
基于主题模型和词向量融合的微博文本主题聚类研究
2021-10-21 03:10颜端武梅喜瑞杨雄飞等
现代情报 2021年10期
颜端武 梅喜瑞 杨雄飞等

DOI:10.3969/j.issn.1008-0821.2021.10.008
[中图分类号]TP391;G203 [文献标识码]A
[文章编号]1008—0821(2021)10—0067—08
微博(Microblog)是根据用户关系实现信息内容传播、共享以及获取的在线社交媒体,是Web2.0技术产生的一种新兴社交网络形式,如国外的推特、国内的新浪微博。用户可以在微博平台上随时随地发布文字、图片、视频以及链接等信息,克服了传统媒介所带来的时间与空间的限制。微博并不是单纯的个人社交工具,而是网民发声的多元化信息平台,其内容涉及广泛,涵盖政治、经济、文化、娱乐、体育、民生等各个方面。目前,越来越多的网民参与到微博平台,以新浪微博为例,其2020年的第4季度财报显示,截至2020年12月,新浪微博的月活跃用户数已达5.21亿,平均日活跃用户数为2.25亿。微博平台具有用户规模大、用户活跃度高、信息类别多、信息传播和更新速度快等特点,极易在较短时间内产生海量数据,造成信息的爆炸式增长,给信息治理带来了巨大挑战。在信息化时代,传统的人工治理方式已经无法满足人们的需求,且微博数据口语化以及短文本特征也为微博信息的管理和利用带来了困难,因此,随着微博的发展和普及,微博内容挖掘引起了学术界的兴趣。
微博主题是对微博信息内容的概括,是微博文本挖掘的重要研究方向。一般而言,网民在微博上发表的言论具有较强的话题中心性,通过分析一定时间内的微博文本,可以掌握网民在该阶段所关注的信息主题。根据文本内容特征进行微博主题聚类,能够促进网络信息治理的效率提升,有助于政府部门掌握和解决民众诉求,有助于企业了解用户体验和危机公关。因此,如何准确高效地表达微博文本特征并进行微博主题聚类,已成为各界亟待解决的一个热点问题。
1相关工作
文本主题聚类是话题检测与跟踪TDT(Topic Detection and Tracking)的子任务,目前国内外关于文本主题聚类的方法主要有两种:文本主题建模和文本相似度聚类。
文本主题建模通常根据词汇出现在文档中的概率以及词汇之间的共现频率对文档集进行建模,它通过概率生成模型从而识别潜在语义信息并发现文本主题。2003年,Blei D M等提出的潜在狄利克雷(Latent Dirichlet Allocation,LDA)模型是使用最廣泛的概率主题模型,其经历了潜在语义索引(Latent Semantic Index,LSI)模型、概率潜在语义索引(Probabilistic Latent Semantic Index,PLSI)模型等阶段的发展,目前在文本挖掘领域已经逐渐走向成熟.且在长文本的主题识别中取得了不错的效果,但应用于微博文本数据时,由于短文本数据稀疏、共现信息匮乏等特性而导致主题聚焦性差,难以发挥LDA主题模型的功效。为了解决该问题,一些学者针对微博等短文本的特点,对标准LDA进行改进,如Twitter-LDA、Labeled-LDAE、BTM、MB-LDA、RT-LDA、mixtureLDA以及MB-HDP等。Zhao W X等在LDA的基础上引入推特用户信息,构建twitter-LDA模型并取得理想的结果。Ramage D等构建了一个半监督的Labeled-LDA模型。Yan X等将LDA的文档一主题层替换为共现词对从而构建BTM词对主题模型,解决了短文本数据稀疏问题。
