
智轨列车基于稀疏点云和图像的车辆识别技术
2021-10-20 01:00罗意平宇文天万政良刘斯斯
铁道科学与工程学报 2021年9期
罗意平,宇文天,万政良,刘斯斯
(中南大学 交通运输工程学院,湖南 长沙 410075)
株洲电力机车研究所自主研发的智轨列车运行模式采取了“虚拟轨道跟随控制”技术[1],通过识别虚拟车道线来规划行车路径,可与其他车辆共享虚拟车道。但智轨列车速度快、车体长,在40 km/h 行车速度下制动距离约为14 m,当其他车辆误入虚拟轨道时易发生连环交通事故。针对以上问题,需采用车辆识别技术作为智能驾驶辅助功能,检测前方车辆的三维信息,用于防撞预警和智能驾驶的数据支撑。在常用的三维检测方法中,以激光雷达点云作为输入数据,通过人为规定目标点云的特征进行训练,从而利用分类器进行目标检测。QIU 等[2]静态安装激光雷达采集点云,并采用AdaBoost 自适应算法进行训练,获取弱分类器完成车辆识别,识别率为87.7%,但目标车辆的速度仅为3.57 m/s,远小于智轨列车的最低时速8.3 m/s。程健等[3-4]分别使用SVM 和级联分类器动态识别车辆,但实时性较差,单帧处理时长大于200 ms。上述方法识别精度取决于人为设计特征和点云特征表现。一方面,人为设计特征的主观性较强,不具备数据代表性,常综合多种特征来提高检测精度,计算量大导致处理效率低下。另一方面,点云特征表现取决于点云密度,而采用的64 线激光雷达成本高达50 万元,难以进行工程应用。近年来,基于深度学习的检测方法利用数据特征代替了经验特征。CHARLES等[5−6]提出网络模型PointNet 和PointNet++,将目标点云的全局特征和局部特征作为分类和分割用途,识别率达到74.9%和77.3%。LIANG 等[7]集成不同尺度的特征来加强特征表达能力,识别率为70.85%。CHEN等[11]融合点云的多视角特征完成目标检测,识别率为78.63%,平均时耗为360 ms。深度学习方法通过建立目标的点云数据集进行训练,使网络直接学习点之间的关系特征,来提取更趋向于数据群体表现的特征进行目标识别,但该方法极大程度依赖于点云密度和庞大的数据集,且使用单一的激光雷达点云可靠性较差,在实际应用中泛化能力较弱。为进一步提高识别精度,科研人员提出多种融合图像和点云的检测方法。WU 等[8]融合点云和图像生成数据集,并使用CNN获得语义点云,可检测环境中的车辆,但受开阔性环境的数据量影响,处理时长约为1 000 ms。FEI 等[9]将图像检测的车道映射到点云获取检测区域,利用模板匹配来识别箱型障碍物,处理时长为100 ms,但无法确定障碍物的类别。