
面向轻量化网络的安全帽检测算法
2021-10-28 06:01:44蒋润熙阿里甫库尔班耿丽婷
计算机工程与应用 2021年20期
蒋润熙,阿里甫·库尔班,耿丽婷
新疆大学 软件学院,乌鲁木齐 830046
近些年越来越多在人工智能上的研究被应用到生活中。安全帽是工人在施工现场的重要防护工具,但许多工人因安全帽缺乏舒适感而选择不佩戴,这将危及工人的生命安全[1]。因此实时监控工人是否正确佩戴安全帽十分重要,但工地上作业环境危险,不适合用人力进行实时监控,所以考虑将机器视觉应用其中,代替人力进行安全帽佩戴检测。这可以一定程度上预防安全事故的发生,保证工人的安全。
安全帽检测由于施工环境复杂、摄像头拍摄角度、摄像头距离目标的距离远近等问题,国内外许多学者对其进行研究。刘晓慧等[2]利用肤色检测定位人脸区域,将Hu矩作为图像的特征向量,利用支持向量机(Support Vector Machine,SVM)作为分类器对安全帽进行识别。冯国臣等[3]选取SIFT角点特征和颜色统计特征的方法进行安全帽检测。Park等[4]通过HOG特征提取来检测人体,而后通过颜色直方图识别安全帽。李琪瑞[5]提出研究如何定位头部区域以及安全帽颜色特征的计算来检测安全帽。虽然以上方法可以有较好的精度需求,但传统检测算法存在特征提取困难、泛化能力差等问题,还需进一步的改进。由于神经网络的发展,深度学习在目标检测领域已有很好的效果,许多研究者进行研究[6]。
基于深度学习的目标检测算法一般分为双阶段检测和单阶段检测算法。双阶段检测算法包括物体定位和图像分类两个步骤。主要的检测算法包括RCNN[7]、SPP-net[8]、Fast-RCNN[9]、Faster-RCNN[10]、Mask R-CNN[11]。单阶段检测是基于回归的检测算法,主要使用YOLO[12]系列和SSD[13]算法。双阶段检测算法的准确度高,但所需检测速度慢。与之相反单阶段检测虽然准确率略逊,但在速度方面有较大的提升,符合本文需求。因此本文将使用单阶段算法进行检测。由于SSD网络层数不深,对特征提取不充分,所以本文使用YOLO作为检测网络[14]。许多学者也将深度学习方法应用在安全帽检测中。张明媛等[15]使用Faster-RCNN对安全帽进行识别。王兵等[16]改进GIoU计算方法并结合YOLOv3进行安全帽检测。施辉等[17]在YOLOv3中添加特征金字塔进行多尺度的特征提取,获得不同尺度的特征图,以此实现安全帽的检测。尽管上述使用的网络可以实现对安全帽的自动检测,同时准确率高,但以上网络都是大型复杂网络,需要足够的算力支持。考虑到在实际的检测场景中,要求将算法部署在移动端或者嵌入式设备上,而移动端的计算能力远不如计算机等大型设备,不足以支撑大型神经网络所需的计算。
因此为适应其有限的计算能力,本文基于Inverted Resblock结构重构新的主干特征提取网络,跟大型网络相比该网络减少了参数量和浮点数计算,对算力的需求大大降低。同时,大多数移动端设备无法使用GPU来处理数据,所以本文还考虑算法在CPU上的处理速度。这对网络的轻量化要求更高,因此需进一步压缩模型。
目前主要使用的模型压缩方法包括:知识蒸馏、低秩分解、参数量化、参数剪枝等。知识蒸馏由Hinton等[18]提出,是将预训练好的大型网络作为教师模型,并用其输出作为网络结构较小的学生模型的输入,可以使得学生模型具有和教师模型相当的处理能力,以此进行模型压缩,但该方法训练起来复杂,并且用教师模型SoftMax层的输出来指导,只限于分类任务,不适合本文的需求[19]。Denton等[20]提出低秩分解,通过奇异值分解技术来压缩模型。虽然该方法将模型压缩成原先的3倍,但只压缩全连接层,没有对卷积层进行处理。参数量化[21]是将神经网络中使用的32位浮点数经过线性变化转化为8位整型数。虽然参数量化可以减少存储空间,并加快网络运算速度。但需设计专门的系统框架,灵活度不高。相反参数剪枝[22]方法,不仅灵活度高,而且无需训练复杂网络,直接对训练好的网络进行剪枝。因此本文将采用参数剪枝方法对网络进行压缩。
在实际工程需求中,不仅需要网络有较好的精度,更重要的是网络的推理速度与实时性还应满足需求。为提高推理速度,本文将卷积层和BatchNormalization(BN)层融合,更好地满足实时检测的需求。
1 相关理论
1.1 YOLOv5网络
YOLOv5是Ultralytics公司提出的目标检测网络,并有v5s、v5m、v5l、v5x四种不同大小的模型,v5s是其中网络深度和宽度最小的模型,权重大小仅27 MB。对比YOLO系列中具有代表的YOLOv3[23]模型,其权重文件大小达到246 MB,是YOLOv5s的9.1倍,且在检测640×640大小的图像时参数量达到61.9×106、浮点运算超过156×109,而越小的权重对移动端的性能要求也越低,部署起来越方便[24],所以YOLOv5s比YOLOv3有更大的优势。YOLOv5s网络主要使用BottleneckCSP结构,结构如图1所示。

