
基于YOLOv5的违章建筑检测方法
2021-10-28 06:01:04于娟,罗舜
计算机工程与应用 2021年20期
于 娟,罗 舜
福州大学 经济与管理学院,福州 350108
随着我国经济的的不断发展,城市规模日益扩大,对城市管理也提出更高的要求,其中就包括违章建筑的检察。城市违章建筑是指不符合土地规划和城市管理相关法律法规,擅自改变建筑样式的建筑,例如彩钢瓦房、破旧平房等。城市违章建筑占用城市发展空间,破坏城市形象,甚至危害到人民的生命财产安全,是我国城市管理发展路程上迫切需要解决的路障。目前,我国城市管理中的违章建筑检测主要依赖效率低下的人工访查方式。随着无人机航拍科技的不断普及和深度学习方法的日益成熟[1],违章建筑的自动检测成为可能。
目前,城市违章建筑物的拍摄方式主要有两种:卫星遥感和无人机航拍。在基于卫星遥感影像的违章建筑检测方面,文献[2-3]采用多时相影像和变化检测相结合的方法对违章建筑进行监测,通过对比不同时期的图像得到区域的变化图斑,并以人工解译的方式判断变化区域,定位违章建筑。文献[4]改进形态学标记分水岭算法,强化违章建筑的提取效果,将结果与定位数据进行叠加与匹配,得出最终的检测结果。由于卫星必须在规定的轨道上行进,其拍摄范围受到约束,且其拍摄结果易受到外部条件的干扰,所以卫星遥感影像不适用于城市违章建筑的实时检测。另一方面,无人机航拍科技近几年飞速发展,具有灵活、成本低、操作简单等优点,且其影像分辨率高,能够清晰地反映建筑物的基本特征,更适用于地面小目标的检测。因此,本文采用无人机航拍图像作为数据源研究城市违章建筑的自动检测方法。
同时,深度学习方法在图像目标检测问题上表现相当出色。2012年,Krizhevsky等[5]提出了一个卷积神经网络(Convolutional Neural Networks,CNN)结构——AlexNet,使用非线性激活函数ReLu[6]与Dropout[7]方法,在减少过拟合方面取得了卓越的效果。自此,基于深度学习的图像目标检测方法研究迅速发展,目前已形成两类主要的检测流程。其中一类是基于候选区域的深层卷积网络,首先生成可能包含检测目标的候选区块,再用CNN对候选区块进行分类和位置回归并得到检测框,其代表模型有R-CNN(Region CNN)[8]、Fast R-CNN(Fast Region-Based CNN)[9]和Faster R-CNN(Faster Region-Based CNN)[10]等。另一类为基于回归计算的深层卷积网络的目标检测。这类方法将目标定位整合在单一CNN网络中,只需进行向前运算就能预测不同目标的类别与位置。第二类方法的准确度较低,但检测速度比前一类快,其标志性模型有YOLO(You Only Look Once)[11]、SSD(Single Shot MultiBox Detector)[12]和YOLOv4(YOLO Version 4)[13]等。
YOLOv5属于目前比较优秀的检测算法,学者们将它应用于不同对象的检测中,并提出不同的改进方案。对于牛日常行为的实时检测,文献[14]改进YOLOv5,构建牛特征部位的空间关系向量,对图像中的多目标和重叠目标取得较优的检测效果;文献[15]对YOLOv5网络的卷积层进行降维并使用非极大值抑制提高了喷码字符的检测精度。虽然改进后的YOLOv5在各个数据集上取得了较优的检测结果,但是不能直接运用于城市违章建筑的检测,因为违章建筑多为小目标且有许多被部分遮挡的目标,而YOLOv5的网络参数过多,使得训练时间变长,难度变大,图像的检测时间也会变长,难以同时满足检测中准确性和实时性的要求。
综上,本文提出一种基于YOLOv5卷积神经网络模型,对无人机航拍的城市建筑图像进行处理,改进YOLOv5的批量标准化模块、损失函数与网络结构,自动定位其中的违章建筑,以提高城市违章建筑检测的准确率和速度。
1 违章建筑数据集预处理
1.1 数据来源
本文研究的违章建筑图像来自无人机航拍的城镇建筑影像,尺寸为3 992像素×2 442像素,共107张。图像为白天晴天航拍,包括彩钢瓦房和其他疑似违章建筑,其中包括单目标图像、多目标图像以及违章建筑被电线杆等异物遮挡的特殊图像。图1为几种典型的违章建筑示例图。

