
深度视觉目标跟踪进展综述
2021-10-26 12:14王宁席茂周文罡李礼李厚强
中国科学技术大学学报 2021年4期
王宁,席茂,周文罡,李礼,李厚强
中国科学技术大学多媒体计算与通信教育部-微软联合实验室,安徽合肥,230027
1 引言
视觉目标跟踪是计算机视觉领域的一个基本任务.目标跟踪旨在基于初始帧中指定的感兴趣目标(一般用矩形框表示),在后续帧中对该目标进行持续的定位,如图1所示.目标跟踪的应用场景非常广泛,包含视频监控、人机交互、机器人、无人驾驶等.虽然近二十年来,视觉目标跟踪取得了极大的进展,但是一些挑战性因素如目标遮挡、背景杂乱、运动模糊、光照变化等仍是目标跟踪算法面临的主要挑战.

图中的红色矩形框表示感兴趣的跟踪目标.图1 视觉跟踪任务示例Figure 1.The example of visual tracking
传统的视觉跟踪算法通常采用手工特征来对目标进行表观建模,通过训练鲁棒的辨别式或生成式模型实现目标跟踪,典型的方法包括 MIL[1]、TLD[2]、SCM[3],STRUCK[4]、KCF[5]等.新近比较有挑战性的数据集如VOT2018[6]或大规模数据集TrackingNet[7]和LaSOT[8]上,这些算法的性能远远达不到实际应用的要求.
自从2012年AlexNet[9]在图像分类任务中大放异彩,深度学习受到了广泛关注.得益于强大的特征提取能力和端到端的训练模式,深度学习技术在计算机视觉、机器学习、自然语言处理等领域都广受关注,并取得了巨大进展.在过去的五、六年间,基于深度学习的目标跟踪算法获得了巨大突破.一些经典的深度跟踪算法,如 HCF[10]、MDNet[11]、SiamFC[12]、ECO[13]、SiamRPN[14]、ATOM[15]、DiMP[16]等不同程度地挖掘了深度学习的潜能并显著提高了跟踪性能.例如,在经典的OTB-2015[17]数据集上,这些深度学习的跟踪算法大幅度超越经典的跟踪器并不断刷新最优性能.在每年举办的视觉跟踪的挑战赛如VOT-2018中,排名前10位的算法均不同程度地使用了深度特征.这些深度学习的跟踪算法采用了各种各样的框架,包含相关滤波器、分类式网络、双路网络等.在处理跟踪任务的角度,从基于匹配思想的双路网络框架到基于二分类思想的辨别式跟踪器,各种算法框架在性能和效率上各有千秋.
最初的深度跟踪算法主要聚焦于相关滤波器.通过将传统相关滤波器中的手工特征替换成深度特征,跟踪性能得到了大幅度提升.后续研究人员尝试端到端地结合相关滤波器和深度模型,并进一步引出了一系列的基于梯度优化的方案,如DiMP算法[16].通过将跟踪任务视为模板匹配,基于双路网络跟踪算法(如SiamFC[12])由于其简洁的框架和高效率而受到了极大关注.但是该类方法由于忽略了背景信息,因而对相似干扰物的辨别能力较弱,后续工作在双路网络中借鉴相关滤波器来提升模型的辨别能力.此外,受目标检测领域进展的启发,基于分类式的深度跟踪框架(如MDNet[11])、双路网络结合区域锚点的多尺度回归[14]等思路同样受到广泛研究.近期基于Transformer的深度跟踪器使用注意力机制进行跟踪模型建模,取得了领先的性能.我们总结了深度跟踪领域常见的框架及代表性工作,如表1所示.

表1 深度跟踪算法框架概述Table 1.An overview of deep visual tracking algorithms.
表1按照各种算法出现的先后顺序进行安排.深度相关滤波器在2015年左右提出(如HCF[10]),并在近年来持续受到关注.相关滤波器的思想近年来被其他跟踪框架如双路网络和基于梯度的跟踪器所吸纳.基于分类网络(MDNet)和双路网络(SiamFC)的跟踪算法几乎同期被提出,大致于2016年获得了广泛关注.由于分类网络需要在线的模型微调,导致效率偏低,因而近年来关注度逐渐降低.双路网络通过汲取相关滤波器的优势(如CFNet)以及融入区域候选网络(如SiamRPN)而持续地演变和进化,目前仍是研究的热点.基于梯度的优化方法在2019年左右受到了广泛关注,其代表性工作包括ATOM和DiMP.该类方法受相关滤波器启发,通过采用快速梯度下降的方法求解具有前景、背景区分能力的滤波器核.由于利用了背景信息,该类方法相比于双路网络具有更好的干扰物辨别能力.2021年,同时期出现了数个基于Transformer结构的深度跟踪算法.该类方法利用注意力机制利用时序信息[24],或对跟踪器建模[25,26],取得了十分突出的性能.