图1 BottleneckCSP结构Fig.1 BottleneckCSP structure
BottleneckCSP结构分为两部分,第一部分进行Bottleneck操作,其是一种经典的残差结构[25],它经过一次1×1和3×3的卷积操作后,将卷积结果与输入相加。另一部分通过1×1卷积进行降维,减少一半通道数。最后两者合并输出。YOLOv5系列中,将通过深度和宽度两个参数来控制网络结构大小。在v5s中Bottleneck操作只做一次,而v5l的深度是v5s的三倍,所以将进行三次Bottleneck操作。BottleneckCSP同理,也会受深度参数的影响。
1.2 MobileNetv2网络
MobileNetv2[26]是兼并轻量化、速度和准确率的一种专门针对移动设备而提出的神经网络。主干由Inverted Resblock结构块构成,结构主干如图2所示。

图2 Inverted Resblock结构Fig.2 Inverted Resblock structure
Inverted Resblock的提出是文献[26]中发现Residual block使用的激活函数ReLU在低维时可用信息较少,容易造成信息丢失,而在高维度运算时,丢失的信息相对变少,因此构造出该结构。Inverted Resblock中先利用1×1卷积升维,再通过3×3的深度可分离卷积DWConv降低计算参数量,之后通过1×1卷积降维,最后将结果和输入相接。
1.3 模型压缩
通道剪枝是在已训练好的模型基础上对网络进行稀疏训练;而后根据权值的绝对值进行排序;最后设定适合的阈值或剪枝率,如果权值小于设定的范围就会被剪枝。由于剪枝后模型会损失一定精度,还需要对剪枝后的网络进行微调来恢复网络性能。模型压缩步骤如图3所示。

图3 模型压缩步骤Fig.3 Model compression step
1.3.1 稀疏训练
稀疏训练通过对BN层进行L1正则化训练,使BN层的权值尽可能趋向于0,被稀疏的权值将重新分配到网络的其他有效层中。稀疏训练将直接影响剪枝后的模型是否满足所需性能。稀疏训练的损失函数公式如下:
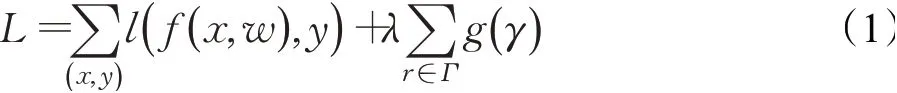
其中,(x,y)是训练数据的输入和输出。第一项为卷积层训练的损失函数。后一项中,γ为BN层的缩放因子,通过改变γ的初始值和训练γ进行网络稀疏。g(γ)是缩放因子的损失函数,来评估缩放是否合理。由于本文使用L1正则化进行稀疏,因此g(γ)=|γ|。λ用于平衡前后两项的损失。经过稀疏训练后,网络将变得更加密集,而后通过剪枝,得到更小的网络,与此同时网络性能却没降低,甚至变得更好。Dettmers等[27]对该现象进行了说明,表示稀疏网络学习的是更一般、更大范围的特征,有更好的泛化能力。
1.3.2 剪枝与微调
通过稀疏训练后,网络的BN层中大部分通道数的权值都将趋近于0,此时这些层对网络的贡献随之降低,剪枝后不会造成较大的性能损失。文献[28]通过L1正则化对网络进行稀疏;然后对参数进行排序;最后设定一定大小的剪枝率,将小于设定值的通道剪除。但如果网络的一层中所有通道权重的绝对值都小于设定阈值,此时该层的所有通道都会被剪枝,这样网络结构就被破坏。对于上述的情况本文选择保留权重的绝对值最大的一层通道,以此来保证网络结构的完整。
网络在剪枝后,可以有效减少过拟合,但精度将存在一定程度的丢失,本文通过微调来恢复精度。微调的方式一般分两种,一种是逐层剪枝,剪枝完后重新训练,重复多次进行微调,但此方法需要迭代多次,尤其在网络结构更深时需消耗大量的计算资源。因此本文选择另一种方式,一次性对所有BN层进行剪枝,然后重新训练来进行微调恢复精度。
1.4 融合卷积层和BN层
BN层的存在可以使训练更稳定,同时有效防止过拟合。因此本文的每层卷积层后面都添加了一层BN层。为加快网络在CPU上的推理速度,本文考虑将卷积层和BN层融合[29]。对于Batch中的第i个样本,令输入样本为x i,其经过BN层后输出为yi。BN层公式如下:

