
基于机器学习的北京空气质量预测
2021-10-25 03:42:48何春旺
信息记录材料 2021年10期
刘 侠,何春旺
(江西软件职业技术大学 江西 南昌 330000)
1 引言
近10年来,随着整个中国工业化水平的不断提高,环境污染问题变得越来越严重,而空气质量的好坏更是其中最为重要的标准之一。PM2.5是指空气中直径小于或等于2.5 µm的固体颗粒或液滴[1]。PM2.5指标可以用来评价一个区域空气质量和环境的好坏,过高的浓度会危害人类的健康,所以近年来受到了各级政府与部门的关注。此次研究的目的就是通过实验比对寻找一个预测准确率、召回率、精确率较高预测模型,并对其进行调优。
2 数据分析
2.1 数据来源
UCI数据库是加州大学欧文分校(University of CaliforniaIrvine)提出的用于机器学习的数据库[2]。本次研究的数据是2013—2017年北京市周边12个站点的气象数据,各站点每天每1h检测1次数据。数据包含PM2.5浓度(µg/m3)、PM10浓度(µg/m3)、SO2浓度(µg/m3)、NO2浓度(µg/m3)、CO浓度 (µg/m3)、O3浓度 (µg/m3)、TEMP温度 (℃)、PRES气压(hPa)、DEWP露点温度 (℃)、rain降水量(mm)、Wd风向、WSPM风速(m/s)等多个空气指标,见表1。

表1 部分气像数据
2.2 数据分类
按PM2.5的值将空气质量分成优、良、轻度污染、中度污染、重度污染、严重污染6个等级,见表2。

表2 根据PM2.5进行分类表 单位:µg/m3
2.3 数据归一化
对于以上12项特征,单位不统一,数据量不在同一范围,无法将其与PM2.5进行比较。观察其与PM2.5之间的关系,需要将每项特征进行标准化处理,缩放至0~1范围,也叫归一化处理。常用的归一化处理的方法有minmax标准化方法以及z-score标准化方法两种[3]。本文采用min-max标准化,函数如下:
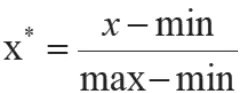
见表3,可以看到归一后,模型的各项指标均有提高。

表3 决策树预测PM2.5归一化前后对比 单位:%
2.4 特征分析
利用python的matplotlib工具库,取了500条数据,绘制了10幅线性图,可以较为直观地观察PM2.5数值与各个气象指标之间的关系,X轴是按时间顺序排好的编号,Y轴是各特征值。图1和图2中虚线代表PM2.5,实线代表其他特征。再使用pandas.corr()方法得到协方差矩阵,结果见表4。从图1、图2和相关系数表可以知,PM2.5与PM10、CO、NO2、SO2、DEWP、PRES正相关,与WSPM、O3、TEMP、RAIN负相关。

