
BESIII实验软件事例级并行化研究
2021-10-28 06:01马震太张晓梅孙功星
计算机工程与应用 2021年20期
马震太,张晓梅,孙功星
1.中国科学院 高能物理研究所,北京 100049
2.中国科学院大学,北京 100049
近年来随着高能物理作业所需资源的不断增长,通过不断增加时钟频率和分配更多物理机的时代将趋于终结,未来硬件的特点是更专业和更多的内核,尤其是异构资源,为充分利用多核的潜力,并行技术在高能物理领域势必得到广泛的应用。
并行计算以充分发挥硬件的计算能力为首要目标,具体实现时需结合体系结构选择相应的解决方案,常见的并行方法有:(1)区域分解法,把原问题的求解转化为若干子问题的求解。(2)功能分解法,将由不同功能组成的问题,按照其功能进行分解,并行求解。(3)流水线技术,常用的时间并行技术。(4)分而治之,把复杂问题划分为等价的小问题。按处理器处理数据的方式,又分为:(1)同步并行,在某一刻需要与其他处理器进行数据交换,才能继续执行。(2)异步并行,不需要处理器之间相互等待,充分发挥CPU效率[1]。
国内外常见的并行编程模型主要有以下几类:(1)共享内存模型,如OpenMP[2]、pthreads[3];(2)消息传递模型,MPI[4]、虚拟并行机[5];(3)数据并行模型,CUDA[6]、OpenCL[7]、MapReduce[8];(4)混合模型,如MPI+OpenMP模型[9]、MPI+CUDA模型[10]、大规模并行编程模型[11];(5)基于共享存储的任务并行编程模型,如fork-join框架、Cilk++、TPL[12]、TBB[13]。
北京谱仪(BESIII)是北京正负电子对撞机上的大型通用谱仪,BESIII离线软件是一个相当复杂的系统,包含了离线数据处理框架,模拟、重建、刻度等算法模块,使用了大量的外部库,涉及到多种编程语言;需要处理PB级别的数据量,所以并行方案的改善已迫在眉睫。
本文对BESIII实验软件的并行化展开研究,首先分析了作业级并行和序列级并行的弊端,从而得到内存消耗严重和性能损失的根本原因,并由此提出了事例级并行的解决方案,主要创新点表现在:
(1)设立全局缓冲区,提出了事例组的定义,采用分而治之的并行方法,揭示了数据粒度是制约并行计算性能的主要因素。
(2)设计了事例级并行的框架,核心思想是:采用最佳粒度,在保证并行度的同时,减少通信次数和通信量,从而使性能加速比接近线性。框架中的关键技术有信号量交互机制、映射表机制、信号的发射与接收、延迟加载技术、三层映射表。
(3)结合实验数据,分析事例级并行相较于作业级并行和序列级并行的性能优势。
按操作系统切换上下文环境的方式,作业级并行和序列级并行皆属于进程级并行;而事例级并行则属于线程级并行。从处理器处理数据的方式,作业级并行和序列级并行属于同步并行,事例级并行属于异步并行。从编程模型的角度,序列级并行和事例级并行虽然都选用了任务并行编程模型,但序列级并行采用fork-join框架,而事例级并行则选用TBB。
1 高能物理传统并行化方案
