
基于DBSCAN的智能机舱多源数据异常检测方法
2021-10-29 06:20陈砚桥张侨禹
舰船科学技术 2021年9期
陈砚桥,孙 彤,张侨禹
(1. 海军工程大学 动力工程学院,湖北 武汉 430033;2. 中国舰船研究设计中心,湖北 武汉 430064)
0 引 言
目前,随着我国海军舰船装备快速发展以及海军战略的转型,舰船装备的使用环境愈发苛刻,并对在航率要求逐渐提高。动力系统是舰船的“心脏”,决定了舰船的机动性和在航率,面对新形势,舰船智能机舱是提升动力系统整体性能的最优选择,其具有状态监测、健康评估、视情维修、故障诊断、辅助决策等功能,能够提升动力系统的稳定性、可靠性,并大大降低舰员的工作量,从而起到减员增效,提升舰船战斗力等作用。
从目前舰船智能化研究[1-3]可以得出,数据采集是机舱装备智能化的基础,动力系统设备的数据采集测点高达数千,测试对象众多、分布广,而且动力系统工况复杂运行环境苛刻,在数据采集过程中,不可避免会发生采集信号异常现象,如测试仪器松动、电磁干扰、震动、仪器故障、信号转换出错以及人为因素等导致的异常数据产生。因此识别和清洗传感器异常数据是提高测试数据质量的重要手段,对于舰船动力系统,优质的数据质量对于系统装备的健康评估、视情维修、故障诊断及辅助决策等功能具有重要意义。
传感器异常数据的识别检测方法一般有人工检测、基于专家系统和基于数据驱动的方法。人工检测法需设定阈值,从而判数据是否超限,该方法操作简单,但阈值的设定依赖大量工程经验和试验确定,而且阈值难以根据系统运行工况及测试环境动态修正。基于专家系统法需要建立一套规则知识模型识别异常,其识别率优于人工检测法,但建立规则知识的难度大,且无法识别规则知识限定外的异常数据。基于数据驱动的异常数据识别方法,其可运用统计、数据挖掘等理论对数据建模,从而识别出异常数据,其不依赖专家知识,具有自学习能力,在数据量大、工况复杂的数据识别检测场景具有较大的优势,是智能机舱数据识别检测的理想方法之一。
DBSCAN算法能够利用类的高密度连通性,发现任意形状的类,是基于数据驱动的异常数据识别方法之一。基本原理是:对于一个类中的每个数据,在给定半径的空间中涵盖的数据不能少于某一给定的最小数目[4]。该算法以数据集的局部密度将数据集分类,对于非球形分布的数据集,其具有较为理想的分类效果,并对不同空间分布特征的数据集有较好的适应性,可以识别任意形状的簇[5]。DBSCAN聚类算法的数据检测有很多研究成果:阮嘉琨[6]利用DBSCAN聚类算法检测高速公路交通流的异常数据,有效进行数据分类并分离出异常数据样本;潘渊洋[7]使用DBSCAN算法提取环境特征集,并依据特征集对异常数据进行识别检测;于重重[8]采用DBSCAN聚类分析算法,建立了桥梁健康监测预测模型,对原始数据进行分段聚类分析预处理,实现桥梁健康状况预测功能;蔡怀宇[9]在检测三维激光雷达障碍物应用中,采用了将距离因素引入聚类邻域半径的DBSCAN算法,提高了聚类的准确性;郭保青[10]提出了利用测量序列极值点作为核心对象的DBSCAN聚类方法,依据点簇的运动分布特征判断是否为正常通过的列车。
