
基于情感分析的突发公共卫生事件网络舆情热度预测模型仿真
2021-10-21 17:50牟冬梅靳春妍邵琦
现代情报 2021年10期
牟冬梅 靳春妍 邵琦

DOI:10 3969/j.issn.1008-0821.2021.10.007
[中图分类号]G202 [文献标识码]A [文章编号]1008—0821(2021)10—0059—08
社交网络的重要载体“三微一端”承载了公众情感表达及舆论传播的重要功能。由于突发公共卫生事件涉及公众的健康和生命安全问题,公众对此类信息更为敏感、关注度更高,所以在突发公共卫生事件发生后,真假难辨的信息极易加剧公众的恐慌形成持续发酵的网络舆情。近年来,突发公共卫生事件网络舆情频频发生,突发公共卫生事件也成为网络舆情研究的焦点之一。
网络舆情研究的关注对象通常为公共事件领域的新闻及其评论以及电子商务领域的产品或服务评论,其主要研究内容是对关注对象的文本内容、行为属性、形成机理、传播规律等进行深入分析。舆情预测是实现网络舆情监控的重要环节,对于网络舆情分析具有重要的意义,也是网络舆情领域的重要组成部分。网络舆情在大量的网络数据之中具有延续性、交互性和演化性,有一定的可预测性。网络舆情在短时间内会大规模、快速地扩散,从风险的社会放大理论看,如果突发公共卫生事件网络舆情处理不当,容易诱发民众的不良情绪,导致涟漪效应,引爆舆情危机。建立合适的预测模型来仿真网络舆情的热度,相关部门就可以尽快掌握社情民意,及时发现工作中存在的不足和对问题矛盾出现的影响,对负面声音进行正确引导,这对于政府相关部门有效监管网络舆情、维护社会稳定具有一定的重要意义。突发公共卫生事件网络舆情的发生,往往是因为公众对舆情趋势的未知而造成恐慌蔓延,安全感缺失更加重公众的焦虑恐慌情绪,用户在网络平台上通过情感词充分表达自身的情感,又由于网络舆情的否定多于肯定,激情压倒理性的特征,负面的情感推动舆情不断发酵,加剧了突发公共卫生事件网络舆情的监管难度。
因此,本研究将情感因素引入网络舆情热度预测依据之中,针对突发公共卫生事件构建网络舆情热度预测模型并进行仿真。研究将解决以下两个问题:①构建基于情感分析的突发公共卫生事件网络舆情热度预测模型,以期优化突发公共卫生事件网络舆情热度的预测效果;②在理论模型的指导下,以“×××疫苗造假”事件为例进行模型仿真,验证理论模型的有效性和可行性,评价加入情感值的网络舆情热度预测效果。
1相关研究
目前,国内外学者对网络舆情预测的研究大多采用的是时间序列分析或者灰色理论。舆情预测与时间序列分析相结合的研究方法,一种是利用历史网络舆情热度来进行网络舆情预测,历史网络舆情热度的测量多选择百度指数、发文量等;另一种是针对网民的各类情感倾向性伴随时间的转移所发生的变化来进行研究的。梳理舆情预测与灰色理论相结合的研究成果发现,一种是仅通过舆情方面的单一观测值来实现网络舆情的预测研究;另一种是利用多种网络舆情观测值来实现网络舆情的预测研究。张和平等选用百度指数作为舆情热度的衡量指标,利用马尔可夫修正灰色模型的预测结果。王宁等分别以微指数、百度指数、头条指数作为事件热度的衡量指标,运用灰色模型实现预测并运用灰色关联分析方法提出网络舆情事件分级方案,还有学者选取多个指标数据建立多因素灰色模型,并利用BP神经网络对多因素灰色模型的预测残差进行修正,实现网络舆情的精确预测。
网络舆情预测的方法还包括Logistic模型、模糊综合评价法、马尔科夫链、BP神经网络、组合预测等。有学者基于灰色关联度方法构建网络舆情热度模型,并在此基础上构建多维度Logistic模型对各个媒体平台舆情信息开展预测。Chen X G等采用粗糙集理论筛选舆情指标体系,通过层次分析法确定指标权重,引入模糊综合评价法预测和评估舆情发展趋势。刘勘等采用马尔科夫链对网络舆情热度进行预测,结果表明,建模方法和预测算法是有效的。曾子明等在構建微博舆情热度评价指标体系的基础之上,建立了基于BP神经网络的突发传染病舆情热度趋势预测模型。还有学者将常用的Logistic模型、指数平滑法模型和灰色模型结合在一起,通过层次分析法进行权重赋值后得到最优化网络舆情数据的预测值。