高能物理作业通常为批处理作业,这些作业在指定的数据集合上,运行特定的物理计算过程,最终产生科学家们需要的数据结果;包括模拟、重建、刻度、分析等过程,数据文件相互独立,每个文件包含若干个事例,各个事例数据之间相互独立。作业的执行过程依次为:读取待处理数据,创建并初始化消息服务、作业配置服务、其他必须服务,启动作业配置选项的顶级算法,事例处理循环,停止相关算法和服务,析构并释放资源,作业结束;在初始化阶段,应用软件会将大量的库文件、通用配置文件、几何数据装入内存[14]。根据库文件和几何数据是否被各个进程所共享,高能物理传统并行化方案可分为作业级并行和序列级并行。
高能物理作业级并行,对每个作业创建一个处理进程,各个作业进程之间相互独立;每个作业进程初始化阶段都会向内存中读入大量的库文件和几何数据,导致内存消耗严重;各个作业请求的资源直到作业结束阶段才释放,致使资源闲置,无法高效利用;输出文件由各个作业单独负责,得不到统一的管理。作业级并行示意图如图1所示。

图1 作业级并行原理Fig.1 Principle of job level parallel
如图2所示,为避免作业级并行时库文件和几何数据无法共享所带来的内存浪费问题,序列级并行采用了fork-join框架:父进程将库文件、几何数据、通用文件装入内存,根据用户指定的参数调用fork系统启动多个子进程;将多个文件对应的大量事例数据集合,分解成若干事例子集;每个事例子集对应一个子进程,每个子进程在事例循环结束后生成对应的临时数据文件;父进程将所有的临时文件排序,形成输出文件。
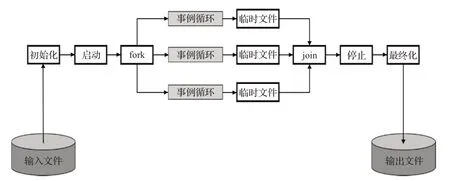
图2 序列级并行原理Fig.2 Principle of sequence level parallel
序列级并行有助于节约内存,但文件合并阶段需要排序工作,资源得不到高效配置;由于临时数据文件存储在磁盘中,属于外部排序。因临时数据文件中的事例数据已经是非递减有序的,所以外部排序算法采用选择树进行多路合并[15]:假设事例总数为m,共存储在n个临时文件中,查看每个临时文件的第一个事例,将这n个首位事例作为n个终端节点构造二叉树,自下而上选择次序小的事例,树的根部即为次序最小的事例,将这个事例写到输出文件;接着将树中相应的事例替换为该临时数据文件的下一个事例,重复选择过程,直到所有事例全部输出到结果数据;每次选择需要lgn次比较,故时间复杂度为O(mlgn)。因每个事例开始执行时需读取磁盘1次,执行结束写至临时文件需要写磁盘1次,合并过程需要从磁盘读取临时文件1次,生成最终文件需写磁盘1次;整个过程m个事例共需要I/O操作4m次。图3展示了两级选择树进行四路合并的样例,即n=4,m=16 000,共需要32 000次比较操作,64 000次I/O操作。

图3 两级选择树进行四路合并Fig.3 Two level selection tree for merge
2 事例级并行框架设计
为了提高并行度,需要将一个错综复杂的大任务拆分成大量可以并行执行的子任务,由于各个事例数据之间相互独立,故这些子任务的并行类型为数据并行;作业级并行选择以单个文件全体事例组成的数据流作为基本单元,序列级并行选择以区间有序但全部事例失序的子数据流作为基本单元,这两者都不能对内存进行统一高效的管理;为解决这一难题,需要重新选择数据并行的粒度。如果以单个事例作为基本处理单元,便可以产生数量最多的子任务,取得最高的线程并行度,但同时也会产生最高的线程交互开销;一个好的粒度应该在子任务并行带来的性能提升与线程交互的性能开销中取得最佳平衡点。因此本文提出了事例组的概念,将特定数目连续有序的事例视为一个事例组,选取事例组作为数据并行的基本逻辑单元;将若干连续且按原始顺序流动的事例组视为队列;故而在内存中创建全局缓冲区,用于缓存事例数据,缓冲区将事例数据从输入文件读入,在数据处理完成后按输入顺序写到输出文件中。
