
基于Python影评数据挖掘与分析
——以《你好,李焕英》为例
2021-10-25 03:43:18邵小青贾钰峰章蓬伟
信息记录材料 2021年10期
邵小青,贾钰峰,章蓬伟,丁 娟
(新疆科技学院信息科学与工程学院 新疆 库尔勒 841000)
1 引言
近年来,自然语言处理技术得到了以计算机科学为代表的自然科学领域到社会科学领域的广泛关注,并且在新闻传播、舆论管理、观点分析等问题中展示了不容忽视的价值[1]。随着互联网的发展和大数据时代的到来,网络上的数据分析仅仅靠人工筛选挖掘出有价值的信息是实现不了的,如何快速高效地从不规则、海量的文本中挖掘出有意义的信息并分析情感倾向性是自然语言处理(natural language processing,NLP)领域研究的热点。NLP是人工智能领域的一个分支,主要是运用自然语言处理和理解人类的语言,应用包括机器翻译、信息提取、文本分类、语音转换等。本文通过Python语言编写爬虫程序自动获取数据,筛选有价值的信息,对数据进行挖掘来解决业务问题。对豆瓣影评数据进行清洗与筛选,采用Python的类库SnowNLP进行影评数据的情感分析,将有价值的数据通过可视化技术展示出来,可以帮助用户更高效便捷地获取到有价值的信息,同时为媒体、电影市场、社交网站提供口碑及相关服务的帮助。
2 数据采集
登录豆瓣电影《你好,李焕英》页面,Python爬取解析网页源码,由于豆瓣电影短评总数只能显示500条评论,爬取到数据500条。首先确定数据所在的url,《你好,李焕英》豆瓣影评的URL是https://movie.douban.com/subject/34841067/comments?start=20&limit=20,34841067为电影ID,start=20影评开始的页面,limit=20是每页评论数。使用requests库发送网络请求,url='https://movie.douban.com/subject/34841067/comments?status=P',headers={"User-Agent":Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/90.0.4430.72 Safari/537.36 Edg/90.0.818.42},查看文本内容:response=requests.get(url=url,headers=headers)。使用xpath解析影评数据,html_data=response.text,selector=parsel.Selector(html_data),comments_list=selector.xpath("//span[@class='short']/text()").getall()。每条数据内容有10个维度,数据保存结果见图1。

图1 影评数据
3 数据预处理
爬取到的电商评论数据集存在很多无意义或重复的数据,如果不进行数据清洗预处理,把这些数据进行分词、词频统计及情感分析等,会增加很大工作量,甚至影响实验结果的准确性[2]。
去除重复、不完整、语义不清的数据,获取有效评论485条。借助jieba分词对清洗后的每条评论进行中文分词,以哈尔滨工业大学停用词词典为基础对停用词进行过滤,最后生成标准化的文本。
4 影评结果可视化
基于Matplotlib库实现影评结果可视化,以《你好,李焕英》为例,影评饼状图见图2,影评评分饼图可相对直观展示出影评星级比例;词云图见图3,影评关键词展示图可展示出观众对《你好,李焕英》的热点话题。其中,五星占41以上,一星占11%,影评情感反馈这是一部催泪感人的电影,仅有一小部分人认为是烂片。从图2、图3可以初步判断大多数观众对《你好,李焕英》这部电影持有喜爱和推荐的态度,值得观赏。