对近年来国内外相关文献进行梳理,发现目前国内外学者的网络舆情预测研究尚处于探索阶段,已有的舆情预测研究多采用时间序列分析或者是灰色理论来实现研究目的。网络舆情热度预测是网络舆情预测的子类。网络舆情预测不仅包括网络舆情热度预测,还包括话题演化预测、观点预测等。在网络舆情热度预测的相关研究中,鲜有研究人员在网络舆情热度预测模型仿真中引入情感因素。鉴于突发公共卫生事件的影响力大、危害程度高、更容易使网络舆情发酵,结合上文所述,考虑到网民情感对网络舆情传播的影响作用,纳入情感因素不仅能够从理论上优化舆情热度预测模型的精准度,也具有一定的现实意义,为舆情应对及监测提供管控依据。因此,本研究将情感因素引入网络舆情热度预测之中,针对突发公共卫生事件,实现基于情感分析的网络舆情热度预测模型仿真。
2突发公共卫生事件网络舆情热度预测模型的构建
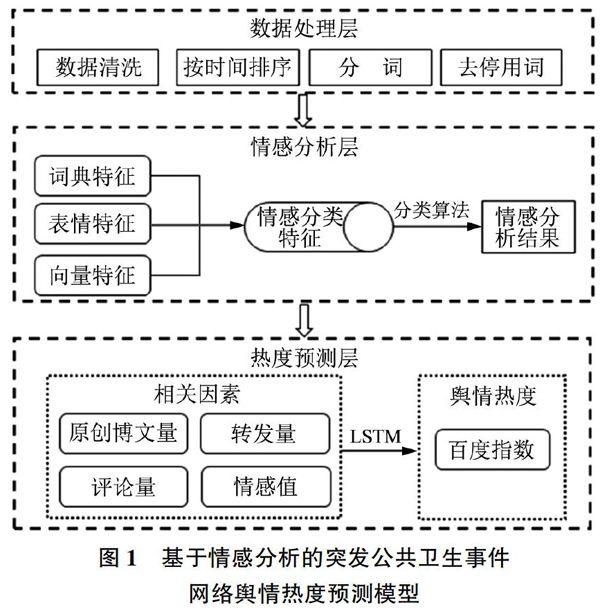
本研究提出的基于情感分析的突发公共卫生事件网络舆情热度预测模型包括数据处理层、情感分析层、热度预测层3个层级,各层级之间逐层递进,基于数据预处理获得文本数据的结构化语料集,基于多特征融合的情感分析方法获得情感倾向,基于多元时间序列分析进行舆情热度预测。数据的预处理部分包括数据清洗、按时间排序、分词、去停用词4个步骤,从而获得结构化的语料集。将数据处理层的结构化数据作为情感分析层的输入数据,情感分析层采用多特征融合情感分析方法,获得词典特征、表情特征、向量特征后融合成为情感分类特征,再利用机器分类算法得到情感倾向作为情感分析结果。在热度预测层,将情感值及原创博文量、转发量、评论量作为相关因素,百度指数作为输出序列,利用LSTM实现突发公共卫生事件网络舆情热度预测。所构建的理论模型如图1所示。
2.1数据处理层
数据的预处理是突发公共卫生事件网络舆情热度预测模型的基础,对原始数据进行预处理可以将以自然语言书写的博文转化为方便机器学习方法识别的形式,同时也利于后续各类时间序列数据的建立。本研究所构建的突发公共卫生事件网络舆情热度预测模型的预处理部分包括以下步骤:①数据清洗环节包括删除非原创的微博数据和博文噪声,博文噪声是指网址链接、标签、特殊符号(“$”“#”“@”……)等;②将所有的原创微博数据按照时间进行排序;③使用Jieba分词脚本对原创博文进行分词;④对原创博文去停用词。
2.2情感分析层
本研究的创新点就是在突发公共卫生事件网络舆情热度预测中加入情感倾向,因此情感分析方法的有效性对网络舆情热度预测来说必不可少。而《融入表情特征的网络舆情情感分析方法研究》一文中所提出的网络舆情情感分析方法是对以往方法的改良,所以本研究在突发公共卫生事件网络舆情热度预测模型中的情感分析部分采用了融入表情特征的网络舆情情感分析方法。该舆情情感分析方法是在词典特征和向量特征的基础之上融入表情特征,通过表情特征对情感的浓缩表达提升舆情表述中潜在情感的挖掘能力。在关注单一文本信息的同时还考虑了重要的情感线索——表情符号所具有的强烈情感表达能力对于情感倾向判断的影响,而且避免了文字表述与表情符号的情感歧义问题,提高了网络舆情情感分析效果。
融入表情特征的网络舆情情感分析方法分3个步骤:①抽取文本的情感词、修饰词、语气词和标点符号,按照一定的规则进行组合计算来提取词典特征;在构建表情符号集的基础上,考虑积极表情、消极表情、中性表情的数量来获取表情特征;选择Doc2vec作为提取向量特征的手段;②将词典特征、表情特征、向量特征进行融合,得到情感分类特征;③将情感分类特征作为分类器的输入,获得文本的情感分析结果。本研究利用融入表情特征的网络舆情情感分析方法获得所有原创微博数据的情感分析結果后,把情感分析结果作为舆情热度预测部分中情感值的来源。