YIN 等[10]将点云转换为深度图,利用K-means算法对图像进行聚类,进而通过坐标转换获取目标点云,该方法处理速度较慢约为950 ms,在动态检测中识别率为49.43%。CHEN 等[11]融合图像特征图和64 线点云俯瞰图特征,并在融合后的特征中提取目标的3D 检测框,识别率为81.94%,处理时长为80 ms,但该方法需要64 线激光雷达作为传感器,成本高昂难以应用于智轨列车。针对智轨列车的应用和检测要求,以上方法在识别率、处理时长及应用成本均表现出一定的局限性。在广泛使用的传感器中,16 线激光雷达成本可控,但点云稀疏无法利用目标特征直接完成车辆识别,而图像可对车辆进行高精度的二维信息检测,但无法反馈车辆的距离值。因此基于稀疏点云与图像的多源数据融合成为车辆三维动态识别的有效手段。本文提出一种分散式的识别方法,分别处理稀疏点云和图像,可同时保证实时性和车辆识别率。首先针对开放式行车场景中的车辆点云进行聚类分析,提出距离角度约束算法检测包含车辆的预融合聚类点集,然后采用深度学习网络模型YOLOv3 检测图像获取车辆图像识别信息,最终迭代匹配车辆图像识别信息和预融合聚类点集以实时获取具有车辆三维信息的点云。
1 研究问题描述
研究目的是在智轨列车开放式行车场景中,如图1 所示,采用16 线激光雷达稀疏点云检测前方障碍物,结合车辆图像识别信息对障碍物进行判断,返回车辆相应的三维信息。
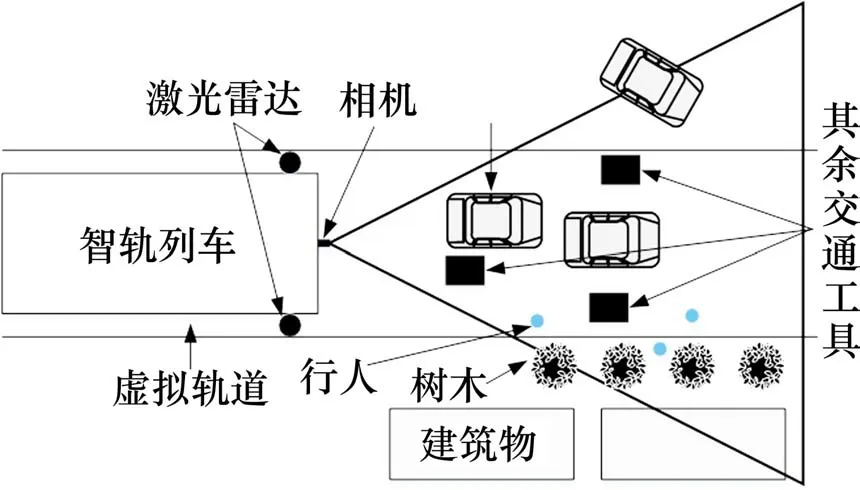
图1 智轨列车开放式行车场景示意图Fig.1 Schematic diagram of open operating scene for autonomous rail rapid transit
传感器为Velodyne-16 激光雷达和Logitech c920相机,相关技术参数如表1所示。由于智轨列车的安装位置限制,将激光雷达安装在车体两侧,安装高度为1 m,如图2(d)所示,最低激光束的扫描距离为3.73 m,保证了近距离车辆的点云密度,同时避免了安装高度过高引起的近距离采集死角问题。相机安装于车头中心,安装高度为1.5 m。

表1 激光雷达和相机的技术参数Table 1 Technical parameters of lidar and camera
相机可采集三角形视角内的车辆信息,并反馈有序的车辆图像特征用于图像检测。而激光雷达由于安装高度和采集特点的限制,在开放式行车场景中车辆点云的采集存在以下4个问题:
1)车辆点云连续性差。如图2(a)所示,左侧激光雷达对前方车辆右侧方采集时,由于采集面积小,导致该处点云连续性差。2) 车辆重复检测。如图2(b)所示,双激光雷达在中间区域存在重复扫描问题。3)遮挡导致点云缺失。如图2(c)所示,车辆相互遮挡或其它障碍物遮挡只反馈回部分车辆点云。4)远距离车辆点云稀疏。如图2(d)所示,激光雷达垂直分辨率低,远距离车辆反射的激光束极少。1和2将导致车辆被分割为多个聚类点集,3和4将增加点云聚类难度。

图2 车辆点云采集示意图Fig.2 Schematic diagram of vehicle point cloud collection
2 基于点云和图像的车辆三维信息识别
如图3所示,首先采用基于角度阈值的地面分割算法,根据地面低纬度特征和连续曲率特征,从稀疏点云提取障碍物点云;之后,针对激光雷达采集车辆点云存在的问题,提出距离角度约束聚类算法,对障碍物点云进行聚类,解决了车辆点云处理中的难聚类、重复聚类等问题,生成了预融合聚类点集;最后,通过YOLOv3 网络模型进行图像检测获取车辆图像识别信息,并提出基于几何映射的融合方法,在行车方向融合聚类点集和车辆图像识别信息,完成车辆三维信息识别。
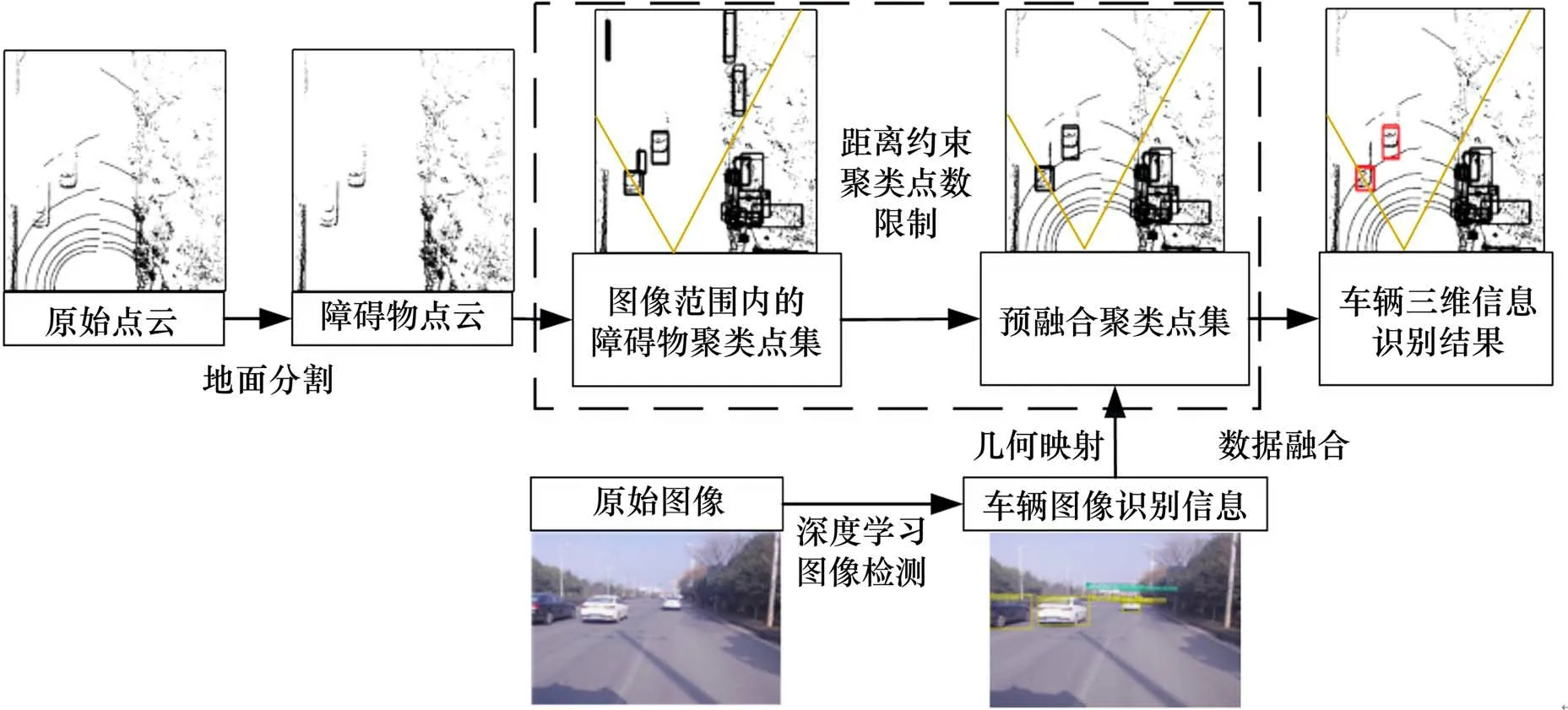
图3 车辆三维信息识别的技术流程Fig.3 Technical process of vehicle three-dimension information recognition
2.1 障碍物点云提取
障碍物与地面相连,可通过地面分割提取具有明显特征的障碍物点云,进而提高多障碍物共存场景中的点云聚类准确率,同时减少数据量加快处理速度。地面形状表现出连续曲率,因此采用基于角度阈值的算法[13]进行地面分割。计算相邻点间的角度值αi:
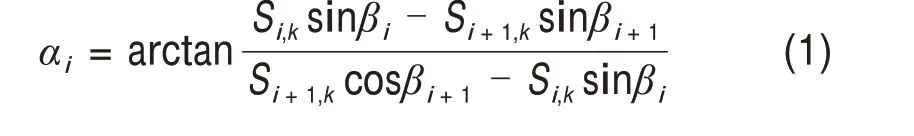
式中:β为点对应的激光束与水平面的夹角;S为点与激光雷达中心的距离;i,k为点对应的激光束编号和水平方向的编号。初始点集为激光雷达底端激光束扫描点,从下到上遍历进行角度评估,若相邻点夹角值小于阈值Td,则将该点标记为地面进行移除,最终获取障碍物点云。
2.2 开放式行车场景中的障碍物点云聚类
障碍物点云包含所有障碍物数据,提出距离角度约束聚类算法对障碍物点云进行分割,获取预融合聚类点集,每个点集对应行车场景中的单个障碍物,用于后续处理的数据融合。
开放式场景中不同物体间存在距离间隔,由于激光雷达扫描频率高,因此,扫描点在不同物体间隔处的距离值变化量较大,通过计算水平或垂直方向相邻点间的距离差值可对物体临界点进行判断。为提高处理速度,将距离差值转换为角度表示。垂直方向角度值γi,k和水平方向角度值γk,i可表示为:
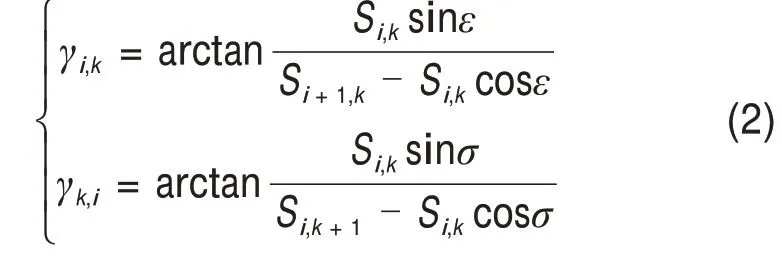
式中:Si,k为点的距离值;ε,σ分别为激光雷达的垂直分辨率和水平分辨率。
设置顶端激光束初始采集点为起始点建立聚类点集p1,对周围相邻角度值进行访问,当角度值大于设定的阈值Tc时,将满足条件的点加入点集p1。若小于阈值,则以不满足条件的点为起始点建立新的聚类点集p2,最终获取障碍物点云的聚类点集集合N={P1,P2,…,Pn},n为聚类点集个数。
由于车辆遮挡、距离因素导致车辆点云稀疏无法有效聚类的问题,通过降低角度约束Tc可解决,但产生了小型噪点聚类点集,并使道路旁障碍物聚类点集融合为大型聚类点集,因此,限制聚类点集数目为:

Sn为点集包含点的个数,n为点集的编号。有效识别范围为ω=(-π/6,π/6),范围阈值为Ta=tanωmax,采集距离约束条件为y∈(0,25),对聚类点集集合N进行快速访问,可获得有效范围目标函数:

xi,yi为聚类点集中心值坐标,通过计算点集内点的最大值和最小值的平均值获得。Ti为有效聚类点集,根据式(4)初步确定预融合聚类点集T。为解决点云连续性差和重复扫描导致的重复聚类问题,采用距离约束二次求解聚类点集。计算集合T中双激光雷达的聚类点集中心值集合P1={SP1,1,SP1,2,…,SP1,m}、P2={SP2,1,SP2,2,…,SP2,n},并 求取任意2 个聚类点集间的距离差值seg,可获取距离函数:
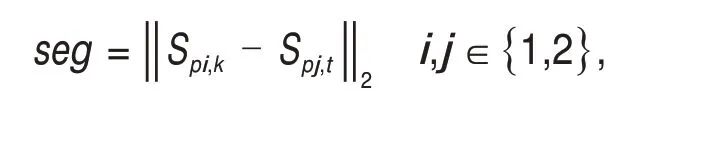
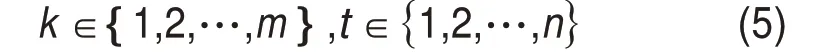
k,t为聚类点集编号;i,j为集合编号;i,k与j,t不相等。当距离差值seg大于阈值TD时,保存2个聚类点集,小于阈值时,保留体积较大的聚类点集,使车辆仅对应单个最优聚类点集,获取预融合聚类点集集合Nall。
2.3 图像与点云融合
考虑到图像具有车辆的有序特征,采用YO‐LOv3 深度学习网络模型提取车辆的高维特征进行检测[14]。如图4 所示,利用Darknet-53 网络对图像进行5 次步长为2 的卷积操作,输出图像下采样获取的13×13,26×26,52×52 共3 种尺度的特征图。将下采样的特征图输入到多尺度网络,并融合具有低阶特征和高阶特征的特征图提升对不同大小目标的检测性能,即:输出下采样的13×13特征图作为第1 尺度特征图,对13×13 的特征图进行上采样与下采样的26×26 特征图相连获取第2 尺度特征图,对26×26 的特征图进行上采样与下采样的52×52 特征图相连获取第3 尺度特征图。通过3 个不同尺寸的2D 检测框在不同尺度特征图上预测多个检测框,利用非极大值抑制算法排序来输出最优检测框,并反馈车辆的二维位置信息。