表4 各指标相关系数
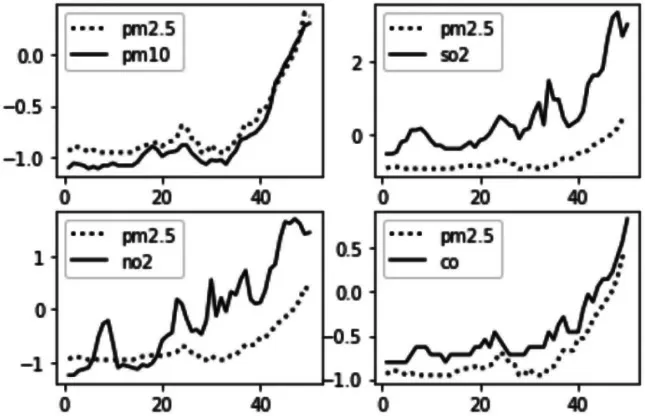
图1 PM2.5与PM10、SO2、NO2、CO的相关性

图2 PM2.5与O3、PRES、DEWP、RAIN、TEMP的相关性
3 研究方法
3.1 逻辑回归
Sigmoid函数在不同坐标尺下,当x为0时,函数值为0.5,随着x增大,函数的值无限接近于1;随着x的减小,函数的值无限接近于0,所有大于0.5的数据被分入1类,小于0.5的被归类为0类[4]。如图3所示,对于数据集(x1,x2,…,xn),其输出都可以映射到[0,1]区间进行分类。
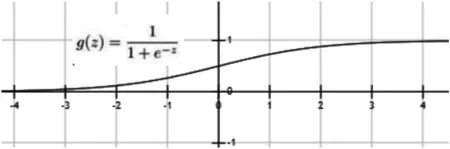
图3 Sigmoid函数
对于本文的PM2.5空气质量属于多分类问题,可以采用one-vs-rest方式。具体步骤如下:首先选用一个类型作为正样本,其他类型作为负样本,再计算出该类型的概率P1。其次,再选用另一个类型作为正样本,其他类型作为负样本,得到另一个类型的概率P2。重复上述步骤得到每个类型的概率Pi,取概率最大的那个类型作为预测的类型。
具体执行过程调用Sklearn中的LogisticRegression(),并将multi_class参数设置为ovr,使用分类方法one-vs-rest (ovr,一对多)。
3.2 决策树
决策树和二叉树一样,由节点和边组成,叶子节点代表一个类别,非叶子节点代表特征属性。从根节点开始,对每个特征进行判断,至直到叶子节点得到预测类型。决策树也可以看成是特征条件下类的概率分布;这个类的概率分布其实质就是在这个单元中的样本属于某一类的概率,这个概率通过训练得到;各子类的概率分布构成决策树的条件概率分布,见图4。
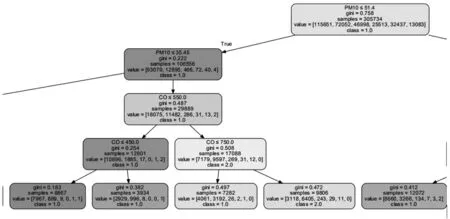
图4 PM2.5预设决策树部分
(1)选择最优特征:首先计算gini系数,挑选gini系数值最大的特征作为最优特征。
(2)决策树构造过程:按照最优特征将训练数据集分类成子集。然后递归向下处理子集,如果子集被正确分类,就继续构造叶子结点,将对应的数据分到各结点下;否则重新选择根结点,重复上面过程。递归至所有数据被正确分类,或者没有合适的特征为止。最后所有数据子集都有了自己的分类,就形成了一棵决策树。
(3)决 策 树 预 测:调用Skearn中的Decision-TreeClassifier(),设置参数max_depth,criterion,使用GridSearchCV查找最优参数,见表5。

表5 决策树参数
3.3 随机森林
3.3.1 简介
随机森林是将多棵决策树集成的学习方法,可以用来做分类与回归等问题。我们这里就是利用其做分类问题,通常它有较高的准确率,每棵决策树都作为分类器,N棵树就产生N个结果,随机森林集成了所有结果,将分类概率最高的一个类作为结果。
3.3.2 理论基础
随机森林使用决策树作为基分类器,采用Bagging方法生成相互差异的训练集,随机划分子空间构建决策树,从所有特征中随机选择部分特征,从该部分特征中选择最优特征进行分裂。这种随机划分子间和随机选择特征的思想能够让随机森林不容易陷入过拟合,每棵决策树之间存在多样性,所以随机森林具有优越的分类性能。随机森林的算法框架见图5。
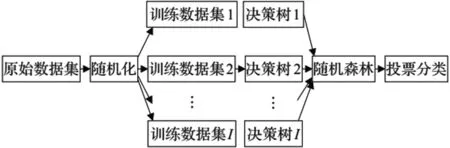
图5 随机森林算法框架
调用sklearn.ensemble中RandomForestClassifier进行预测分类,调整n_estimators,oob_score,random_state参数进行优化。
3.4 梯度提升决策树(GBDT)
GBDT是基于决策树的线性回归算法,与随机森林类似,由多棵决策树组成,处理结果为多棵决策树结果[5]。
梯度提升决策树算法即梯度加提升树,是一个加法模型,优化算法采用前向分步算法,基学习器使用回归树,每一棵回归树对上一棵树的残差进行拟合。假设训练集样本T=(x,y1),(x,y2),...,(x,ym),损失函数用L表示,最大迭代次数为T,输出得到强学习器f(x)。回归算法过程如下所示:
(1)先初始化弱学习器,c的值可以设置为样本y的均值f0(x)
(2)对样本i=1,2,3,...,m,计算负梯度
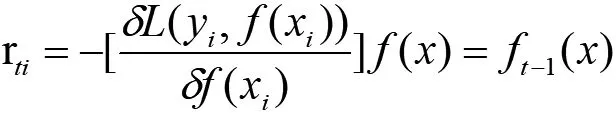
(3)利用(xi,rti),i=1,2,3,...,m,训练出一棵CART回归树,获得第t棵回归树,其对应的叶子节点区域Rti,J=1,2,3,...J。其中J为回归树的叶子节点个数。
(4)叶子区域j=1,2,3,...,m,计算出最佳似合值
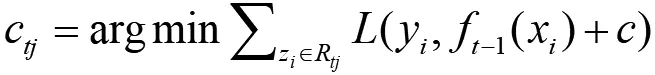
(5)更新强学习器
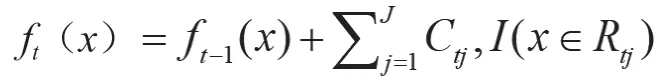
(6)得到强学习器f(x)表达式

