
基于多层深度特征融合的中低分辨率车型识别研究
2021-10-26 07:22侯远韶
安阳工学院学报 2021年6期
侯远韶
(河南工业贸易职业学院机电工程系,郑州451191)
车辆在快速移动时背景不断变化,同时受制于计算机硬件、环境和天气等因素,使得采集的车辆信息难以对车型进行全面的描述,进而导致车型信息有限、鲁棒性差,对后期的车型识别和数据维护都存在较大挑战[1]。针对这一情况,主要通过提升硬件参数和改进软件算法两个方面来提升车型的识别率:提升硬件参数可以精确得到车辆的有效信息,在一定程度上提高识别率,但是当硬件参数达到一定数值时,每增加一个数量级都需要付出巨大的成本,同时环境和天气等外部因素以及后期维护成本都是需要考虑的因素;传统的机器学习和车型识别算法过于依赖提取特征的全面性以及识别算法的准确性,且只有当特征之间存在巨大差异时才会有较好的识别效果,不具有普适性;基于改进卷积神经网络的多层深度特征融合算法,通过含有多个隐层的深层网络获取图像的初始特征,然后通过特征融合策略对多个特征进行融合,得到更具有代表性的车型信息,从而提高车型识别效率,同时避免了位置变化以及背景多变带来的影响[2]。
1 深度特征融合相关理论
1.1 典型的深度学习方法
图像的低层特征如何与高层语义联系起来是图像处理的难点。源于人工神经网络的深度学习,模拟人脑进行学习分析,可以将原始数据通过一系列简单的、非线性映射转变为高层次抽象的表达[3]。典型的深度学习主要有双向分层递归神经网络(RNN)、受限玻尔兹曼机(DBN)、卷积神经网络(CNN)等,通过构建含有多个隐层的模型(通常在5层以上),对原始数据进行训练,进而得到具有图像代表性信息的特征[4]。深度学习利用分层原理逐层进行特征提取将提取到的低层特征,反馈给高层,也就是说将m层的输出作为m+1层的输入,用数学原理表示为,如果存在多维复杂函数log(cos(exp(sin(x)))),深度学习则可以将多维复杂函数分解为低维简单函数x,sin(x),ex,cos(x),log(x),深度学习利用分层原理网络模型如图1所示。

图1 深度学习利用分层原理网络模型
1.2 深度卷积神经网络
卷积神经网络主要由卷积层、池化层和全连接层构成,权值共享、局部连接、池化是卷积神经网络所具有的典型特征,可以将复杂抽象的网络结构类似成生物神经网络,在减少网络参数的同时保持网络的深层结构,进而提高系统的稳定性[5]。卷积神经网络不需要对原始数据进行复杂的变换从而直接输入网络,避免复杂的特征提取和数据重建,同时针对复杂多变的外部环境,卷积神经网络具有高度不变性,在面对图像数据倾斜、平移、比例缩放时仍然具有稳定性[6]。
卷积神经网络计算包括前向传导、反向传导以及卷积和降采样过程[7]。传统的图像处理算法,在面对一个1 000×1 000像素的图像时,需要将图像表示成一个1 000 000的向量进行描述,同时每个神经元都需要面对所有输入层像素,那么由图像处理算法可知隐层的参数规模将达到1 000 000×1 000 000为1012个,在面对如此规模的参数时,对计算机硬件和处理算法都是一个巨大的挑战[8]。针对这种情况,通过对局部数据进行特征感知的卷积神经网络,在进行卷积操作时可以减少参数数量,同时具有相同特征值的神经元可以进行权值共享,进一步提升网络流畅性,缓解数据的类不平衡,卷积神经网络原理如图2所示。