其中,μ为Batch中输入样本的均值,σ2为Batch内输入样本的标准差,ε为一个极小常数,用来消除除零错误。γ、β为训练参数,通过损失函数来改变。在神经网络的训练过程时μ、σ2、γ、β都是变量,但在训练完成后这四个参数都被确定。因此在进行推理时,BN层的公式可以变为:
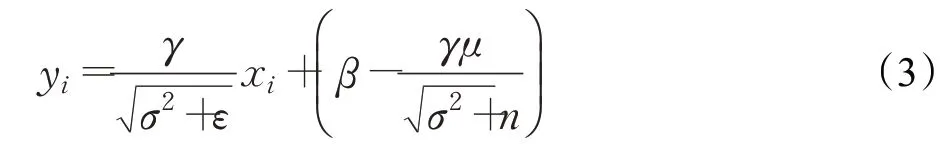
其中令:


则:

因此在网络进行推理时,可以把BN层当作线性操作。而对于卷积层的输入输出公式如下:

其中,w和c分别表示卷积层的权重和偏置。由于式(6)、(7)都是线性表达,因此本文得出可以将卷积层和BN层融合起来,公式如下:

将卷积层与BN层相互融合,在降低参数量的同时减少推理时网络的深度、加快模型推理速度。
2 改进后的YOLOv5网络
为解决在移动端和嵌入式设备算力不足无法部署大型网络的问题,本文从权重大小、计算量、检测速度和精确度等方面考虑,提出HourGlass结构,并用该结构替换YOLOv5s的主干网络得到HourGlass-YOLO(HGYOLO)。同时为适应移动端有限的算力,对网络使用通道剪枝进一步进行减少网络参数量。融合卷积层和BN层提高检测的速度,以便更好地满足实时性的需求。
2.1 HourGlass结构
Inverted Resblock结构在轻量化网络方面有较好的性能表现,但Daquan等[30]解释Inverted Resblock结构存在梯度混淆的情况,同时1×1卷积会减少空间信息。因此根据Inverted Resblock结构中存在的问题,本文重建新的主干网络HourGlass结构,如图4所示。

图4 HourGlass结构Fig.4 HourGlass structure
HourGlass结构中先进行3×3的DWconv,再利用1×1卷积降维,降维后进行3×3的DWconv,然后用1×1卷积重新升维,最后将结果和输入相接。因为Inverted Resblock存在梯度混淆,所以本文重新使用Residual block。又使用1×1卷积会减少空间信息,因此在输入后加入一个3×3的DWconv来获取更多的空间信息。而针对Residual block存在的激活函数在低维时信息丢失的问题,本文将其设置在第一个DWconv和最后一个1×1卷积中来解决,以此构建新的网络HourGlass。该结构的公式描述如下:

其中,F表示输入张量,G表示输出张量,Φi,p、Φi,d分别表示第i次的1×1卷积和3×3深度可分离卷积。HourGlass这种设计结构让更多的空间信息传入神经网络,使深度可分离卷积可以进行更丰富的特征提取。
2.2 HourGlass-YOLO
将YOLOv5s的主干网络替换为HourGlass结构。改进后的HG-YOLO网络,如图5所示。
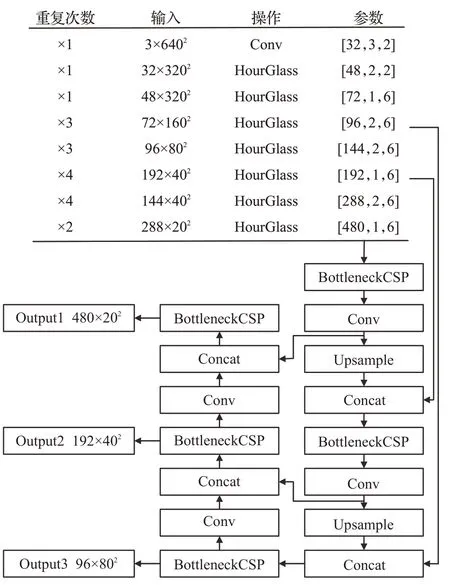
图5 改进后的网络结构Fig.5 Improved network structure
网络输入为640×640大小的图片,主干网络除第一层为Conv层外,其余由HourGlass结构构成。其参数分别表示输出通道数、步长和是否进行升维。除第一个HourGlass,其余HourGlass结构都进行6倍的升维操作。网络的输出部分沿用YOLOv5s的输出,通过特征融合[31]的方式对20×20、40×40、80×80三个不同尺度的图片进行预测。
3 实验
3.1 实验数据及环境
本实验的运行环境为Windows 10操作系统,通过Pytorch深度学习框架实现HG-YOLO模型算法。硬件配置:Nvidia GeForce GTX1650 GPU、AMD Ryzen54600H CPU。本文所用的数据集是SafetyHelmetWearing,其中部分的人脸数据来自SCUT-HEAD数据集,并使用PASCAL VOC的标记方式对数据进行标记并训练。根据实际场景,本文对未佩戴安全帽、佩戴安全帽和人进行检测,共7 577张图片,其中训练集6 062张,测试集1 212张,验证集303张。由于施工环境的复杂,并且SCUT-HEAD数据集中的人脸数据绝大部分都是小目标物体,导致检测难度大大增加,样式如图6所示。