考虑到线程并行共享堆内存,可大幅降低内存消耗,同时共享资源可以得到高效管理,故基于事例组创建的各个子任务均采用线程实现,这些线程被称为事例循环处理线程,线程启动后会统一提交到TBB并行执行。之所以选择任务并行编程模型TBB,是因为TBB从逻辑任务而非物理线程的角度指定线程功能[16],不用考虑线程的细节问题;只需从库中选择高效并行的算法模板,即可得益于处理器高效的多路执行而获得性能提升[2,5]。
根据上述思想设计的事例级并行框架如图4所示,由图可知,全局缓冲区中的逻辑单元可以保存任何类型的事例数据,而各个并行子任务为逻辑子任务,框架中只有文件输入服务和文件输出服务线程与具体文件数据相关,故只需创建文件输入服务和文件输出服务的子类对象并实现相关代码逻辑,本框架便可推广到其他物理实验。现本章将从事例组的定义、事例组的运转机制、如何访问事例组中的事例数据三个方面对框架展开阐述。
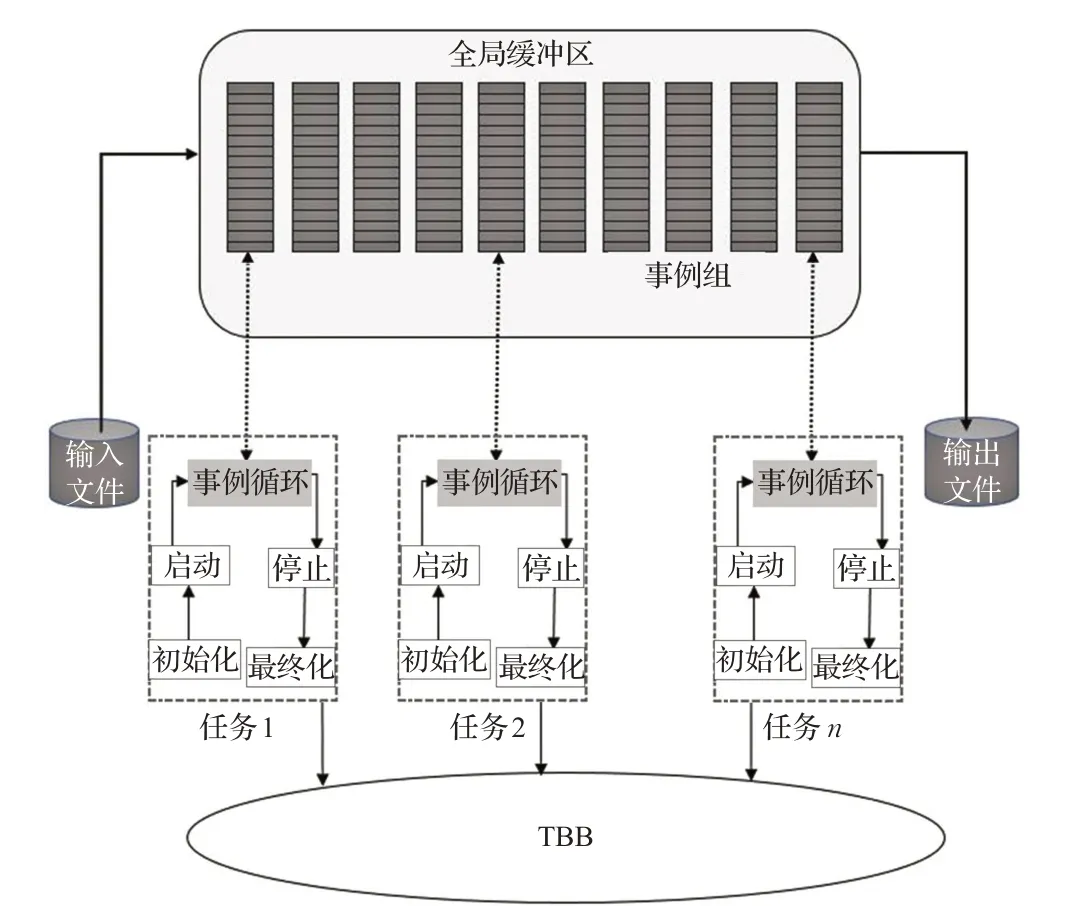
图4 事例级并行框架设计图Fig.4 Architecture of event level parallel
2.1 事例组
缓冲区中事例数据在内存中的逻辑层次自上而下为:{事例组先进先出队列、事例组、事例}。
(1)事例。由事例头和事例数据组成,事例头记录了事例大小、Run号、事例号、事例类型、探测器名,以及各个子探测器数据位置的偏移地址表;事例数据部分由各个子探测器的数据头和数据部分组成,子探测器的数据头用于记录子探测器标识、数据大小、数据状态。
(2)事例组。由特定数目事例构成的有序序列;其结构如图5所示,其中FileID字段标识文件ID,用于标记事例组所属文件上下文环境;GroupState字段标记事例组当前状态,具体状态包括:空闲、数据准备就绪、事例循环正在处理数据、数据处理完成等待输出、数据占用内存可释放、数据错误。EventCount字段记录该事例组包含的事例数目;EventProcessedCount字段用于记录已处理的事例数目;CurrentIndex字段用于记录当前正在处理的事例对应的索引位置;EventPtr[n]为一组指向若干事例数据入口地址的指针。事例组支持对应线程存取数据。

图5 事例组数据结构图Fig.5 Data structure of event group
(3)事例组先进先出队列。由若干事例组按先进先出原则构成的有序队列,队列尾端只允许插入操作,首端只允许删除操作。