为了总结归纳深度跟踪算法的发展趋势,本文详细梳理了近年来深度跟踪领域的相关工作,并按如下顺序进行阐述:跟踪数据集的发展趋势、结合深度特征的相关滤波器、基于分类网络的跟踪算法、基于双路网络的跟踪算法、基于梯度的深度跟踪算法、基于Transformer的深度跟踪等,最后对研究方向进行展望.
2 跟踪数据集发展趋势
数据、算法和算力是人工智能最重要的三个要素.在计算机视觉任务中,好的数据集往往能够带动相关领域的快速发展.随着卷积神经网络的快速发展,更多参数量的网络往往需要更多的数据去学习得到一个更好的模型.因此需要一个良好的标注数据集以促进相关算法的快速发展.近些年来,视频目标跟踪领域出现了许多不同大小、种类的数据集.这些数据集引领了目标跟踪算法的进步.本节将详细介绍目标跟踪领域的常见数据集.这些数据集的概况和对比如表2所示.

表2 目标跟踪任务中常用数据集对比Table 2.Comparison of benchmark datasets in visual tracking task.
OTB:OTB数据集分为OTB2013[27]和OTB2015[17]两个版本.其中OTB2013数据集包含51个视频序列,由Wu等收集以往目标跟踪领域的常用测试视频构成.该数据集考虑到很多影响跟踪性能的因素,比如形变、遮挡、光照变化、快速运动、运动模糊等.同时作者还提出了一系列的评估准则,这些准则与数据集一起为跟踪算法提供了相对统一的测试与评估环境,有利于不同跟踪方法之间的比较,极大地促进了早期目标跟踪任务的发展.OTB2015是OTB2013数据集的扩充,通过引入额外的视频,该数据集总共包含100个视频.此外,该数据集还对视频标出了遮挡、形变、快速运动、模糊等11个视频属性,便于分析跟踪器应对不同场景的能力.
TColor-128:Liang等[28]于2015年提出此数据集.针对OTB数据集中存在大量的灰度视频,不利于实际场景的评估,TColor-128数据集收集了128个彩色视频,含27个类别和7个属性.其中,78个视频是新收集的,剩余的50个视频来自OTB2015.其中,新收集的数据集的视频目标跟踪难度高于原有视频.
VOT:VOT数据集[6]随2013年首次举办的单目标视觉跟踪比赛开始发布,每年一期,发展至今.早期VOT数据集主要针对短时目标跟踪,近些年来也会评价算法的实时性以及长时目标跟踪的性能.该数据集的评价方式与以上的数据集不同,当跟踪器在该数据集上每次跟踪目标失败时,跟踪器都会复位,重新进行初始化.最终根据失败的次数以及准确度综合成一个统一的指标来评价跟踪器的性能.
NFS:此数据集[29]包含100个视频,含17个类别和9个属性.不同于常规数据集30 FPS的视频采样频率,NFS视频的帧率达到240 FPS,较高的帧率往往对跟踪器的跟踪性能有很大的提升.通过高帧率的摄像设备,很多传统跟踪算法可以与最新的跟踪器相媲美.和前面数据集一样,该数据集没有划分训练集与测试集.
UAV123:此数据集[30]包含123个由无人机拍摄的视频,有9个类别12个属性,帧率为30 FPS,不同于以往针对通用单目标视频跟踪数据集,UAV123数据集针对特定的无人机场景,视频往往是高空俯视角度,特点是背景干净,视角变化较多.
GOT-10K:此数据集[31]含560个类别,共有1万个视频.在目标类别、视频数量上均远超以往数据集.此外该数据集进行训练集和测试集划分,且两者之间没有重叠.需要说明的是,该数据集的训练和测试视频中的物体类别没有重合,目的在于更加贴近目标跟踪任务的设定,即离线训练阶段跟踪方法没有任何关于待跟踪目标的先验知识,这样可以使跟踪方法更加通用,不依赖于特定物体类别或数据集.
