次使用新的W来提取新的翻译对实现,两种语言之间的新翻译对是通过使用跨域相似度局部缩放(Cross-domain Similarity Local Scaling,CSLS)产生的。CSLS 距离定义如下:
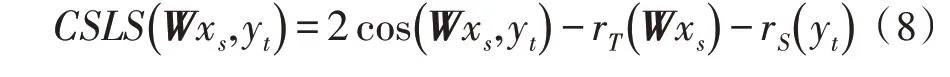
对于n种语言,选择一种语言L1作为锚点,将其他n-1 种语言映射到嵌入空间中。为此,首先为每种语言训练单语词嵌入;然后,逐个将n-1 种语言的嵌入映射到L1的嵌入空间中。文中实验考虑了4 种语言,即英语、法语、西班牙语和德语,通过保持英语嵌入固定,为法语、西班牙语和德语创建了3种跨语言嵌入。
图3 所示为多语言无监督NMT 模型结构,共享编码器和每种语言的解码器是两层双向GRU[12];在训练的每次迭代中,对n种语言L1,L2,…,Ln进行降噪自编码;如虚线箭头所示,将每个Li反向翻译为L1;如实线箭头所示,从L1反向翻译到每个Li,其中i∈{2,3,…,n}。实验设置了4 种语言,L1是英语。在降噪自动编码步骤中,一种语言中的句子被一些随机的单词随机打乱,并训练解码器以预测原始句子。在反向翻译步骤中,要针对源到目标的方向训练系统,首先使用推理模式系统(使用共享编码器和源语言解码器)将目标句子翻译成源句子,以生成伪源-目标平行语句,然后使用该伪平行语句按照源到目标的方向训练网络。对于从目标到源的训练过程类似于以上方法。
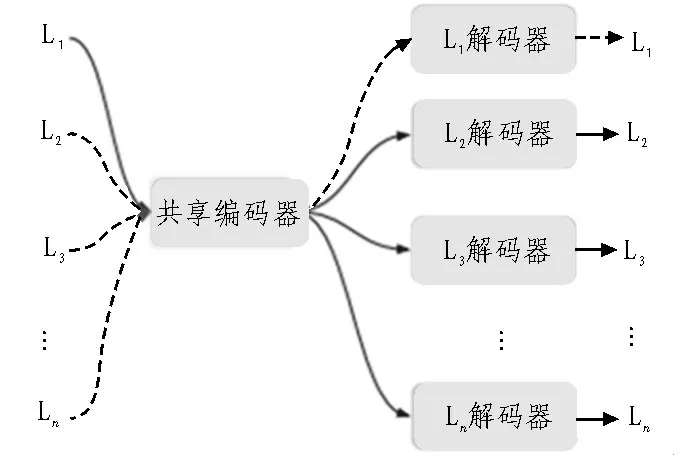
图3 多语言无监督NMT模型结构
2 数据集和实验设置
2.1 数据集
文中使用来自WMT 2014的单语英语、法语和德语新闻语料库和WMT 2013的西班牙语语料库进行训练[13];其中英语、德语、法语和西班牙语的tokens个数分别为4.955 亿、6.226 亿、2.243 亿和1.229 亿。对于测试集,英语-{法语、德语}使用newstest2013 和newstest2014,英语-西班牙语使用newstest2013[14]。文中不使用任何平行语料来训练,也不使用任何开发集来优化模型,使用Moses 对语料数据进行Tokenize 和Truecase[15]。
2.2 实验设置
使用向量维度为300的skip-gram 模型调用fastText(https://github.com/facebookresearch/fastText)训练单语嵌入;对于其他超参数,设置为fastText的默认值[16]。在获得每种语言的单语嵌入后,使用跨语言嵌入映射代码 MUSE(https://github.com/facebookresearch/MUSE)将每种非英语的嵌入映射到英语的嵌入空间中[17],对于映射不使用双语数据。基于双语无监督NMT 模型,使用PyTorch 框架实现了所提出的多语言无监督NMT 模型架构;编码器和解码器是两层双向GRU,将句子的最大长度设置为50 个tokens。对于模型训练,设置嵌入维数为300,隐藏维数为600,词汇量大小为50 000,Adam 优化器学习率设置为0.000 2[18]。由于文中不使用任何开发集,所以对双语无监督NMT 模型和多语言无监督NMT 模型都进行20 万次迭代,保持批处理大小为50个句子,并对最终结果用BLUE 值进行评估[19]。