由于输入文件包含的事例数目一定,故事例组数目和事例组大小成反比关系。当事例组包含的事例数目太多时,则事例组分配给事例循环线程后,需要较多的计算时间才能处理完毕,在程序运行前期,由于事例组数目较多,每个线程都能分配到自己所属的事例组,但在程序运行后期,由于事例组数目逐渐减少,只有部分线程分配到事例组,其他线程则处于闲置状态,极端的情况就是整个事例组先进先出队列只有一个事例组,此时整个程序运行期间只有一个事例循环处理线程执行全部事例的计算工作,导致CPU时间得不到充分利用,造成性能低下。当事例组包含的事例数目太少时,则事例循环处理线程只用少量时间即可完成事例组的计算量,极端情况是一个事例组只包含一个事例,这样每处理一个事例都要请求一次事例组,事例循环处理线程需要频繁请求事例组,大量的时间被浪费在事例组调度方面,事例计算时间所占比重严重下滑,同样会造成性能低下。事例的计算时间和事例组的大小,与框架性能有着紧密的关系。对于真实的BESIII实验数据处理中,由于作业的各种参数很难做出正确的预估,故对大量有代表性的作业,选用不同的事例组尺寸进行实验,得出该作业的事例组大小取值区间;将作业类型与事例组大小的取值区间录入作为训练集,建立线性模型,采用最小二乘法进行学习,取得了优良的效果。
2.2 运转机制
为了让事例组和各个工作线程正常交互,需要追踪事例组的状态并设置状态机,如图6所示,事例组的状态有:空闲、数据就绪、处理中、处理完成。文件输入线程在初始化文件上下文环境后,向全局缓冲区请求分配处于空闲状态的事例组,将原始文件中的事例数据按序读入事例组,在数据输入完成后置事例组为数据就绪状态;各个事例循环处理线程向全局缓冲区申请分配数据就绪状态的事例组,分配成功后置事例组状态为处理中,在事例组中的全部事例处理完成后,置事例组状态为处理完成;文件输出线程按事例组的输入顺序,依次将处理完成状态事例组的数据写到磁盘文件后,重置事例组为空闲状态。
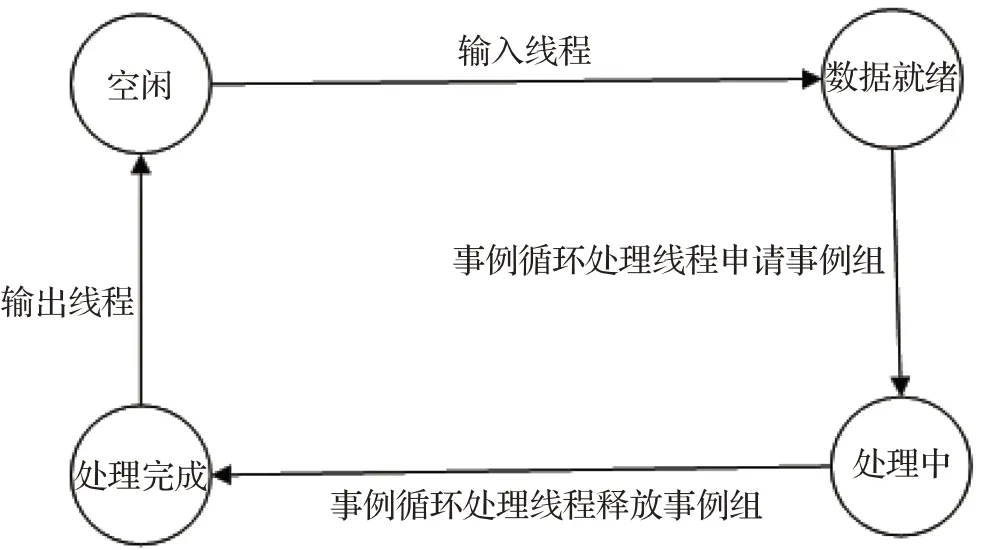
图6 事例组状态机Fig.6 State machine of event group
为同步处于不同状态事例组的数目,本文设计了三个信号量:记录处于空闲状态事例组数目的信号量EmptyStateSemaphore,记录处于数据就绪状态事例组数目的信号量ReadyStateSemaphore,记录处于处理完成状态事例组数目的信号量ProcessedStateSemaphore。图7中的P、V操作[17]为信号量操作原语:(1)P操作,当该信号量大于零时,将信号量减一,否则调用P操作的线程等待,直至该信号量大于零;(2)V操作,将对应信号量加一。信号量变化过程详述如下:

图7 事例组信号量变化图Fig.7 Semaphore variation diagram of event group
(1)文件输入线程对EmptyStateSemaphore执行P操作以检查是否存在空闲状态的事例组:如存在则读入新的事例数据,事例读入结束后,转换状态{空闲→数据就绪},然后对ReadyStateSemaphore执行V操作;否则等待。
(2)每个事例循环处理线程都会向全局缓冲区发出请求,缓冲区查询映射表:若为新的线程,对ReadyState-Semaphore执行P操作,将分配的事例组转换状态{数据就绪→处理中},并更新映射表和文件上下文;若为映射表中已存在的线程,则返回对应事例组中下个事例。