图2 卷积神经网络基本结构
1.3 多特征深度融合
不同等级的特征具有不同的特点,深度学习利用分层原理逐层进行特征提取将提取到的低层特征,反馈给高层,而如何在不丢失低层结构特征的同时保留高层特征的语义信息是研究的重点[9]。低层图像信息完整地保留了数据的结构和彼此间的关联性,具有分辨率高图像清晰的特点,但用于检测图像内在语义信息不足;高层特征语义信息丰富可以很好地表达图像的内在语义信息,但由于经过多次卷积和变换,图像原始的结构信息丢失进而导致对图像的细节感知不足[10]。将低层特征和高层特征以一定的规则进行互补融合,从而最大程度提升识别效果,是多特征深度融合的关键。具体做法就是将低层特征的结构信息融合到高层特征,高层特征的语义信息融合到低层特征,实现优势互补进而得到一个联合高低级特征的深度卷积神经网络图像识别算法[11]。
2 基于多层深度特征融合算法设计与实现
2.1 多层深度特征融合模型
建立多层深度特征融合模型,需要讨论特征融合的可行性。中低分辨率车型的识别,首先需要选择具有代表性的特征,但由于其分辨率较低在低层特征上缺少语义信息,同时深度学习模型需要大规模的数据集,故对系统硬件提出了更高的要求。其次,深度网络含有多个隐层(一般大于5个),导致局部特征维度大于全连接层特征向量维度,因此建立多层深度特征融合模型必须解决这些问题,才能实现算法的整体提升[12]。
多层深度特征融合模型具体操作为:通过卷积下采样运算将低层特征降维进而达到相同的尺寸,具体流程为将图像低层特征与深度为Ⅰ而维数不同的卷积核进行卷积运算,使得低层特征的维度下降但深度不变,卷积神经网络下的采样为池化,池化可以看作以p范数为卷积核的卷积运算,数学表示式为
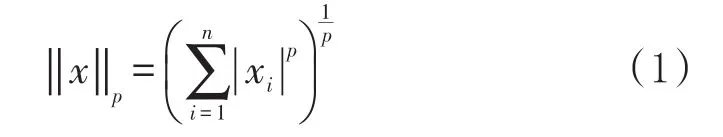
式(1)中,x为n维向量,xi(i=1,2,……,n)为向量元素。当p接近无穷大时为最大池化,p=1时则为平均池化,传统的池化操作可能会丢失图像部分信息,而针对中低分辨率的车型信息时,任何信息的丢失都可能造成识别的误差,因此需要通过卷积操作避免数据的丢失。如果低层特征维度为(m×m),深度为n,卷积运算结果为
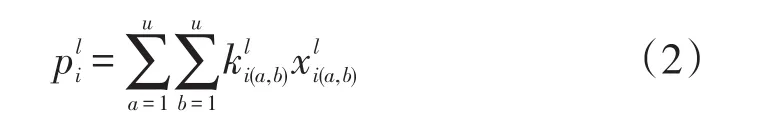
式(2)中,第l层的特征映射用l表示,a=(1,2,……,u),b=(1,2,……,u),为卷积核在像素区域对应的位置,为像素区域,为像素区域(a,b)第i个卷积核的值。那么在像素区域(a,b)处的多层深度特征融合Y,可以通过对低层特征卷积运算与激活函数f、偏置函数以及加权函数Wl求和得到

2.2 算法设计
多层深度特征融合算法,在构建融合模型的基础上,需要进行训练过程和特征组合方式的研究,算法通过对深度特征1和2进行融合得到特征融合层,然后特征融合层再与深度特征3融合,以此类推得到全连接层网络,继而利用不同深度特征间存在的结构信息,实现低层特征和高层特征的优势互补融合,最大程度提升识别效果。全连接层网络节点决定了算法的有效性,k层网络的节点Z数学表示为

式(4)中,xk-1表示k层网络的前一层。算法在去除冗余特征的同时,有效避免了特征融合带来的维数灾难,同时可以得到不同特征间的相关信息,进而通过融合特征得到鲁棒性好、识别能力强的特征,增加车型的识别效率。多层深度特征融合算法具体流程如图3所示。
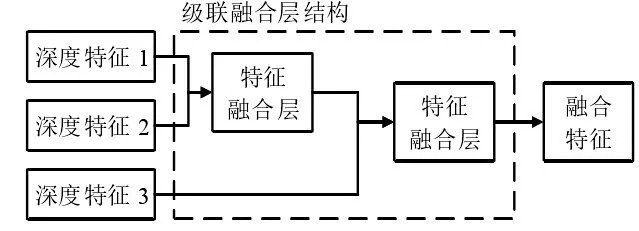
图3 多层深度特征融合算法流程
2.3 多层深度特征融合网络优化
像素区域的多层深度特征融合结果,受偏置函数、加权函数以及激活函数的影响,同时中低分辨率的车型图像对外界环境变化敏感,而深度学习只有通过大量的训练数据集才能得出数据特征,因此为了防止过拟合现象的发生,需要对多层深度特征融合网络进行优化,具体方法有数据加强技术和Dropout技术。基于Dropout的防过拟合,为了减少参数数量需要对神经元进行选择,每个神经元的选择概率相等,如果某个神经元的传递函数为