然而,传统的DBSCAN聚类算法对于单一传感器信号识别有较大优势,但动力系统工况复杂,数据之间耦合强,很难以单一数据的聚类进行异常数据识别判定。而且动力系统长时间的运行后,某些性能参数有可能会偏离设计值,此时DBSCAN算法即失去数据聚类的功能,因此,本文提出基于多源数据的DBSCAN算法的数据异常检测方法,用以表征系统状态的多源数据组为对象进行聚类,基于试验数据自动获取、校正及更新聚类参数,并可通过定期智能获取核心点,用以监测舰船动力系统的状态变化趋势。
1 基于DBSCAN的多源数据异常检测方法建立
1)DBSCAN聚类算法
DBSCAN算法是一种基于密度的空间聚类算法,基本原理为对于一个聚类中的每个对象,在给定半径的邻域中包含的对象不能少于某一给定的最小数目[11],该算法的关键在于定义局部密度,即给定一个邻域阈值Eps和密度阈值MinPts,根据样本的邻域数据密集程度将样本划分为核心点和边界点以及离群点,如图1所示。核心点是其半径为Eps的邻域内包含的对象不少于MinPts个,而边界点的含义是其与核心点距离不大于Eps,但其Eps邻域内包含的对象少于MinPts个,离群点的含义是与核心点的距离大于Eps。最后将所有核心点按照密度可达分类从而输出聚类,同一聚类中任意核心点均可按照邻域Eps的距离依次连接达到到其余所有的核心点。
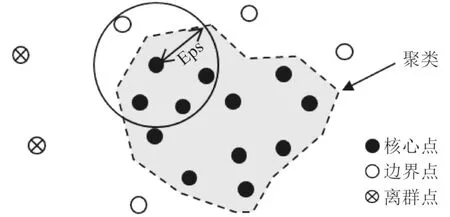
图1 DBSCAN聚类示意图Fig. 1 The schematic of DBSCAN cluster
DBSCAN算法的执行流程如图2所示。2)DBSCAN聚类算法参数计算
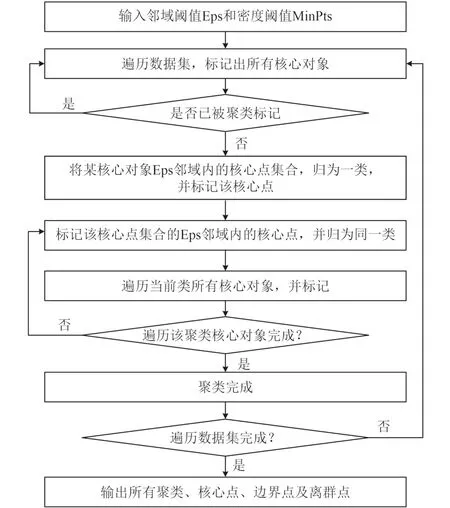
图2 DBSACAN算法流程图Fig. 2 The flow diagram of DBSCAN cluster algorithm
通过DBSCAN算法流程图可以得知,MinPts和Eps为输入参数,其选值的情况对聚类效果影响很大,本文采用K-Dist升序曲线法和数据生成及系数校核联合方法对MinPts和Eps参数进行选取和校核,流程图如图3所示。

图3 Eps,MinPts系数计算及校核流程图Fig. 3 The flow diagram of Eps and MinPts calculaion and correction
首先利用K-Dist升序图方法初步确定Eps和MinPts,选择10~15组数据样本,令MinPts=4,K取4~6,对每组数据样本计算最邻近K的平均距离,并将这些数据样本的最邻近K平均距离进行升序排序,做出K-Dist升序曲线,如图4所示,再根据曲线的拐点确定Eps参数;之后,根据Eps值,计算数据样本内所有点邻域内的密度期望作为MinPts参数。
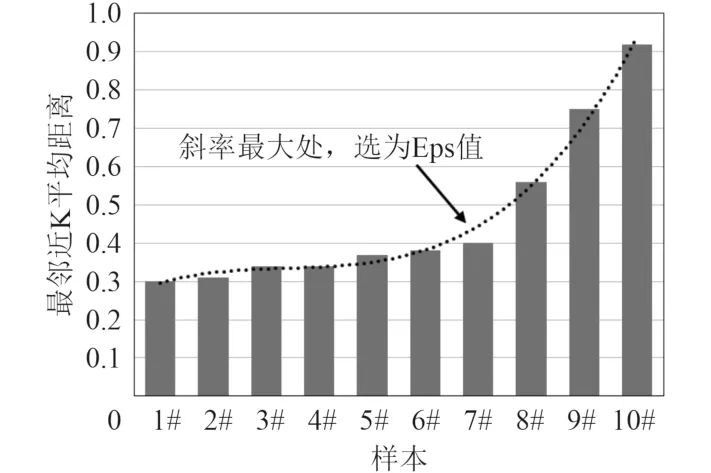
图4 基于10组样本数据的K-Dist升序图Fig. 4 The K-Dist ascending sort diagram based on 10 groups data
统计所有点邻域Eps内的密度值,求其期望值作为MinPts值:
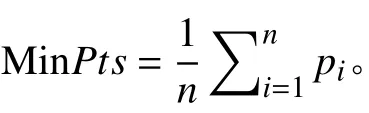