(3)当事例组中的事例全部处理完成,则将该事例组转换状态{处理中→处理完成},对ProcessedState-Semaphore执行V操作;然后寻找新的事例组,并检查文件上下文根据需要进行更新。由于所有事例循环处理线程对事例组的竞争全部集中在{数据就绪→处理中}这一状态转换,选择事例组为粒度显著降低了加锁的开销。
(4)文件输出线程对ProcessedStateSemaphore执行P操作,将状态为处理完成的事例组输出到磁盘,转换状态{处理完成→空闲},对EmptyStateSemaphore执行V操作。
状态机和信号量的设置,保证了事例数据自始至终按原序存储,不再发生任何变更,避免了复杂的合并排序工作;由于文件输入输出线程以事例组为单位与磁盘交互,假设一个事例组包含1 000个事例,则与图3相比,不需要比较操作,只需32次I/O操作;与序列级并行相比,I/O性能有了质的飞跃。
2.3 数据访问
至此,本文确定了事例组的运转机制,现在只需将不同的事例组以特定模式分派到处理器上,即可支持各个事例循环处理线程访问事例数据;事例组的调度策略由TBB负责执行,采用宽度优先和深度优相结合的方法:宽度优先用于提高并行度,保持CPU繁忙,深度优先则促使线程高效执行。为了按特定事例组中的原始顺序访问事例数据,需建立两张映射表,一张为每个事例循环处理线程与对应事例组的映射表,用于分配事例数据;另一张为每个事例循环处理线程与对应文件上下文环境的映射表,用于更新文件上下文环境。
每个事例循环线程请求事例数据的流程如图8所示,全局缓冲区首先查询线程与事例组映射表:
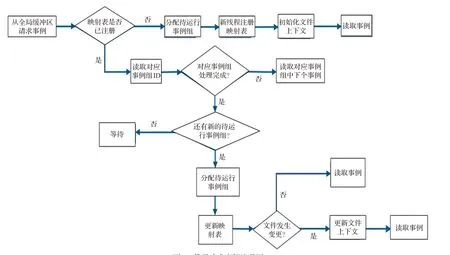
图8 线程请求事例流程图Fig.8 Flow chart of requesting event
(1)如果为新的线程,则获取处于数据就绪状态的事例组分配给线程,更新映射表,设置事例组状态为处理中,根据事例组FileID字段初始化文件上下文环境,读取事例数据开始处理。
(2)如果映射表已经存在该线程的记录,则获得对应事例组,判断当前事例组是否已经处理完成,若尚未处理完成的话,直接获取下个事例。
(3)如果事例组的事例数据已经全部处理完成,则更新事例组的状态为处理完成;向全局缓冲区请求新的事例组,如果当前没有处于数据就绪状态的事例组,则线程进入阻塞状态,直到有数据就绪状态的事例组出现。
(4)如果全局缓冲区中存在数据就绪状态的事例组,则更新映射表,并设置该事例组状态为处理中,检测事例组FileID字段与线程的文件上下文环境是否一致。
(5)如果文件发生变更,则调用文件只读服务更新文件上下文环境。
3 文件I/O
作业级并行和序列级并行这两种方案的事例处理过程皆是一个循环的过程,作业级并行每个作业的循环次数取决于作业输入文件所包含的事例数目,序列级并行每个进程的循环次数取决于对应的事例子集所包含的事例数;该循环过程分为三个阶段:事例读取、事例数据处理、事例存储;这种循环机制既导致I/O操作频繁,又容易产生大量内存碎片。事例级并行由于全局缓冲区和信号量机制的支持,使得文件输入线程、文件输出线程、事例处理线程可以并行工作,彻底消除了循环机制所带来的弊端,本章对事例级并行的文件I/O具体技术展开详述。