假设原网络的激活函数为a(h),采用Dropout技术后隐藏部分神经元,得到一个不可靠的网络结构,避免过拟合现象的发生,融合后网络的激活函数为

那么,基于Dropout的防过拟合输出结果为

式(7)中,D=(x1,x2……xdh)为伯努利分量。基于Dropout的网络优化,在降低计算复杂度的同时,可以很好地防止过拟合现象的发生,同时降低了样本训练时间,提升了算法的时效性。
3 实验设计与结果分析
试验平台采用64位PC机,Windows7操作系统,CPU为Intel i7处理器,96GB RAM,图像处理器(GPU)采用NVIDIA,编程环境为Python3.8。试验数据集采用Stanford cars数据库,Stanford cars将汽车类别按型号、年份、生产商进行分类由斯坦福大学发布,该数据集包含分辨率为575pixel×310pixel的16 185张汽车数据,共197个车型。为了验证算法的普适性,采用数据集16 185张汽车数据中的8 144张作为深度学习的训练样本,8 041张图片作为测试样本,通过对比不同算法对测试样本的识别准确度、特征敏感度来验证算法的性能。不同算法实验对比分析结果见表1。
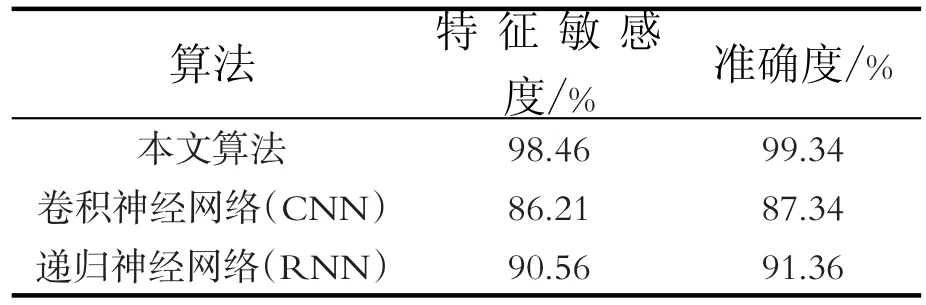
表1 不同算法实验对比分析
通过表1可知,本文算法不管是在准确度上还是对特征的敏感度上都明显优于其他算法,具有良好的识别效果,体现了高维和低维特征融合的优越性,同时在保持较高精确度的同时避免了过拟合现象的出现。但是,由于Stanford cars数据库没有显现出低分辨率以及复杂背景下融合算法的优越性,因此,为了体现算法的普遍适应性特别是在中低分辨率情况下的效果,通过对数据集图像人为进行加噪处理,使得数据集分辨率降为原始图像分辨率的80%、60%和40%,来验证本文算法在中低分辨率情况下对车型识别的效果。不同算法在不同图像分辨率下的实验结果见表2。

表2 不同算法在不同图像分辨率下实验结果
通过表2可知,不同分辨率情况下基于多层深度特征融合的车型识别算法可以充分融合高维低维的特征信息,将低层特征的结构信息融合到高层特征,高层特征的语义信息融合到低层特征,进而实现高低维特征间的优势互补,相对于其他算法具有一定的优势和普遍适用性。
4 结束语
本文首先分析了典型的深度学习方法,以及卷积神经网络的基本结构和操作,在此基础上提出了多层深度特征融合算法以及优化策略。为了提高车型识别效率,同时降低计算复杂度,建立多层深度特征融合模型,将高层特征的语义信息和低层特征的结构信息进行优势互补,为了避免过拟合现象的出现采用Dropout技术对融合网络进行优化。最后通过实验仿真,验证本文算法在不同分辨率情况下的准确度以及对特征的敏感度,实验表明本文算法相对于传统算法具有一定的识别精确度和普遍适用性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
报刊荟萃(上)(2018年3期)2018-04-24
北京航空航天大学学报(2018年1期)2018-04-20
益寿宝典(2017年34期)2017-02-26
妇女生活(2016年5期)2016-05-26
重型机械(2016年1期)2016-03-01