式中:n表示样本点数;pi表示点i在Eps邻域内包含的数据点数。
为了验证得出的Eps以及MinPts是否合适,采用数据生成及校核程序对参数进行验证,首先根据样本数据得出样本数据的均值、方差、峰度、偏度、极值数据特征,根据这些特征生成相似的验证数据样本,并按照一定比例生成异常数据,利用K-Dist升序图方法得出的Eps和MinPts参数,调用DBSCAN聚类程序,进行异常数据的算法识别,并与之前生成的异常数据进行对比,若完全识别,则选取的Eps和MinPts参数合适,若出现数据识别失败,则重新按照K-Dist升序图方法选取Eps值,并计算MinPts参数,直到满足数据生成及校核程序的验证。
3)异常识别方法设计
基于DBSCAN聚类的异常识别方法的思路是利用历史数据识别训练得出的核心数据点及聚类参数,对采集数据进行异常数据识别,并定期基于近期的数据库进行数据识别更新核心数据点及聚类参数,从而优化数据识别并掌握系统性能变化情况。
基于DBSCAN聚类的异常识别程序架构如图5所示。该架构可以根据采集数据进行数据分类,计算MinPts和Eps参数,并通过数据生成及程序自查程序,验证修正MinPts和Eps参数。通过DBSCAN聚类程序获取各工况核心数据点;在数据采集过程中,程序会将采集数据与核心数据点进行欧几里得距离计算,并与阈值Eps进行对比,从而得出正常和异常数据并将数据存入数据库中;在动力系统运行每隔一段时间,利用数据库进行一次程序修正,修正各工况MinPts和Eps参数以及工况核心数据点;通过观测核心数据点的变化趋势,可计算得出动力系统部分性能的变化趋势。

图5 基于DBSCAN聚类的多源数据异常识别程序架构Fig. 5 The framework of multi-source data detecting method based on DBSCAN cluster algorithm
程序流程图如图6所示。从采集系统得到运行参数数据组,根据工况参数,选取该工况参数对应的核心数据及聚类参数MinPts及Eps,调用DBSCAN聚类程序,若该参数组不符合聚类结果,则显示为异常参数,触发异常报警,并在数据库中标记该异常数据组及传感器通道。
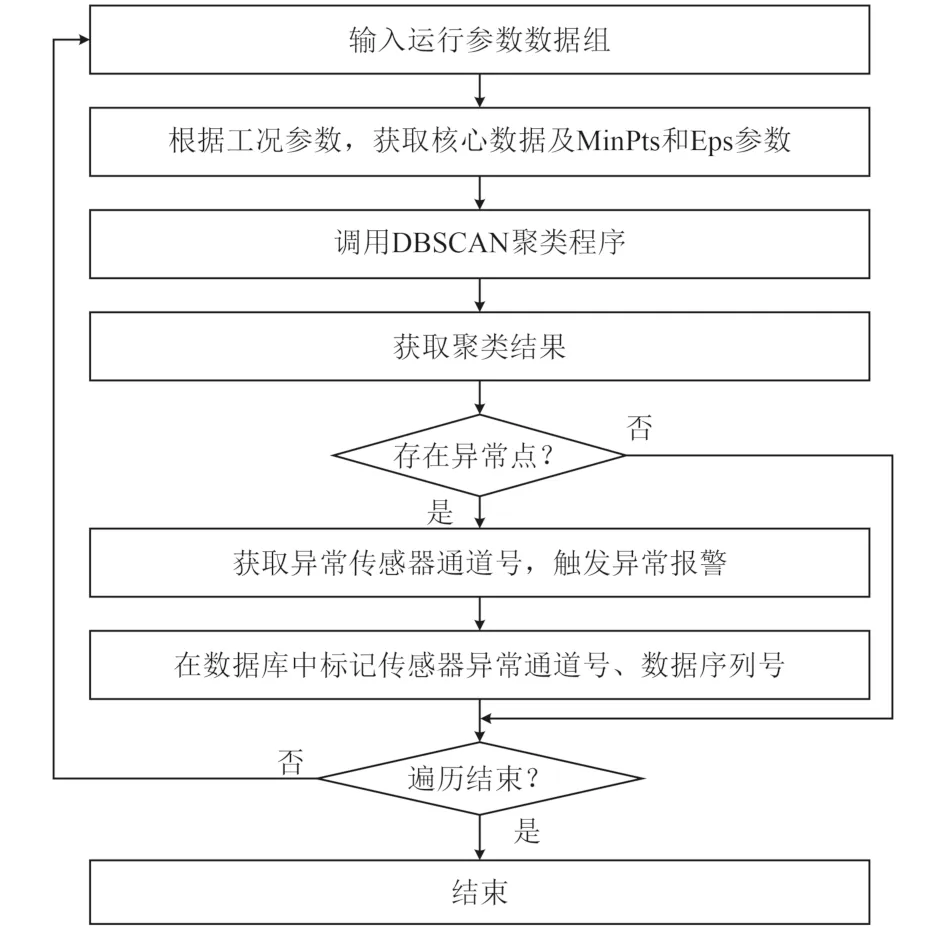
图6 异常识别调度程序流程Fig. 6 The flow diagram of data detecting subprogram
2 仿真测试
对于舰船动力系统,主动力滑油系统是确保动力装置安全、稳定运行的关键系统。对于监测滑油系统的性能,一般采用监测动力装置进口滑油压力的方式,然而该参数受工况负荷、滑油泵转速、滑油总管温度的影响,因此只通过监测单一滑油压力,并不能有效地识别异常数据。因此,仿真测试以滑油系统为测试案例,测试滑油总管温度测点和总管压力测点的传感器数据识别功能。
对于滑油系统,工况负荷、滑油泵转速、滑油总管温度、油压为耦合关系,在工况固定情况下,滑油泵转速固定,滑油总管温度与油压呈一一对应关系。给出2组滑油总管温度与总压力的归一化试验数据,第1组数据为总管温度变化趋势较小,因此总管压力变化也较小,如图7所示。第2组数据为总管温度在一定范围内变化,而总管压力变化范围也较大,如图8所示。