3 实验结果与分析
作为对比试验,按照文献[3]提出的方法,把为英语↔{法语、德语和西班牙语}训练的双语无监督NMT 模型作为基线模型。如表1 和表2 所示,给出了双语和多语言无监督NMT 模型每个翻译方向的BLEU 值,所提出的多语言无监督NMT 模型在两个测试集的所有翻译方向上均优于双语无监督NMT模型,其中西班牙语到英语BLEU 值最大改进为1.48%。由于参数仅在编码器端共享,并且每个目标语言使用一个单独的解码器,因此,多语言训练在不失去其自身语言特征的情况下提高了所有语言对的性能。
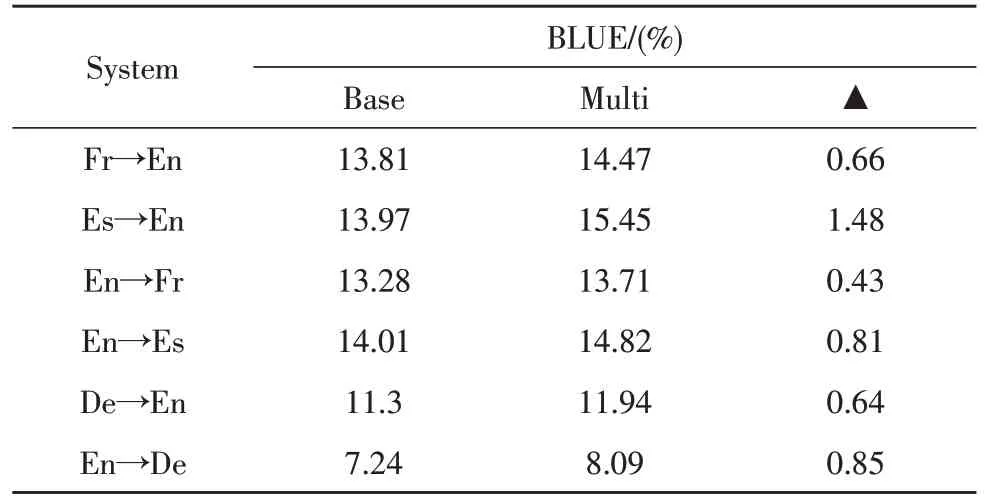
表1 newstest2013测试集BLUE值对比
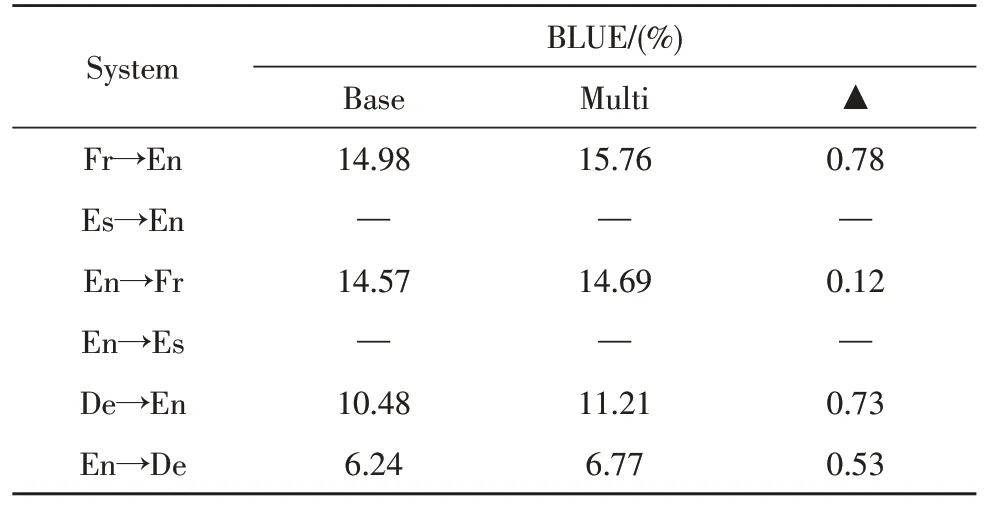
表2 newstest2014测试集BLUE值对比
在训练期间,只在英语和非英语(西班牙语、法语、德语)语言之间进行反向翻译,但网络也学会了在非英语语言对之间进行翻译。例如,为了将西班牙语翻译成法语,文中对西班牙语句子进行编码,编码器的编码输出由法语解编码器解码。为了进行评估,文中将newstest2013 测试集用于西班牙语-法语、西班牙语-德语和法语-德语语言对。表3给出了在训练中不可见语言对之间的翻译结果,可以看出,法语和西班牙语之间的翻译BLUE 值分别高达13.87%和13.92%;涉及德语的语言对BLUE 值最高为7.40%。
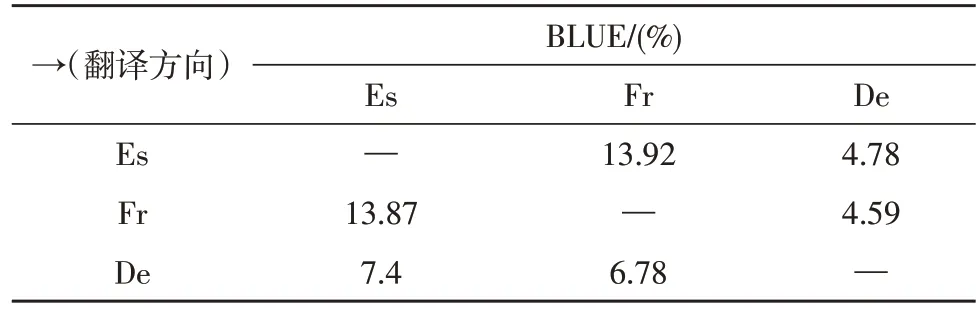
表3 newstest2013非英语语言翻译BLUE值
4 结论
文中提出了一个多语言无监督NMT 模型,使用共享编码器和特定语言解码器联合训练多种语言。提出的方法基于所有语言的降噪自动编码以及英语和非英语语言之间的反向翻译。根据实验结果显示,多语言无监督NMT 模型在所有翻译方向上较双语无监督NMT 基线模型都有了明显的改进,最大改进BLEU 值为1.48%。由于提出的网络中共享编码器能够生成与语言无关的表示,所以网络也学会了在不可见的语言对之间进行翻译。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
天津外国语大学学报(2020年1期)2020-03-25
家庭影院技术(2019年8期)2019-12-04
海外华文教育(2017年10期)2018-01-19
中国工程咨询(2017年8期)2017-01-31
英语知识(2016年1期)2016-11-11
外语教学理论与实践(2016年4期)2016-06-11
外语学刊(2011年6期)2011-01-22