图4 YOLOv3深度学习网络模型Fig.4 YOLOv3 deep learning network model
本文提出基于几何模型映射的融合方法,将图像检测的n个车辆与点云聚类获得的i个预融合聚类点集进行匹配,可同时对开放式行车场景内的多个车辆进行三维信息识别。
分析车辆图像识别的二维坐标和车辆聚类点集的三维坐标。如图5所示,车辆M检测框的角点图像坐标为M′(box[0],box[1],box[2],box[3]),检测框中心的图像坐标(xcenter,ycenter)满足:
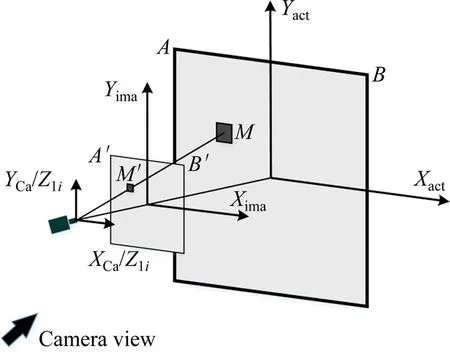
图5 图像映射示意图Fig.5 Diagram of image mapping
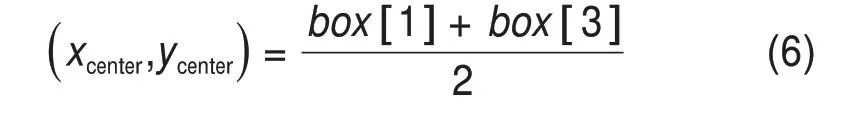
box[1],box[3]为对侧角点坐标。车辆图像的x坐标与图像横向分辨率的比值对应于车辆世界坐标与道路宽度AB的比值,可计算车辆相对于智轨列车中心的角度,获取融合角度值I′n:
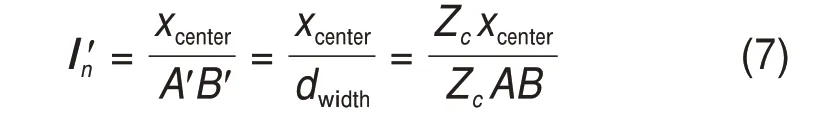
Zc为缩放比;dwidth为图像横向分辨率值;n为图像检测的车辆数目。将预融合聚类点集投影在坐标系XliOYli上,如图6 所示为相机采集视角对应的点云区域,场景中包含3 个障碍物聚类点集p1,p2和p3,对应的聚类点集融合角度值φi满足:
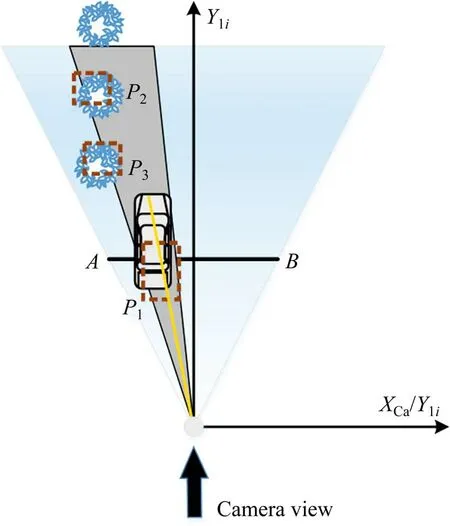
图6 点云映射示意图Fig.6 Diagram of point cloud mapping

式中:ABi= 2yitanτ,τ为30°,xi,yi为聚类点集的中心坐标。由于16 线激光雷达采集数据稀疏,聚类点集与实际车辆位置具有一定的偏差,因此以n个车辆图像融合角度值为基准,对预融合聚类点集迭代计算匹配误差,最小位置匹配误差Δdn为:

对n个车辆图像信息进行匹配融合,若Δdn小于预设的偏移阈值Tfuse,将相应聚类点集标记为车辆,并将对应的φi值移除,重复公式(9)直到遍历所有图像映射值,保证车辆聚类点集只匹配单独的图像信息。
3 实验与分析
3.1 算法参数设置及评估方式