TrackingNet:此数据集[7]包含超过3万个视频,共有27个目标类别,其视频数量和标注数量比以往的任何跟踪数据集都要大.同时该数据集也进行训练集和测试集划分,且两者之间没有重叠.该数据集提供的大规模视频能够有效地缓解当前跟踪领域的训练数据不足问题.
OxUvA:此数据集[32]包含366个视频,总时长超过14小时.OxUvA专门针对测试长时跟踪的性能.长时跟踪,由于目标频繁地被遮挡及超出视野,对跟踪器的鲁棒性有更高的要求.与此同时,作者还提出了评价长时跟踪算法性能的指标,有助于带动长时跟踪领域的发展.
LaSOT:LaSOT[8]是近年来Fan等提出的高标准的数据集,包含70个类别1400个全部由人工标注的视频,分为训练集与测试集,且两者没有重叠.该数据集的视频平均长度在2500帧左右,算法训练具有挑战性.同时作者也提出对应的评价标准以并测试了多数当前领先的目标跟踪算法性能.
上述的跟踪数据集各有特色并且近年来提出的新数据集也展现出更大的挑战性.种类多样的数据集为全面综合评估跟踪算法提供了有力的工具.此外,近年来的高质量、大规模数据集为深度跟踪算法的训练提供了极大的便利.
3 深度跟踪算法
3.1 深度相关滤波器跟踪
相关滤波器(correlation filter,CF)通过学习一个具有区分力的滤波器来处理待跟踪的图片,其输出结果为一个响应图,表示目标在后续帧中不同位置的置信度.相关滤波器通过利用循环样本和循环矩阵的性质求解岭回归问题,得到了频域上的高效闭合解,计算效率高.传统的相关滤波器使用手工特征(如HOG、ColorName等)进行学习,较好地兼顾了性能和效率.由于相关滤波器的学习过程中引入了循环样本,这些样本不可避免地带来了边界效应,因此学者对传统的相关滤波器算法针对如何抑制边界效应开展了大量的研究,典型的工作包括SRDCF[33]、BACF[34]、ASRCF[35]等.其余的经典工作包含如何自适应调整学习率(如SRDCFdecon[36]),如何引入更多的背景信息(如CACF[37])等.
随着深度学习的日益发展,深度学习与相关滤波器的结合受到了广泛的关注.在早期的工作中,研究人员探索如何将离线训练好的深度特征(如利用ImageNet预训练的VGG模型[38])与相关滤波器进行结合.典型的工作HCF[10]提出将不同层的深度特征分别训练相关滤波器并进行由粗到精的融合.高层的语义特征对于目标的抽象表达能力很强,而低层的模型特征擅长刻画目标的纹理、形状等底层信息.通过将不同尺度特征的滤波响应图进行融合,相关滤波器更好地利用了深度模型.HCF的框架图如图 2所示.在后续的工作中,如何更加充分利用深度特征得到了进一步研究,如HDT[39]算法研究了如何自适应地改变各尺度特征下滤波器的权重,MCCT[40]跟踪器将滤波器的各种特征进行组合并从中自适应切换等.
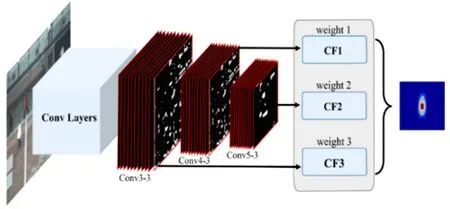
图2 HCF算法[10]示意图Figure 2.Framework illustration of HCF algorithm[10].
深度相关滤波器跟踪代表性的工作C-COT[18]和ECO[13]取得了同期十分优异的性能.C-COT算法重点研究了不同尺度深度特征的分辨率不同而导致的响应图融合问题.不同于传统方法采用线性插值来调整特征或响应图的尺度,C-COT采用了连续性插值并和滤波器进行联合优化,取得了良好的效果.ECO在C-COT的基础上,进行了自适应的相关滤波器选取、目标样本的聚类和稀疏的目标更新,获得了效率和存储上的进一步优化并轻微提升了性能.在UPDT[41]中,C-COT和ECO系列工作进一步研究了深度特征在相关滤波器中的潜能.以往的深度滤波器跟踪通常使用较浅的神经网络进行特征提取,使用更深的网络如ResNet[42]并没有进一步的性能增益.UPDT算法详细分析了该问题,并提出了适合深度相关滤波器的数据增广、滤波器带宽、融合权重优化等细节,使得深度相关滤波器在使用更深的神经网络后可以得到持续的性能提升.虽然上述深度相关跟踪在一系列数据集中取得了优异的性能,但是提取特征耗费了大量时间,使其即便使用先进的GPU也无法达到实时的速度.