图7 第1类数据,数据分析标记及测试数据识别结果Fig. 7 The data analysis and classification and test data detection for the 1st data group
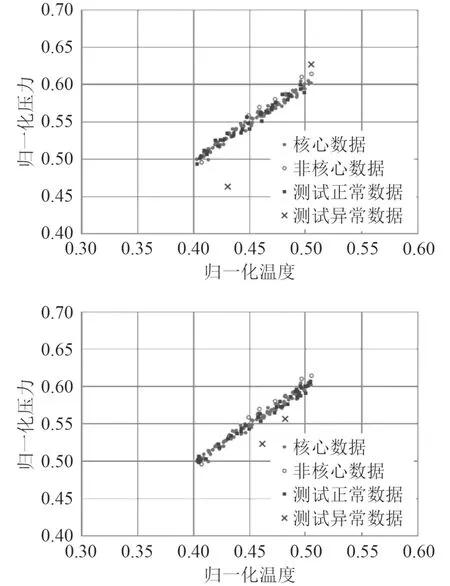
图8 第2类数据,数据分析、生成及识别结果Fig. 8 The data analysis and classification and test data detection for the 2ed data group
首先,基于2组工况数据,进行聚类参数和核心数据计算。利用数据生成程序,分别给每类数据生成10组试验数据,通过参数更新程序,获得MinPts及Eps参数,并基于系数校正程序进行系数校核。通过程序计算,发现对于第1类数据组,其参数偏差较大,在进行参数校正时,发生部分正常数据被误判为异常数据,这也映证了K-Dist升序图法对球形数据簇聚类效果较差,不过通过本文提出的系数校正程序,对MinPts及Eps进行了自动校正,此时聚类效果明显改善。图7展示了程序对原始试验数据的聚类分析,标记出了核心数据和非核心数据;对于第2类数据组(见图8),参数更新程序获得的MinPts及Eps参数较为合适,并通过数据生成及系数校正程序的系数校核,同时展示了程序对原始试验数据的聚类分析,标记出了核心数据和非核心数据。
其次,图7和图8展示了程序对异常数据的检验结果。根据原始数据的数据特征(均值、方差、峰度、偏度)生成测试数据,每组数据40个,并包含5%的与正常数据相差15%以上的异常数据进行聚类分析。可以看出,程序可成功标记两类试验数据的正常数据和异常数据。综上,通过本文提出的基于DBSCAN的舰船多源数据异常检测方法,可以对测试数据进行判断分析,标记正常数据和异常数据,且对与正常信号相差15%以上的异常数据的分析结果,识别度达到100%。
3 结 语
本文针对舰船动力系统的数据特征,建立了基于DBSCAN的舰船多源数据异常检测方法,介绍了该检测方法的程序框架、程序流程,并基于典型的滑油系统数据进行检测测试。经过测试,该检测方法可以对测试数据进行分析,自动得出并修正聚类参数,且对正常信号相差15%以上的异常数据检测结果识别度达到100%,提出的异常数据检测方法可行有效,可以作为智能机舱数据处理系统的方案之一。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
舰船科学技术(2022年11期)2022-07-15
农业工程学报(2022年7期)2022-07-09
舰船科学技术(2022年10期)2022-06-17
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
舰船科学技术(2021年12期)2021-03-29
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电子技术与软件工程(2019年8期)2019-07-16
知识力量·教育理论与教学研究(2013年11期)2013-11-11