BESIII实验软件数据文件自顶向下分为四层结构:目录、树、分枝、叶子,但大多数情况下,用户只需访问其中的部分数据。为避免读入大量的无效数据,采用了延迟加载技术,如图9所示,只将数据指针读入内存,仅当事例处理线程访问相应数据时,才会请求文件只读服务,通过事例对象指针,获取线程对应的分支管理器,进而调用分枝搜索算法在线程本地已知树列表中查找所需树的指针,最终将磁盘数据读入内存;延迟加载的应用,显著提高了内存利用率。实验软件还提供了分枝选择服务,用于筛选用户感兴趣的事例数据,进一步减少冗余的读写操作,提升I/O性能。

图9 事例级并行数据服务图Fig.9 Data service diagram of event level parallel
原始数据一般以字节流形式存储于文件中,由文件输入服务线程将字节流数据读入到内存,内存中的字节流形成一个完整逻辑事例单元;字节流解包服务可以很方便地获得各部分数据,文件输出服务线程则按顺序将逻辑事例单元写入到指定的字节流文件中[18]。如图10所示,在数据存储管理器初始化后,当每个事例循环执行时,向信号管理器发送“事例开始”信号,信号管理器通过信号句柄请求事例,进而访问全局缓冲区获得下个事例。每个事例循环处理线程都会设置一个监视器,用于控制事例执行过程中的各个步骤,以便在事例发生错误和异常时及时做出响应,避免造成硬件资源的浪费。
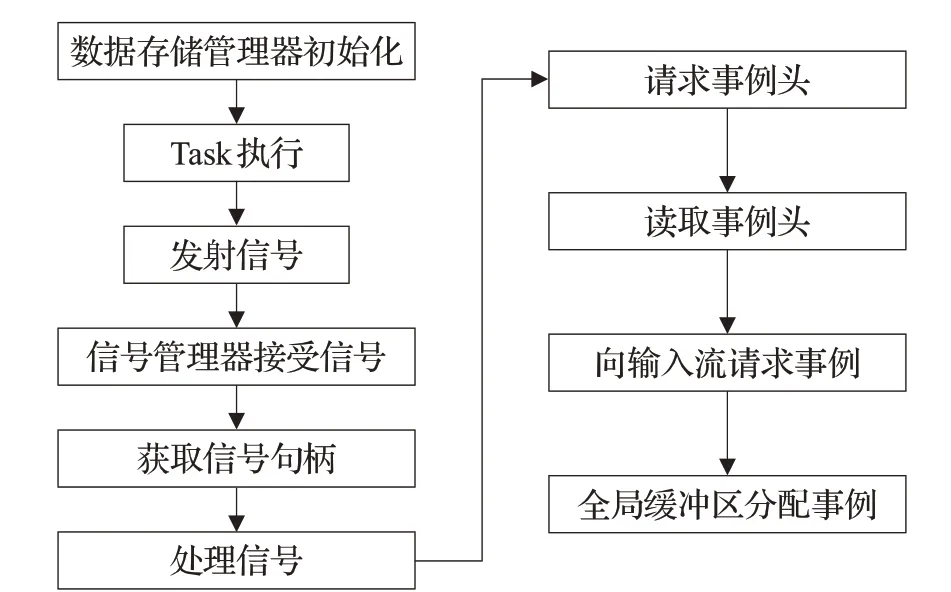
图10 事例级并行事例获取流程图Fig.10 Flow chart of distributing event data
元组输出为分析作业独有的输出方式;针对事例级并行的元组输出,本文建立了三层映射:在作业脚本配置时,由用户设置第一层映射,“逻辑文件名”→“物理文件路径”;在并行缓冲区合并服务初始化阶段建立第二层映射,“逻辑文件名”→“缓存合并管理器(TBuffer-Merger)”;在用户算法初始化阶段建立第三层映射,“<线程ID,逻辑文件名>”→“临时缓存”、“数据树”→“临时缓存”。在线程处理事例循环时,线程只需填充对应的树。最终化阶段,根据线程ID和逻辑文件名,查询映射表,获取对应的临时缓存,将数据文件输出到磁盘;原理如图11所示。
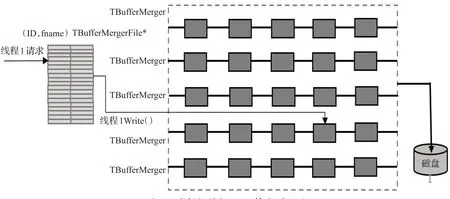
图11 事例级并行Tuple输出原理图Fig.11 Tuple output principle of event level parallel
4 实验结果
目前BESIII软件依赖的外部库皆为串行版本,并行版本算法库的开发工作尚需较多的人力物力才能完成,为预测事例级并行方案在BESIII中的性能趋势,本实验将真实BESIII实验数据处理中比较耗时的热点过程相关代码移植为并行版本,进行测试,从而更准确地预测事例级并行的优势所在。为了实验数据更加精确,实验数据取50轮测试数据的平均值,本文实验环境详见表1。

表1 实验环境Table 1 Experimental environment

图13 PMT信号处理过程性能对比Fig.13 Performance contrast of PMT signal processing
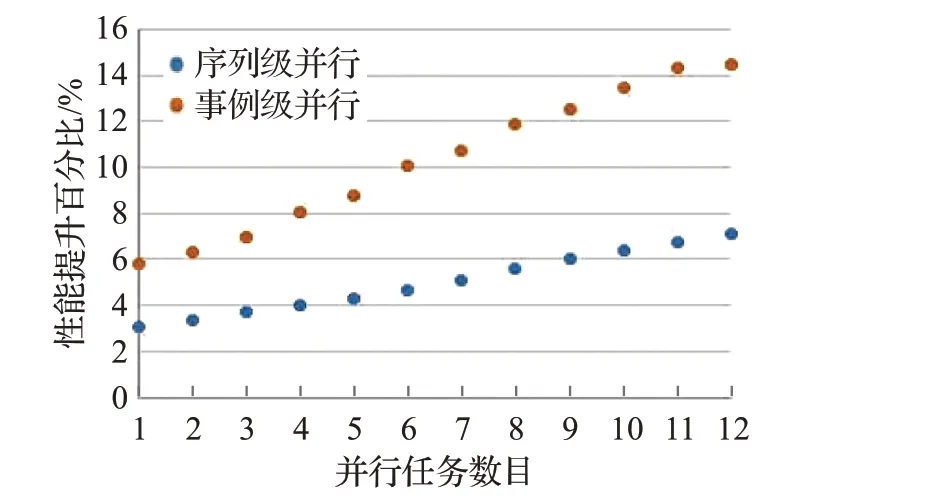
图14 点搜索过程性能对比Fig.14 Performance contrast of locating point