随着技术进一步发展,研究人员发现离线训练的深度特征可能并不是最适合相关滤波器的.得益于相关滤波器的闭合解,研究人员尝试将滤波器和深度特征提取网络进行联合训练.这样训练得到的网络不仅能够获得适合滤波器的特征,而且网络的深度也比较浅.经典的工作包括CFNet[19]和DCFNet[43].CFNet的流程图如图3所示,该方法将相关滤波器嵌入在双路网络中进行端到端的学习,在获得相关滤波器辨别能力的情况下,同时保证了极高的运行效率.同时期提出的DCFNet采用了相似的策略将相关滤波器和主干网络进行联合学习,并在线更新滤波器模板取得了更优的性能.这类端到端的训练模式效率良好并保持了相关滤波器的频域闭合解.但是相关滤波器中抑制边界效应等一系列工作(如SRDCF、BACF)和其他优化(如C-COT、ECO)等破坏了经典相关滤波器(如KCF)的闭合解,需要使用交叉迭代的方法进行优化,为端到端训练带来了新挑战.RTINet[44]对此进行了探索并成功将BACF和深度学习网络进行联合训练.在最新的一系列工作中,研究者采用了梯度下降的方法,成功地汲取了上述工作的优势并采用端到端的网络训练优化整个框架.

图3 CFNet[19]框架示意图Figure 3.Framework illustration of CFNet algorithm[19].
3.2 基于分类的深度跟踪器
基于分类的深度跟踪方法受经典的目标检测框架R-CNN[45]的启发,将目标跟踪任务视为二分类(目标和背景)任务.该深度跟踪网络包含预训练的卷积层以提取通用的、鲁棒的深度特征,然后利用第一帧的大量正、负样本进行全连接层的训练,使得网络能够适应当前场景下的目标区分.后续通过适当的网络更新以适应目标的变化,但同时也使得效率降低.MDNet方法[11]最早将分类式网络引入跟踪领域,并针对跟踪场景中目标和背景在不同视频(目标域)下可能引起歧义(即该视频中的目标可能成为其他视频中的背景物体),引入了多目标域下的训练模式以学习鲁棒的通用目标特征.在MDNet的训练过程中,网络的共享层(包含前三层卷积层和两个全连接层)由训练集中所有视频共同训练.对每个视频,分别训练独立的分类层(最后一个全连接层)用于区分当前视频域中的目标和干扰物.经过离线训练阶段,在跟踪时,利用第一帧的标注信息快速微调一个新的全连接层用于辨别当前视频的前、背景.MDNet的训练图片如图4所示.