图1 数据集中的城市违章建筑的主要类型Fig.1 Main types of urban illegal constructions in data set
1.2 数据集构建
原本的航摄图片尺寸较大,如果用原尺寸作为训练所用数据集会导致参数过多的现象,所以首先通过像素变换的方式将原来所有的航拍图片尺寸统一缩小为608像素×608像素。并且在原图的基础上对图像进行旋转变化、裁剪变换、对比度变换等,使得违章建筑图像有不同的表现形式和尺度,这样有助于避免过拟合现象的产生,从而提高训练网络的泛化能力[16]。图2为不同表现形式的预处理图片。

图2 预处理图片示意图Fig.2 Schematic diagram of preprocessing picture
通过预处理后最终得到1 000张城市违章建筑图片,模仿VOC2007数据集格式,利用LabelImg标注软件依次对这些图片中的违章建筑进行标注外围框,转化为训练所需要的xml格式[17]。LabelImg是使用Python语言编写用于深度学习的图片数据集制作的标注工具,用来标注图片中目标的类别名称与位置的信息。
1.3 数据集分析
1 000幅存在城市违章建筑的图像中,共有2 062个城市违章建筑目标,其边界框分布如图3所示,纵坐标表示标记框高度占原图高度的比例,横坐标为宽度占比。由图3可知,目标框大小具有多样性,但总体占原图像比例较小,属于小目标,背景信息较多。