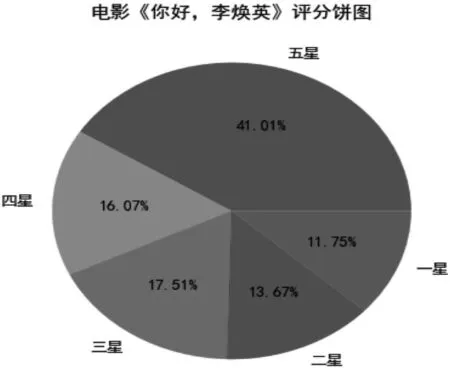
图2 影评评分饼图

图3 影评关键词展示图
5 影评情感倾向性分析
影评描述性可视化仅能在一定程度上展现观众对电影的情感倾向和关注话题,不能挖掘出评论蕴藏的深层次情感。本文通过SnowNLP进行影评的情感分析。现在自然语言处理库基于英文的居多,而SnowNLP库是Python中用于专门处理中文文本的类库,功能丰富,能实现中文分词、词性标注、情感分析、提取文本关键词、提取文本摘要及计算文本相似度等[3]。它受到TextBlob的启发而写的,没用NLTK,所有算法都是自己实现的,有自己训练好的字典,采用unicode编码。通过阅读SnowNLP源码,情感判断过程是首先读取分类好的文本内容,对文本进行分词,去除停用词;计算每个词出现的频数,计算文本的先验概率和后验概率,选择概率较大的类别。本次数据分析操作步骤是首先按行读取评论文本,循环遍历通过sentiments方法,计算得到情感分数,生成情感分数柱形图以及波动曲线图。核心代码如下:
line = source.readlines( )
sentimentslist = [ ]
for i in line:
s = SnowNLP(i)
sentimentslist.append(s.sentiments)
plt.hist(sentimentslist, bins = np.arange(0, 1, 0.01), facecolor = 'g')
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.show()
将sentiment情感分析纵坐标区间从[0,1.0]变为[-0.5,0.5],其中0以上表示积极情感,负数表示消极情感。如图4、图5所示,通过情感分布图说明电影持喜爱和推荐的态度观众占绝大多数,积极情感相对集中,电影值得一看。
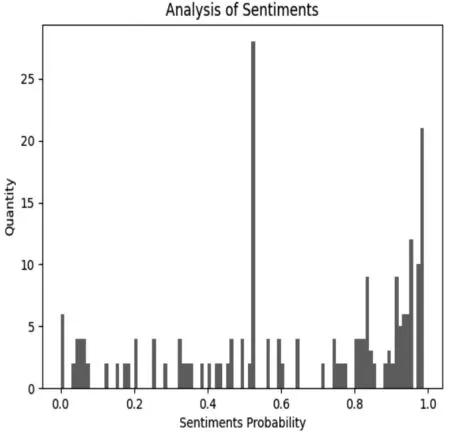
图4 情感分数柱形图
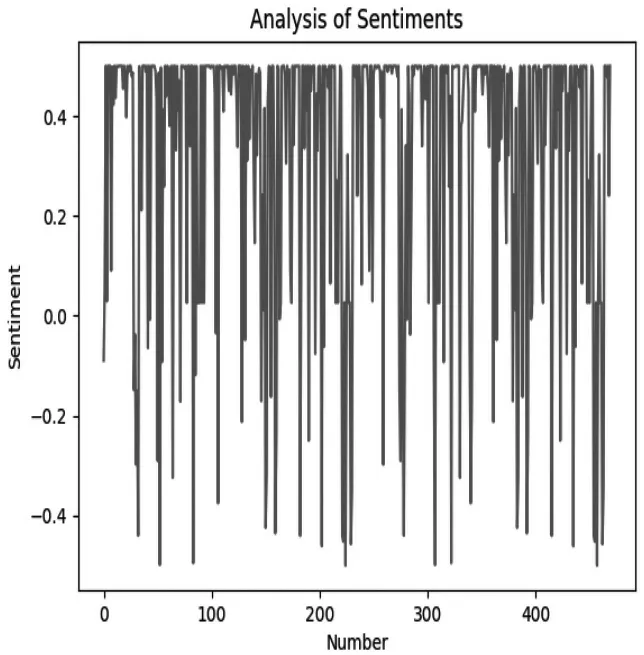
图5 情感分数波动曲线图
6 结语
大数据时代,人人是信息的缔造者也是使用者,越来越多的企业都尝试从数据中挖掘有价值的信息,来解决业务的问题。本文采用Python爬取数据,基于SnowNLP对影评数据进行情感分析,从而帮助用户更高效便捷地获取到有价值的信息,同时为媒体、电影市场、社交网站等提供口碑及相关服务的帮助,有一定的研究价值。本文对影评数据情感倾向性进行挖掘分析,由于SnowNLP库是基于商品评论训练好的模型,本次使用中没有重新训练数据,因此数据分析的准确率有待提高。下一步优化算法,训练好数据,提高数据分析的准确率。
猜你喜欢
小学生优秀作文(低年级)(2021年10期)2021-11-24 01:07:44
快乐作文(1.2年级)(2021年8期)2021-09-04 23:46:52
中学生博览(2021年9期)2021-05-18 11:28:20
科教新报(2021年10期)2021-05-17 03:47:01
文萃报·周五版(2021年9期)2021-03-15 06:11:46
世纪人物(2021年3期)2021-03-15 05:50:28
微型计算机·Geek(2021年2期)2021-03-12 03:39:50
智富时代(2019年6期)2019-07-24 10:33:16
高中生·天天向上(2016年9期)2016-11-22 09:10:34
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