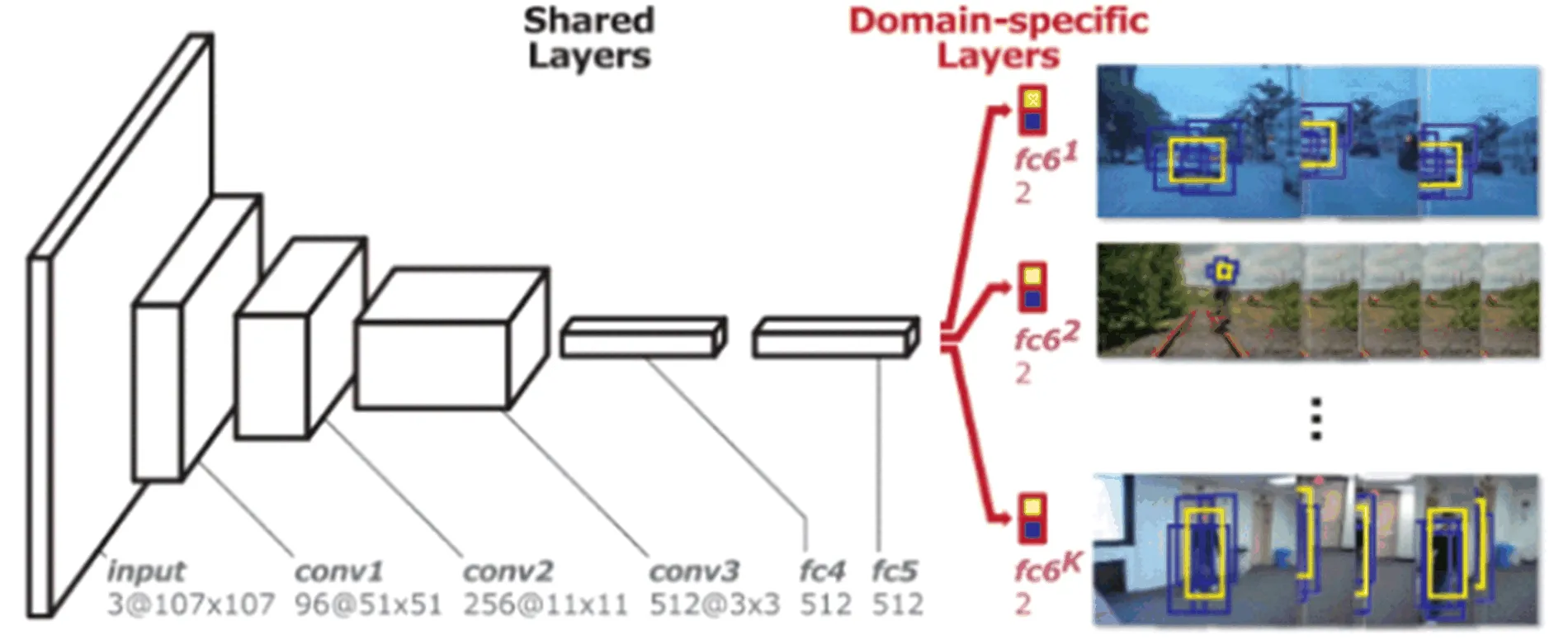
图4 MDNet算法[11]框架Figure 4.Framework illustration of MDNet algorithm[11].
后续的一系列工作围绕该分类式模型展开.BranchOut[46]算法在MDNet的基础上引入了模型集成的思想,提出了多个并行的全连接层,并挑选对当前场景最具区分力的子分类器进行跟踪.VITAL[20]方法在MDNet分类模型中引入了生成对抗式网络,通过生成具有遮挡属性的掩膜来干扰分类器,使得分类器学习到的特征更加鲁棒以抑制遮挡掩膜的影响.分类式跟踪方法的主要弊端是速度慢,在GPU中仅能达到1 FPS,其主要原因在于大量的候选样本都需要进行特征提取.近期的实时MDNet算法(RT-MDNet[21])在分类式网络借鉴Fast RCNN[47]的思想,对搜索区域进行共享特征的提取再裁剪出样本特征,通过引入ROI Align并修改了其他一系列网络细节使得精度下降很少的情况下跟踪速度得到极大提升.
3.3 双路网络跟踪算法
近些年由于深度神经网络快速发展,其强大的特征提取能力使得其对计算机视觉不同领域的表现都有很大的提升.在视频目标跟踪中,Bertinett等于2016年首次提出双路网络框架(SiamFC[12]),此方法利用卷积网络提取目标模板和搜索区域的特征,然后再进性相关操作生成响应图,其中响应图上的峰值点就是目标所在的位置,如图5所示.不同于传统的相关滤波器算法,双路网络不需要在线参数更新,而且目标模板的特征只需要提取一次即可,因此双路网络的跟踪速度通常很快.经典的SiamFC算法可以在GPU下达到86 FPS的跟踪速度.

图5 SiamFC算法[12]框架Figure 5.Framework illustration of SiamFC algorithm[12].