图3 边界框分布图Fig.3 Boundary box distribution
2 YOLOv5目标检测算法及改进
2.1 YOLOv5算法概述
Ultralytics LLC公司提出的YOLOv5(You Only Look Once version 5),为基于YOLOv4的改进版本,是目前从准确性以及检测速度效果来说比较优秀的单阶段(one-stage)检测网络[18]。在吸取了之前版本以及其他网络的优点之后,YOLOv5改变了之前YOLO目标检测算法的检测速度较快但精度不高的特点,YOLOv5目标检测算法在检测准确度以及实时性上都有所提高,满足视频图像实时检测需求,同时结构也更加小巧,其网络模型分为4个部分,分别为Input(输入端)、Backbone(骨干网络)、Neck(多尺度特征融合模块)和Prediction(预测端),其网络结构如图4[19]所示。
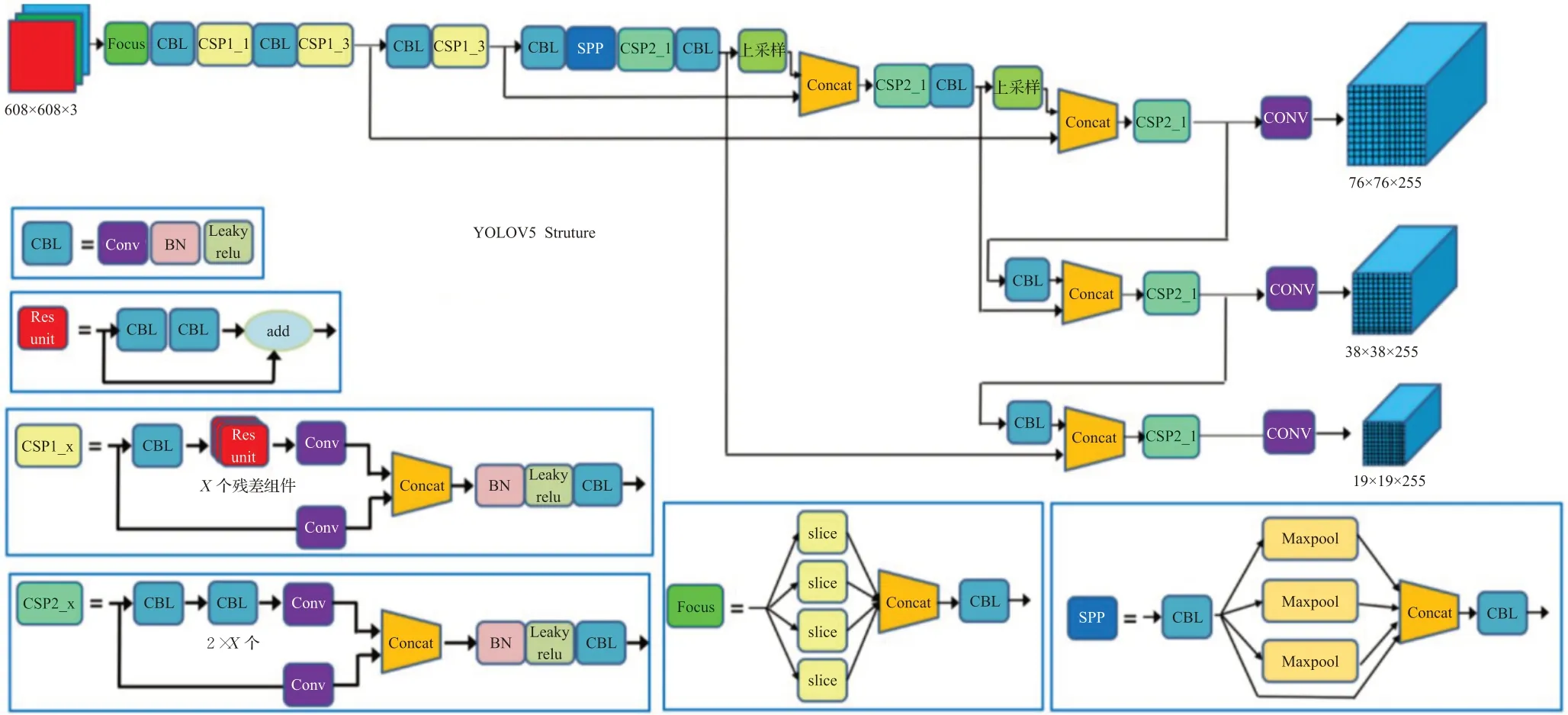
图4 YOLOv5网络结构示意图Fig.4 Network structure diagram of YOLOv5
2.1.1 Input端
Input端包含Mosaic数据增强、自适应锚框计算和自适应图片缩放三个部分。YOLOv5的输入端采用了和YOLOv4一样的Mosaic数据增强的方式,使用随机裁剪、随机缩放和随机分布的方式对图像进行拼接,将4张图片拼接,丰富了检测数据集,让网络的鲁棒性更好,并且减少了GPU的计算,增加了网络的普遍适用性;自适应锚框计算针对不同的数据集设定初始的锚框,因原锚框已达到较好效果,本文实验的锚框参数不变,锚框参数分别为[116,90,156,198,373,326]、[30,61,62,45,59,119]、[10,13,16,30,33,23],并在初始锚框的基础上输出预测框,与真实框进行比对,计算差距后再反向更新,不断迭代网络参数,其过程如图5所示;自适应图片缩放则是将图像统一缩放成统一尺寸。
2.1.2 Backbone
Backbone包括Focus结构和CSPNET(Cross Stage Partial Network,跨级部分网络)结构。Focus将输入的608×608×3的图像进行切片操作,得到304×304×12的特征图,然后再经过32个卷积核的卷积后得到304×304×32的特征图,其过程如图6所示。