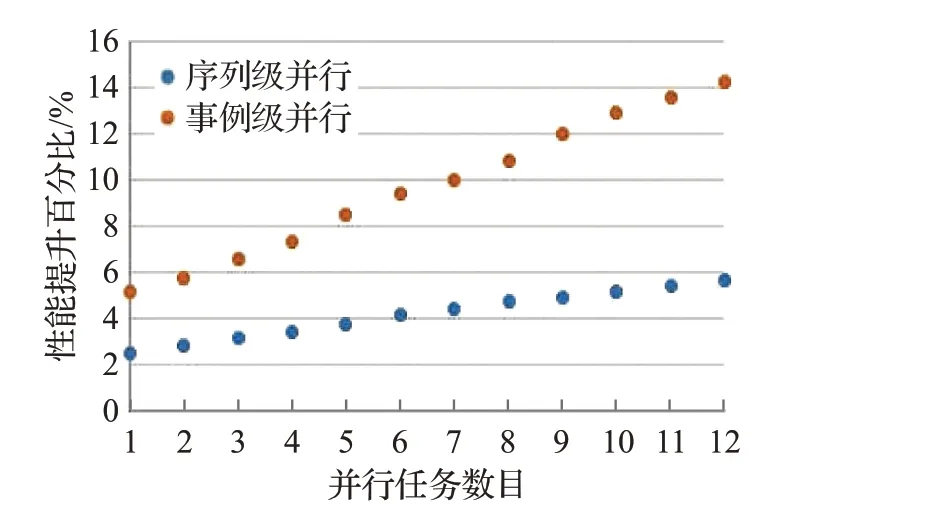
图15 截面计算过程性能对比Fig.15 Performance contrast of calculating cross sections
BESIII事例类型包括模拟、重建、物理分析,模拟用于研究高能物理实验中各种随机物理过程,以及物理量的统计分布,全面地反映相关物理量的统计性质。模拟作业热点过程的实验数据如图12~17所示,相较于作业级并行,随机数生成过程的序列级并行性能提升1.6%~5.3%,事例级并行性能提升4.6%~13.9%;PMT信号处理过程的序列级并行性能提升2.5%~6.6%,事例级并行性能提升5.1%~15.4%;点搜索过程的序列级并行性能提升3%~7.2%,事例级并行性能提升5.8%~14.5%;截面计算过程的序列级并行性能提升2.5%~5.7%,事例级并行性能提升5.2%~14.2%;Hit算法的序列级并行性能提升1.1%~4.1%,事例级并行性能提升3.7%~12%;体素查找过程的序列级并行性能提升2.3%~4.1%,事例级并行性能提升3.2%~9.6%。
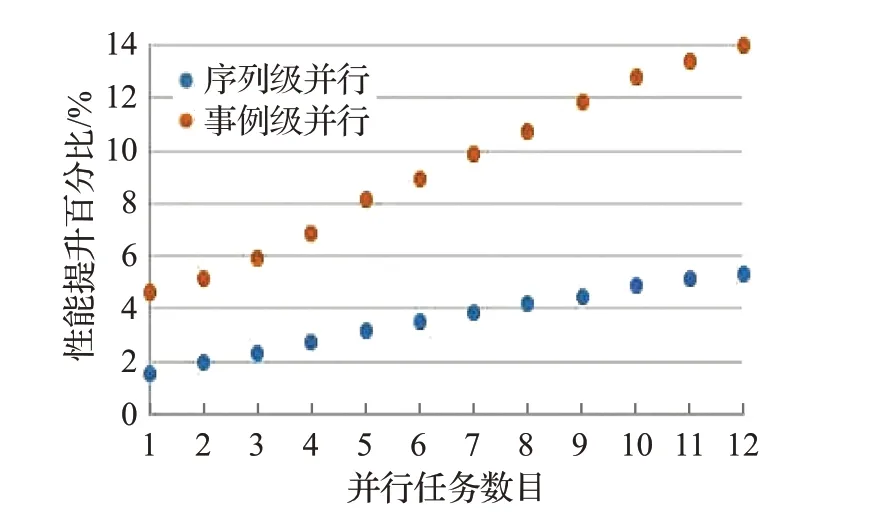
图12 随机数生成过程性能对比Fig.12 Performance contrast of random number generation
事例重建是利用相应的刻度常数对原始数据进行修正,将原始数据中的数字信号还原为粒子的位置、能量、动量等物理量,最终形成重建数据交给物理分析人员。重建作业热点过程如图18~21所示,相较于作业级并行,磁场求解过程的序列级并行性能提升2.1%~4%,事例级并行性能提升2.6%~7.9%;高能物理热点矢量混合运算的序列级并行性能提升1.8%~5.4%,事例级并行性能提升2.9%~11.8%;轨迹追踪算法的事例级并行性能提升1.3%~2.9%,事例级并行性能提升1.5%~5.2%;路径求解算法的序列级并行性能提升3.2%~7.6%,事例级并行性能提升3.5%~16.2%。
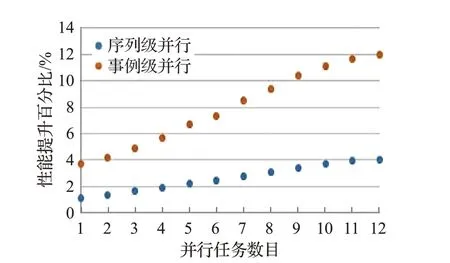
图16 Hit算法性能对比Fig.16 Performance contrast of Hit algorithm

图17 体素查找过程性能对比Fig.17 Performance contrast of locating voxel
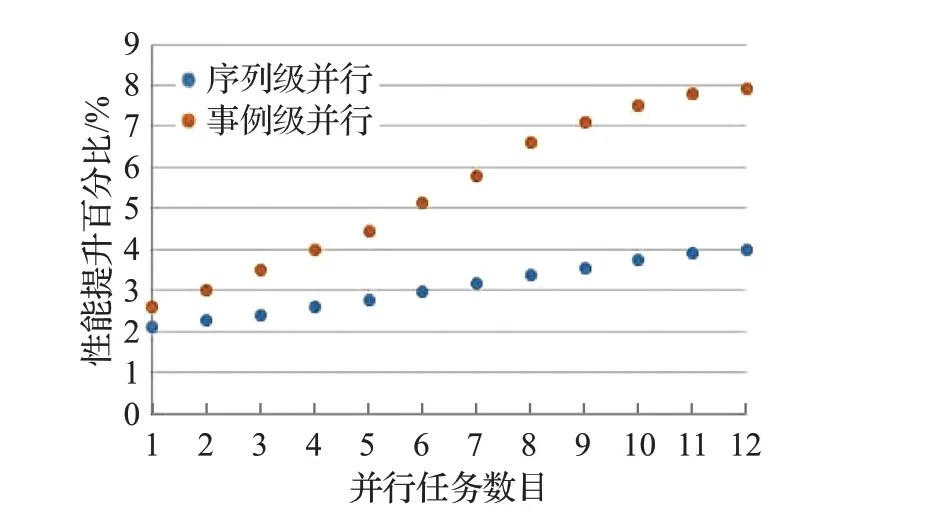
图18 磁场求解过程性能对比Fig.18 Performance contrast of magnetic field computing
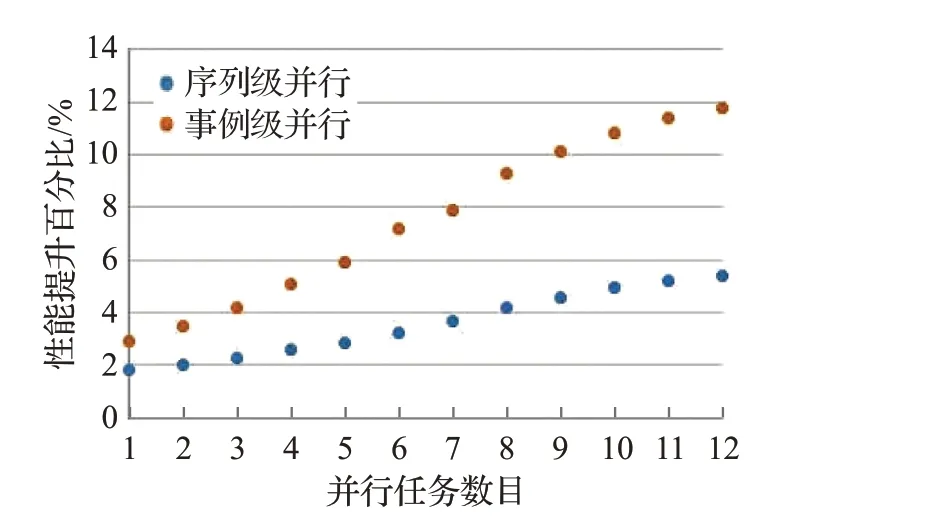
图19 高能物理热点矢量混合运算性能对比Fig.19 Performance contrast of hot vector operation
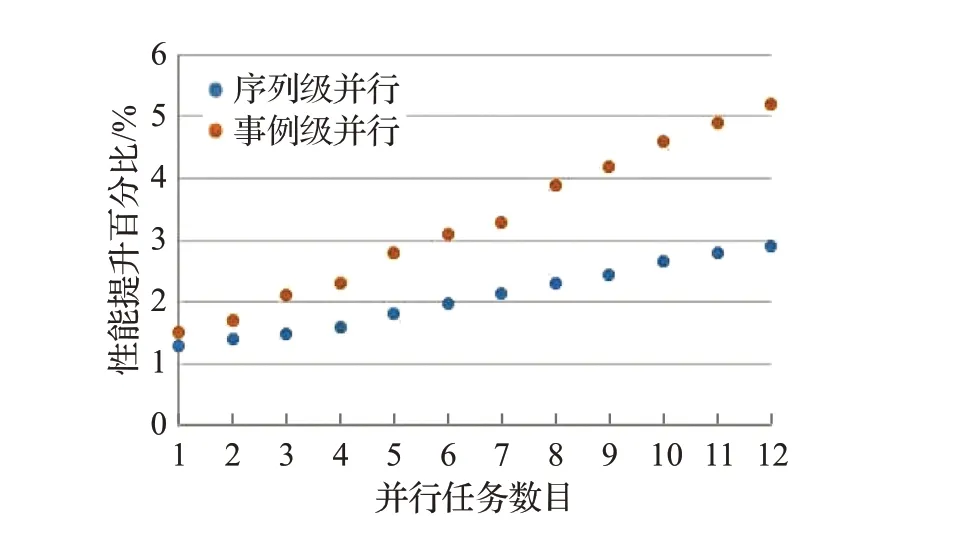
图20 轨迹追踪算法性能对比Fig.20 Performance contrast of trajectory tracking