如图2(d)所示,激光雷达对距离15 m 的车辆接收4条激光束,距离16 m 接收3条激光束,大于16 m 接收2 条激光束。因此,对距离智轨列车0~16 m,16~20 m 和20~25 m 的车辆进行识别,并通过数据解帧统计实验结果。数据处理器选用了NVIDIA Jetson Tx2,将车辆中心点进入识别量程的车辆视为有效识别对象。车辆识别性能评估标准如下:真实阳性图像检测(TP):图像中正确检测到的车辆。真实阳性检测(TPD):点云中正确聚类到的车辆。真实阳性识别(TPC):正确识别的车辆。假阳性识别(FPR):错误识别为车辆的对象。图像检测率(AP)、点云检测率(ACCd)、识别率(ACCc)和检错率(TNR)被用于评估算法的有效性:

TP+FN表示识别量程内的车辆真值数目。采用正交分析方法对点云聚类及融合算法中相关参数进行实验分析,设置数据处理各阶段算法的最优参数,具体参数如表2所示。
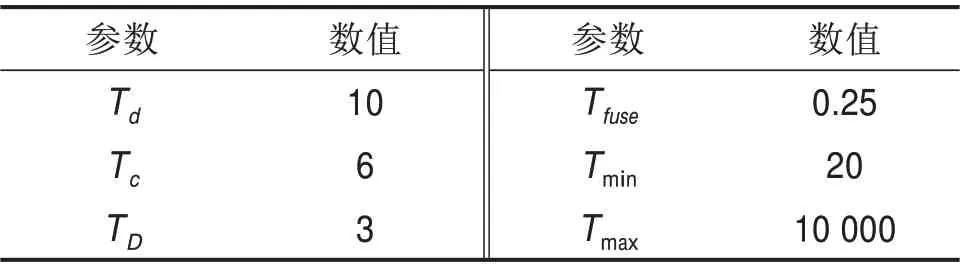
表2 车辆识别方法的参数Table 2 Parameter of vehicle recognition method
3.2 实验结果分析
实验场景为国家智能互联汽车(长沙)测试区和株洲市株洲大道,场景开阔,道路平坦,且车辆数目呈动态变化,实验时智轨列车行车速度为30~50 km/h。在同等实验条件下分别采用本文算法与角度约束算法进行实验对比,实验结果如表3所示。
结合表3 与图7 可知,图像检测中YOLOv3 对近距离车辆具有较高的检测率,不易出现漏检现象,但随着距离的增加,车辆在图像的占比导致特征表达不清晰,检测率下降,使图像整体检测率维持为92%,但远距离车辆在点云中不易聚类且对智轨列车威胁极小,因此,近距离的图像检测精度保证了聚类点集的准确识别,表现为点云检测率与识别率数值相差极小。而相机采集视角限制导致了0~16 m 的检测率和识别率差值较大,如图8 所示,车辆通常从相机视角边缘(即16 m 范围边缘)驶入或者驶出,在连续两帧点云中,由于点云位置变化较小,难以判断车辆是否为有效数据,因此,将中心值大致进入识别量程内的车辆均视为有效数据,从而包含部分无效数据造成样本数量增加,使识别率小于实际识别率且与检测率相差较大。
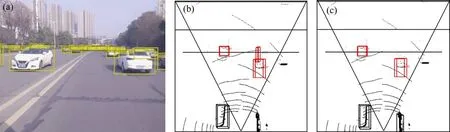
图7 不同算法的车辆三维识别结果Fig.7 Vehicle 3D recognition results of different algorithms
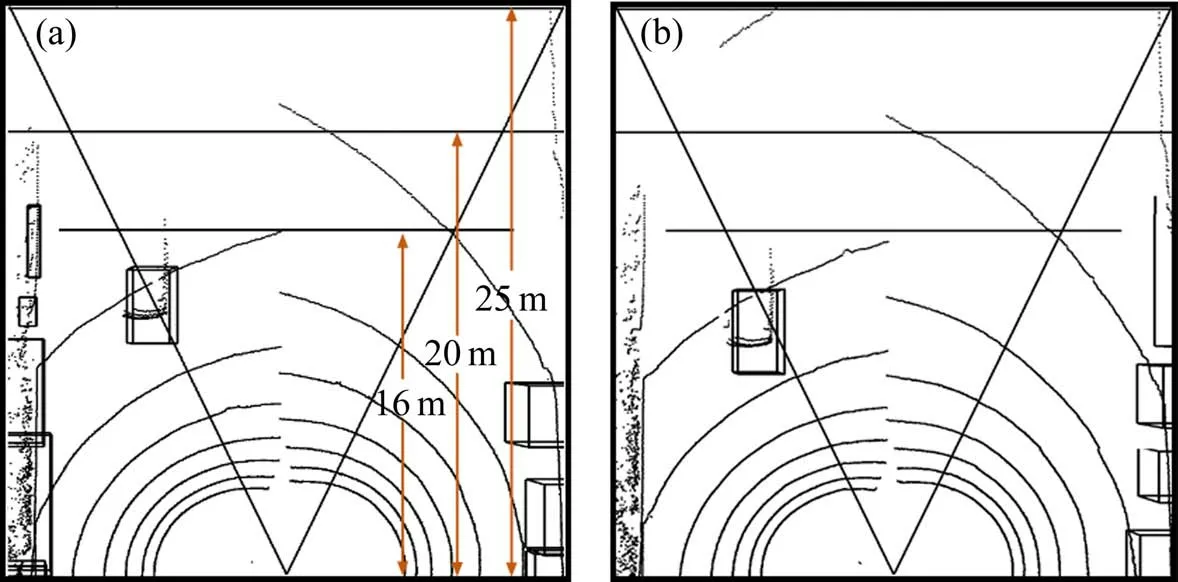
图8 识别范围边缘的车辆Fig.8 Vehicle at the edge of the recognition range

表3 基于激光雷达和图像的车辆三维信息识别结果Table 3 Recognition results of vehicle three-dimension information based on lidar and images