文本相似度聚类的核心思想是“依据特定的标准将文档集划分为不同的簇,使得同簇中的文本相似度尽可能大,不同簇中的文本相似度尽可能小”,该方法属于无监督范畴。文本聚类主要有划分聚类、层次聚类、密度聚类以及网格聚类。文本向量表示对文本聚类效果至关重要,早期主要采用向量空间模型提取文本特征,通过One-Hot表示、TF-IDF等方法为特征词赋予权重。当采用向量空间模型进行短文本特征提取时,同一个词语在不同微博中出现的概率往往很小,从而造成很多特征项权重为0,即出现数据稀疏和高维度等问题,难以呈现好的聚类效果。一些学者尝试利用主题模型抽取文本特征向量,将文本从高维词向量空间映射到低维的语义空间,以解决数据高维稀疏问题。马雯雯等利用潜在语义分析LSA提取微博文本特征,通过CURE算法和K-means算法发现微博话题。路荣等以LDA主题模型构建推特数据的主题空间向量,利用K-means和层次聚类识别话题。史剑虹等通过文档—主题矩阵和K-means++算法进行微博短文本聚类。近年来,Word2Vec、CNN、RNN等神经网络模型相继被提出,也被用于文本特征的提取,这些方法受文本长度影响小,通过将文本训练为低维稠密的向量,生成文本的分布式表示。如张谦等、牛雪莹、马远浩等采用Word2Vec模型对短文本进行向量化表示,提取词汇的深层语义信息。
然而,单一模型提取的特征向量往往不能充分表征文本内容,需要结合其他模型构造融合特征,丰富特征向量语义信息。李海磊等通过Biter_VSM模型和LDA主题模型生成微博文本的融合特征向量,实验结果表明,融合特征比单一特征具有更好的聚类性能。Baker S等结合CNN和Word2Vec模型提取癌症数据集的特征并得到较好的分类效果。Word2Vec是训练词向量的常用模型,由其构建的文本向量实现了特征降维和上下文语义的表达,但缺乏全局语义信息,而LDA主题模型侧重文本集合整体语义特征的构建,因此,两种模型的结合可提高文本向量的表征能力。Moodv C E提出LDA2vec模型.通过词向量和文档向量之和创建上下文向量,预测上下文单词,从而获得可解释的主题。Niu L等、Liu Y等提出Topic2vec模型,构造词汇在特定主题下的词向量以及上下文环境中的词向量。王婷婷等利用Word2Vec模型将LDA主题一词汇分布矩阵转变为主题一词向量矩阵,采用自适应K-means聚类算法识别科技文献主题。聂维民等利用卷积神经网络对新闻数据进行分类,设计融合层机制将Word2Vec模型生成的字、词向量和LDA主题模型生成的词汇一主题向量融合为新的文本特征。
还有学者通过将短文本扩充为长文本来丰富文本的语义信息,实现主题聚类的效果提升。如Liu M、Yang Z等、Li X等采用外部知识库(如领域词典、维基百科等)進行短文本扩充;Hong L等、Mehrotra R等将推特文本合并为长文本进行LDA主题建模。
综上,主题聚类的优化提升主要涉及主题模型、文本向量和短文本扩充3个途径。其中,短文本扩充的方式过度依赖外部知识库,且操作复杂;改进的LDA主题模型往往具有特定的使用范围及局限,通用性不强。微博文本作为一种典型的短文本形式,在以往的微博聚类研究中对主题语义的针对性不够,聚类效果还有进一步提升空间。多特征融合是目前短文本主题聚类的新方向。本文综合运用LDA主题模型、Word2Vec词向量模型以及TF-IDF权重测算方式,提出文本浅层特征和词汇语义特征融合的微博文本主题聚类方法。该方法分别运用LDA主题模型、Word2Vec词向量模型提取微博的文本浅层特征和词汇语义特征,运用TF-IDF进行词向量的主题贡献权重测算,并通过向量拼接获得最终的融合特征,以解决短文本特征高维稀疏和语义缺失等问题。
2 LDA与词向量融合的主题聚类方法
2.1思路与流程
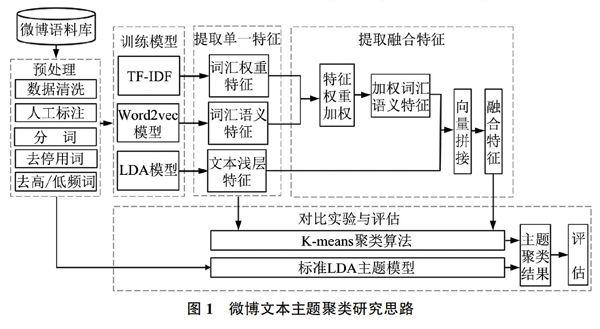
本文提出微博文本主题聚类方法,重点构建文本的融合特征向量,提高特征向量的文本表示能力。首先采集微博文本构建语料库,并对数据集进行清洗、人工标注、分词等预处理操作,然后从文本层面利用LDA主题模型提取主题向量.从词汇层面利用Word2Vec模型提取词向量,并利用TF-IDF计算词向量权重,进而构建微博短文本的融合特征,实现文本浅层特征和词汇语义特征的融合,最后通过K-means算法进行文本主题聚类。此外,本文构建4个对比实验(LDA+K-means、Word2Vec+K-means、TF-IDF+K-means、标准LDA主题模型)评估融合特征主题聚类方法的有效性。本文的研究框架如图1所示。