图6 Focus结构中切片和卷积得到的特征图Fig.6 Feature maps obtained by slicing and convolution in focus structure
YOLOv5借鉴YOLOv4主干网络中的CSP结构,设计了CSP1_X和CSP2_X两种CSP结构,2者结构如图4中所示,其中Backbone中包含CSP1_X模块,Neck中包含CSP2_X模块。
2.1.3 Neck
Neck使用FPN(Feature Pyramid Networks,特征金字塔网络)+PAN(Pyramid Attention Network,金字塔注意力网络)结构,其结构如图7所示,FPN自顶向下将高层的特征信息通过上采样的方式进行传递融合,传达强语义特征,PAN为自底向上的特征金字塔,传达强定位特征,两者同时使用加强网络特征融合能力。
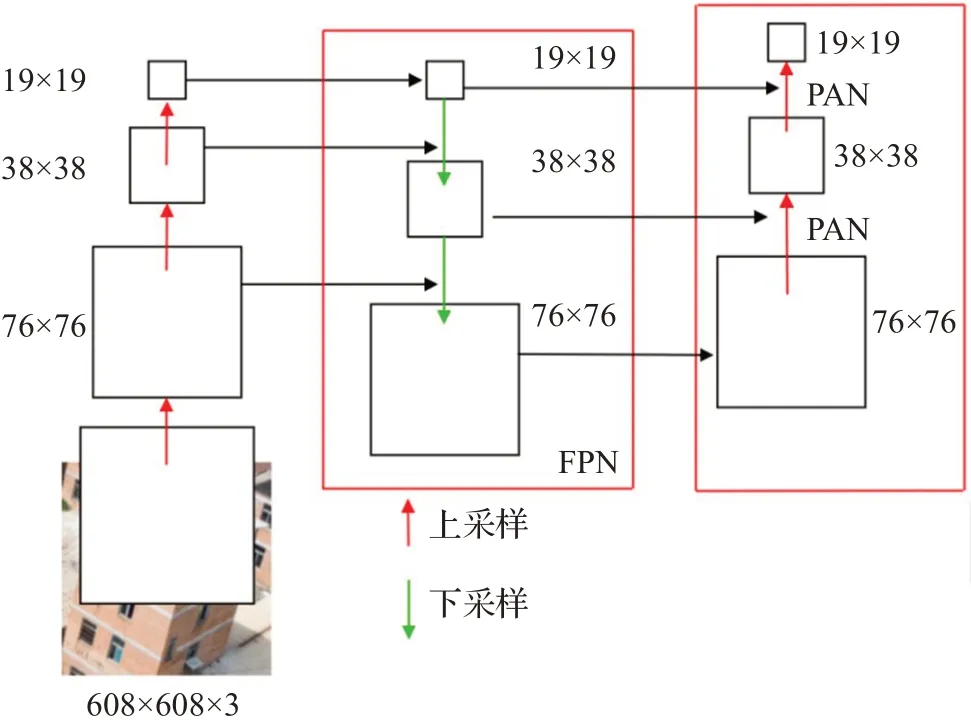
图7 Neck结构示意图Fig.7 Neck structure diagram
2.1.4 Prediction
Prediction包括Bounding box损失函数和NMS(Non-Maximum Suppression,非极大值抑制)。YOLOv5使用GIOU_Loss作为Bounding box的损失函数,有效解决边界框不重合的问题,并且提高了预测框回归的速度和精度。在目标检测预测阶段使用加权NMS,对于多目标和有遮挡的目标增强了识别能力,获得最优目标检测框。
2.2 YOLOv5算法改进
2.2.1 批量标准化改进
批量标准化(Batch Normalization,BN)已成为现代神经网络稳定训练的默认组件,在BN中,中心化和缩放操作以及均值和方差统计用于批量维度上的特征标准化。BN的批依赖性使得网络具有稳定的训练和更好的表示,同时不可避免地忽略了实例之间的表示差异。为了对BN进行特征校正,借鉴代表性批量标准化的思想,将原来的BN模块进行改进,在BN的原始标准化层的开始和结束处分别添加了中心和缩放校准[20]。首先对特征进行中心校准,如式(1)所示:

式中,X cm为中心校准后的特征图,X为输入的特征图,满足X∈RN×C×H×W(N、C、H、W分别表示批量大小batch size、通道数channel、输入特征图高度和输入特征图宽度);w m为可学习的权重向量,满足w m∈R1×C×1×1,其数值随网络层数的变化如图8(a)中所示,大多数层中的数值接近于0,并且其绝对值随着层数的增加而增加,因为层数越高网络就具有更多特定于实例的特征;⊙是点积运算器,它将两个特征传播成同一形状,然后进行点积运算。为了更好地展示其效果,对网络中的特征图进行提取,其结果如图9所示,可以看出最右边经过中心校准后的特征图比中间输入的特征图的特征分布更加显著。

图8 可学习权重变量折线图Fig.8 Line chart of learnable weight variables

图9 中心校准效果图Fig.9 Centering calibration renderings
再对X cm进行中心化:

式中,E(X cm)表示X cm的均值。再对中心化后得到的X m进行缩放,得到式(3):