2.3热度预测层
屈启兴等、陈福集等、曾子明等研究者在进行网络舆情预测时都把博文量、转发量、评论量作为舆情热度的影响因素,研究者们普遍认为民众对于网络舆情的关注程度可以通过发文、评论与转载等方式来体现,原创博文量可以测度话题的曝光度,转发量、评论量则是从受众视角来反映舆情热度。情感倾向作为社会属性的一种,对突发公共卫生事件网络舆情的传播有重要的影响作用,所以本研究也考虑了原创博文量、转发量、评论量,并在此基础上加入情感值来作为舆情热度的相关因素。百度指数是统计网民在百度上针对关键词的搜索量,通过科学分析并计算关键词在百度上搜索量的加权而获得,反映网民的主动搜索量和某一类事件受网民的关注程度,由于其在搜索引擎产品中极高的市场占有率及数据的可获得性,受到学者们的广泛关注。因此,本研究选取百度指数作为网络舆情热度的衡量指标。
多元时间序列分析指对多变量时间序列的研究,是一种将多元回归分析与时间序列分析相结合的方法。LSTM属于多元时间序列分析的一种实现方式,它是RNN的变体,内部更为复杂,能够处理长时依赖问题,其相比于RNN主要进行了两个改进:一是在记忆状态的基础上加入了新的内部状态——单元状态,让它来储存较长时期的记忆;二是引入了门限机制来控制信息流动。也就是说,LSTM的结构中不但包含了RNN中所涉及的隐含层单元之间的外循环,而且包含了神经元内部的自循环。针对序列数据而言,LSTM的优势在于一方面可以提高模型的收敛速度;另一方面由于门限机制的存在可以促使模型避免局部最优朝正确的方向进行收敛,因此适用于序列数据的分类、处理和预测。所以,选择LSTM来实现突发公共卫生事件网络舆情热度的预测。
LSTM内部隐含层由“遗忘门”“输入门”“输出门”和记忆单元构成,使用“门”来有选择地控制信息的流动。当前时刻的输入数据xt和上一时刻隐含层的输出ht-1依次流向“遗忘门”“输入门”和“输出门”,通过使用激活函数将数据映射到0~1得到隐含层的输出ht。“遗忘门”的表达式见式(1),“输入门”的表达式见式(2),“输出门”的表达式见式(3)。
3实验及结果分析
3.1数据预处理
在百度指数官网获取某突发公共卫生事件“×××疫苗造假”2018年7月15日—2018年10月31日的百度指数,形成百度指数时间序列作为预测模型的输出序列。以新浪微博作为网络舆情数据的获取渠道,利用Python自编网络爬虫得到新浪微博上该事件2018年7月15日—2018年10月31日的相关微博,部分原始数据如图2所示。获得的原始数据经过数据清洗、按时间排序、分词、去停用词的预处理后,剩余87860条原创博文。计算该事件对应时间段内的原创博文量、转发量、评论量分别形成原创博文量时间序列、转发量时间序列、评论量时间序列。
3.2网络舆情情感分析
词典特征规则模板的输入为微博文本集合M,输出为每条文本的词典特征。词典特征的具体构建方式包括如下步骤:
1)读取文本数据,对每条文本进行分句。
2)查找每个分句中的词语,若该词在积极词典中出现,则赋值为“+1”,若在消极词典中出现,则赋值为“-1”,没有出现,则赋值为“0”。
3)在程度级别词词典、否定词词典中比对修饰词,若在情感词前出现则赋予对应的权值。
4)在语气词词典中比对语气词,若出现则赋予相应的权值,没有出现则赋值为“0”。
5)标点符号按照标点符号词典给予对应的权值。
6)将情感词和修饰词的分数相乘,再对句子中依存关系的分数进行累加,然后乘以语气词和标点符号的权值。累加各分句的情感倾向分数,最终得到该博文的词典特征,记为SCOl'e,如式(4)所示。