执行过程使用sklearn中的RandomForestClassifier,并调整参数n_estimators、oob_score 和random_state进行优化。
3.5 极端梯度提升(XGBOOST)
XGBoost最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进提高了精度[6]。XGboost在多个方面进行了优化,其基学习器可以用CART也可以线性分类器。
极端极度提升就是不停地添加树,进行训练去拟合上次预测的残差。训练完成后得到n个决策树,每棵树根据样本的特征得到一个分数,每棵树的分数之和即预测值。
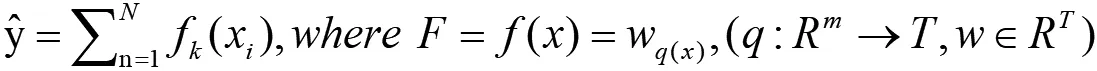
注:Wq(x)为叶子节点q的分数,f(x)为中其一个回归树,T表示叶子结点的个数,w表示叶子节点的分数。
步骤:第1步:增加一颗 CART树,使用贪婪算法构建树。第2步:求得损失函数的一阶和二阶导数值,利用导数计算出叶子节点的最佳权重W和节点分裂的最佳增益Gain。第3步:利用构建好的树再次进行预测分类。第4步:重新更新计算损失函数的一阶和二阶导数值。第5步:重复第1步,直到生成N颗树。
4 评价指标
本文使用TP(True Positive)、FP(False Positive)、FN(False Negative)和TN(True Negative)作为评价指标。如表6混淆矩阵表所示,TP为正样本被预测为正类的概率,FN为正样本被预测为负样本的概率,FP为负样本被预测为正样本的概率,TN为负样本被预测为负类的概率。

表6 混淆矩阵表
5 结论
(1)影响PM2.5的因素包括很多,其中SO2、NO2、CO和WSPM等对PM2.5的影响较大,经过数据分析发现,PM10、SO2、NO2、CO、DEWP与PM2.5的值成正相关,而O3、PRES、RIAN、WSPM都与PM2.5的值成负相关。其中,相关系数排序前8的因素为PM10、SO2、NO2、CO、WSPM、O3、TEMP、DEWP。
(2)经过实验对比,利用xgboost算法预测的北京空气的PM2.5的值的准确率为0.8 316,精确率为0.8 084,召回率为0.8 079,F值为0.8 077,与逻辑回归、决策树、随机森林、梯度提提升决策树、极端梯度提升相比,预测结果最接近实际值,各项指标得分最高见表7。
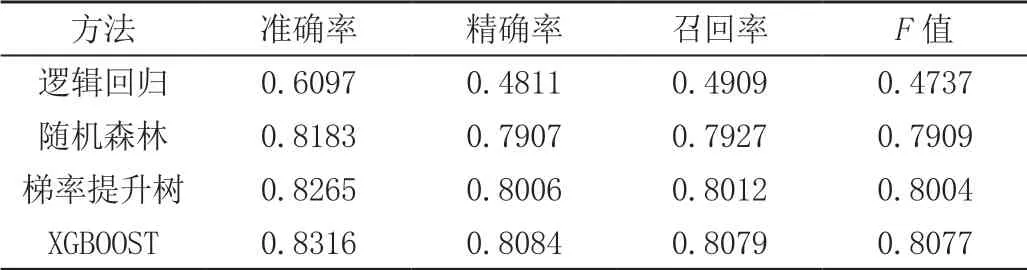
表7 实验结果 单位:%
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
小学生导刊(2018年34期)2018-12-18 01:53:26
电子制作(2018年16期)2018-09-26 03:27:06
小学生优秀作文(趣味阅读)(2018年6期)2018-09-19 06:37:38
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
海峡姐妹(2016年1期)2016-02-27 15:15:13