在此之后,考虑到SiamFC对目标尺度的回归仍然采用传统缩放形式不能准确地获得目标的尺度信息,Li等提出SiamRPN[14],此方法将目标检测中的RPN结构引入到SiamFC中,通过利用共享的参数提取特征,然后分别通过分类支路获得目标的位置以及回归支路获得目标尺度的精确估计.如图6所示,左边表示共享参数的CNN网络;中间部分表示RPN模块,这里包含了两支,一支表示分类网络,另一支表示回归网络.相比于SiamFC中采用的传统的图像金字塔的方式来估计目标的大小,SiamRPN的推理速度更快,可以达到160 FPS.此后Li等进一步对SiamRPN进行拓展提出DaSiamRPN[48],通过有效地利用负样本对提高了跟踪器的抗干扰能力.尽管如此,以上方法都是使用AlexNet作为特征提取网络,没有用到当前的更深、更强大的特征提取网络.因此为了能使双路算法充分利用到现有得深层神经网络,Li等对ResNet网络进行更改提出了SiamRPN++算法[22].SiamRPN++一方面采取随机平移目标在搜索区域内的位置以解决CNN网络边界填充对网络平移不变性的破坏,另一方面也采用了高、中和低层的特征融合的方式获得更好的目标特征表达.最终通过结合多个数据集进行训练,SiamRPN++在多个目标跟踪的数据集上获得了很好的效果.

图6 SiamRPN算法[14]框架Figure 6.Framework illustration of SiamRPN algorithm[14].
研究人员针对SiamFC框架,提出了一系列改进,包括集成学习引入互补的双路网络分支[49],引入注意力机制[50,51],无监督学习[52,53],图卷积神经网络[54],采用强化学习来调整模型参数[55]等.Du等[56]提出了基于角点预测的双路网络.Siam R-CNN[57]提出基于重检测的长时双路跟踪框架,取得了十分出色的结果.针对SiamRPN框架,研究人员进一步研究了无锚点的双路网络[58,59].基于固定锚点的方法很难约束与目标重合度较小(如IOU<0.3)的锚点,而无锚点的双路网络能够在较大空间内回归目标区域,因而表现更加出色.
尽管以上的双路网络方法在视频目标跟踪中取得了很大的成功,但是仍然存在缺陷,即其始终使用视频序列的初始帧模板与后续每一帧进行匹配,缺少在线更新过程.这导致我们的跟踪器不能自动调整参数以适应目标的变化,于是提出了基于双路网络的更新方法.MemTrack[60]算法通过LSTM结构利用历史帧的模板信息去预测当前帧的模板信息.Meta-Tracker[61]算法额外利用一个元学习网络为双路网络提供新目标的外观信息.此外,Re2EMA[62]算法学习一个变换矩阵将过去的模型自适应地变换到新模型.UpdateNet[63]算法训练一个独立的卷积网络,利用历史模板在下一帧预测一个最优的模板特征.GradNet[64]算法利用梯度信息去更新模板,这一定程度上可以抑制模板中的背景信息.以上算法从不同角度利用历史帧信息更新模板,这缓解了固定模板带来的适应目标变化不足的缺陷.
3.4 基于梯度优化的深度跟踪方法
经典的相关滤波器通过闭合解的形式最小化岭回归损失,但是该闭合解主要依赖循环样本.在使用真实样本的情况下,岭回归损失虽然失去了快速的闭合解,但仍可以通过梯度下降的方法进行求解.在CREST[23]算法中,深度学习中常见的随机梯度下降算法(SGD)被用于优化该岭回归损失,来学习一个类似相关滤波器具备前景、背景区分能力的卷积核.该卷积核和搜索图片的特征图进行卷积,可以生成响应图用于目标跟踪.在CREST跟踪器中,作者进一步引入残差项来弥补目标外观的快速变化,取得了进一步的性能提升.在DLST算法[65]中,研究人员发现训练区域中的正负样本不均衡问题导致梯度优化不够精确且效率不高.该方法基于岭回归中的二范数损失形式,引入了收缩式损失权重,极大地抑制了冗余的、容易分类的负样本的权重,使得学习到的滤波器更加具有区分力且学习的速度更快.
上述的随机梯度下降方案能够学习到鲁棒的滤波器用于目标跟踪,但是随机梯度下降的优化过程通常需要数十次甚至上百次迭代才能较好地收敛,因而一定程度抑制了跟踪器的效率.在最近的工作中,研究人员转向更加快速的梯度下降方法.ATOM[15]算法中,作者采用共轭梯度策略结合深度学习框架进行快速优化.共轭梯度下降方法估计了每次迭代的学习率和步长,配合深度学习框架的梯度回传求解能力,可以快速地进行优化.该研究团队在工作DiMP[16]中进一步将该思想用在了端到端的学习中,通过神经网络学习到所有的参数,取得了目标领先的性能.DiMP算法的流程图如图7所示.该算法最核心的设计在于模型预测部分,其包含一个模型初始化和一个模型优化器.模型初始化主要通过剪裁目标区域特征并通过池化来得到一个良好的初始化滤波器模型,该过程和经典的双路网络类似.模型优化器部分旨在约束初始化滤波器进行岭回归损失,使得滤波器模型具有背景区分的能力.由于使用神经网络端到端地估计梯度下降的优化步长,使得模型可以在少数的几次迭代中快速收敛,保持了岭回归损失的区分能力同时保证了跟踪效率.该算法在数个跟踪数据集上都刷新了当前最好的性能.