其中,n是微博文本集合M中某个博文包含的分句数,m是句子包含的依存关系数,basescore是情感词的基本分值(+1、-1或0),modifiers是句i的程度词权重或否定词权值,mood是语气词权值,punctuation是标点符号权值。
以人工选择的方式筛选新浪微博平台的169个常用表情符号,构建表情符号集。将筛选后的表情符号划分为积极、消极、中性3种类型。表情特征使用三维特征[e1,e2,e3]表示,3个维度从左到右分别对应积极表情个数、消极表情个数、中性表情个数。
Doc2vec包括Distributed Memory(DM)、Dis-tributed Bag-of-Words(DBOW)两种方式。由于DBOW在训练中只需要存储Softmax参数,更加节省存储空间。所以,选择DBOW作为获得向量特征的方式。利用Python中的Gensim库提取向量特征,经过反复试验,维度设置为200维时效果最佳。
相关领域的现有研究中大多使用拼接的方式实现多特征融合,所以本研究亦采用拼接的方式将词典特征、表情特征、向量特征融合后得到情感分类特征,情感分类特征=[词典特征+表情特征+向量特征]。选择One-Versus-One SVM作为分类方法,核函数选用高斯核函数来实现网络舆情的情感三分类。
情感分析方法的有效性为网络舆情热度预测的顺利开展奠定基础。经过上述过程,得到尚未进行情感标注的79860条原创博文的情感分析结果。接着在对应时间段内对原创博文的情感倾向取绝对值后进行累加得到情感值,形成情感值时间序列,用情感值来代表对应时间段微博网民对该事件的整体情感倾向。
3.3网络舆情热度预测
3.3.1序列平稳性检查及评价指标
研究采用多元时间序列分析方法进行舆情热度的预测,多元时间序列分析的各个时间序列必须满足以下两个条件之一:①输入序列和输出序列均平稳;②虽然序列非平稳,但是具有协整关系。平稳序列必须满足3点要求:第一个要求为整体序列的均值保持不变,是一个与时间无关的常数。即随时间的发展,数据在均值范围内上下波动;第二个要求是方差与时间无关。即意味着数据在围绕均值上下波动的范围是相同的;第三个要求是协方差只与时间间隔相关,而与具体的时间点无关。即数据随着时间波动的两个波峰或者波谷之间的距离是相等的。序列的平稳性检查包括时序图检验、偏相关函数图与自相关函数图检验、单位根检验3种方式,单位根检验又可分为DF检验、ADF检验、PP检验。协整检验方法包括EG检验和Johansen检验。本研究选用被广泛使用的ADF检验对序列数据的平稳性进行检查,通过Eviews软件来实现。若Eviews软件的结果中P值小于0.05且t值为负值,则该时间序列为平稳时间序列数据。
根据本研究的数据量按照8:2划分训练集和测试集。为了评价模型的拟合效果,以及方便将预测结果与现实数据做量化比较,本文引入了两种评价指标,分别是均方根误差(Root Mean Square Er-roy,RMSE)和平均绝对百分比误差(Mean Abso-lute Percentage Error,MAPE)。RMSE指的是预测值与真实值偏差的平方与观测次数N比值的平方根,其計算方式见式(5)。MAPE指的是偏差与真实值比值的平均绝对值百分数,其计算方式见式(6)。同种误差的误差值越小就表示预测值与真实值的差值越小,模型的预测效果越好。
分别对百度指数时间序列、原创博文量时间序列、转发量时间序列、评论量时间序列和情感值时间序列进行平稳性检查,ADF检验的结果如表1所示。如表1所示,百度指数时间序列、原创博文量时间序列、转发量时间序列、评论量时间序列和情感值时间序列的p值都小于0.05且1%、5%、10%置信区间均为负值,因此这5个序列都是平稳时间序列数据。
3.3.2预测模型仿真结果