2.2微博文本收集及预处理
以新浪微博为数据源,通过Python的Scrapy开源爬虫框架和网页解析技术设计微博数据采集程序,并辅以新浪微博API,获得微博网页的数据信息,每条微博信息包括3个字段:微博ID、话题标签以及微博文本。获得微博原始数据后,通过预处理操作提高数据的可靠性和有效性,主要包括以下5个步骤:
1)数据清洗:人工剔除无用、重复数据;去除非中文数据以及图片等多媒体信息。
2)明确“主题标签”:在实验过程中需要对主题聚类的结果进行评估,因此,每条微博文本在实验前都要具备明确的主题标签。本文通过3位专家分析微博内容,并结合新浪微博自定义的话题标签,进行人工标注与审核。
3)分词:利用哈尔滨工业大学的开源中文分词工具LTP对微博文本进行分词。
4)去停用词:根据停用词表去除“转发”“@”等停用词。
5)去高/低频词:去除词频为1的低频词,人工去除无意义的高频词,从而降低文本特征维度。
2.3 LDA与词向量融合的微博文本表示模型
2.3.1利用LDA主题模型进行文本浅层特征提取
LDA主题模型是三层贝叶斯概率模型,该模型认为文档是主题的概率分布,而主题是词汇的概率分布。基于该思想,模型从文档—主题、主题—词汇两个方面建模,描述文档、词汇以及主题三层结构之间的生成关系,如图2所示。
其中,M表示语料库的微博数量,N表示每条微博的词汇量,α、β分别服从狄利克雷分布。LDA主题模型是文档生成的逆过程,对于微博D,从先验概率分布抽样产生其在主题上的概率分布θ,并根据文档一主题分布采样获得微博D中第k个词汇的主题z;对于主题z,从先验概率分布β抽样产生其词汇分布φ,并根据主题一词汇分布φ抽样生成词汇w。
LDA对语料库中的所有文本进行主题建模,根据文档、主题、词汇三者之间的概率分布关系,可以通过词汇共现信息和概率值的估计发现文本的主题分布特征,从而发现文本的全局语义信息和特征表达。但模型在训练数据时将文档中的词汇视为相互独立,忽略了上下文词汇之间的语义关联,因而本质上是对文本特征的浅层表达。本文采用LDA模型的文档—主题分布来表征微博短文本的主题倾向性和全局语义。对于微博文本D,其文档—主题特征表示如下:
其中,lt表示微博D在第t个主题下的概率,t为向量的维度。
2.3.2利用Word2Vec模型进行词汇语义特征提取
Word2Vec词向量模型是Mikolov T等于2013年提出的具有“输入层—隐藏层—输出层”的三层神经网络模型,主要用于文本词向量学习,有CBOW和Skip-gram两种学习方式。如图3所示,w(t)为目标词,其上下文词汇为w(t-r)、w(t-r+1)、…、w(t-1)、w(t+1)、…、w(t+r-1)、w(t+r)。CBOW模型根据目标词的上下文预测目标词,而Skip-gram模型则根据目标词预测目标词的上下文。
与LDA主题模型侧重于文本集合的特征表达不同,Word2Vec模型通过将词汇量化为低维空间中的稠密实值向量,从而实现文本词汇的特征表达。Word2Vec模型生成的词汇特征向量包含了邻近词汇的语义关联,可弥补短文本环境下特征表达的词汇语义缺失。微博作为短文本,每条微博的词汇量少,目标词汇的上下文语义信息缺失明显,故本文选取Word2Vec模型的Skip-gram学习模式进行微博语料集的词向量生成。在此基础上,针对微博文本D中的词汇进行词向量映射,从而将该微博的文本特征表示为:
其中,第k行表示微博D中词汇wk所对应的词向量,t为词向量的维度。
2.3.3文本浅层特征和词汇语义特征融合
1)词汇语义特征权重计算