图21 路径求解算法性能对比Fig.21 Performance contrast of calculating path
相较于作业级并行,模拟作业和重建作业热点过程的序列级并行性能提升幅度不大,这是由于序列级并行虽然消除了重复的初始化过程且减少了冗余I/O,但引入了复杂的事例排序;事例级并行方案能获得如此显著的性能提升,说明事例组运转机制是有效的。
物理分析是根据科研人员的具体需要,对不同的实验数据进行综合的计算和统计,进而获得所需的物理结果。分析作业热点过程如图22~23所示:相较于作业级并行,衰变树处理过程序列级并行性能提升4.8%~9.7%,事例级并行性能提升5.3%~19.8%;射线处理过程序列级并行性能提升2.8%~7.5%,事例级并行性能提升6.5%~26.7%。

图22 衰变树处理过程性能对比Fig.22 Performance contrast of Decay Tree
事例级并行以事例组为粒度,保证了事例数据在与输入线程、输出线程、事例处理循环线程交互时的顺序流动,消除了无效的内存浪费,最终大幅提升了分析作业的文件I/O效率;由于射线处理过程采用前文所述的三层映射,虽然有一定的内存损耗,但性能提升显著。现对上述两个过程的内存消耗进行对比测试,实验数据如图24、25所示:相较于作业级并行,衰变树过程序列级并行内存用量降低5.6%~28.7%,事例级并行内存用量降低12.9%~46.5%;射线处理过程序列级并行内存用量降低3.5%~19.6%,事例级并行内存用量降低9.2%~25.8%。

图23 射线处理过程性能对比Fig.23 Performance contrast of ray processing

图24 衰变树内存消耗量对比Fig.24 Performance contrast of Decay Tree memory consumption
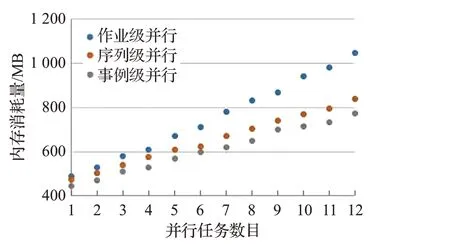
图25 射线处理过程内存消耗量对比Fig.25 Performance contrast of ray processing memory consumption
5 结束语
本文实验结果总体是令人满意的,但实验软件目前并不支持异构平台[19];而且当事例中某个算法长时间占用某类资源,事例级并行将会出现其他资源闲置的情况;在以后的实验中,将针对算法和数据的依赖关系建立有向无环图[20],将控制流信息和数据流信息集成在图中,采用关键路径和性能权重表相结合的解决方案,以期在异构平台上能充分利用硬件资源,取得理想的实验效果。
猜你喜欢
新世纪智能(高一语文)(2020年10期)2021-01-04
作文成功之路·小学版(2020年4期)2020-06-16
网络安全技术与应用(2020年1期)2020-01-07
沈阳工业大学学报(2018年1期)2018-01-08
水利规划与设计(2017年11期)2017-12-23
中国宪法年刊(2017年0期)2017-05-20
环球市场(2017年36期)2017-03-09
项目管理技术(2015年3期)2015-04-23
电视技术(2012年1期)2012-06-06
中国宪法年刊(2012年0期)2012-03-25