式中,Var(X cm)表示X cm的方差,ε为避免方差为0而设置的大于0的常数。接着在原本的缩放操作上,再添加缩放校准操作:
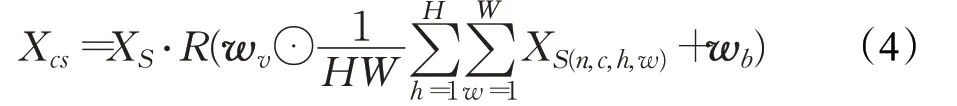
式中,w v,w b∈R1×C×1×1为可学习的权重向量,如图8(b)中所示,与w m类似,大多数层中趋近于0且其绝对值随着层数的增加而增加,R()为受限函数,可以定义为多种形式,这里将它定义为tanh函数,Xcs为缩放校准后得到的值,其效果和图9相似。最后如式(5)所示,将训练好的可学习尺度因子γ和偏差因子β作线性变换得到最终的代表性批量标准化结果Y:

通过在BN的原始标准化层的开始和结束处分别添加了中心和缩放校准,增强有效特征并形成更稳定的特征分布,加强了网络模型的特征提取能力。
2.2.2 损失函数改进
YOLOv5算法对于目标框坐标回归过程中采用的是均方误差(Mean Square Error,MSE),使用交叉熵作为置信度和类别的损失函数。但MSE作为目标框损失函数,其损失值对目标框较为敏感,为了进一步提高收敛稳定性,本文在对置信度设计损失函数时将交叉熵损失替换为基于KL散度的分布损失函数。KL散度也被称为相对熵[21],对于同一个连续变量的2个概率分布p和Q而言,KL散度的定义式为:

本文使用̂表示模型对n个输入样本的坐标预测概率分布和真实标签分布之间的KL散度最小化的参数变化过程,表达式如式(7)所示:
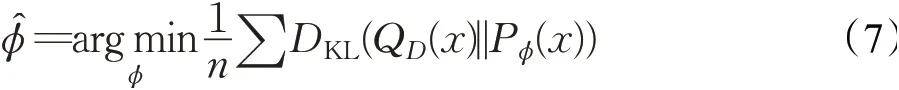
式中,Q D(x)表示真实标签坐标概率分布,Pϕ(x)表示预测坐标概率分布,定义Q D(x)和Pϕ(x)均为高斯分布函数。真实标签坐标概率分布和预测坐标概率分布越接近越好,因此将边界框回归损失函数定义如式(8)所示:

根据高斯分布函数性质推导,得到如下公式:
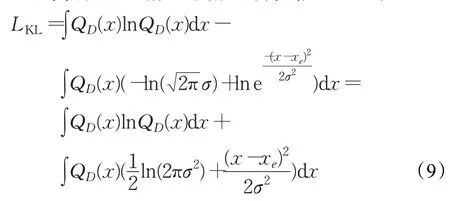
狄拉克函数的定义如式(10)所示,由于高斯分布在标准差接近0时为狄拉克函数的近似,于是将式(9)根据式(11)中的狄拉克函数的筛选性质推导,得到式(12):
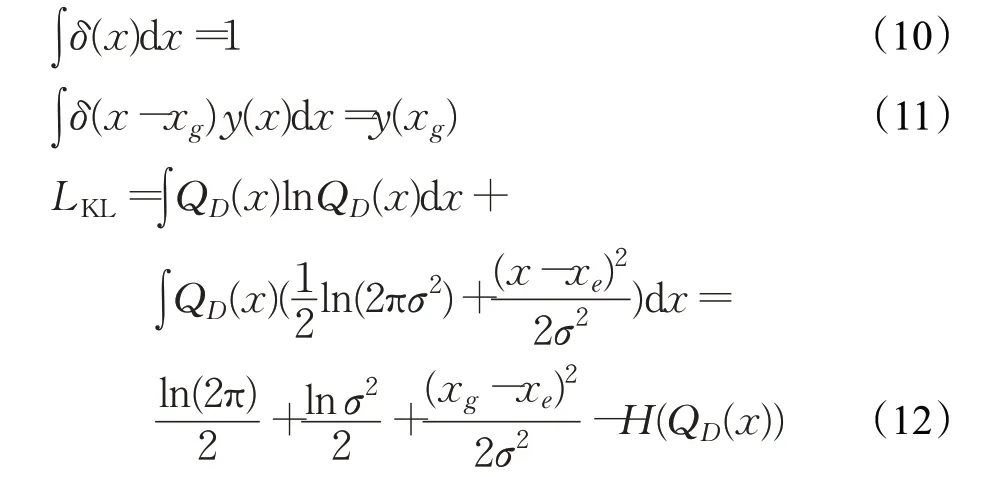
由于常数项对于求导没有影响,因此可以将不含参数的项舍去,得到如下公式:
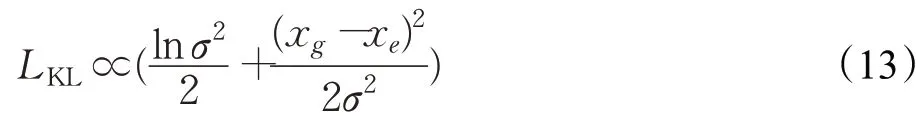
式中,σ的初始值如果较大,很容易导致网络在训练的初始阶段产生梯度爆炸现象从而导致模型无法正常收敛,且ln在数学计算中存在输入受到限制的问题,因此本文在模型训练的预测阶段令变量α和σ满足关系式(14),再将式(14)带入式(13)中,得到损失函数如式(15)所示:
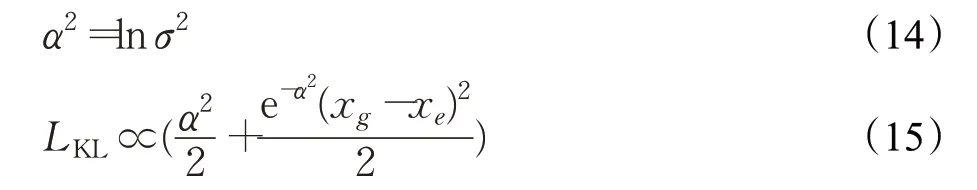
为了进一步增强模型的鲁棒性,本文将KL损失函数进行平滑化处理,当|x g-x e|>1时,得到模型边界框回归损失函数:

在模型训练过程中,经过平滑处理后的损失函数对噪声大的样本数据不会产生骤变,从而降低其在反向传播过程中受到的干扰,模型收敛也更加稳定。
2.2.3 网络结构改进
原YOLOv5中的CSPNET结构将基础层的特征层划分为两部分,然后使用跨阶段层次结构将两者合并,使得网络能够实现更丰富的梯度组合信息,然而这也更容易导致信息损失与梯度混淆。因此,本文借鉴mobileneXt网络[22]的思想,使用类沙漏状模块LSandGlass替代YOLOv5网络中的Res unit残差模块。LSandGlass模块的结构如图10所示,不同于中间具有深度空间卷积的瓶颈结构,本文将3×3深度空间卷积层Dwise移动到具有高维表示的残差路径的两端,并将YOLOv5的两个基本组件CBL置于中间。两次的深度卷积可以编码更多的空间信息,并且使得更多的梯度跨多层传播,减少了信息损失。图11展示了使用LSandGlass模块的前后比对,图11左边的两张图为未使用LSandGlass模块,连续使用6次卷积的结果,可以看出没有很好地提取出建筑的边缘特征,信息丢失严重,图11右边的两张图为使用LSandGlass改进后的特征提取结果,建筑的边缘特征信息得到了更好的提取,背景信息与特征信息也有更加明显的区别。

图10 LSandGlass模块示意图Fig.10 Schematic diagram of LSandGlass module

图11 改进前后对比Fig.11 Comparison before and after improvement
在原版YOLOv5的输入中,因为其卷积层后边的全连接层特征数固定,使得本文的输入图像的大小会固定在608像素×608像素,由此得到的特征层网络的尺寸分别是19×19、38×38、76×76。特征层尺寸越小,说明其神经元感受野越大,也就意味着语义层次更丰富,但会出现局部与细节特征丢失。与之相反,当卷积神经网络较浅,感受野变小,特征图中的神经元会偏向于局部与细节[23]。为了减少语义丢失,去除主干特征提取网络里的19×19特征层,保留其他两个特征层。这样不仅减少了语义丢失,还减少了网络的参数量。图12展示了剔除低分辨率特征层后的检测结果,可以看出右边剔除低分辨率特征层后的检测结果比剔除前更好,减少了语义丢失从而降低了漏检率。

图12 剔除前后对比Fig.12 Comparison before and after cutting
图13展示了改进后的YOLOv5网络的完整结构图,其中LSG表示LSandGlass模块,RBN表示改进后的BN模块。