图6 SafetyHelmetWearing数据集Fig.6 SafetyHelmetWearing dataset
3.2 模型压缩训练
对HG-YOLOv5进行稀疏训练,尽可能将BN层的权值稀疏到0。但稀疏训练是一个追求平衡的过程,因为本文既想将更多BN层稀疏到0,也想在剪枝微调后恢复足够的精度。同时稀疏训练将直接影响最后的结果,如果网络稀疏程度不够,可能很多权值不为0的通道被剪除,丢失大量信息。但稀疏的太过密集,剪枝时会删除过多通道,可能导致微调后无法恢复足够的精度,所以寻找一个合适的稀疏率(sparse learning,sl)是其关键一步。本文选择三个不同的稀疏率0.001、0.002、0.003进行对比。稀疏过程中BN层的变化,如图7所示。其中图7(a)、(b)、(c)分别展示稀疏率0.001、0.002、0.003的BN层的变化过程,经过100轮的迭代训练后,BN层的权重都被压缩,逐渐靠近0。
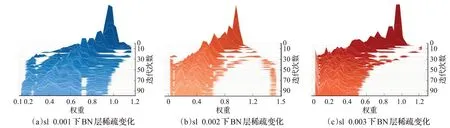
图7 不同稀疏率下BN层的变化Fig.7 Changes of BN layer under different sparsity rates
稀疏训练结束后,对模型进行剪枝。剪枝前需设置剪枝率,通道权重的绝对值小于设定剪枝率对应的阈值时则删除,且与之相连的通道也将删除。但如果一层中所有通道的权值都小于阈值,则保留该层权值最大的通道,以保证网络结构的完整性。剪枝完成后,再通过微调恢复精度。本文将评估原网络HG-YOLOv5和网络剪枝微调后的结果,评估指标包括:精确度(P)、召回率(R)、平均精度(mAP)、稀疏后网络对应权值的最小值(Min)与最大值(Max)、阈值(threshold)、网络参数量(parameters)和浮点数(GFLOPS),结果如表1所示。
表1中,首先将MobileNetv2的主干结构替换YOLOv5s的主干得到MobileNet-YOLOv5与改进的新主干网络HG-YOLOv5进行对比,虽然两者在各个指标上没有太多的差别。
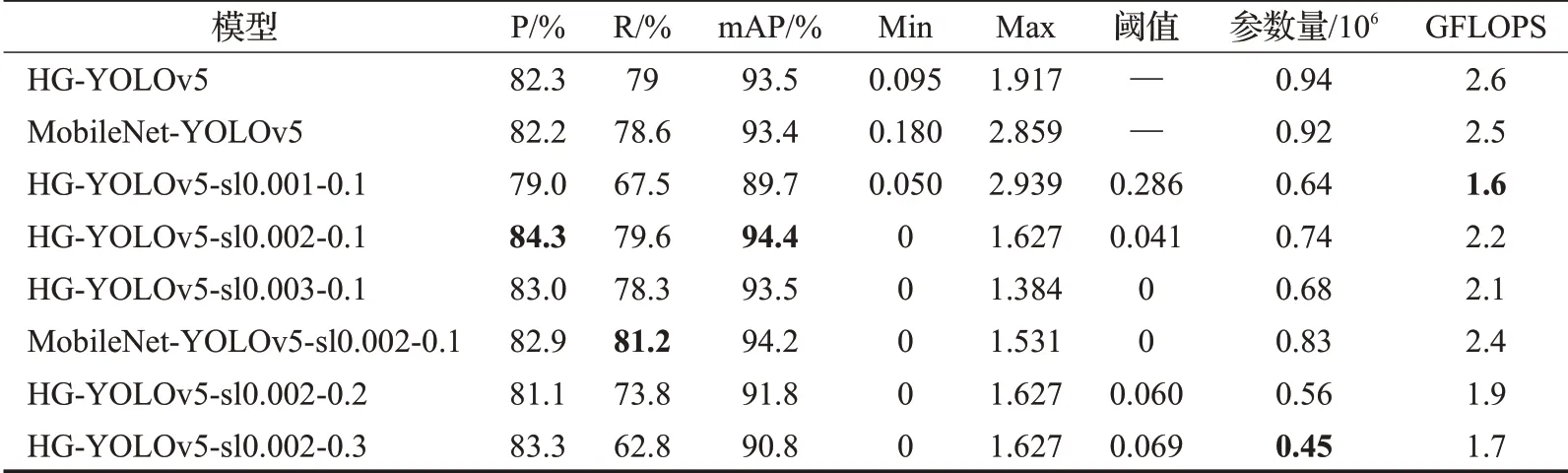
表1 原网络和剪枝后的指标对比Table 1 Comparison of original network and index after pruning
但本文进一步对比HG-YOLOv5在不同稀疏率、同一剪枝率下的指标。当稀疏率为0.001、剪枝率为10%时,剪枝阈值被设定在0.286,虽然此时网络的参数量和浮点数是三个稀疏率中减少最多的,但在50轮的微调后,mAP比原网络HG-YOLOv5降低3.8个百分点,说明网络稀疏的程度还不够,剪掉很多权值不为0的通道数。而在同一剪枝率下将稀疏率改为0.003,网络参数降低了0.26×106,但精度和原网络一致,说明此时有较好的稀疏效果。但反观稀疏率为0.002时剪枝后的表现,其参数量下降虽不如稀疏率为0.003时,但微调后mAP反而比原网络上升0.9个百分点。因此实验得出稀疏率为0.002、剪枝率为10%时HG-YOLOv5网络的稀疏效果最好。
所以又对比该稀疏率和剪枝率下MobileNet-YOLOv5的性能,实验得出HG-YOLOv5-sl0.002-0.1的mAP、参数量和浮点数都优于MobileNet-YOLOv5-sl0.002-0.1。
本文还对比不同剪枝率对HG-YOLOv5-sl0.002的性能影响。由于HG-YOLOv5的参数相比大型网络已经很少,所以剪枝率只设定在20%和30%。实验得出剪枝率为30%时,参数量是所有网络中减少最多的,比原网络降低了0.94×106,浮点数也减少0.9 GFLOPS,mAP比HG-YOLOv5-sl0.001-0.1模型要高1.1个百分点。但相比HG-YOLOv5-sl0.002-0.1,mAP还是降低3.6个百分点。
3.3 融合卷积层与BN层
由于本文要求将算法部署在移动端或嵌入式等算力不高的设备上,因此本文还要考虑算法在CPU上的处理速度。而CPU没有GPU一样的算力,无法很好地满足检测的速度需求,因此本文将融合卷积层与BN层,减小网络层数和参数量,提高检测速度。网络融合后的指标对比如表2所示。
由表2可以看出,将卷积层和BN层融合后,虽然参数量和浮点数没有降低很多,但每张图片在CPU上的推理时间都相应减少。在大型网络YOLOv5中,平均推理时间减少了23 ms。在轻量化的网络中,对于没剪枝的HG-YOLOv5其平均推理时间减少了28.1 ms,在剪枝了10%和30%后的网络中其平均推理时间分别减少了26.4 ms和19.8 ms。实验结果证明,融合卷积层和BN层在大型网络和轻量化网络中都可以有效地提高网络的检测速度,可以更好地满足对检测速度的需求。
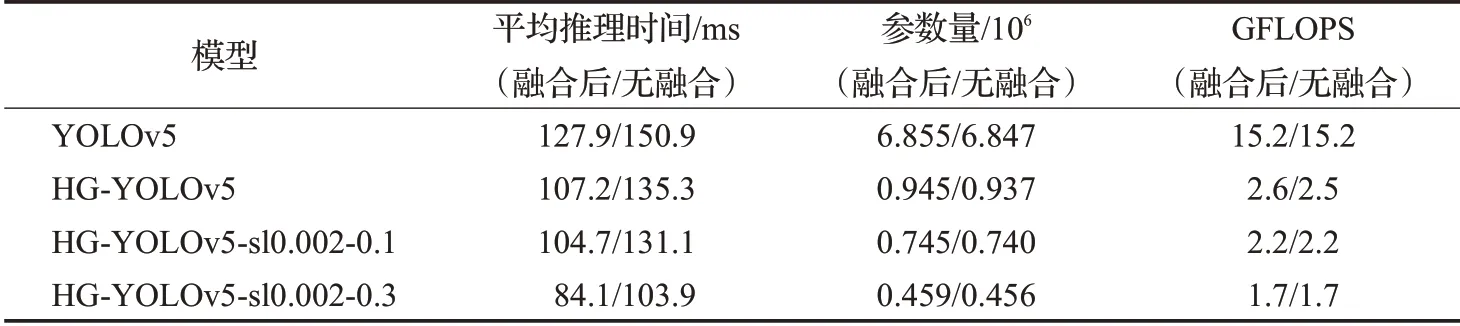
表2 网络融合后的指标对比Table 2 Comparison of indicators after network fuse
3.4 对比实验
实验将选择Mobile SSDLite、Mobile YOLOv3、SSD、YOLOv5、Slim-HG-YOLOv5等算法进行对比,其中Mobile SSDLite、Mobile YOLOv3都是轻量级网络,SSD是单阶段检测算法,YOLOv5是本文的特征提取所替代的原网络、Slim-HG-YOLOv5为本文算法。对比结果如表3所示。