对经过平稳性检验后的各个时间序列数据进行Min-max标准化方式处理后,采用LSTM进行多元时间序列分析,从而实现突发公共卫生事件网络舆情热度预测。在时间窗口的选择方面,部分进行网络舆情预测研究的学者们选择的最长滞后范围为4~6天。因此,本研究的时间窗口选择为滞后1~5天。图3展示了滞后1天时的真实值与预测值,图4展示了滞后2天时的真实值与预测值,图5展示了滞后3天时的真实值与预测值,图6展示了滞后4天时的真实值与预测值,图7展示了滞后5天时的真实值与预测值。
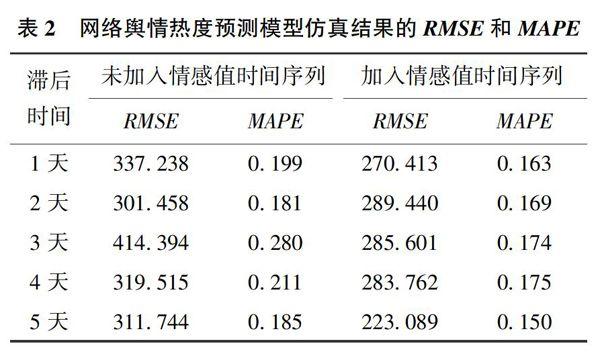
网络舆情热度预测模型仿真结果的RMSE和MAPE如表2所示。表2显示,滞后1天时,加入情感值的网络舆情热度预测模型RMSE为270.413、MAPE为0.163,均低于未加入情感值的网络舆情热度预测模型;滞后2天时,加入情感值的网络舆情热度预测模型RMSE为289.440、MAPE为0.169,均低于未加入情感值的网络舆情热度预测模型;滞后3天时,加入情感值的网络舆情热度预测模型RMSE为285.601、MAPE为n 174,均低于未加入情感值的网络舆情热度预测模型;滞后4天时,加入情感值的网络舆情热度预测模型RMSE为283.762、MAPE为0.175,均低于未加入情感值的网络舆情热度预测模型;滞后5天时,加入情感值的网络舆情热度预测模型RMSE为223.089、MAPE为0.150,均低于未加人情感值的网络舆情热度预测模型。可见,无论时间窗口选择的滞后天数是哪种情况,加入情感值的网络舆情热度预测模型效果优于未加入情感值的网络舆情热度预测模型,且时间窗口选择的滞后天数为5天时加入情感值的网络舆情热度预测效果最好。因此,将情感因素引入突发公共卫生事件网络舆情热度预测之中可以显著提高其预测效果。
4结论与展望
本研究的目的是突发公共卫生事件网络舆情热度预测,而较少有研究人员将网民情感引入网络舆情热度预测之中,因此确立了基于情感分析进行突发公共卫生事件网络舆情热度预测的研究主题。在研究设计中,以大多数学者选用的百度指数作为网络舆情热度衡量指标,在考虑了网络用户的原创博文量、转发量、评论量等网络舆情热度相关因素之外,增加情感因素,利用多个指标更为全面地实现突发公共卫生事件网络舆情热度预测。获得情感倾向时,采用了融入表情特征的网络舆情情感分析方法。本研究的模型仿真结果也显示了情感因素对于突发公共卫生事件网络舆情热度预测的重要性。
本研究提出了基于情感分析的突发公共卫生事件网络舆情热度预测模型,并选取某一突发公共卫生事件的新浪微博数据进行预测模型仿真。虽然在研究思路和方法上有了一些创新性,但由于时间因素以及现实条件的限制,研究仍然存在着一定的不足之处:仅选择了单一突发公共卫生事件。未来可选择更多的突发公共卫生事件进行实证研究,以验证基于情感分析的突发公共卫生事件网络舆情热度预测模型的普适性。
基于情感分析的突发公共卫生事件网络舆情热度预测模型为舆情监管部门的工作提供了新思路。网民通过网络针对突发公共卫生事件发表自己观点的过程中产生大量具有感情色彩的文本信息,体现出的情感倾向展现网民所持的态度。突发公共卫生事件网络舆情的监管中,要考虑到网民情感对网络舆情传播的影响作用,充分了解网民的态度和意见,将情感因素纳入网络舆情热度预测依据之中。同时也要注意网民情感的疏导,定位网民负面情绪的根源,及时准确地发布事件相关的各种信息,以公开透明的方式解答网民的质疑,消除焦虑与恐慌,避免引爆舆情危机。
(责任编辑:孙国雷)
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
首都公共卫生(2019年5期)2019-02-12
首都公共卫生(2017年1期)2017-11-29
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
中国卫生(2014年3期)2014-11-12
中国卫生(2014年11期)2014-11-12