图13 改进后的YOLOv5网络结构示意图Fig.13 Network structure diagram of improved YOLOv5
3 实验结果与分析
3.1 实验环境
本文采用违章建筑数据集进行训练,搭建OpenCV深度学习平台,具体测试环境:显卡为Nvidia Tesla V100,显存为16 GB,CUDA版本10.1,cuDNN版本7.6.5,编译语言为Python3.8,batch size设置为16,一共训练200个epochs。
3.2 评价标准
涉及目标检测领域,通常使用召回率(Recall)、精准率(Precision)和综合前两者的mAP(mean Average Precision)对目标检测算法性能进行评价[24]。召回率针对样本,用于描述在所有正例的样本中,有多少在预测中被检测出来,其计算公式如下:

式中,R表示召回率;TP表示算法将样本正类预测为正类的个数;FN表示将样本正类预测为负类的个数,即遗漏检测的个数;精准率针对最后的预测结果,用于描述预测出来的正例占所有正例的比率,计算公式如下:

式中,P表示精准率,FP表示将样本中负例预测为正例的个体数量,即检测错误的目标。但一般情况下召回率和精准率很难都维持在高水平,由此就需要一个参数来综合这两个参数,使用mAP值来衡量检测网络的算法性能,其适用于多标签图像分类,计算公式如下:

式中,N表示test集中的样本个数,P(k)是精准率P在同时识别k个样本时的大小,ΔR(k)表示召回率R在检测样本个数从k-1个变为k个时的变化情况,C则是多分类检测任务重类别的个数。
3.3 对比实验
首先为了验证应用基于KL散度的损失函数是否能够对网络收敛能力有所提升,在相同数据集上对改进损失函数前后的网络分别进行相同epoch数量的训练,损失曲线图如图14所示,带点曲线和不带点曲线分别表示原YOLOv5网络损失曲线和单独改进损失函数后网络的损失曲线。由图可知改进后的损失函数降低了其在反向传播过程中受到的干扰从而使得初始损失值更小,模型收敛速度也快于原网络,说明将原损失函数置信度中的交叉熵替换为基于KL散度的损失函数后提高了网络的收敛能力。

图14 改进损失前后损失曲线图Fig.14 Loss curve graph before and after improving loss
接着对改进后网络整体的收敛性进行分析,为了比较改进后的YOLOv5网络与标准YOLOv5网络,将对它们进行相同epoch数量的训练,同时,加入YOLOv4网络做多元对比。为了方便比对,将改进后的模型称为YOLOv5-Building。首先对比各模型之间损失下降的情况,图15为三种模型的loss图,横坐标为epoch个数,纵坐标为损失量,实线、虚线和点线分别代表三种不同的模型。可以看到,YOLOv5-Building的loss下降速度比YOLOv5和YOLOv4的loss下降速度更快,说明改进后的YOLOv5-Building的损失网络收敛速度更快。收敛后YOLOv5-Building的损失波动范围在0.1~0.2之间,YOLOv5在0.3~0.5之间,YOLOv4则在0.7~0.9之间,本文提出的改进模型的损失值更趋近于0且更为平滑。