表3 不同算法在本数据集上的对比Table 3 Comparison of different algorithms on dataset
从表3可以得出,Slim-HG-YOLOv5虽然在GFLOPS上不如Mobile SSDLite,且mAP方面略逊YOLOv5,但相比Mobile SSDLite,本文算法在mAP方面比其提高52.6个百分点,同时在评估网络轻量级的指标方面,如参数量、GFLOPS和权重大小分别是YOLOv5的9.2倍、6.9倍和7.63倍。在推理速度上,本文算法要比SSD快8.6倍,更好地满足实时检测的需求,可以应用在安全帽检测中。具体的检测对比结果如图8所示,图8(a)为YOLOv5检测结果,图8(b)为本文算法检测结果。可以看出,本文算法因为经过稀疏训练从而得到更好的泛化能力,YOLOv5上出现的误检测,在本文的检测结果中并没出现。而本文算法为了追求更好的轻量化,对模型进行剪枝,虽然在小目标的检测方面出现一些漏检情况,但在中大目标的检测方面仍满足良好性能。

图8 检测对比结果Fig.8 Comparison results
4 结束语
针对实际安全帽检测环境中,所部署的移动端或嵌入式设备无法为大型网络模型提供足够算力的问题。本文提出了一种基于HourGlass模块的轻量目标检测算法HG-YOLO,用于更好地将算法部署在低端设备。该模型将YOLOv5的特征提取网络替换为HourGlass,并且在保证精度的情况下对模型进行适当地压缩,通过通道剪枝的方法降低模型的参数量、浮点数和权重文件大小。其次实际中部署可能会在CPU上进行数据处理,因此为加快在CPU上的推理时间,本文在推理时将网络的卷积层和BN层进行融合,大幅减低推理时间。在对比实验中,本文的算法和其他算法相比具有一定优势,推理速度是所有算法中最快的,并且还有较好的精度。在后续研究中可以将算法部署在实际的移动端和硬件平台,进一步提高算法在CPU上的推理速度。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
自动化学报(2017年7期)2017-04-18 13:41:02
天津诗人(2017年2期)2017-03-16 03:09:39
计算机工程(2014年6期)2014-02-28 01:26:33