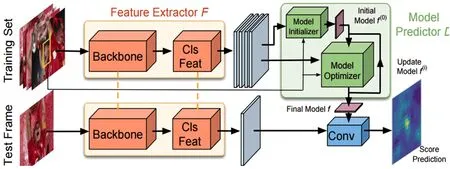
图7 DiMP跟踪算法[16]框架Figure 7.Framework illustration of DiMP algorithm[16].
D3S算法[66]将ATOM中基于梯度优化的相关滤波器模型融合在视频目标分割网络中,增强了对干扰物的辨别能力.在DiMP算法的基础上,PrDiMP[67]采用了基于概率回归的方法对跟踪器和尺度预测模块进行建模,减缓不精确或有歧义的噪声标签对网络的干扰,有效提升了模型精度.KYS算法[68]在DiMP的基础上考虑了周围环境中背景物体在连续帧间的关联,有效提升了跟踪器对背景区域的感知能力和对干扰物的区分能力.
3.5 基于Transformer的深度跟踪方法
Transformer结构[69]最初在自然语言处理任务中提出.Transformer的核心模块是注意力机制,可以将全局信息聚合到需要的位置.由于该结构可以充分利用GPU等硬件设备进行并行计算,因而相比于传统的RNN方法更加适合处理长句子.近年来,注意力机制[70]在视觉任务中展示了优异的效果.基于Transformer的深度跟踪器在近期取得了优异的性能,获得了广泛的关注.
Wang等[24]利用Transformer结构探索视频中的时序信息.传统的跟踪器通常将跟踪任务视为逐帧的目标检测,忽视了丰富的时序关系.文献[24]提出使用Transformer结构将独立的视频帧桥接起来,一方面利用Transformer编码器对不同时刻的模板进行相互融合,另一方面利用Transformer解码器将不同时刻的视频帧桥接起来,以传递丰富的时序信息,如目标在不同时刻的特征表达以及模板的注意力掩膜等.TransT算法[25]借鉴Transformer结构改进传统双路网络中的特征融合操作.传统的双路网络跟踪器利用相关操作将模板特征融合到搜索图片特征中对搜索区域进行分类和回归.然而这种相关操作没有对模板和搜索区域特征的关系进行充分建模.TransT算法利用Transformer中的注意力机制将模板信息融合到搜索区域中,以便更好地进行目标定位和尺度回归.STARK算法[26]借鉴目标检测算法DETR[71],利用Transformer结构进行局部区域中的目标检测实现跟踪任务.该算法不使用诸如高斯窗等后处理机制,仅使用网络来预测目标的角点进行跟踪.STARK算法进一步引入时空信息,通过在跟踪过程中将新采集的样本加入Transformer,跟踪器可以一定程度适应目标的外观变化,取得进一步的性能提升.值得注意的是,最近提出的Transformer跟踪算法[24-26]在大规模数据集上不断刷新了当前的最优性能,显示了Transformer跟踪的巨大潜力.
4 展望
视觉跟踪领域的算法层出不穷,并且各类算法框架都处于不断的发展与完善中.随着研究的不断深入,深度学习的潜能也进一步被激发.然而,现有的框架仍存在有待提升的空间.
最近的双路网络方法(如SiamRPN++)和梯度优化的方法(如DiMP)为了追求高性能,均采用了很深的CNN模型如ResNet50.最新的深度模型动辄具有几十甚至上百兆的模型大小,使得这些算法需要极大的存储空间,限制了实际应用.如何设计适合他们的轻量级模型,例如使用神经网络搜索的方式来获得更优的模型结构,以兼顾低内存消耗和高精度具有重要的研究价值.