Word2Vec模型未体现词汇对主题的贡献度,导致非关键词汇影响特征语义表达,可通过TF-IDF值对Word2Vec词向量加权,提高词向量对主题的区分能力。微博D中词汇的权重特征如下所示:
其中,tfidfk表示詞汇wk在躯干D中的权重,即其TF-IDF值。TF-IDF值越高,则词汇的重要性越强。
本文将词向量与其对应的TF-IDF值相乘,得到微博D的加权词汇语义特征向量AT:
2)特征向量拼接
LDA主题模型和Word2Vec模型在向量化表达微博短文本时,都有各自的侧重点:LDA的主题分布向量虽然可以从全局描述文本特征,但词袋模型的特点导致无法挖掘深层语义信息;Word2Vec模型能够深入了解序列词汇之间的语义关联,但只关注一定范围的邻近词汇关系,可能导致全局信息的缺失。因此,本文将LDA的文档主题分布向量和文本加权词向量纵向拼接,形成融合特征向量ATL:
在维度层面,低维稠密的文本加权词向量AT和文档主题分布向量L纵向拼接后仍然是低维稠密向量,解决了短文本数据高维稀疏问题;在语义层面,向量拼接后的融合特征既包含文本全局语义,又包含词汇顺序信息和深层语义关联信息,词向量加权使得噪音词汇的干扰降低。以融合特征表征文本,弥补LDA和词向量两者的缺点,丰富了短文本向量的语义信息。
K-means聚类算法简单有效,计算的时间复杂度低,能够快速处理大规模数据集。本文通过K-means算法对微博文本的特征向量进行主题聚类,将内容相近的文本聚为一个簇,每个簇表征一个微博主题。
3实验对比及结果分析
本文生成4种微博短文本特征向量:LDA文档一主题向量、Word2Vec词向量、TF-IDF权重向量以及融合特征向量,利用特征聚类和标准LDA主题模型进行微博主题聚类的对比实验。
3.1实验环境和数据准备
实验环境为2.5GHZ的CPU、8G内存以及64位Windows10专业版操作系统,开发工具为PyC-harm 2017。
从新浪微博采集2019年6月份具有代表性的热点话题作为原始语料库,包括“高考成绩”“中国拟立密码法”“养老金上调”“重庆交通事故”“信用惩戒”等44个话题,累计6万条微博。预处理后,共获得48212条微博数据。
3.2评估指标
模型效果的优劣常采用精确率P、召回率R以及F1值3个标准进行评估,其值越高,则模型效果越好。
精确率又称查准率,指预测为主题i的微博中实际主题为i的比例。
召回率又称查全率,指实际主题为i的微博中被预测为主题i的微博比例。
本文采用综合评价指标F1值衡量模型的主题聚类效果。首先,分别计算每个主题的精确率和召回率,再利用宏平均求得整个模型的精确率和召回率,最后求得模型的F1值。
3.3特征提取模型参数设定
Word2Vec词向量模型的窗口大小设置为5,向量维度t为100维,对于没有出现在该词向量中的词汇,其向量会被随机初始化。LDA主题模型中,主题维度t设置为100,与Word2Vec词向量维度保持一致,以便于特征的融合,α=50/主题维度t,β=0.001,Gibbs抽样2 000次。
3.4主题聚类算法参数设定
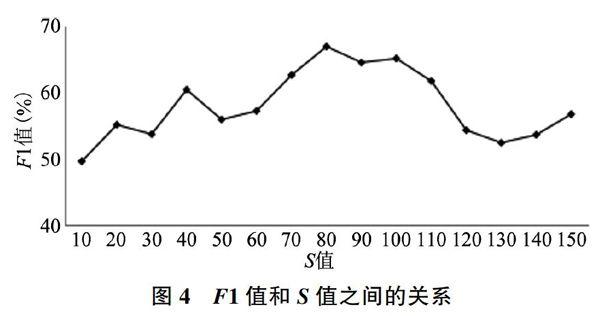
K-means聚类算法和LDA主题模型在训练数据前要明确最佳的聚类主题数S。K-means聚类算法的S值设置为语料库主题标签类别数目44。对于LDA主题模型,采用交叉验证法选择最优主题数,令S分别取10、20、30、40……130、140、150等值,在不同S值下训练LDA主题模型,观察模型F1值的变化,如图4所示。选取最优F1值的主题数,故本文将LDA主题参数设置为80。
3.5对比实验与分析
针对微博短文本,分别通过LDA主题模型、Word2Vec词向量模型以及TF-IDF权重测算方式构建不同方法下的文本特征向量,按照式(5)生成微博文本融合特征。采用十折交叉验证法对数据集进行训练和测试,对于K-means算法,分别对以上4种文本特征向量进行主题聚类,F1值为69.2%、78.8%、74.0%和83.7%;对于标准LDA主题模型,F1值为64.5%。实验对比结果如表1所示。