图15 损失曲线对比图Fig.15 Loss curve comparison chart
另外在YOLOv4、YOLOv5和YOLOv5-Building进行对比分析的同时,结合YOLOv3和双阶段检测网络Faster RCNN的测试结果进行多元分析[25],结果如表1所示。
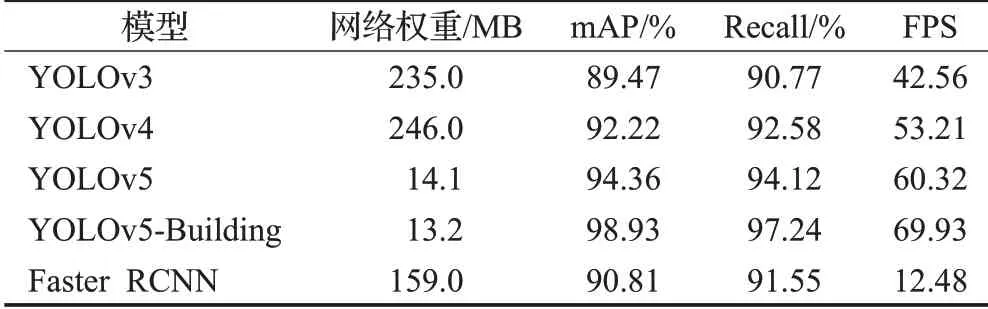
表1 综合指标测试结果Table 1 Test results of comprehensive index
表1中FPS(Frame Per Second)代表检测速度,即算法在每秒钟里能够检测图片的数量。分析表1的数据可得知,YOLOv5-Building的检测精度指标相较于原来的YOLOv5网络有所提高,mAP提高了4.57个百分点,说明YOLOv5-Building准确检测城市违章建筑的能力有所提升,并且改进后网络的检测速度也有较大提升,FPS提高了9.61。Faster RCNN采取了双阶段检测机制,二次微调了anchor区域,但其mAP较其他算法只超过了YOLOv3,但检测速度却远低于后者。从整体参数规模来看,改进后的网络代表整体参数规模的网络权重从14.1 MB减少为13.2 MB,而且远小于其他网络的权重,由此可以看出改进后的YOLOv5-Building网络在提高了检测准确性的同时提高了检测实时性,并且减少了对电脑硬件的要求,可以部署于更多环境。
进一步对本文提出的改进YOLOv5模型进行消融实验以验证各模块的有效性。对部分网络模块进行替换,其结果如表2所示,其中CUT表示剔除低分辨率特征层操作。由表中数据可知,RBN模块、LSG模块和KL散度损失函数的使用均提高了检测的精度与速度,而改进网络结构的操作提高了检测速度,但检测精度有所下降。RBN模块由于其强化了网络的特征提取能力,明显对于检测的精度与速度有较大的提升,分别提高了1.35个百分点和3.21;KL散度损失函数降低了噪声干扰,mAP提高了1.87个百分点,但对于检测速度没有明显影响;LSG模块减少了梯度下降过程中的信息损失,对于检测的精度与速度也有一定的提升;剔除低分辨率特征层的网络由于比没有剔除低分辨率特征层的网络少了一层特征层,同时减少了卷积和拼接等操作,使得网络检测速度有比较明显的提升,但也因此降低了检测的精度,由此也显示出了RBN模块、LSG模块和KL损失函数对于模型检测精度提高的必要性。

表2 消融实验测试结果Table 2 Test results of ablation
3.4 检测结果分析
改进YOLOv5网络前后的检测结果如图16所示。由于无人机拍摄角度等问题,原图中有部分图像中的目标与图16(a)、(b)最左边图像一样被遮挡。从图16(a)、(b)最左边图像的对比中可以看出,原YOLOv5对于存在遮挡目标的图像存在漏检的现象,而YOLOv5-Building在目标被遮挡导致部分图像特征丢失的情况下依然检测出了目标,说明YOLOv5-Building提高了图像特征的提取能力;从图16(a)、(b)中间和右边存在多目标的图像对比中可以看出,原YOLOv5存在部分目标漏检的情况,而改进后的YOLOv5-Building能够准确检测出图像中所有的违章建筑目标,说明改进后的网络减少了图像信息损失从而获取了更多的信息,提高了有效信息完整性,使得漏检问题得到有效改善。

图16 改进YOLOv5与原YOLOv5检测结果对比Fig.16 Improved YOLOv5 and original YOLOv5 detection results comparison
4 结语
针对人工检测城市违章建筑费时费力的问题,本文在YOLOv5的基础上,提出改进的YOLOv5城市违章建筑目标自动检测方法。本文方法采用无人机航拍的城市违章建筑图像,经过预处理构建数据集,在YOLOv5网络中使用改进的代表批量标准化替代原有BN模块,并使用平滑化处理后的KL散度损失函数替代交叉熵损失函数,最后用LSandGlass模块代替残差网络并剔除低分辨率特征层,得到更适用于违章建筑检测的YOLOv5-Building模型。对比实验的结果表明,YOLOv5-Building的损失函数收敛速度更快,并且与YOLOv5相比FPS提高了9.61,mAP提高了4.57个百分点。
通过将改进YOLOv5网络应用到无人机航拍违章建筑图像检测领域,说明深度学习在违章建筑的自动监察方面具有可行性,能够用于支持城市建筑管理。并且,由于YOLOv5-Building对建筑中的违章建筑有较好的检测速度和精度,其还可用于其他类型的建筑异常检测等方面。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
电子制作(2019年11期)2019-07-04 00:34:38
今日农业(2019年15期)2019-01-03 12:11:33
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