由表3知,本文算法在开放式行车场景中16 m内的车辆点云检测率为90%,图像检测率为92%,识别率为82.04%,较角度约束算法相比,识别率提升了4.44%,检错率下降了2.3%,在多车辆共存场景下,其性能提升较大。随着距离增加,车辆点云密度减少,本文算法检测率和识别率出现小幅度下滑,与角度约束算法相比较,本文算法仅对车辆进行单次检测,因此,在实际融合过程中,如图7(b)和7(c)所示,在开放式场景中对多车辆进行同步识别,角度约束方法产生多聚类导致右前方车辆漏检,本文所提方法有效限制了多聚类点集的产生,对车辆进行了准确识别,使错检和漏检情况减少。所提算法优于文献[12]的车辆识别率81.94%,满足智轨列车的检测需求。
车辆识别的处理时长由点云处理、图像检测、数据融合3部分组成。点云处理和图像检测并行运行,因此取最长的处理时间为评估数据,结合数据融合的处理时间,如表8可知,平均处理时长为77.7 ms,始终小于激光雷达采集间隔100 ms,优于文献[12]的处理时长80 ms,满足智轨列车车辆识别技术的实时性要求。实验结果表明:在智轨列车开放式行车场景下,运行速度为30~50 km/h时,所提方法具有良好的车辆三维信息识别准确率和实时性。

表4 车辆识别处理时长Table 4 Processing time of vehicle recognition
4 结论
1) 通过车辆三维信息识别结果分析可知,在智轨列车开放式行车场景下,基于16 线激光雷达和相机的车辆三维信息识别能够在保证高准确度的同时保持实时性。
2) 提出距离角度约束的聚类方法,在保证车辆点云高检测率的同时,其余障碍物聚类点集和车辆的重复聚类点集大幅度减少,所提方法对单激光雷达稀疏点云和双激光雷达的重叠点云具有鲁棒性。
3) 探讨了开放式行车场景中点云稀疏时的数据融合,实验结果表明,该方法在稀疏点云条件下保持了良好的融合性能。
猜你喜欢
汽车观察(2021年8期)2021-09-01
空间科学学报(2021年4期)2021-08-30
动漫界·幼教365(中班)(2020年3期)2020-04-20
创新作文(1-2年级)(2019年4期)2019-10-15
中国听力语言康复科学杂志(2019年3期)2019-06-24
好孩子画报(2019年10期)2019-01-10
电子制作(2018年16期)2018-09-26
汽车电器(2017年1期)2017-12-06
中国高新技术企业(2017年5期)2017-05-05
物联网技术(2016年11期)2017-01-12