此外,随着CNN网络越来约深,模型越来约复杂,几大类深度跟踪框架无论双路网络(SiamRPN++)、分类网络(如RT-MDNet)还是梯度优化的方法(DiMP),都仅能保持GPU设备下勉强实时的速度.视觉跟踪作为很多应用系统中的底层辅助任务,对效率有很高的要求.期待未来更多的工作能够聚焦于跟踪算法的速度提升.设计硬件友好的模型运算结构,用于特定场景的高效率视觉跟踪同样具有巨大的应用前景.
基于Transformer的视觉跟踪算法刚刚起步,未来有巨大的挖掘空间.首先,目前的Transformer跟踪算法[25,26]仍没有充分利用背景信息,如何将背景信息引入到Transformer结构中提升它的前景、背景区分能力有待探索.其次,设计可更新的Transformer结构,用于适应目标的外观变化亟须探索.例如,STARK算法[26]仅仅粗暴地加入一帧历史样本.如何更好地利用时序信息以更新Transformer模型将有助于达到更优性能.最后,Transformer的注意力机制擅长进行多模态信息间的转换以及融合,该框架的兴起为多模态的视觉跟踪提供了良好的研究契机,如带有红外信息(RGBT视频中)和深度信息(RGBD视频中)的视觉跟踪.
目前几大类主流的跟踪算法框架均聚焦于短时视觉跟踪场景.在实际的复杂场景中,如长时目标跟踪的情况下,如何处理目标的剧烈外观变化、严重目标遮挡、频繁超出视野等问题仍有巨大的提升空间.应对目标外观的长时间的、剧烈的变化,如何有效对目标外观进行建模以及如何更新跟踪模型充满挑战.将现有的短时跟踪算法扩展到复杂的实际场景中需要不断探索.Transformer跟踪器在各种短时跟踪数据集中展示了出色的性能.而Transformer结构本身特别擅长对全局信息进行聚合和分析,能否利用该结构对长时的时序信息进行建模,以判断跟踪失败、超出视野以及目标重检测,需要进一步探索.
5 结论
尽管近十年来视觉目标跟踪技术取得了巨大的进展,但在复杂的实际场景中,计算机跟踪系统和人类的视觉系统仍有巨大差距.虽然深度学习算法取得了令人瞩目的成绩,但与此同时带来的跟踪效率限制和模型存储消耗等问题仍需进一步完善.真正意义上的通用、鲁棒、准确且高效率的视觉跟踪研究仍然任重道远.我们也目睹了近年来的视觉跟踪领域的快速迭代和不断突破,相信在众多研究者的共同努力下,未来的视觉目标跟踪技术会朝着实用、高效、可靠、通用的跟踪技术方向迈进.
致谢
本文工作得到中国科学技术大学青年创新重点基金(YD3490002001)资助.
利益冲突
作者声明本文没有利益冲突.
作者信息
王宁,中国科学技术大学信息学院博士研究生.研究方向:视觉目标跟踪.
席茂,中国科学技术大学电子工程与信息科学系硕士生.
周文罡,中国科学技术大学信息学院教授,国家“优秀青年基金”获得者.研究方向:多媒体信息检索和计算机视觉.
李礼,中国科学技术大学信息学院教授,研究方向:图像处理与计算机视觉等.
李厚强,中国科学技术大学电子工程与信息科学系教授,多媒体计算与通信教育部-微软重点实验室主任,国家“杰出青年基金”获得者,“长江学者奖励计划”获得者.研究方向:图像处理与计算机视觉、强化学习与机器博弈、多媒体信息检索、视频编码与通信等.
猜你喜欢
太阳能(2022年3期)2022-03-29
太阳能(2020年3期)2020-04-08
电子制作(2019年11期)2019-07-04
当代工人·精品C(2019年2期)2019-05-10
电子制作(2018年16期)2018-09-26
通信电源技术(2018年3期)2018-06-26
铁道通信信号(2018年1期)2018-06-06
计算机应用与软件(2017年7期)2017-08-12
系统工程与电子技术(2016年7期)2016-08-21
火控雷达技术(2016年2期)2016-02-06

- 中国科学技术大学学报的其它文章
- Vocational interests and informal learning in the workplace:The mediating role of goal orientation
- Corporate resistance to pandemic:Evidence from China
- The performance analysis on a novel purified PV-Trombe wall for electricity,space heating,formaldehyde degradation and bacteria in activation
- Development of the Ag nanoparticle-decorated Co3O4 electrode for high-performance hybrid Zn batteries
- Estimation based approximating control for wireless networked control systems