1)LDA+K-means主题聚类和标准LDA主题聚类的精确率、召回率以及F1值都较低。LDA模型将文本映射到低维语义空间提取文本浅层特征,虽然对微博文本数据进行降维处理,但短文本共现信息匮乏而无法完整表达文本全局语义信息,且基于“词袋模型”理论,忽视文本词汇的序列性,所以仅用LDA主题模型对微博短文本进行特征抽取难以充分发挥作用,不适合微博短文本的建模。
2)Word2Vec通过模型训练将每个词汇简化为向量空间中的一个t维稠密词向量,与传统向量空间模型相比,Word2Vec模型构造的文本特征向量实现了高效降维。此外,Word2Vec词向量描述了词汇之间的关联关系,因为是对词汇的向量化,和基于共现信息的LDA主题模型相比,语义表达受文本长度影响小,性能优于LDA主题模型,但未考虑文档的全局语义信息和不同词汇主题贡献程度的差别,在精确率、召回率以及F1值3个方面和融合特征有一定的差距。
3)TF-IDF计算词汇权重信息构建文本特征向量,因同一词汇出现在不同微博短文本中的概率较低,导致大量的特征权重为0,造成短文本向量的高维稀疏性,且没有考虑文本潜在语义信息,使得主题聚类的效果下降。
4)融合特征+K-means主题聚类效果最好,精确率、召回率以及F1值均高于其他模型,达80%以上。融合特征一定程度上克服了微博短文本高维稀疏和语义缺失问题,能更加准确、全面地表征微博文本信息。低维稠密词向量和低维语义空间向量的拼接并未造成特征维度的大量增加,融合特征包含了文本全局语义信息和词汇深层语义信息,同时,词向量TF-IDF加权也提升了主题聚类的准确率。
融合特征主题聚类结果如表2所示。对于主题明确的微博文本,如“高考成绩”“中国拟立密码法”等,准确率可达90%左右。但对于主题较为相似的文本,实验结果出现较大偏差,如“重庆公交事故”和“别碰司机”,因两者都为交通事故、交通规则方面的主题,常涉及“公交”“司机”“安全”等词汇,且部分网民习惯将两者联系起来阐述自己的观点,所以在主题聚类过程中出现混淆,但该误差在合理范围内。
4结论与展望
本文基于新浪微博短文本数据,首先提出数据采集以及预处理方法,然后综合考虑微博的文本浅层特征和词汇语义特征两个方面,结合LDA主题模型的文档一主题分布特征和加权Word2Vec词向量设计文本的融合特征表达公式,并通过K-means算法对文本进行主题聚类实验。在对比实验中,与单一特征主题聚类、标准LDA主题聚类进行比较,从精确率、召回率和F1值评估主题聚类方法,实验结果表明,融合特征在解决微博上下文语义缺失和数据稀疏高维等问题方面具有较好的效果。
本文为微博主题聚类研究提供了一种新思路,但存在局限和不足之处。其一,实验数据主要针对微博文本数据,对微博信息中的图片、音频、视频等多媒体数据类型未能考虑;其二,实验对比着重分析单一特征和TF-IDF+Word2Vec+LDA融合特征的主题聚类效果,对于单一特征不同组合方式下的特征融合主题聚类及其优化涉及不够。因此,如何针对多模态微博数据进行特征融合处理、如何优化特征提取和主题聚类算法,在后续研究中还有待进一步拓展和深入。
(责任编辑:郭沫含)
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19
开放教育研究(2020年2期)2020-03-31
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
小学生作文·小学低年级适用(2018年12期)2018-04-11
现代语文(2016年21期)2016-05-25
校园英语·下旬(2016年2期)2016-03-18
大连民族大学学报(2015年2期)2015-02-27
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
